




问题来了
01
某客户数据库服务器的文件系统经常会被撑满,导致数据库不可用。原来出现过几次解决均是客户清理了文件系统中的trace文件。但是当问题反复频繁出现,客户自然会想到300G的文件系统,怎么说满就满了呢?是不是数据库出现了什么问题了呢?否则怎么会总有那么多trace文件产生?
于是这一次,客户采取的是先删除部分trace,保留了一些信息,然后将系统恢复到正常状态后,联系到了我们,做一次深入的分析。
问题初步分析
02
环境描述:
操作系统:Linux
数据库版本:10.2.0.5
其他:dataguard 备库
/oracle文件系统($ORACLE_BASE所在文件系统)满了,会导致oracle数据库不可用。那到底是什么文件占了大量的空间呢?我们简单的使用du –sh逐步看一下,发现bdump占用了大量空间,进到bdump目录ls –l查看,发现大量trace文件的大小似乎有些超乎寻常;
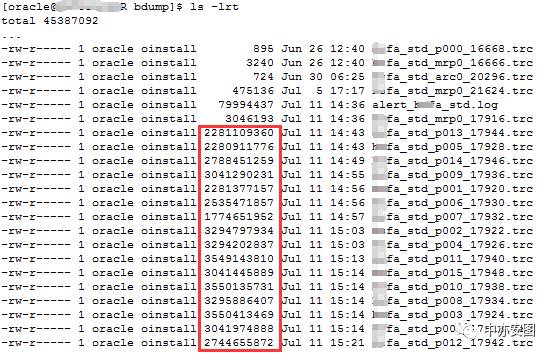
trace文件的特点:
单个trace文件的大小居然达到了3个G左右
这样的trace文件大多都是某些并行进程产生的(从trace名字可以看到进程的名字类似p***)
那么,这些trace文件是怎么产生的呢?难道是因为发生了什么报错导致的吗?
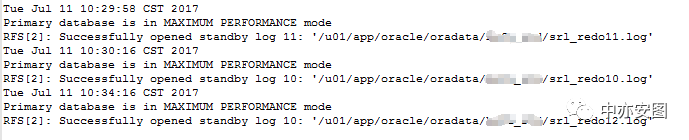
进一步查看alert日志,发现生成trace文件的时间段,alert日志并没有看到明显的异常;
再看trace文件输出的内容:
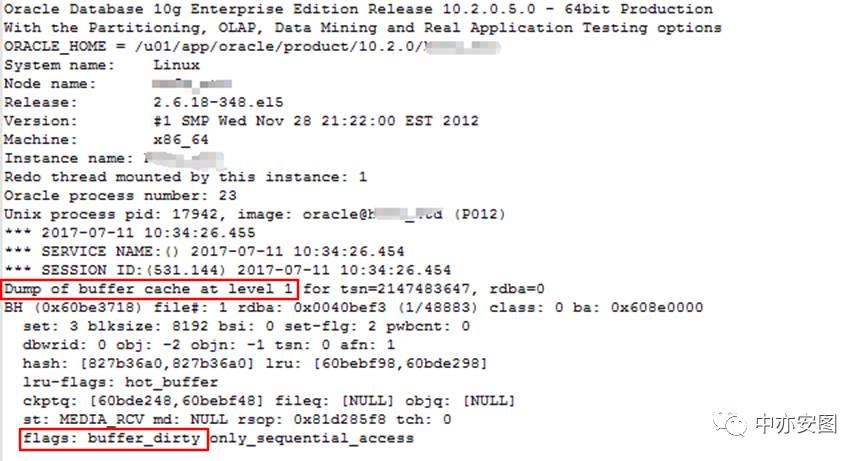
从内容上看,全部都是dump的buffer cache中的数据,所有的数据都是带有buffer_dirty的flag;那么这里是主动dump的dirty buffer呢还是因为所有的buffer 都是dirty的?其实想一想,这是10g的dataguard的备库(只应用redo 日志来修改数据块,不会有其他访问数据的请求),也就不难理解了。
我们知道,这是一套oracle dataguard环境的物理备库,文件系统满了之后MRP进程也就终止了,还需要手工启动MRP进程。
第一次的解决方案
03
老K首先选择远程连接分析这个问题。但是由于问题已成历史,出问题的环境是DATAGUARD的备库环境,无法生成问题时段的AWR报告,客户也没有在操作系统层部署系统监控软件,对于这个问题,暂时没有太多的信息来帮助我们;
虽然根本原因暂时没法找出,临时性的解决方案我们还是可以先给出来的:altersystem set max_dump_file_size='4096M';
通过限定dump的大小,避免出现单个trace文件过大导致的文件系统满的情况 。进一步分析问题,老K暂时只能先对文件系统增加监控,当系统再次出现文件系统使用率快速增长时,可以通过实时监控分析,了解其trace产生的根本原因。
机会来了
04
很快,客户再次联系到我们,系统再次产生大量trace,我们立即通过远程登录操作进行分析,终于看到了问题时刻系统的一系列状态;
首先,我们来看看这些并行进程都是怎么起来的?
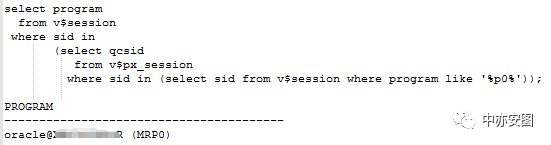
如图所示,产生trace的这些并行进程(pnnn)的父进程都是MRP进程!
然后,从操作系统层面看,CPU和内存均显示正常,唯有IO层面似乎有些异常,可以看到iostat –x的输出结果显示如下:
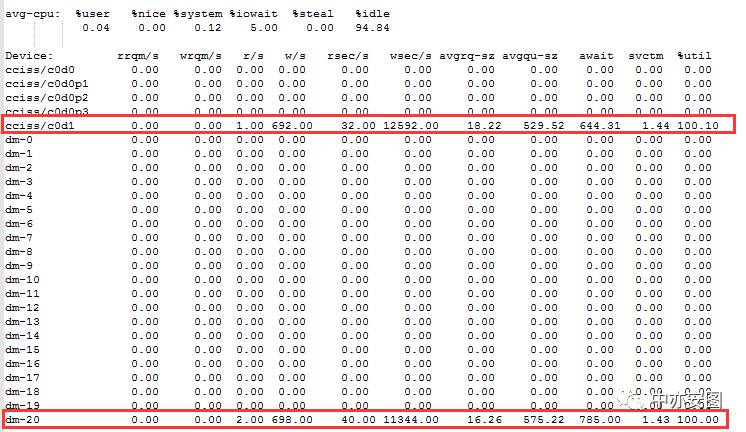
这里可以看到cciss/c0d1盘正是数据库数据文件所在磁盘,其磁盘使用率达到了100%,表面看起来很繁忙,但是我们知道这个磁盘除了数据库(数据库软件和数据文件等)在使用外,并没有其他程序再使用;
嗯,看起来,这是个疑点:难道磁盘慢会导致DATAGUARD备库mrp的子进程出现异常?
先不管,继续看吧,看看还有什么其他信息可以尽快收集的,避免trace文件到达上限后出现新的异常。
OK,下一步我们看看数据库这个时候性能有没有异常。作为dataguard的备库,虽然数据库不是open的,但是我们依然可以通过v$性能视图来查看这些pnnn进程在做什么:
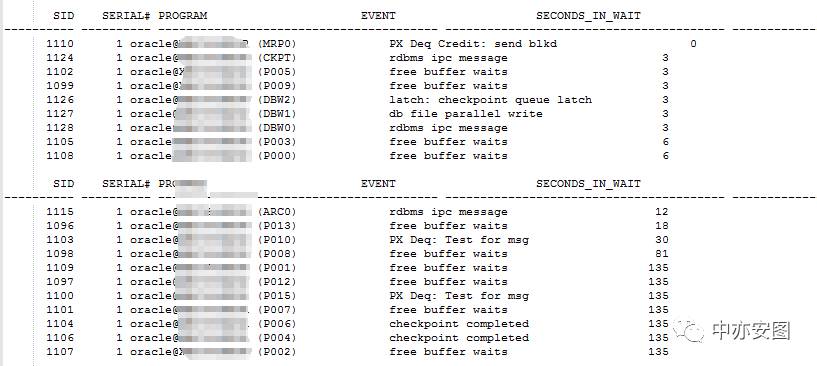
很明显pxxx进程似乎又不少进程在等待free buffer waits,联想到trace文件中打印出来的正是buffer cache中的数据,不得不怀疑pnnn进程输出trace文件正是与这个问题有关;那么,pnnn进程为什么会出现free buffer waits等待呢?这里出现这个等待的原因在哪呢?
完美的推断
05
综合上面的信息,老K充分发挥自己的想象力和逻辑推导,得到下面完美的推断:
系统IO响应时间超长,DBW将buffer cache中的脏块刷到磁盘缓慢;
buffer cache中的脏块没法及时刷出内存,MRP子进程在应用日志时无法获取所需的buffer cache;
MRP子进程出现了freebuffer waits等待,开始向trace文件中写日志;
因为trace文件和oracle数据文件都存放在同一个文件系统,当多个子进程并发的向trace文件写内容时,又进一步加大磁盘IO压力,可能使IO响应时间变长;
再次,回到1,整体陷入循环,直到文件系统写满,MRP进程止;
看似完美的推断,其他部分都可以理解,关键点依然在第三点,当MRP的子进程(Pnnn)出现等待free buffer waits时,它真的就会开始写trace吗?写多少内容呢?
于是,老K开始了MOS搜索,并未找到相关答案,很失望。。。。。。
问题分析到这一步,如果是你,你接下来会怎么做呢?停下来,想一想?
完美的验证
06
对于一个未知问题,在应急处理的过程中我们可以充分利用自己的猜测、推断能力;然而,在问题的根因分析阶段,我们就需要逐步查证、验证我们的猜测和推断;对于上面的推断,我们没有找到对应的官方说法,但是我们完全可以通过不同的环境重现问题来进行验证。
模拟环境:10g的dataguard 环境;
模拟目标:10g环境下dataguard备库,如果MRP子进程出现了free buffer waits等待事件,是否会开始写trace文件?
模拟关键点:如何让MRP子进程出现freebuffer waits等待呢?
什么是free buffer waits?
Thisevent occurs mainly when a server process is trying to read a new buffer intothe buffer cache but too many buffers are either pinned or dirty and thusunavailable for reuse. The session posts to DBWR then waits for DBWR to createfree buffers by writing out dirty buffers to disk.
DBWR maynot be keeping up with writing dirty buffers in the following situations:
The I/O system is slow.
There are resources it is waiting for, such as latches.
The buffer cache is so small that DBWR spends most of it's time cleaning out buffers for server processes.
The buffer cache isso big that one DBWR process is not enough to free enough buffers in the cacheto satisfy requests.
我们的目的是验证MRP子进程出现了free buffer waits等待时,会不会生成dump buffer cache的trace文件。至于free buffer waits产生的原因,我们在测试环境并不关心,因此我们把db_cache_size设置为一个很小的值,主库生产大量的日志,备库启动RMP进程,开始应用日志,很容易就产生free buffer waits等待。
模拟步骤:
依照上面的模拟关键点,我们同样作出了模拟:
调整备库db_cache_size,保持其为比较小的大小即可
在主库做相关的DML操作,生成redo log同步到备库端
查看MRP子进程的等待事件,当出现free buffer waits时,使用oradebug suspend暂停所有的DBW进程

监控MRP子进程是否生产对应的trace文件

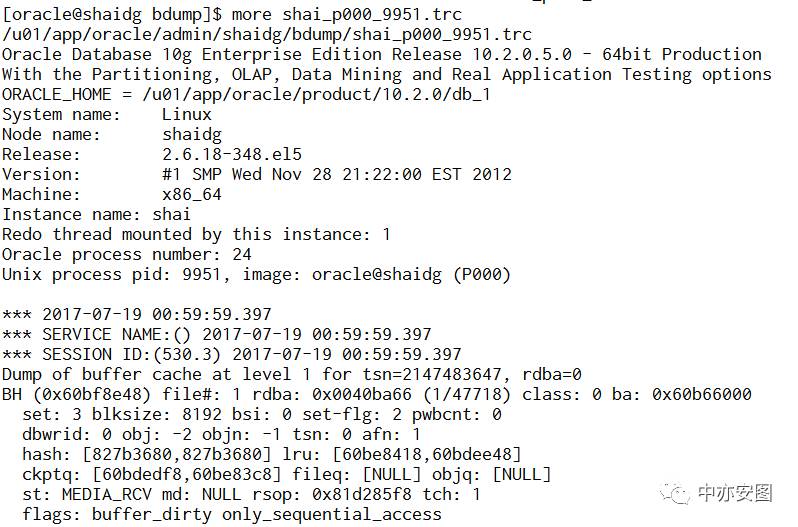
通过上述模拟,我们很快就会发现:
当MRP子进程等待free buffer waits等待达到60秒后,进程就会开始写trace文件
写入trace的内容即为level 1的buffer cache dump
10g dataguard备库会出现这种情况,11g dataguard备库不会出现类似情况;
这样看来,我们的“完美推断”中唯一不确定的点已经被验证了!
再次回顾我们的解决方案
重新想想我们的解决方案
07
通过测试验证了之前的推断是合理的,那么我们需要再次给出解决方案时就更从容了;
首先,对于MRP子进程等待“free buffer waits”就写trace这一问题各方面并没有具体的规避方案,我们可以继续沿用前期的方案,设置max_dump_file_size限制其大小是不错的选择;
其次,为什么会有free buffer waits的等待而且出现超时呢,说白了还是IO缓慢造成的,系统磁盘的IO缓慢,并且多个MRP子进程等待free buffer waits超时后,会同时写trace文件,进一步加大了磁盘的IO压力,最后恶性循环。我们再回头来重新看磁盘的IO性能信息:
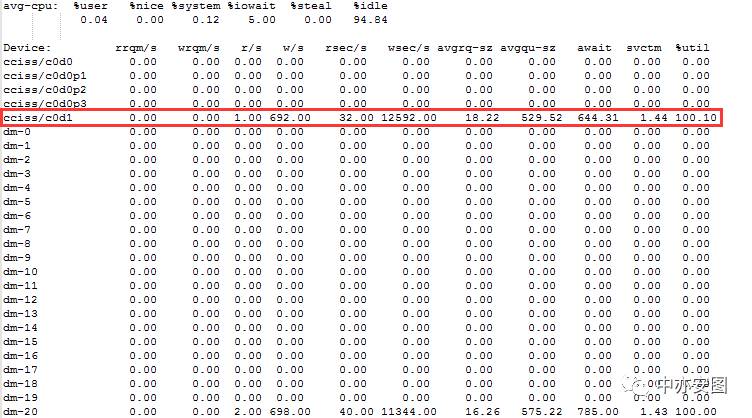
磁盘的服务时间(svctm)约1.4毫秒,IO的响应时间却达到了644毫秒(await),r/s+w/s(也就是IOPS)为将近700,而平均请求队列的长度avgqu-sz达到了(529);磁盘的使用率到达100%!跟客户进行沟通,希望调整存储的分配,然而,客户环境限制,无法及时对此进行进一步的调整;
秉着负责任的态度,我们还需要在此基础上进一步优化调整,那么我们这里能做什么呢?看看系统的异步IO使用情况:

可以看到,系统并没没有使用异步IO;

数据库中的filesystemio_options参数设置为none,看来oracle中也没有配置异步IO,这里可以将数据库中的filesystemio_options参数调整为ASYNCH;

大家跟上思路继续想!为什么会有那么大的IO请求呢?我们是不是可以将IO请求量进一步减小呢?
前面提到,数据库的所有文件都放在/oracle文件系统中,虽然这只是dataguard备库,但是当RFS/MRP、ARC、DBW同时工作的时候,对于磁盘的IO请求量还是挺多的;再出现MRP多个子进程等待free buffer waits超时开始写trace文件,系统的IO压力更是不言而喻;这里减小总IO请求量并不容易,但是我们可以做的是将各种文件分离到不同的磁盘上,减少单个磁盘的IO请求;
最终建议方案
08
综合上面的分析,我们给出的最终建议有三点:
设置max_dump_file_size为较小值,避免出现文件系统撑满的情况;
设置filesystemio_options为ASYNC,提高oracle的DBW进程的性能,降低出现free buffer waits的概率;
通过重新规划ORACLE数据文件、日志文件、归档文件和trace文件的位置,避免单个磁盘IO压力过大导致的上述问题。
注:其中在上述建议1、2实施后,客户系统未再发生p***进程大量写trace的情况;
总结
09
通过这个案例我们能理解到一些什么呢?
1.对于一些猜测、推断,如果我们有条件验证,这将是最好的学习方式;
2.如果数据库的数据文件需要存放在文件系统上,需要做好足够的规划,避免数据库IO性能受到其它因素的影响;

今天的分享就到这里了,上海的小伙伴们福利来啦^_^,CESOUG即将在10月走入上海,报名通道已经开启,快快来报名吧..扫码报名参加CESOUG上海站的欢乐颂技术大会!

更多实战分享和风险提示,请关注“中亦安图”公众号!也可以加小y微信,进微信群探讨技术,shadow-huang-bj。喜欢就转发吧,您的转发是我们持续分享的动力!
关注中亦安图公众号,阅读往期文章:

关注公众号,回复数字查看精彩往期!
回复“017”第十七期:技术人生系列·我和数据中心的故事(第十七期)-看中国最美女DBA的一次价值连城的系统优化!
回复“018”第十八期:技术人生系列·我和数据中心的故事(第十八期)-记一条500行执行计划的SQL问题分析-从应急处理到根因分析
回复“019”第十九期:技术人生系列·我和数据中心的故事(第十九期)-通过案例教你识别操作系统重启是否为CRS引起
回复“020”第二十期:技术人生系列·我和数据中心的故事(第二十期)-ORA-01555错误启示录
回复“021”第二十一期:技术人生系列·我和数据中心的故事(第二十一期)-一条错误结果SQL带来的警示
回复“022”第二十二期:技术人生系列·我和数据中心的故事(第二十二期)-通过trace定位oracle统计信息收集带来的问题
回复“023”第二十三期:技术人生系列·我和数据中心的故事(第二十三期)-致敬618-电子商城秒杀活动技术支持历险记
回复“024”第二十四期:技术人生系列·我和数据中心的故事(第二十四期)-一次一波三折的节点重启问题分析
回复“025”第二十五期:技术人生系列·我和数据中心的故事(第二十五期)-老司机遇到的ORACLE 12C安装问题
回复“026”第二十六期:技术人生系列·我和数据中心的故事(第二十六期)-一次数据库升级引发的惊天大案
回复“027”第二十七期:技术人生系列·我和数据中心的故事(第二十七期)-从一个故障案例看强大到令人发紫的Oracle数据库
回复“028”第二十八期:技术人生系列·我和数据中心的故事(第二十八期)-小CASE见大问题之足以摧毁整个应用的数据库设计
回复“029”第二十九期:技术人生系列·我和数据中心的故事(第二十九期)-如何解决程序时快时慢的业界性能难题
回复“030”第三十期:技术人生系列·我和数据中心的故事(第三十期)-一分钟查一个案例带你看看Oracle数据库到底有多牛逼
回复“031”第三十一期:技术人生系列·我和数据中心的故事(第三十一期)-【深度分析】一个你打死都想不到的死锁导致的应用异常
回复“032”第三十二期:技术人生系列·我和数据中心的故事(第三十二期)-看中国最美女DBA又一次奇葩问题的解决
回复“033”第三十三期:技术人生系列·我和数据中心的故事(第三十三期)-变更不重启,就是害自己!
回复“034”第三十四期:技术人生系列·我和数据中心的故事(第三十四期)-一个CASE看ORACLE新特性的本质
