




作者简介
Dongyu,资深云原生研发工程师,专注于日志与OLAP领域,主要负责携程日志平台和CHPaas平台的研发及其运维管理工作。
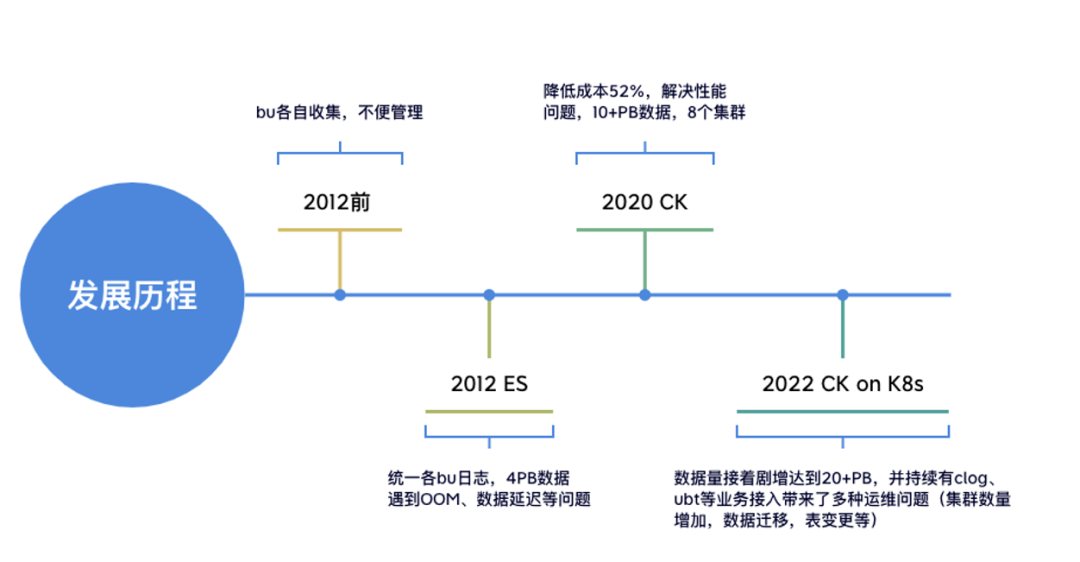

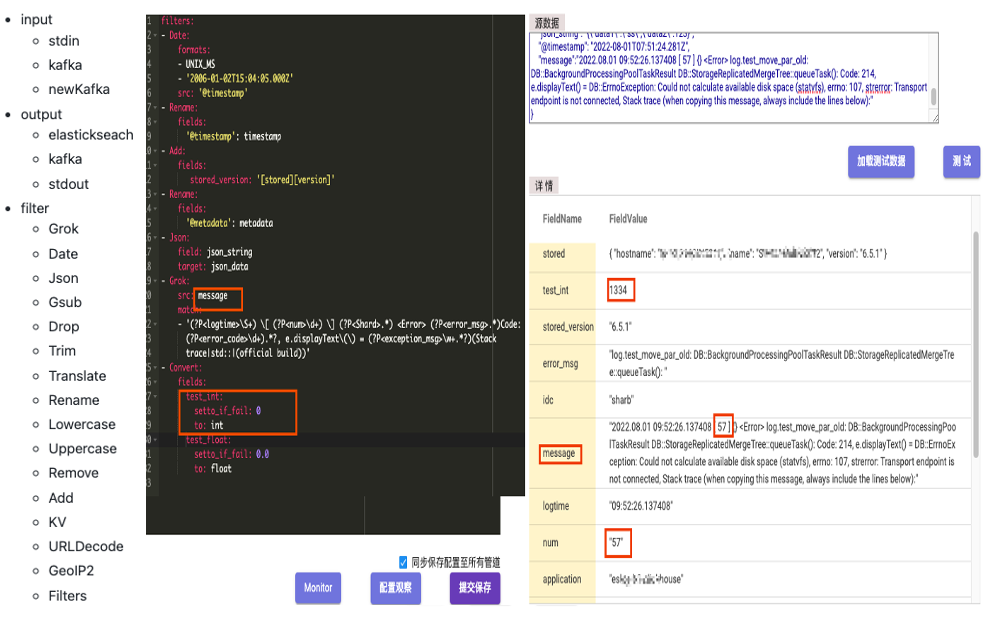
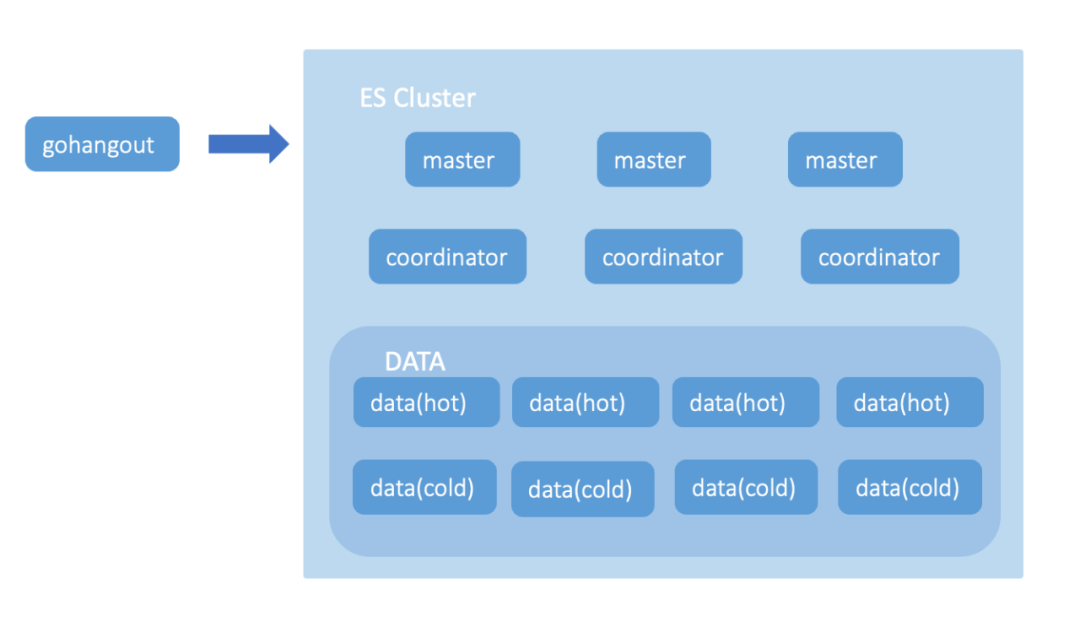
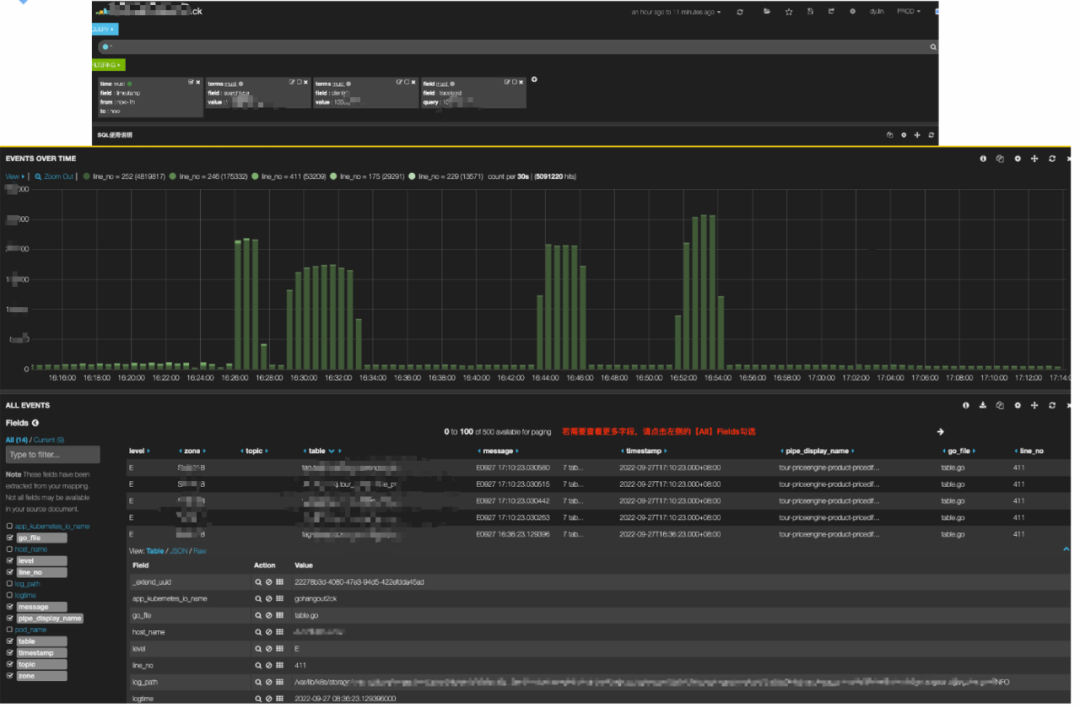
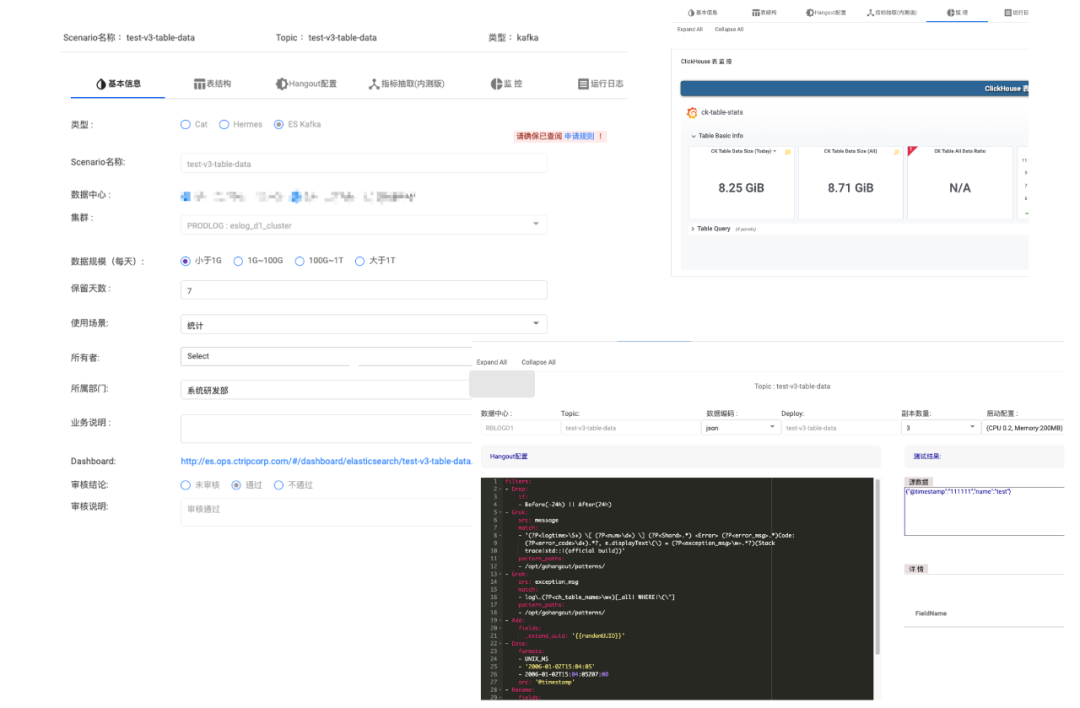
ElasticSearch 集群负载高,导致较多的请求 Reject、写入延迟和慢查询。 每天 200TB 的数据从热节点搬迁到冷节点,也有不少的性能损耗。 节点间负载不均衡,部分节点单负载过高,影响集群稳定性。 大查询导致 ElasticSearch 节点 OOM。
ElasticSearch的吞吐量也达到瓶颈。 查询速度受到整体集群的负载影响。
倒排索引导致数据压缩率不高。 大文本场景性价比低,无法保存长时间数据。
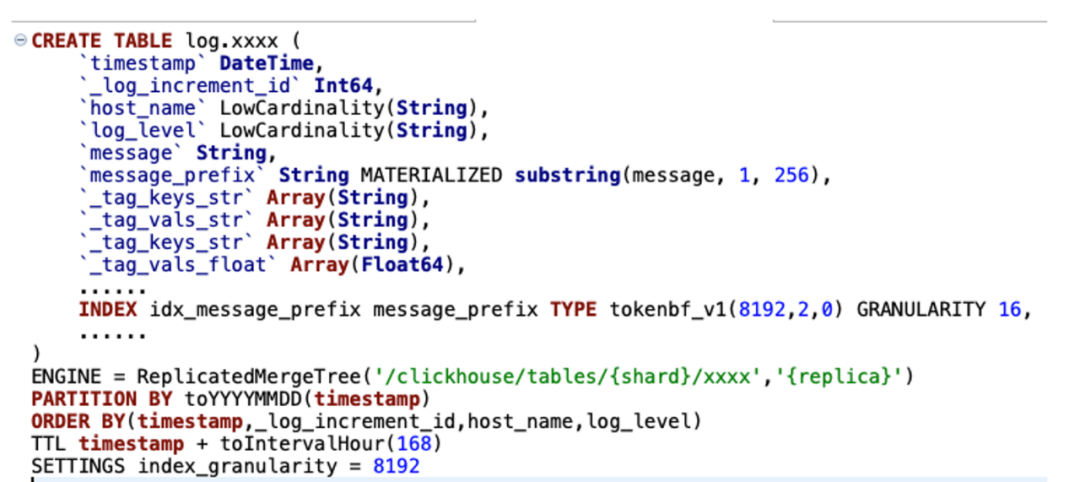 图13
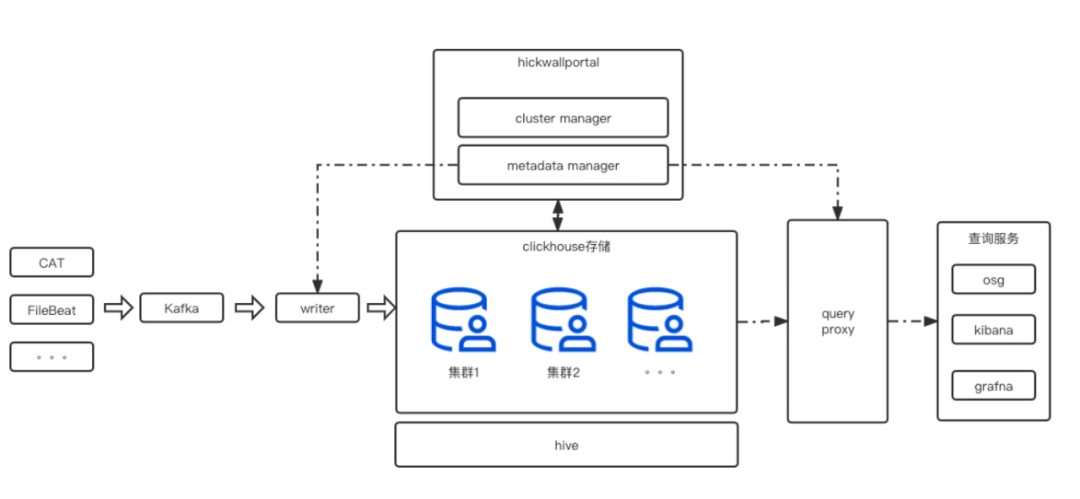
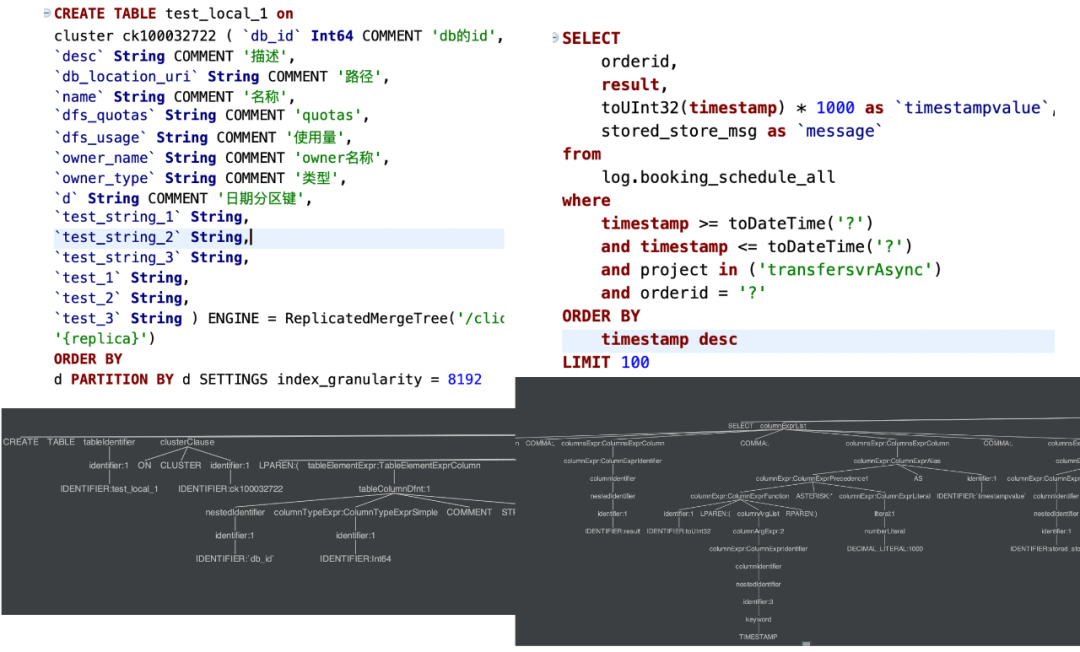
图13我们采用双 list 的方式来存储动态变化的 tags(当然最新的版本22.8,也可以用map和新特性的 json 方式)。 按天分区和时间排序,用于快速定位日志数据。 Tokenbf_v1 布隆过滤用于优化 term 查询、模糊查询。 _log_increment_id 全局唯一递增 id,用于滚动翻页和明细数据定位。 ZSTD 的数据压缩方式,节省了40%以上的存储成本。

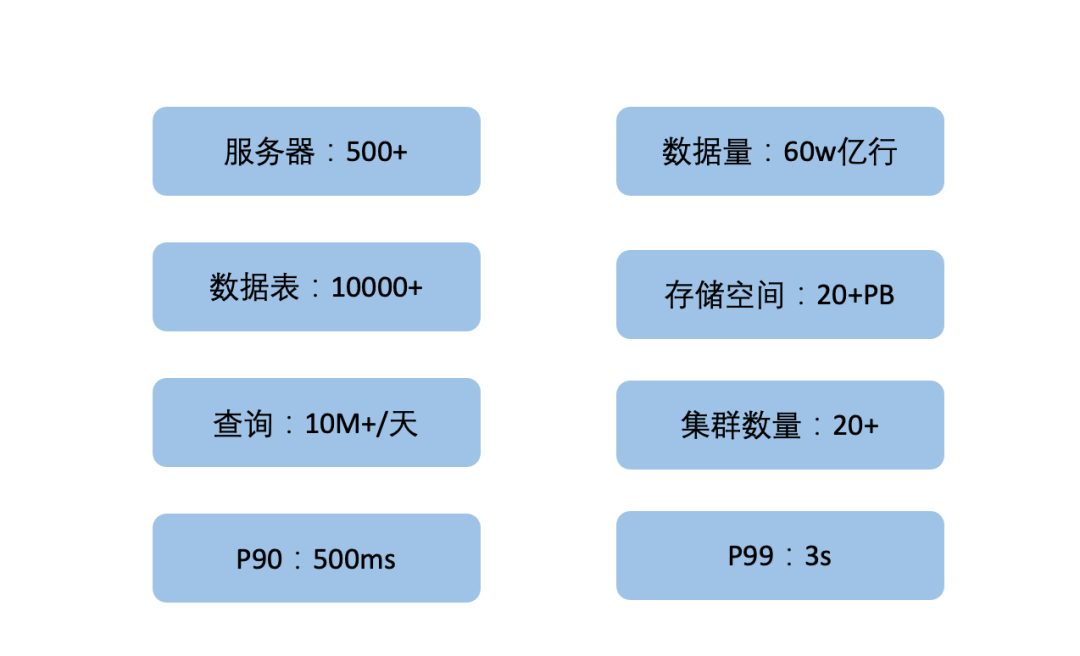
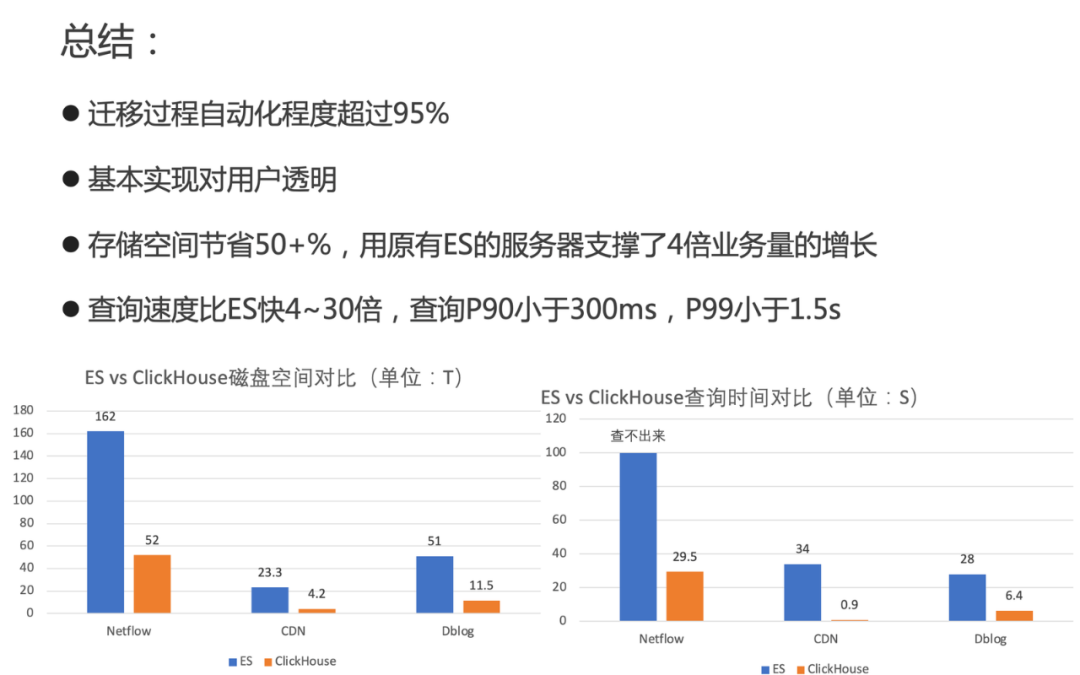
迁移过程自动化程度超过95%,基本实现对用户透明。 存储空间节约50+%(如图17),用原有ElasticSearch的服务器支撑了4倍业务量的增长。 查询速度比ElasticSearch快4~30倍,查询P90小于300ms,P99小于1.5s。
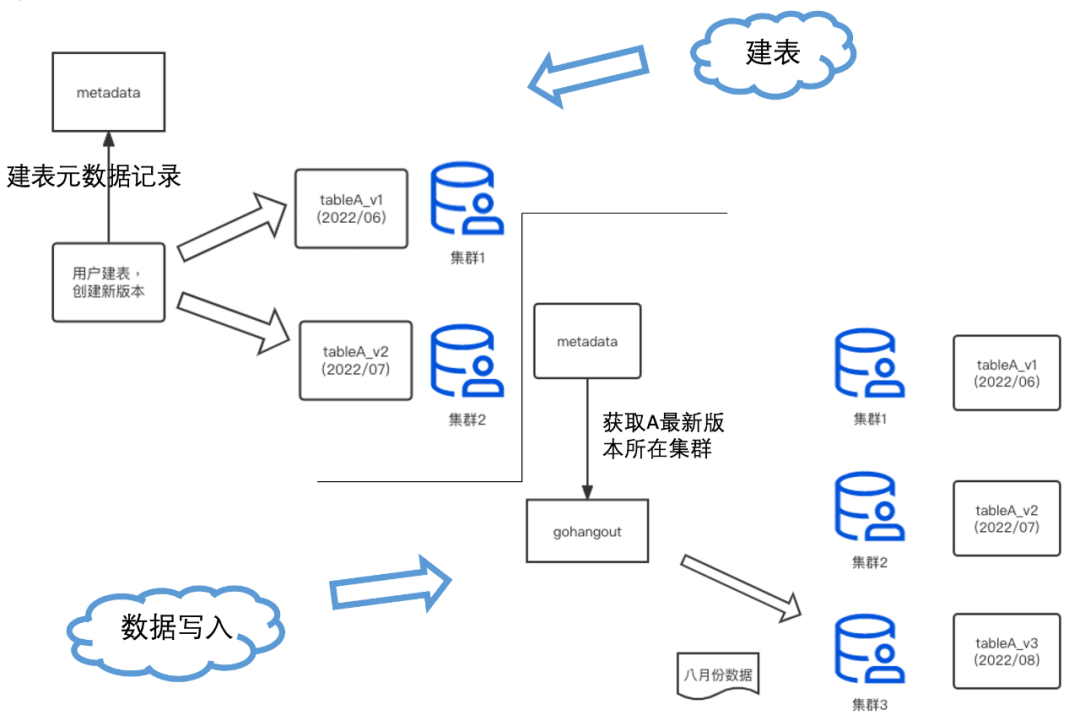
单集群规模太大,Zookeeper 性能达到瓶颈,导致 DDL 超时异常。 当表数据规模较大时,删除字段,容易超时导致元数据不一致。 用户索引设置不佳导致查询慢时,重建排序键需要删除历史数据,重新建表。 查询层缺少限流、防呆和自动优化等功能,导致查询不稳定。
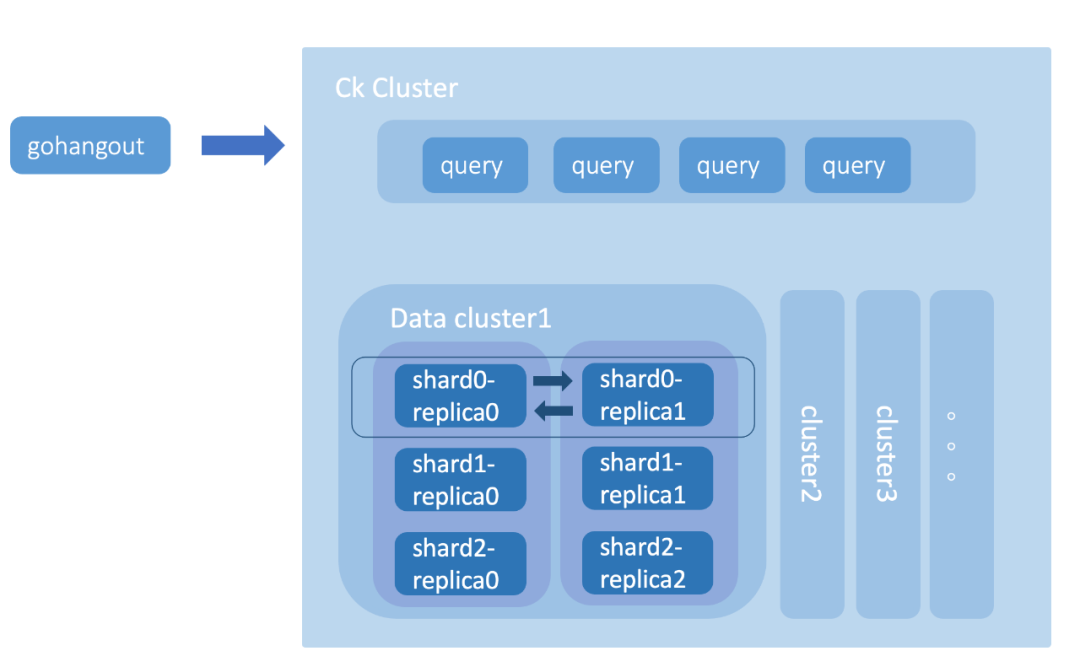
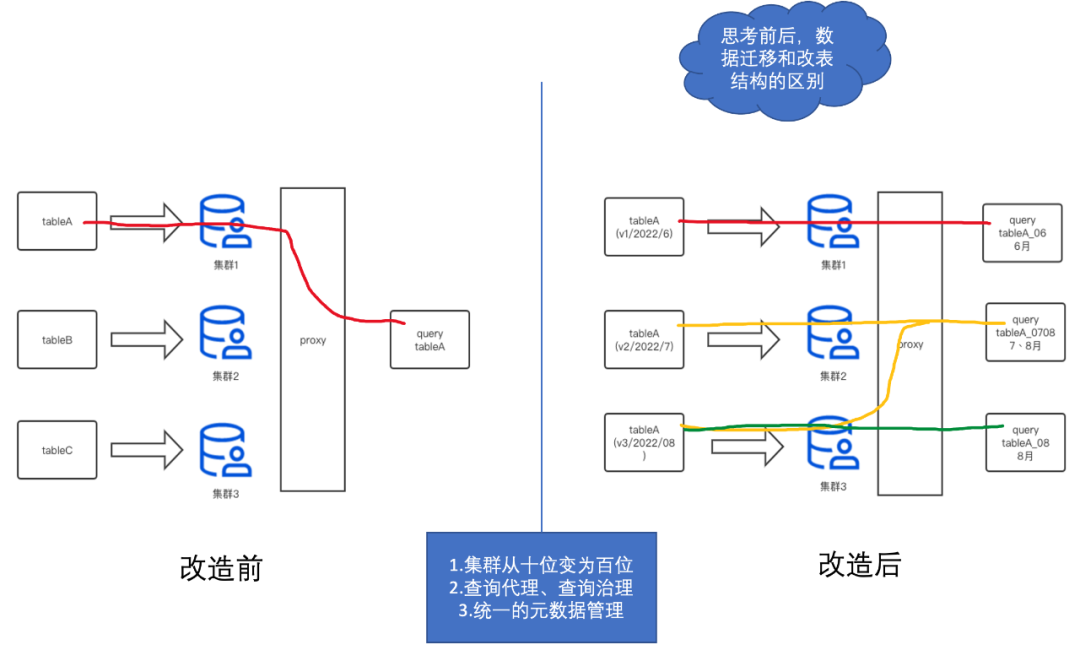
表与集群严格绑定,集群磁盘满后,只能通过双写迁移。 集群搭建依赖 Ansible,部署周期长(数小时)。 Clickhouse 版本与社区版本脱节,目前集群的部署模式不便版本更新。

“携程技术”公众号
分享,交流,成长
文章转载自携程技术,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
