




不知不觉,技术人生系列(每周四首发)到了三十期。
承蒙大家的喜爱,我们会一直做下去!
也希望喜欢技术人生系列的朋友们,顺手帮转发一下,您的转发是我们持续分享的动力。
记得端午节和兄弟们喝酒时,有朋友说,“要不,你们成立一个用户组吧,这样更多的朋友可以以一个公益的形式加入到分享的队伍中,也可以从线上分享发展到线下分享,并且可以到各个城市中去做实战分享,让大家可以面对面的交流”;
说的有道理,于是乎,有了CESOUG,即China Experience Sharing Oracle User Group,中文名为中国经验分享Oracle用户组,希望不同城市有兴趣的朋友一起加入进来成为联合创始人(加小y微信shadow-huang-bj私聊),一起推动运维技术的分享氛围!
再然后,有了第一次线下活动的策划,活动主题是欢乐颂,就是喜欢你---ORACLE!
这可能将是你参加的最精彩的一次Oracle实战类技术分享大会!

小y将邀请国内顶尖的Oracle实战高手一起分享,堪称史上最强阵容,内容绝对让你爽到爆,2017年首届ORACLE欢乐颂技术大会的分享嘉宾包括:

低调行者小y黄远邦
优化高手老猫陈宏义
技术狂人老K周永康
GCS RAC和Exadata顶尖高手高斌
前GCS首席技术工程师宋日杰
ACS神秘高手
金牌DBA徐戟(白鳝)
数据恢复高手程飞(惜分飞)
中行总行Oracle专家张海滨
工行总行Oracle专家邓强
以及建行总行和农行总行的Oracle专家
还在犹豫什么呢,快快识别图中二维码进行报名吧!

问题来了
电话响了,是一位证券客户DBA的来电,看来,问题没过两天,又出现了。
接起电话,果不其然。
“小y,前天那个问题又重现了。重启后恢复正常,这次抓到了hangAnalyze,不过领导在身后一直催,所以没来得及抓取systemstate dump就重启了。你尽快帮忙分析下吧,hanganalyze的trace文件已经转到你邮箱了。” |
就在2天前,该客户找到小y,他们有一套比较重要的系统出现了数据库无法登陆的情况,导致业务中断,重启后业务恢复,但原因未明,搞的他们压力很大。
可惜的是,他们是事后找过来,由于客户现场保护意识不足,最后也只能是巧妇难为无米之炊了…
总的来说,小y还算是比较熟悉证券行业的。
毕竟,小y多年来一直在银行、证券、航空等客户提供数据库专家支持服务,这其中就包括了北京排名前6的所有证券公司。
简而言之,证券行业的要求就是快速恢复,快速恢复业务大于一切。
原因很简单,股价瞬息万变,作为股民,如果当时无法出售或者购买股票,甚至可能引发官司。所以,证券核心交易系统如果中断时间超过5分钟,则可以算得上是严重故障了,一旦被投诉,则可能会被证监会通报,届时业务可能被降级,影响到证券公司的经营和收益。
结合这个特点,小y为客户制定了应急预案,看来收集systemstate dump是来不及了,只能先收集hangAnalyze,时间来得及的话则可以继续收集systemstate dump。
收集hangAnalyze的命令很简单,照敲就是了,没什么技术含量。
$sqlplus –prelim “/as sysdba” SQL>oradebug setmypid SQL>oradebug hanganalyze 3 ..此处等上一会.. SQL>oradebug hanganalyze 3 SQL>oradebug tracefile_name |
开启分析之旅
1
hanganalyze初体验
打开附件,内容如下,中间部分太长了,所以用省略号代替。
朋友们,不妨自己停下来,耐心阅读一下,看看是否可以看的明白。
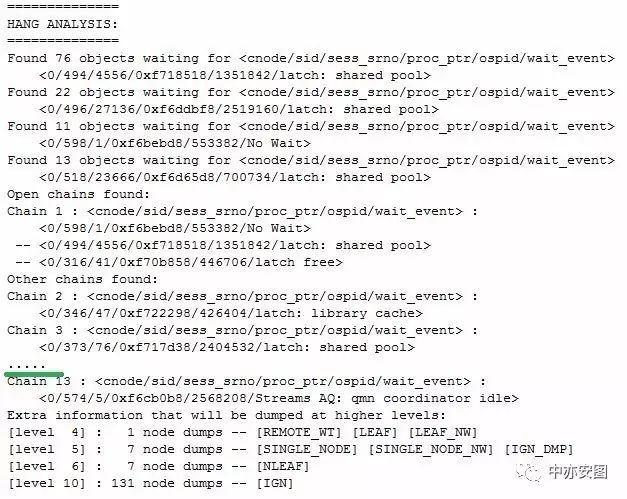
很快,根据这个trace,小y在一分钟找到了问题原因。
而这种问题,在其它数据库中属于很难查清的问题。
所以不得不说,Oracle的hangAnalyze是如此的牛逼…
问题原因就在后面,什么时候往下翻,由你决定…
……
……
……
……
……
……
……
……
……
……
……
2
如何开始
先看trace的第一部分,如下所示:
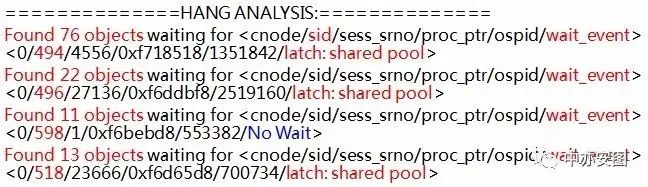
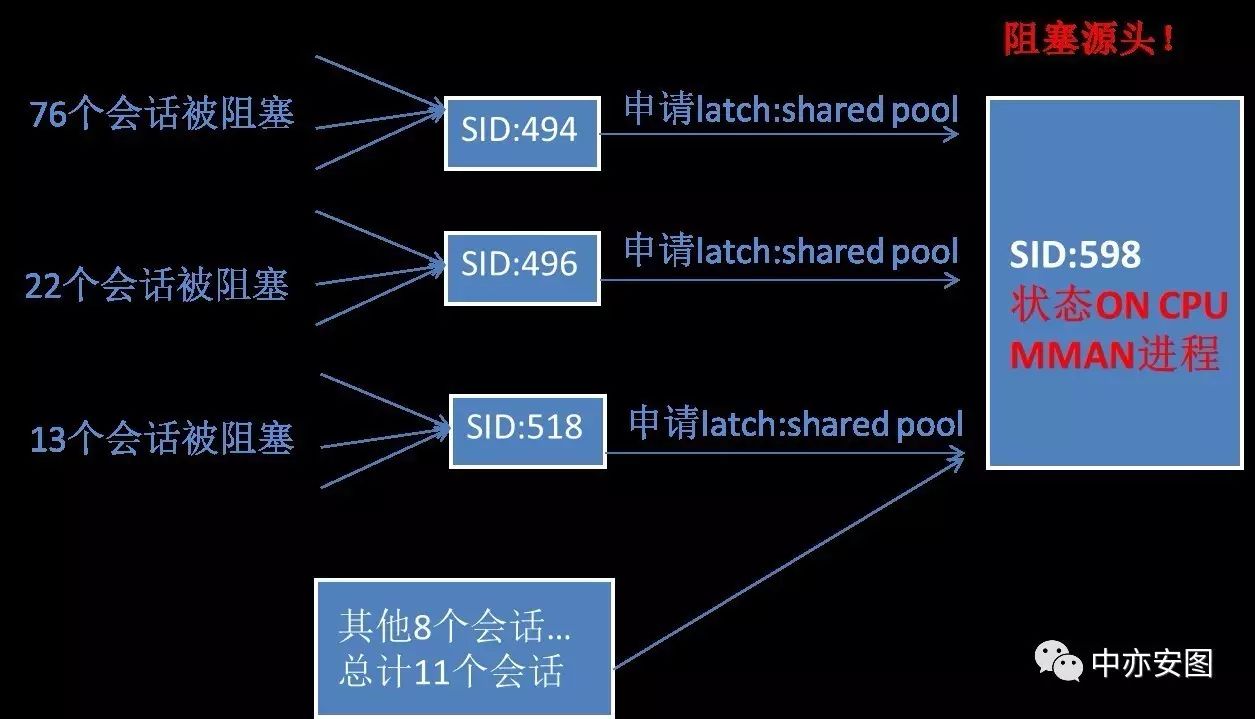
上面的信息为出现异常时数据库的整体状态摘要,这些信息表示:
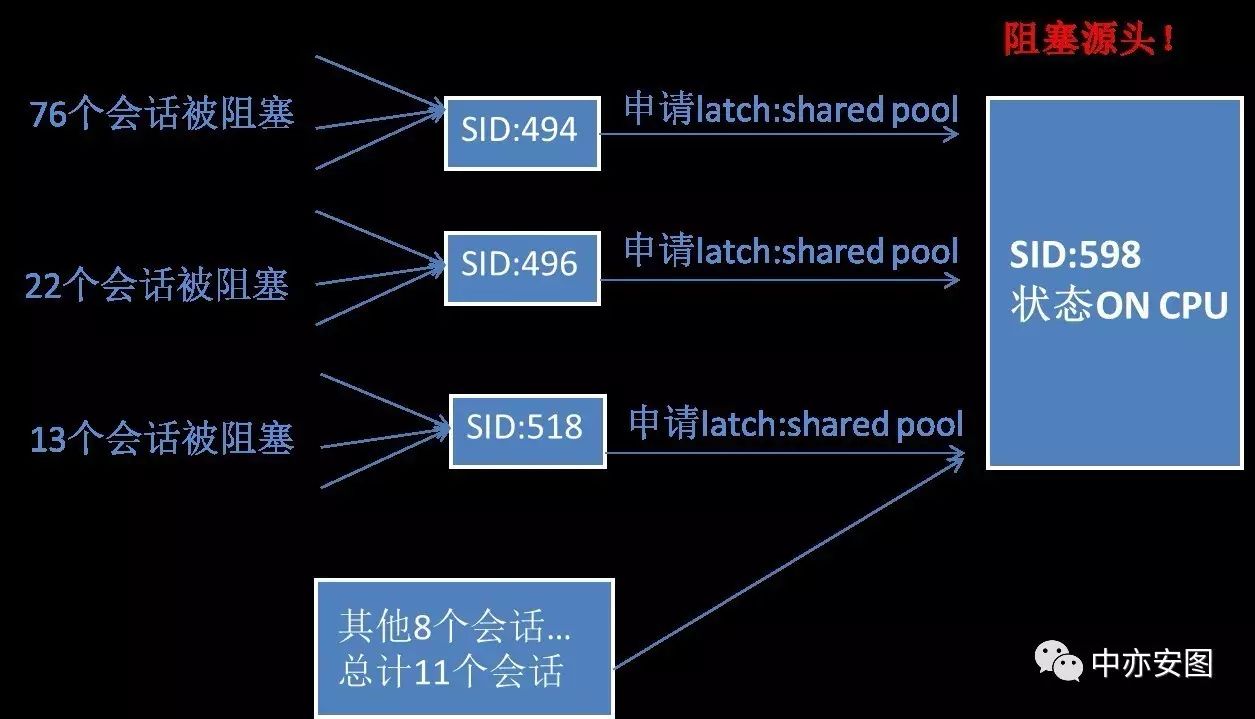
1)共76个会话被sid=494的会话阻塞,原因是sid=494的会话本身申请latch: shared pool资源时被其他会话阻塞。
2)共22个会话被sid=496的会话阻塞,原因是sid=496的会话本身申请latch: shared pool资源时被其他会话阻塞。
3)共11个会话被sid=598的会话阻塞,”No Wait”表示sid=598的会话本身并未等待任何资源,即该进程在使用CPU。
4)共13个会话被sid=518的会话阻塞,原因是sid=518的会话本身申请latch: shared pool资源时被其他会话阻塞。
用一张图来表示,如下所示:
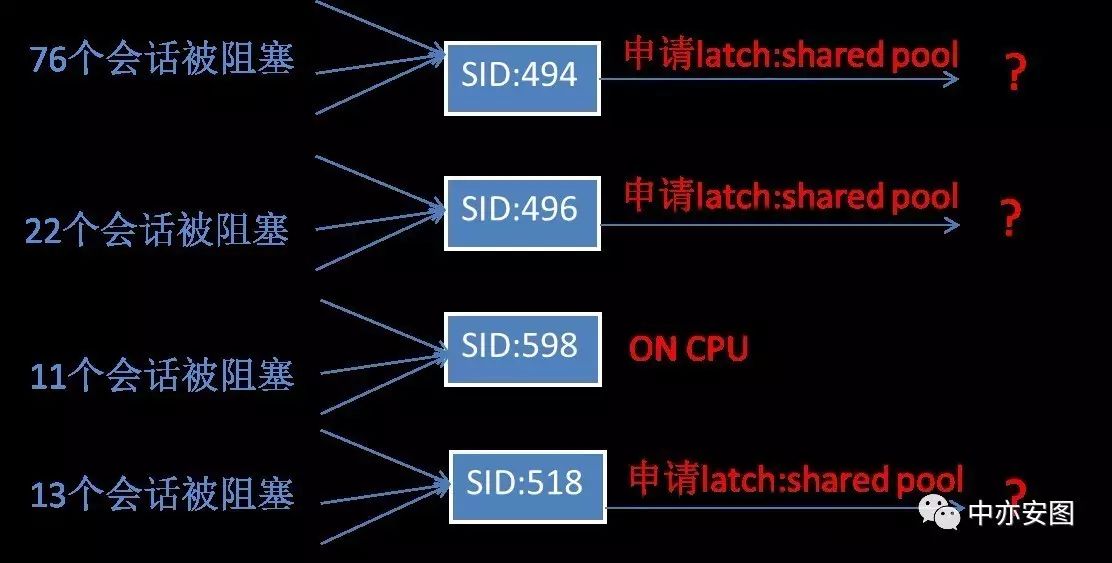
3
找到阻塞的源头
会话494、496、598、518之间可能相互独立,也可能存在互相阻塞的关系。
小y带着大家继续往下梳理。
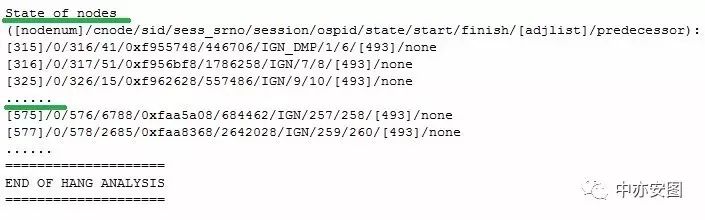
从抓取到的hanganalyze信息摘取上述会话信息的细节,如下所示:
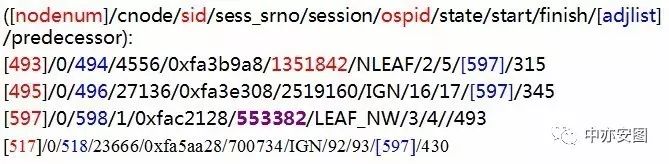
在该信息中,关注4列的内容即可,其中:
第1列为oracle给trace中每一个会话所取的唯一逻辑标识;
第3列表示会话sid;
第6列表示操作系统进程号;
第10列表示阻塞该会话的唯一逻辑标识,为空时表示无阻塞。
因此,从上述信息可知:
1)sid=494的会话被唯一逻辑标识为597的会话阻塞
2)sid=496的会话被唯一逻辑标识为597的会话阻塞
3)sid=518的会话被唯一逻辑标识为597的会话阻塞
而唯一逻辑标识为597的会话信息为:
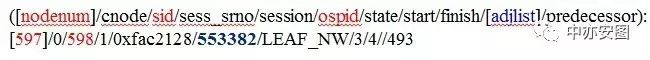
即唯一逻辑标识为597的会话的sid=598,操作系统进程号553382,该行的第10列为空,即再也没有其他会话阻塞sid=598的会话。
也就是说,sid=598的会话就是数据库异常时的会话获取资源时阻塞的源头。如下图所示:
4
陷入僵局?(阻塞的源头只是一个数字!)
前面的分析,已经找到了源头是SID=598的会话。
那么sid=598的会话是什么用户什么程序什么机器发起,在执行什么SQL,进程的callstack是什么呢?所有这些信息,我们都可以在systemstate dump中可以找到,但可惜的是,客户虽然由于时间关系没有来得及抓取systemstate dump,因此无法进一步获取该进程的信息。
悲剧了!难道要再一次陷入巧妇难为无米之炊的尴尬境地么?
如果是你,你会怎么办,此处不妨思考几分钟…
……
……
……
……
……
……
……
……
……
……
……
5
找到打开天堂大门的钥匙
打开天堂之门的钥匙有很多把,但上帝总是会眷恋把握细节和用心的人。难道因为缺少systemstatedump就放弃了么?那客户怎么办?
这里介绍其中一把钥匙,当然还有其他钥匙,如果你也找到了其他钥匙,不妨留言告诉小y。继续看阻塞源头的相关信息。
SID=598的会话,在操作系统上的进程号是553382。
一个进程要么是前台进程(服务进程),要么是后台进程。
如果是后台进程,则我们可以在alert日志中,找到操作系统上进程号是553382对应的后台进程到底是什么!
打开alert日志,果然不出所料,凶手真的是他
……
……
……
……
……
……
如下所示:

因此,造成数据库异常的源头就是数据库后台进程mman进程!
即负责ORACLE内存动态调整的后台进程!
该进程在数据库中负责SGA内存在各个组件比如buffer cache和shared pool之间的动态调整。通俗的来说,我们在配置数据库所使用的相关内存参数时,在10g版本之前,需要手工设置buffer cache和shared pool的大小,但是10g版本后,为了简化管理,可以只设置buffer cache和shared pool加起来的总内存大小,不需要关注单独为buffer cache和shared pool设置多大的内存,数据库后台进程mman进程可以在两者之间根据需要动态调整。
很多客户都默认地选择了这样一种智能但并不完美的内存管理方式。
那么整个系统中,是否有出现SGA内存动态调整的情况呢?
摘取问题当天其他时段,例如15点到16点之间的AWR报告,观察该系统的情况。
(数据库重启后无法观察到问题时段v$sga_resize_ops了)

从中可以看到,shared pool在15点时的大小为3584M,到了16点就已经被动态调整到了1760M,这些就是由后台mman进程来完成的。如此大幅度的下降,说明期间经历过多次的调整,不断的对shared pool进程shrink操作。
那么到底是sharedpool中的哪部分内存被挪到了buffercache呢?
从AWR报告的SGA breakdown difference可以看到:
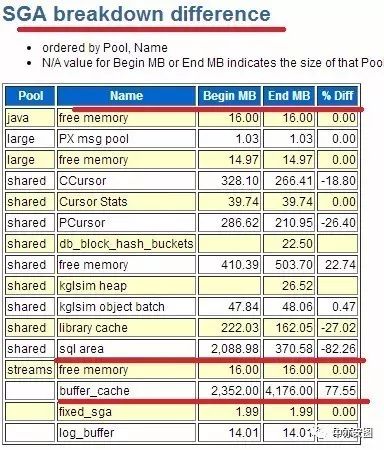
SQL AREA从2088M降至370M,被刷出了82%!
SQLAREA 大量的内存被挪走,SQL语句(含登陆的递归SQL)必然被大量刷出,后续需要硬解析(hanganalyze可以看到有latch:shared pool)。
6
进一步分析原因
根据上述分析,有一个问题仍然需要确认:
那就是为什么SGA动态调整导致如此严重的问题?
这明显与ORACLE的BUG相关。
当发现整个系统buffer cache命中率低、物理读高的时候,buffer cache需要从shared pool中借走部分内存(由MMAN进程来负责完成动态调整)。
当需要借走的granula属于shared pool的SQL AREA,但是由于SQL语句长时间在执行,SQL AREA被pin住,MMAN进程持有了latch:shared pool又不得不等,就容易导致其他进程无法获得latch:shared pool而引发问题。
当然,还有包括ORACLE内部实现动态机制的机制不够合理和高效等缺陷,也可能导致SGA动态调整引发问题。
实际上,小y的经验是,但凡涉及到内存动态调整的,不管是数据库,还是操作系统,都可能出现问题,例如操作系统的透明大页内存转换,就可能导致kernel hang 。
如果想要查BUG,从上文的分析中可以知道,大概搜索的关键字是MMAN 进程、latch Child shared pool和 shrink和CPU,以此为关键字在ORACLE METALINK BUG库中查找相关BUG,与“ Bug 8211733- Shared pool latch contention when shared pool is shrinking [ID 8211733.8]”中的描述吻合,但缺少systemstate dump,无法核对call stack,因此无法完全确认。
但具体到该CASE,核对SGA动态调整的具体BUG号的意义不大,因为SGA在各个版本中还是存在或多或少的问题,个别补丁不能完全预防隐患,最有效的解决办法时关闭SGA动态调整,使用手工管理的方式进行,同时为了避免关闭动态调整后的副作用,需要对应用进行对应的优化和调整。
7
头脑风暴之是否可以不关闭SGA动态调整来解决问题呢
各位看官不妨也想一想这个问题?
…………
…………
…………
…………
…………
…………
…………
…………
…………
…………
答案是当然可以,但是不知道能持续多长时间,因为应用可能在变,SQL可能在变。
说可以,是因为,可以看到,该系统物理读高的SQL有不少,并且很多SQL单次执行时间超过100秒!如果SQL语句优化后,buffercache就几乎不需要动态调大了,同时SQL优化后执行时间短了,需要pin的时间也短了,几个因素变好了,问题遇到的概率就小很多很多。
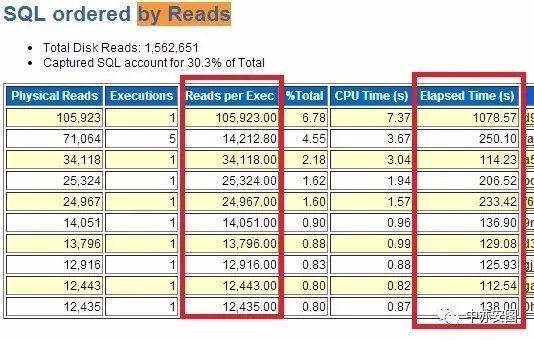
如果SQL语句短期无法优化和解决呢?
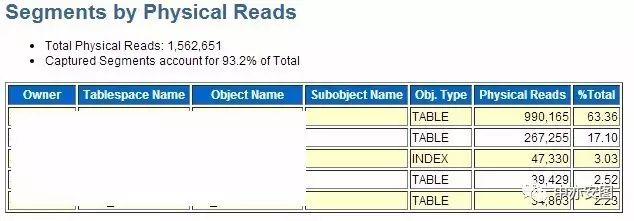
如下图所示,物理读主要集中在两张表,并且表不大,
因此可以通过keep到内存也可以解决物理读高导致动态调整的问题。
8
头脑风暴之如何避免关闭内存动态调整后的副作用
单纯的关闭SGA动态调整,意味着shared pool没有自动增大的机会,可能因为内存碎片化导致ORA-4031的几率增大,特别是对于硬解析较高的系统。因此,我们查看了该系统的硬解析情况。如下图所示:
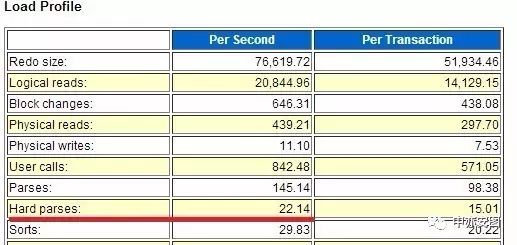
可以看到,每秒硬解析达到了22次!说明SQL语句的共享性做的不好。
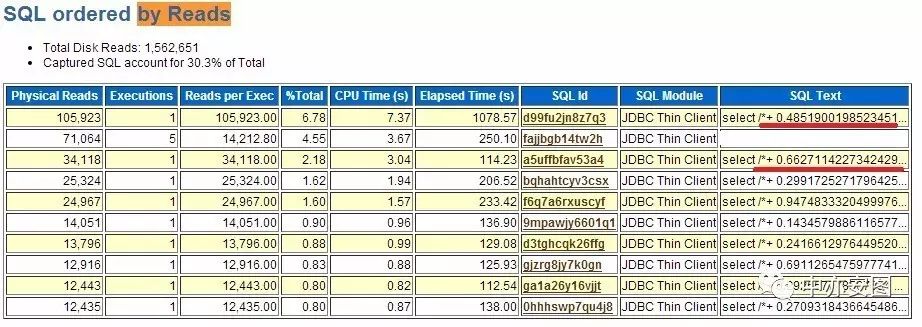
检查发现,如下图所示,该系统大量地用了HINT,HINT中加入了一个随机生成的数据,这样就导致SQL语句无法被共享和重用。长远看,需要和开发沟通解决这类问题。
但是由于证券行业短周期内定期重启的特点,这个问题可以忽略。
问题原因与经验总结
在关闭SGA动态调整后(同时加大shared pool),长时间观察,
问题没有再出现,问题得到解决。
故障原因总结:
1) SID=598即MMAN进程,在进行SGA动态调整,从sharedpool中挪动部分内存到buffercache,期间长时间持有latch:sharedpool,但由于长时间无法完成sharedpool的shrink,导致其他进程无法获得latch:shared pool,从而出现问题
2) 导致内存需要动态调整的原因在于SQL语句的物理读很高,buffer cache需要动态扩大,shared pool需要收缩,SQL语句执行又很长,需要长时间pin住,是触发问题的导火索。
经验总结:
1) 学会阅读hangAnalyze的trace,将帮助你快速找到问题原因
2) 如果不想关闭SGA动态调整,则需要对于系统中出现物理读高的SQL进行优化或者keep物理读高的表到内存中
3) 对于每个调整,需要掌握其副作用,并根据情况作出关联调整
通过这样一个案例,你不难发现,其他数据库中貌似很难查清的问题,在ORACLE中,只要掌握正确的方式,那么只需一分钟!
如果你想听到更多的实战案例分享,快快来报名参加2017首届Oracle欢乐颂技术大会吧^_^
识别图中二维码或者阅读全文进行报名。
更多实战分享和风险提示,请关注“中亦安图”公众号!也可以加小y微信,进微信群探讨技术,shadow-huang-bj。喜欢就转发吧,您的转发是我们持续分享的动力!
关注中亦安图公众号,阅读往期文章:

关注公众号,回复数字查看精彩往期!
回复“017”第十七期:技术人生系列·我和数据中心的故事(第十七期)-看中国最美女DBA的一次价值连城的系统优化!
回复“018”第十八期:技术人生系列·我和数据中心的故事(第十八期)-记一条500行执行计划的SQL问题分析-从应急处理到根因分析
回复“019”第十九期:技术人生系列·我和数据中心的故事(第十九期)-通过案例教你识别操作系统重启是否为CRS引起
回复“020”第二十期:技术人生系列·我和数据中心的故事(第二十期)-ORA-01555错误启示录
回复“021”第二十一期:技术人生系列·我和数据中心的故事(第二十一期)-一条错误结果SQL带来的警示
回复“022”第二十二期:技术人生系列·我和数据中心的故事(第二十二期)-通过trace定位oracle统计信息收集带来的问题
回复“023”第二十三期:技术人生系列·我和数据中心的故事(第二十三期)-致敬618-电子商城秒杀活动技术支持历险记
回复“024”第二十四期:技术人生系列·我和数据中心的故事(第二十四期)-一次一波三折的节点重启问题分析
回复“025”第二十五期:技术人生系列·我和数据中心的故事(第二十五期)-老司机遇到的ORACLE 12C安装问题
回复“026”第二十六期:技术人生系列·我和数据中心的故事(第二十六期)-一次数据库升级引发的惊天大案
回复“027”第二十七期:技术人生系列·我和数据中心的故事(第二十七期)-从一个故障案例看强大到令人发紫的Oracle数据库
回复“028”第二十八期:技术人生系列·我和数据中心的故事(第二十八期)-小CASE见大问题之足以摧毁整个应用的数据库设计
回复“029”第二十九期:技术人生系列·我和数据中心的故事(第二十八期)-如何解决程序时快时慢的业界性能难题
