




前言:
对于DBA来说,掌握数据库的各种特性是保证数据库性能稳定的重要前提之一;统计信息的准确性通常是我们日常运维的难题之一,如何保证统计信息的及时更新有效,而在此过程中是否会引起其他的问题?今天的分享给大家带来的CASE将展示此中隐患,同时通过CASE我们来看看我们如何使用trace文件的分析快速定位问题,并最终给出日常运维的几条建议。
不一样的任务
对于长期处于一线的DBA来说,处理性能故障的最好方式当然是登录到目标服务器,以飞快的手速查询各种性能视图,收集各种信息,然后再综合判断解决问题;然而,对于一些数据中心来说,如果作为远程支持,可能直接登录目标服务器就是一种奢望了,更多的是依赖客户能及时提供我们所想看到的信息来快速判断问题所在;
话说一天下午,某客户打电话要求远程支持,他们遇到的情况是这样的:
前一天,某系统在中午12点到1点前后出现过有几段时间数据库响应缓慢的情况,最后客户自己在简单判断之后通过重启应用解决了该问题,然后已经将帮助处理问题的“重要信息”发送到邮箱,需要我们帮忙协助核查为何会出现这样的情况,如何避免该情况再次发生。
客户的要求
对于我们日常运维而言,如果系统出现了短时夯或者响应缓慢,通常我们的第一要务是恢复业务,然而,为了能防止问题再次发生,我们需要存留相关信息来分析问题根因,那么在恢复业务前,如果可能,我们尽可能做到以下:
1) 通过建表的方式保留问题时段的gv$active_session_history信息
2) 在问题时段内做多次snapshot确保能生成一个全程为故障时间的AWR报告
3) 如果系统夯,收集systemstatedump/hanganalyze数据
4) 如果有可能,收集相关进程的processdump等
5) 保留问题时段oracle后台产生的各种trace/dump文件
客户这一次给过来的“重要文件”似乎只有background_dump_dest目录下的alert日志和trace文件,这对性能分析来说似乎是不够的,然而,再联系客户,客户自己还需要忙别的工作,同时,登录服务器取更多的信息发送过来在流程上也是一件非常麻烦的事,客户要求我们可以先通过已有的信息来分析,如果没有结论,可以随后一天到现场进行跟进。
trace是个好东西
简单翻看了alert日志,并没有什么特别的信息,不过,很幸运,数据库出现问题的时间段,oracle的dia0进程在判断系统出现性能存在问题时,产生了大量的dia0的trace文件,这些文件相当于在问题时刻对数据库做了一个hanganalyze操作,完全可以帮助我们初步定位问题的方向;看起来,虽然只有一些trace文件,但是只要有足够耐心,还是多少能从中找到一些端倪的,trace也是个好东西。
解读trace一点也不难
在数据库性能缓慢的时间段内,dia0进程产生了多个不同的trace文件,我们可以通过不同时间点的hang分析来定位数据库的性能问题原因;我们先选取其中一个trace文件进行分析;
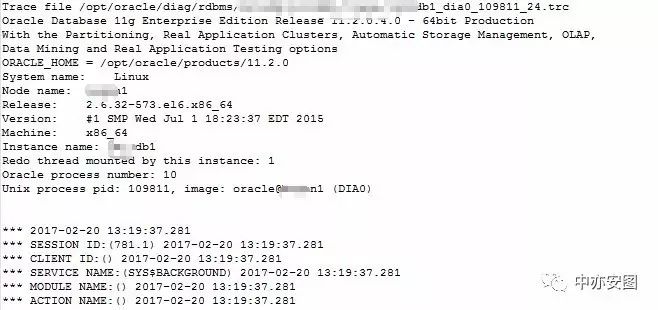
可以看到,这是dia0进程109811产生的一个trace文件,产生的时间点为问题时段的02-20的13:19左右;
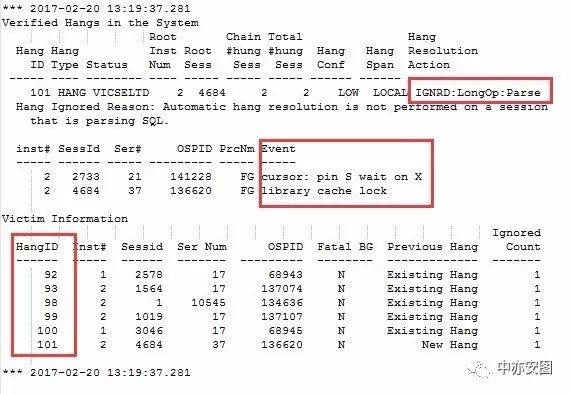
具体分析,可以先大概了解到hang的过程中受影响的操作是解析,最新的夯的等待事件是library cache lock;
接下来,简单看单个wait chain的详细情况如下:
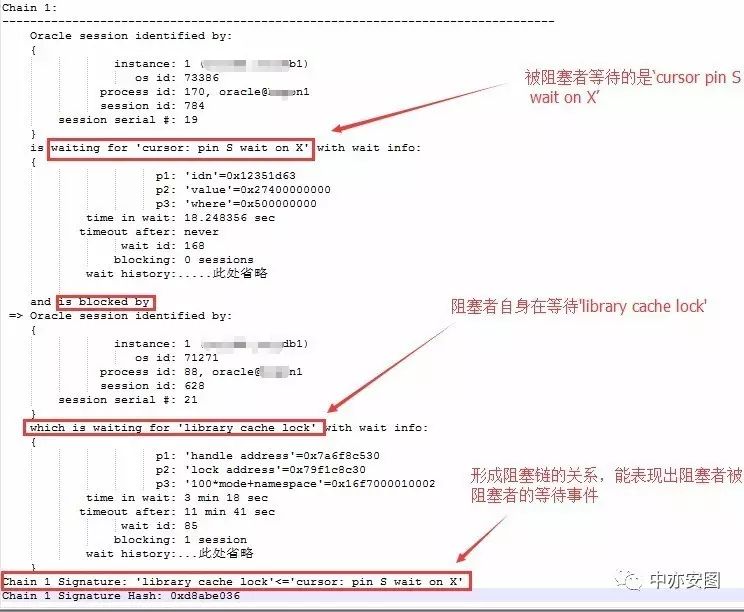
可以简单看到chain 1的阻塞者和被阻塞者的等待事件,最终简单的体现在Chain 1 Signature记录上;这样,我们通过关键字Signature来搜索显示整个trace文件中等待关系如下:
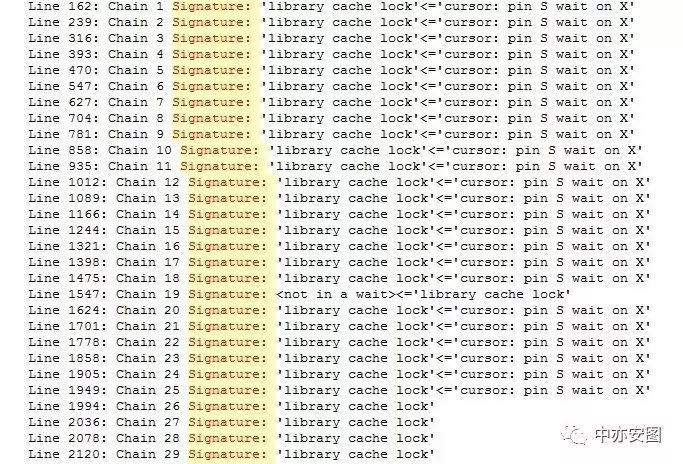
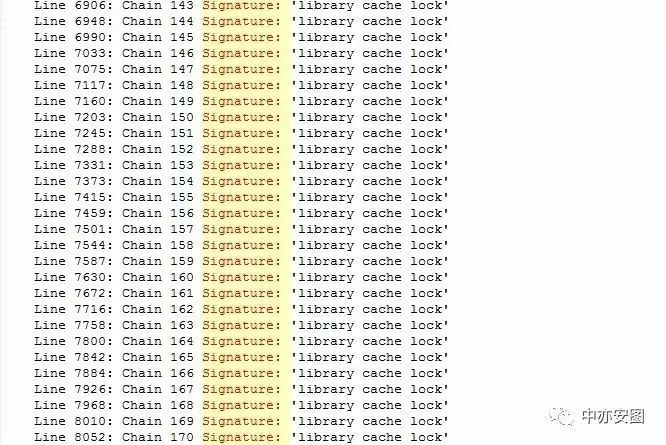
这里居然有170条等待链,而且从Signature中看,也基本没有出现多个等待链合并到其中某个等待链的情况;那么,这么多等待链,接下来我们需要怎样继续分析呢?亲爱的读者,不如停下来想想,这个时候需要些什么知识来帮助我们继续分析下去呢?如果是你,你会怎样继续呢?
~
~
~
~
熟悉的等待事件和等待关系
其实通过上述信息我们大致已经知道,数据库中问题时段的主要等待事件就是’cursor: pin S wait on X’和‘library cache lock’;有经验的读者朋友一定对这两个等待事件都并不陌生,而且在技术人生系列的之前的分享中,这两个等待事件也有专门介绍过,这里不妨我们再简单介绍一下两个等待事件:
‘cursorpin S wait on X’:一般出现在解析/编译时,当一个会话正在对某语句/某存储过程进行解析/编译时,会在对应的cursor上持有X模式的pin,而当有其他会话想要读取该cursor时,会请求S模式的pin,这时这些想读取cursor的会话将会出现’cursor:pin S wait on X’等待事件;其中p1标识涉及的cursor;
‘librarycache lock’:一般出现在涉及share pool中对象被修改时产生的竞争,涉及的对象包括表/索引/数据包等;其中p1标识竞争的对象句柄地址(handle address);
当我们看到Signature: 'library cachelock'<='cursor: pin S wait on X' 时不应该感到奇怪,出现这种情况通常可以理解为,当一个会话1解析某SQL/编译某procedure等时,它因为某些原因在等待’library cache lock’等待事件,而随后另一个会话2也需要执行同样的sql/procedure,因为会话1还正在解析,会话2 即产生了’cursor:pin S wait on X’等待事件;
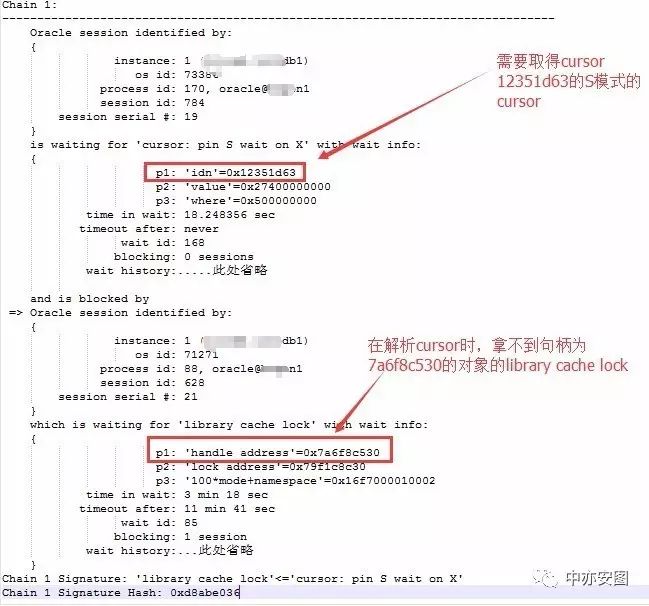
以chain1为例,可以看到1节点的会话784正在请求12351d63(16进制)的S模式的pin,而此时该pin的X模式持有者会话628则在解析/编译阶段出现了library cache lock等待,无法及时请求到7a6f8c530句柄上的library cache lock;
同样,当我们看到Signature: 'library cache lock'时就更简单了,只是某个会话正在解析时请求librarycache lock,而区别只是数据库中再没有其他会话在此时要求执行该解析的cursor而已。
那么,这里有两个问题:
1.系统在问题时段出现那么多'library cache lock'<='cursor: pin S wait on X'阻塞关系正常吗?
正常的!出现这么多不同的chain是因为各个chain涉及的cursor不相 同。
2.如上会话628又被谁阻塞了呢,这里为什么没有阻塞者呢?
不知道!没错,从这里看,会话628的阻塞者并不知道,同时,我们可以通过前面的chain信息搜索可以知道,绝大部分的library cache lock都没有找到阻塞者。
到这里,我们基本可以忽略’cursor:pin S wait on X’等待事件了,接下来需要解释的就是为什么会有library cache lock等待事件以及如何找到其阻塞者了。
恼人的librarycache lock
目前,我们开始关注library cache lock等待事件;诸多会话等待在library cache lock等待事件上,却又没有阻塞者,我们最重要的首先是需要确定各会话是否都等待在同一个对象上,如果是同一个对象,那我们只需要针对一个会话或一个对象进行分析即可。如何确定是否等待同一对象,前面的等待事件介绍中,我们知道p1是其唯一标识,那么我们在trace文件中简单搜索一下关键字“p1: 'handle address'=”即可:
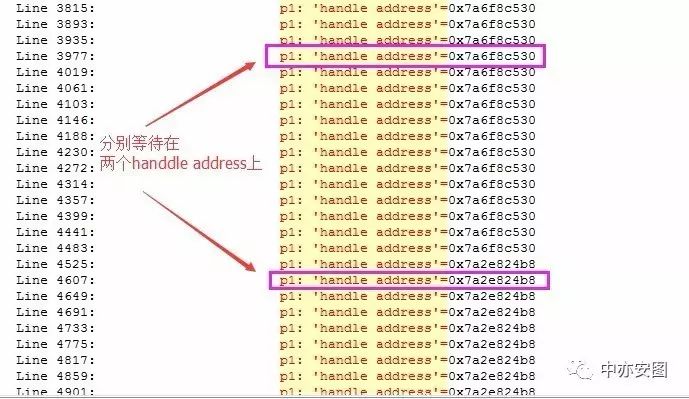
通过搜索结果可以看到,所有的等待分布在两个不同的handle address上,似乎是分布在两个不同的对象上;
两个对象,真的吗?不妨仔细确认一下:
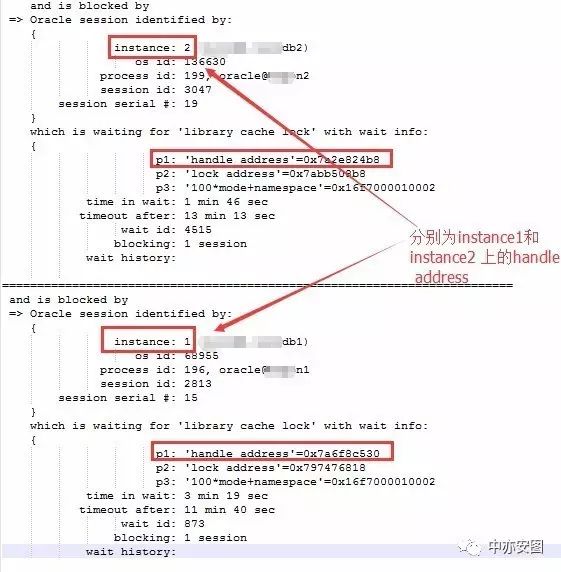
我们通过分别等待在两个不同handle address的对象的具体信息,可以看到,两个handle address事实上是分布在两个不同的实例上的;那么,相同对象在两个实例中的handle address有可能会不一致吗?当然!handle address作为一个地址信息,在不同的实例不一致也是理所当然的。所以这里,我们完全有理由怀疑事实上整个系统中等待library cache lock的会话都是等待在同一个对象上。
这里似乎好像提醒了我们一点,这是一个RAC数据库;那么,这里我们可以说,这么多library cache lock等待事件没有最终的阻塞者,是因为阻塞关系跨了RAC节点了才没有再dia0文件中打出来么?我也不知道,这恼人的library cache lock!
The special one
找不到出路时,我们不妨将我们看过的信息再仔细捋一捋,在那些经意和不经意间,我们总会发现一些我们可以看到的不一样的信息;这里,我们也是一样:
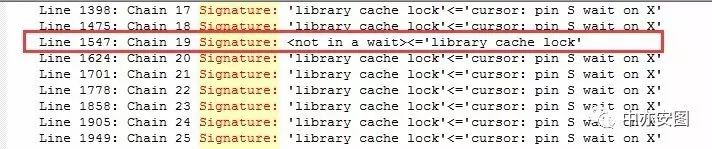
再看看我们的等待chain,在众多相似的chain中,存在独特的那一个chain 19,其中告诉我们有一个会话持有了library cache lock阻塞了另一个会话,我们不妨仔细来看看chain 19;

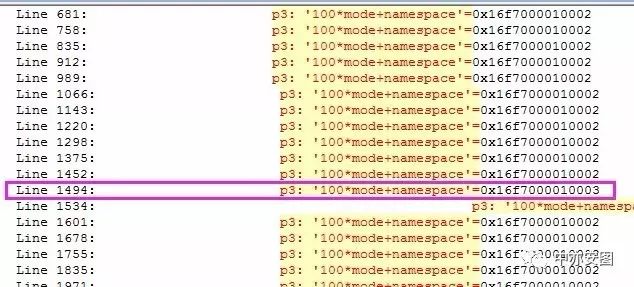
我们可以看到几个点:
跨节点的阻塞关系在这里被打印出来了,所以不存在跨节点的等待无法被dia0分析的情况;
我们发现session 4062请求library cache lock的p3与其他的会话不一致;
阻塞者session 5539长时间’not in a wait’,上一次等待已经是61分钟之前,这意味着会话5539已经持有library cache lock,并在CPU上运行了超过61分钟!基本可以确定是在做解析(以S模式持有library cache lock),而且解析过程中可能遭遇了bug(为什么不是在做DDL操作?因为做DDL操作最终还是要操作非常多的数据块,在长达60分钟的过程中不会不产生任何等待的!)
那这里,我们需要进一步了解的是library cache lock等待事件的p3值对我们又什么帮助,实际上这个值中包含了library cache中对象的类型信息等,不过,在这里我们暂时不关注那些,我们唯一需要知道的是,p3的最后一位实际上意味着请求library cache lock的模式,模式为2意味着shared,而模式为3意味着exclusived,也就是我们通常说的S模式和X模式;那么,什么情况下会以X模式请求librarycache lock 而什么情况下又会以S模式请求library cache lock呢?以请求的对象时表为例,通常,在解析涉及该表的语句时,会要以S模式请求该表的librarycache lock,而当需要对表做DDL操作时,因为表定义的变化,需要修改library cache中的信息,所以会需要以X模式请求library cache lock;同时,我们需要注意的容易忽略的一点是,在使用dbms_stats包操作表的统计信息时(如收集/删除/锁定等),虽然不会全程以X模式持有该表的librarycache lock,但是依然会在过程的某个极短时间范围中以X模式持有librarycache lock;
很显然一点,S模式和X模式的library cache lock也是互斥的。
从chain 19的关系来看,要想避免这个等待链的出现,我们应该怀疑两个点:
是什么情况会让一个会话持有library cache lock而后又长时间在CPU上运行达到61分钟不产生等待事件;
在生产时间段内,为什么会有会话要以X模式请求对象的library cache lock,是在修改表定义?是在收集统计信息?
以上两点,就需要通过视图取出相关的SQL来进行具体分析了,这里的trace已经无法提供更多的信息了;
最开始的疑惑和最后的疑惑
再一次,回到我们一直疑惑的问题,就是其他以S模式请求library cache lock的会话的阻塞者到底是谁呢?跟chain 19有关系吗?查了一圈MOS,似乎没有找到dia0文件中library cache lock等待无阻塞者的情况;不过,我们可以大胆的假设下面情况:
如chain 19所示,会话5539以S模式持有某对象的library cache lock,而会话4062因为DDL或收集统计信息以X模式请求该对象的library cache lock;
而第三个会话628再以S模式请求对象的library cache lock时,因为library cache lock也是作为一种LOCK来处理,有一个请求队列,当前面有4062会话在以X模式请求时,排在其后的会话628则认为4062会先请求到X模式的LOCK,于是此时,虽然数据库中只有会话以S模式持有对象的library cache lock,但是会话628仍然只能在等待;
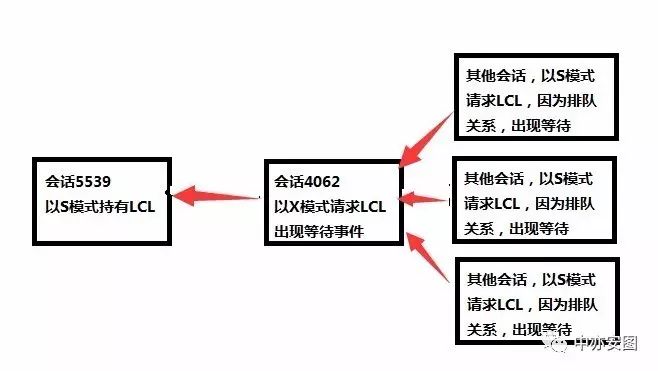
那么,如何验证这一点,我们可以注意的一个点是:
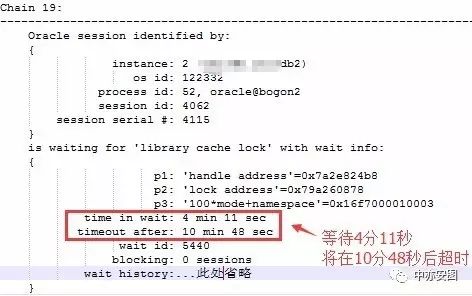
看到4062会话已经等待了4分11秒,如果我们上面的假设成立,那么其他会话的等待library cache lock的时间就不应该多于4分11秒;我们只要搜索关键字’time in wait:’即可:
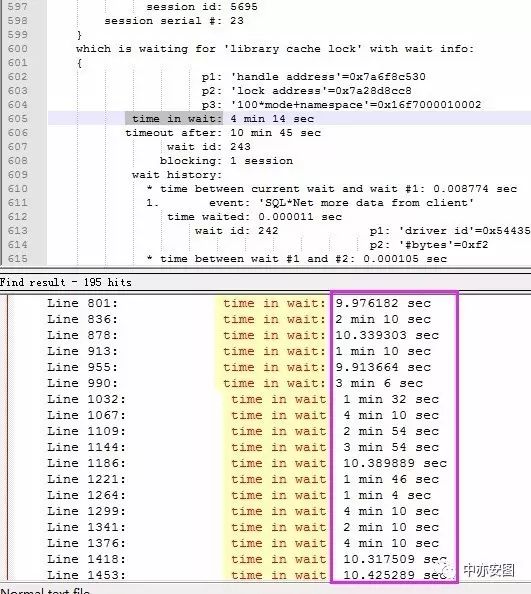
可以看到所有的其他等待都没有超过4分11秒的,所以,我们可以确认,在会话4062之前,系统中没有library cache lock等待,而且我们还确认了一点,那就是源头会话5539持有的library cache lock是S模式的,否则,就不需要4062会话,它一样可以阻塞非常多的其他会话。
还有最后一点点的疑惑,那就是客户说的,系统一段一段时间的慢,那么读到这里,读者朋友们应该会很清楚了,我们可以看到,library cache lock的等待会有一个超时时间,整个系统中以X模式请求library cache lock的会话并不多,此处,一旦4062会话等待超时,该会话则会退出,而其他会话则将继续解析,并执行成功;而类似4062会话的操作可能会在一段时间后重新来做;而在重启应用之后,5539会话也就消失了,即使再有4062这样的会话存在,也不会大规模的影响其他会话的正常执行,这也就是其最终恢复的原因了。
抛回给客户的信息
至此,我们通过分析trace文件,已经能得出基本结论,但是还有几个点需要由客户执行相关的SQL进行核查确认;在与客户微信沟通后我们的推断都得到了验证:
关于两个library cache lock的handle address指向的是否同一个对象?
是的,通过x$kglobj基表分别在两个节点查询即可确认,并且确认为一个应用表;
会话4062(以X模式请求library cache lock)在做什么?
通过历史视图查询其执行的SQL可以知道,该会话在收集表的统计信息,而且为定期收集;
会话5539(以S模式持有library cache lock长达60分钟)在做什么?
通过历史视图查询其执行的情况可以确认,该会话当时正在解析一个从JDBC连接过来的拼接出来的超长SQL,遭遇bug,篇幅限制,此处不再赘述。
给我们的警示
这里,我们看看能给我们的警示是什么呢?这里看上去根源是5539会话遭遇的bug,但是我们从分析来看,如果没有4062这样的会话执行的操作,我们事实上在整个系统中也就只有5539会话本身会比较慢而已;
为什么客户会比较频繁的来收集表统计信息呢,原来,客户收集的这个表会在每天清空,而后在第二天上午有足够数据时,开始使用crontab的方式定期收集,这次,因为遭遇了5539会话的超长SQL而导致了问题;
那么,对于此种场景我们的建议是什么呢?
针对某些业务场景,我们建议使用锁定统计信息的方式来保证统计信息的有效性;
如果某些特殊场景,无法使用前期的统计信息,我们建议在原来lock的统计信息的寄出上使用dbms_stats包的set相关procedure来修正统计信息值;
总之,如果不是到迫不得已的情况,我们不建议在业务高峰期间频繁收集统计信息。
最后,如果您觉得读文章还有所收获,不如像我们一样转发分享吧,您的转发是我们持续分享最大的动力。






