




前言:又一个时快时慢的SQL,不过这一次,10g与11g执行计划不一致,11g执行计划一致却还是时快时慢,如果遇到这样的问题,你会从哪分析入手,如何给出合理的解释,如何给出进一步优化的建议呢?本期,我们继续有请我们的优化老能手老猫与我们分享又一例经典SQL案例。

客户Q:『老猫,我这里有个非常诡异的问题,从10g升级到11.2以后,有条SQL,晚上运行非常慢;白天就很快。数据量变化不大,一天最多增加10几条数据。』
老猫:『那么,在10g上,是快还是慢?』
这么神奇的问题?对此,没有看到数据,老猫不发表评论。
观察问题的特点
远程到客户环境,查看SQL在不同情况下的执行情况,总结SQL执行特征如下:
11g晚上的情况
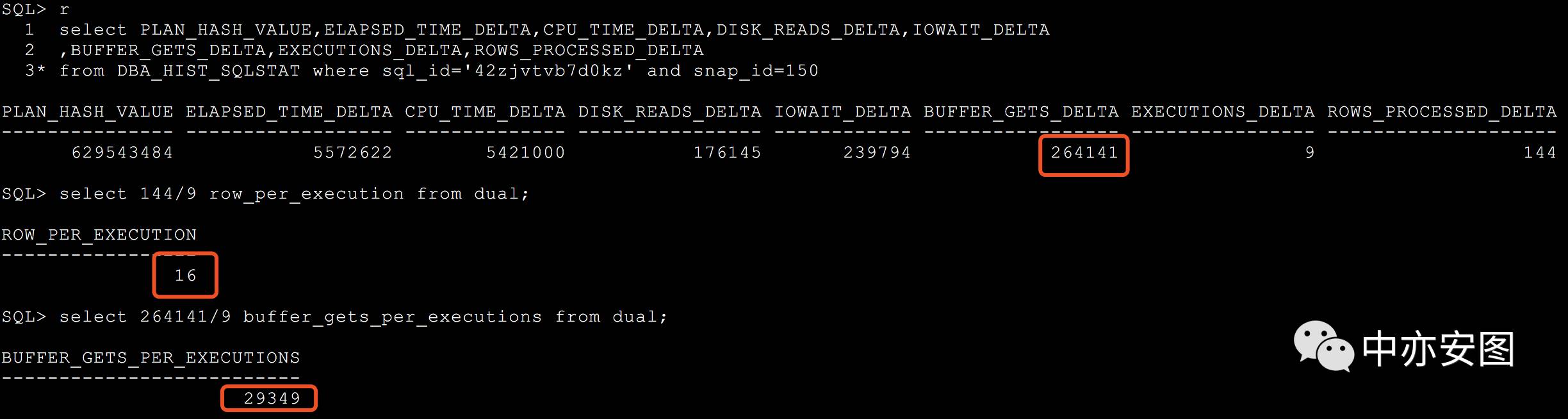
平均每次的buffer gets: 29349
平均每次返回行数: 16行
11g白天的情况

平均每次的buffer gets: 3
平均每次返回行数: 0行
10G上的情况

平均每次的buffer gets: 4098156
平均每次返回行数: 0行
无论是白天还是晚上,每次执行的buffer gets都是4098156,返回的行数与11.2的状况差不多。晚上大约10几行,白天为0行。但是,性能一直很差。

没骗你吧!?11g上执行计划也没变,数据变化也没那么大,但是buffer gets相差很大。11g是不是怕光呀?
也许是得了狂犬病,怕光。你养宠物吗?J

“古老”的10G
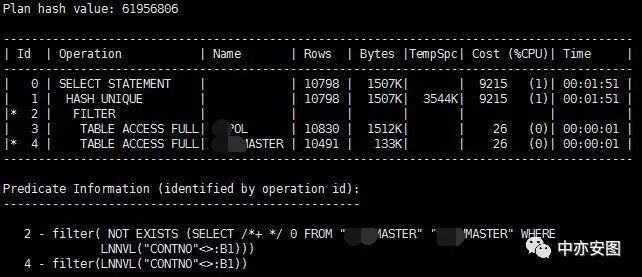
老猫是个尊重事实的人,我要证明Oracle是不是真的患上了狂犬病。先作个血常规!我们看到10G与11G的执行计划不一样,所以,先看执行计划吧。
10g
11g
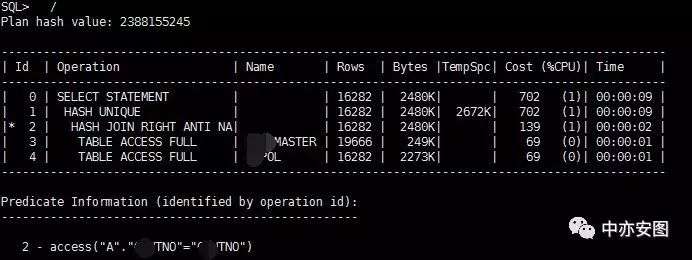
老猫调SQL的习惯是不会先看SQL,执行计划往往能更直接地告诉我们问题出在了哪里。看来10g执行计划和11g执行计划大有不同,逻辑读区别大也是情有可原的了;然而,11G白天晚上的执行计划相似,如果不是大规模的数据量的变化,又是怎么会出现逻辑读相差太多呢?

看完执行计划,其实语句是什么老猫心里也有数了,语句并不复杂:
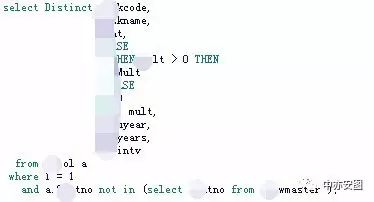
可以看到,语句涉及的两张表,XXOL和XXXMASTER表,使用not in的方式进行关联,关联字段为XXtno;
对于这样一个语句,执行计划的区别就是10g上使用的是filter,而11g上使用的是hash join;
filter相当于从驱动表(XXOL)中取出一条,然后逐条到被驱动表(XXXMASTER)中进行检测,整个语句执行过程中被驱动表将被访问N次;
hash join则只需要将驱动表和被驱动表做一次扫描,然后基于hash算法进行等值关联计算即可;
两种连接方式一对比,高下立判;那么这里的问题就变成了,为什么10g是用filter的方式,而11g却可以实现hash join的方式呢?
not in和not exists
这里filter总是我们不想看到的一种情形,那么怎样给他规避这种情形呢?稍有些经验的同学看到not in 这样的语句,不免会想到oracle中另一种写法not exists;那我们这里不妨用not exists的方式来试试呢?

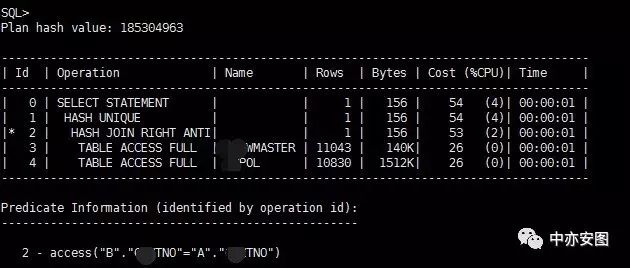
很显然,如果改用not exists的方式进行关联,在10g的数据库中,我们也能看到很顺利的使用了hash join anti;
然而,如果我们稍加理解,就会知道,not in和not exists不是可以随意转换的;
我们来简单分析下面的语句:
select * from t1 where id not in (select id from t2 );--SQL1
select * from t1 where not exists (select 1 from t2 where id=t1.id);--SQL2
考虑下面的各种情形(划重点):
对于SQL1:
1.在t1表中有id=1的记录,如果在t2表中存在id=1的记录,那么 1 not in {1,...}结果为false,id=1的记录将不会返回;
2.在t1表中有id=2的记录,如果在t2表中只有id={1,3,4,5}的记录,那么2 not in {1,3,4,5}结果为true,id=2的记录将会返回;
3.特殊情况,在t1表中有id=1的记录,如果在t2表中存在id 为null值的情况,对于 1 not in (null,2,3,4...},结果为false,因为 null与任何值关联,结果都是false;也就是说,对于任意t1表中的记录,如果t2表中存在id为null值的情况,在这种查询的情况下,它都没有返回,整个查询的返回的结果集将是0条;
4.特殊情况,在t1表中有id 本身为null的记录,null not in {1,2...},结果为false,id为null的记录将不会返回;
对于SQL2:
1.在t1表中有id=1的记录,如果在t2表中存在id=1的记录,那么 not exists {1=1}结果为false,id=1的记录将不会返回;
2.在t1表中有id=2的记录,如果在t2表中只有id={1,3,4,5}的记录,那么not exists {1,3,4,5}=2结果为true,id=2的记录将会返回;
3.特殊情况,在t1表中有id=1的记录,如果在t2表中存在id 为null值的情况,对于not exists {null,2,3,4}=1,其中null与任何值关联均为false,再加上一个not exists取反,结果为true;id=1的记录将会返回;
4.特殊情况,在t1表中有id 本身为null的记录,not exists {1,2,3,..null,..}=null,同上,null值关联为false ,加上not exists取反,结果为true;id为null的记录将会返回;
简单综合上面的结论,我们可以得知,not in 和not exists的区别其实可以简单粗略来说,not exists的查询最终将会返回关联字段含有null值的记录,而not in的查询则正好相反!所以,如果对于一个SQL,用not in还是not exists,可不能为了图方便或者图性能,就随便改写的,需要考虑关联字段上的null值情况;
11g做了什么
上面我们看到了,在10g中,not in 似乎只能走filter,而not exists则可以轻松走上hash join,但是语义上是有区别的;而在11g中,优化器似乎自动帮改写为hash join了;
难道是,语句本身就可以改写,而在10g中优化器没有发现或者被忽略了?通过前面的理解,能不能改写,我们看看表上的字段是否已经被强制定义为非null值即可;
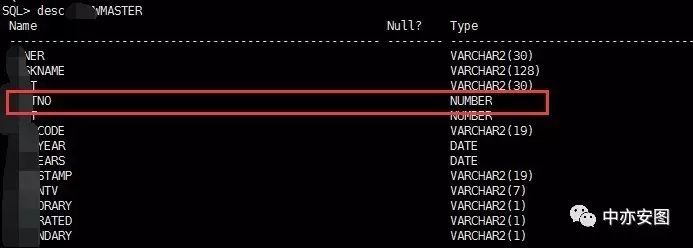
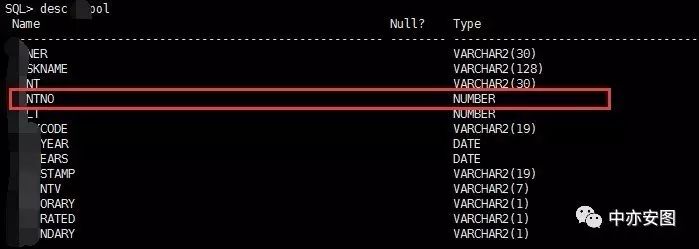
这样看来,直接改写not in为not exists是会有问题的?难道11G做了这么一个愚蠢的决定吗?我们不妨仔细来看看11G上的执行计划:
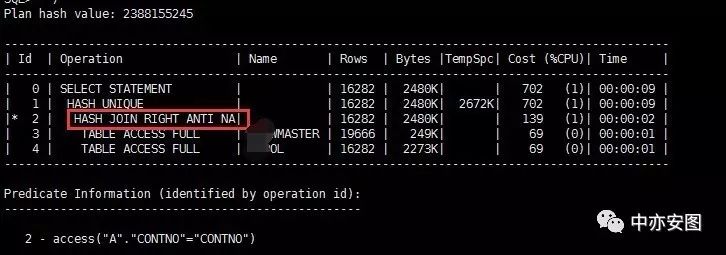
注意到,与我们10g中改写为not exists后执行计划中的"hash join right anti"不同,这里使用的连接方式叫做"hash join right anti na";什么是NA呢?实际上就是11g新功能Null aware的体现!
神奇的Null aware
什么是null aware呢?字面意思就是发现null值;考虑前面划重点部分针对not in语句的第3点和第4点,oracle在帮助改写"not exists"之后做了额外的操作,在提高效率的同时,保证了结果的正确性;
理解Null aware
实际上理解了前面的null值的结果差异,我们就可以大致理解null aware的实现原理了,对于下面这条SQL:
select * from t1 where id not in (select id from t2 );
如果t1/t2表上的id字段都没有定义not null属性,11g的优化器的null aware功能是怎么做到既高效又准确的呢?老猫给它写的伪代码是这样的:
if (select count(*) from t2 where id is null)>0
return null;
else
return
(select *
from t1
where id is not null
and not exists (select 1 from t2 where id = t11.id));
end if;
解释:
1.对于t2表(not in 子表),如果有存在id字段(关联字段)为空的情况,不用继续,整个结果集将为空,不需要再访问外层主表;
2.如果t2表没有id字段为空的情况,继续做t1表的查询,不过在查询的过程中也将t1表的null 值去掉,然后做not exists的转换,继续老老实实的做hash join anti;
理解了上面的逻辑,我们也就能推断出客户白天黑夜数据的变化;
是不是白天的时候XXXMASTER表中xxtno列有null值的情况?到了晚上这些null值列就消失了呢?
...若干了解时间过后...
还真是这样的,原来这就是狂犬病毒啊,太神奇了,你是怎么知道的呢?
......%$@*#^%巴拉*#^%......
看来还是11G好!ORACLE太智能了!那这样,晚上慢一些好像也是正常的了?
功能是不错,不过也得防着点bug,记得把补丁打全哟。晚上那不能说慢,只是正常的过程。

开心一笑
福特汽车公司接到投诉电话,说我买的汽车对香草冰激凌过敏,因为我每次到超市买香草冰激凌,回来时车就打不燃火了,但是我买芒果和巧克力冰激凌就没问题。
客服中心说这是捣乱的,没有理会,直到接到第五次投诉的时候,福特才开始重视,有一个技术工程师自告奋勇去了,说我陪你开车去买冰激凌。结果发现,事实果然如之前所说的那样。
为什么?拿到修理厂也没有发现原因,验证了好几次之后,终于解答了神秘事件:
这辆车的确有故障,系统一旦熄火散热不好,需要5分钟之后才能打燃,芒果味或者巧克力味冰淇淋的销售很好,排队要超过5分钟,所以没有问题。但是香草冰激凌的销售不好,排队的人很少,3分钟就可以买到,这个时间不足以让系统散热,所以打不燃。
老猫有话说
该升级的时候,就升级。Oracle在每个版本上,不仅仅是修复一些Bug,还作出了很多贴心的好功能。
这个NOT IN(…)的语义,开发人员真的理解了吗?会不会是应用的Bug呢?这需要与开发人员确认。
福特汽车的故事告诉我们,不要轻视客户的描述,往往背后藏着天大的秘密。

敬告:
今天的分享就到这里了,听说你很热爱ORACLE技术,而且还报名参加了2017首届Oracle欢乐颂技术大会!!那么请您留意您的报名邮箱是否已经收到邀请函;因为此次活动规模控制在300人左右的范围,而报名人数已经超过了700人,我们不得不通过报名的先后顺序等方式对报名人员进行筛选,如果您未能收到邀请函,我们对您表示诚挚的歉意,同时我们在未来将继续做线下分享,届时将优先考虑本次报名而未能收到邀请函的朋友;对于本次未能向您发送邀请函深表歉意。

不过,您也可以加入我们,每周我们来一场团队内部的欢乐颂:

关注中亦安图公众号,阅读往期文章:

关注公众号,回复数字查看精彩往期!
回复“017”第十七期:技术人生系列·我和数据中心的故事(第十七期)-看中国最美女DBA的一次价值连城的系统优化!
回复“018”第十八期:技术人生系列·我和数据中心的故事(第十八期)-记一条500行执行计划的SQL问题分析-从应急处理到根因分析
回复“019”第十九期:技术人生系列·我和数据中心的故事(第十九期)-通过案例教你识别操作系统重启是否为CRS引起
回复“020”第二十期:技术人生系列·我和数据中心的故事(第二十期)-ORA-01555错误启示录
回复“021”第二十一期:技术人生系列·我和数据中心的故事(第二十一期)-一条错误结果SQL带来的警示
回复“022”第二十二期:技术人生系列·我和数据中心的故事(第二十二期)-通过trace定位oracle统计信息收集带来的问题
回复“023”第二十三期:技术人生系列·我和数据中心的故事(第二十三期)-致敬618-电子商城秒杀活动技术支持历险记
回复“024”第二十四期:技术人生系列·我和数据中心的故事(第二十四期)-一次一波三折的节点重启问题分析
回复“025”第二十五期:技术人生系列·我和数据中心的故事(第二十五期)-老司机遇到的ORACLE 12C安装问题
回复“026”第二十六期:技术人生系列·我和数据中心的故事(第二十六期)-一次数据库升级引发的惊天大案
回复“027”第二十七期:技术人生系列·我和数据中心的故事(第二十七期)-从一个故障案例看强大到令人发紫的Oracle数据库
回复“028”第二十八期:技术人生系列·我和数据中心的故事(第二十八期)-小CASE见大问题之足以摧毁整个应用的数据库设计
回复“029”第二十九期:技术人生系列·我和数据中心的故事(第二十九期)-如何解决程序时快时慢的业界性能难题
回复“030”第三十期:技术人生系列·我和数据中心的故事(第三十期)-一分钟查一个案例带你看看Oracle数据库到底有多牛逼
回复“031”第三十一期:技术人生系列·我和数据中心的故事(第三十一期)-【深度分析】一个你打死都想不到的死锁导致的应用异常
回复“032”第三十二期:技术人生系列·我和数据中心的故事(第三十二期)-看中国最美女DBA又一次奇葩问题的解决
回复“032”第三十三期:技术人生系列·我和数据中心的故事(第三十三期)-变更不重启,就是害自己!
