




直接查询 Apache Parquet[1] 文件中的数据可以获得与大多数专用文件格式相似或更好的存储效率和查询性能。虽然需要大量工程工作,但 Parquet 的开放格式和广泛的生态系统支持的优势使其成为各种数据系统的明显选择。在本文中,我们解释了在 Apache Arrow Rust Parquet 读取器[2]中实现的快速查询以 Parquet 格式存储的数据所需的几种高级技术。这些技术共同使 Rust 的实现成为查询 Parquet 文件的最快实现之一 —— 无论是在本地磁盘还是远程对象存储上。它能够在几毫秒内[3]查询 GB 的 Parquet。
背景
Apache Parquet 是一种越来越流行的用于存储分析数据集的开放格式,并且已成为具有成本效益的、与 DBMS 无关的数据存储的事实标准。Parquet 最初是为 Hadoop 生态系统创建的,现在由于其引人注目的组合而广泛扩展到整个数据分析生态系统:
• 高压缩比
• 适合商品 blob 存储,例如 S3
• 广泛的生态系统和工具支持
• 跨许多不同平台和工具的可移植性
• 支持任意结构化数据[4]
越来越多的其他系统,如 DuckDB[5] 和 Redshift[6] 允许直接查询存储在 Parquet 中的数据,但与它们的自定义文件格式相比,支持仍然是次要优先级,此类格式包括 DuckDB .duckdb 文件格式、Apache IOT TsFile[7]、Gorilla 格式[8]等。
访问相同的复杂查询技术,以前只能在闭源商业实现中使用,现在可以作为开源使用。所需的工程能力来自具有全球贡献者社区的运行良好的大型开源项目,例如 Apache Arrow[9] 和 Apache Impala[10]。
Parquet文件格式
在深入了解从 Parquet 高效读取的细节之前了解文件布局很重要。文件格式经过精心设计,可快速定位所需信息,跳过无关部分,并有效解码剩余部分。
• Parquet 文件中的数据被分成称为 RowGroup 行组的水平切片
• 每个 RowGroup 都为 Schema 中的每一列包含一个 ColumnChunk
例如下图说明了一个 Parquet 文件,其中三列“A”、“B”和“C”存储在两个 RowGroup 中,总共有 6 个 ColumnChunk。
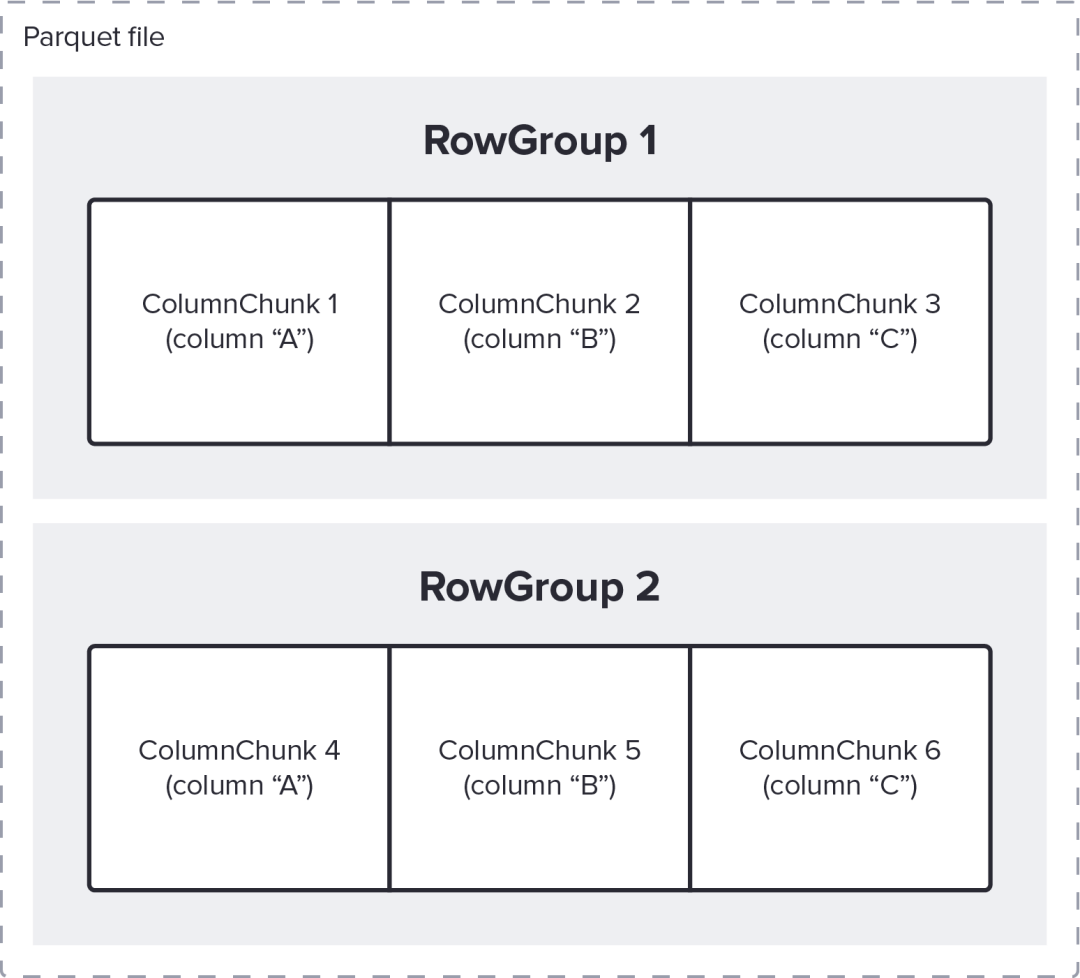
ColumnChunk 的逻辑值使用许多可用编码[11]中的一种写入到一个或多个数据Page中,这些数据页按顺序附加在文件中。Parquet 文件的末尾是页脚,其中包含重要的元数据,例如:
• 文件的Schema信息,例如列名和类型
• RowGroup 和 ColumnChunks 在文件中的位置
页脚还可能包含其他专门的数据结构:
• 每个 ColumnChunk 的可选统计信息,包括最小值/最大值和空值数
• 指向包含每个页面位置的 OffsetIndexes 的可选指针
• 指向 ColumnIndex 的可选指针,其中包含每个 Page 的行数和摘要统计信息
• 指向 BloomFilterData 的可选指针,它可以快速检查某个值是否存在于 ColumnChunk 中
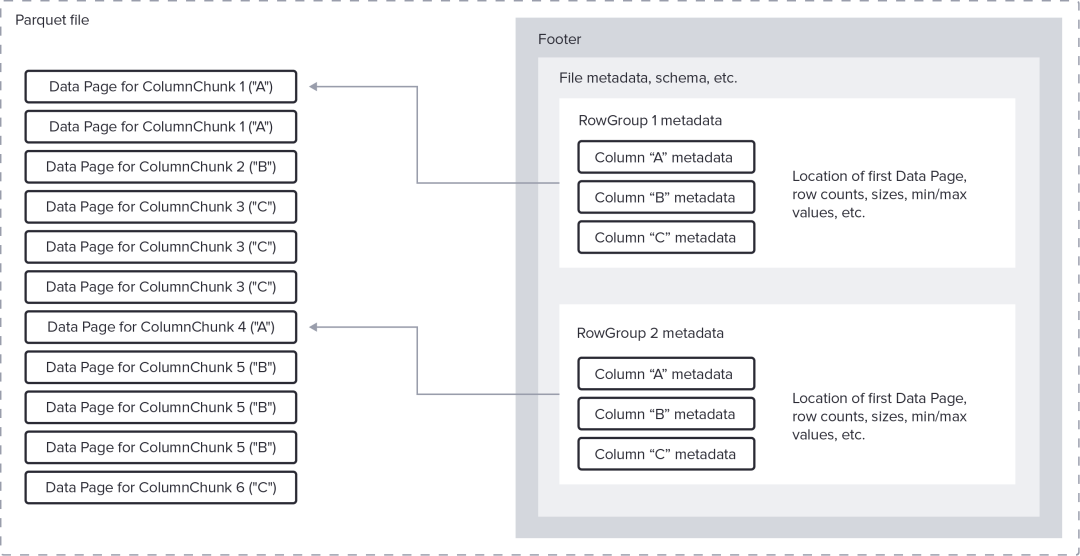
例如上图中 2 个 Row Groups 和 6 个 ColumnChunks 的逻辑结构如下图所示存储在 Parquet 文件中, ColumnChunks 的 数据 Page 页首先出现,然后是页脚。数据、编码方案的有效性和 Parquet 编码器的设置决定了每个 ColumnChunk 所需的Page数量和大小。在这种情况下,ColumnChunk 1 需要 2 个Page,而 ColumnChunk 6 只需要 1 个Page。除其他信息外,页脚还包含每个数据页的位置和列的类型。
创建 Parquet 文件时需要考虑许多重要标准,例如如何优化排序/聚簇数据并将其结构化为RowGroup行组和数据Page页。这种“物理设计”的考虑很复杂,本文不予讨论。本文专注于如何使用可用的结构来非常快速地进行查询。
优化查询
在任何查询处理系统中,以下技术通常可以提高性能:
1. 减少必须从存储传输以进行处理的数据(减少 I/O)
2. 减少解码数据的计算量(减少 CPU)
3. 交织/流水线数据的读取和解码(提高并行性)
相同的原则适用于查询 Parquet 文件,如下所述
解码优化
Parquet 通过使用复杂的编码技术[12](例如游程压缩、字典编码、增量编码等)实现了令人印象深刻的压缩比。因此受 CPU 限制的解码任务可以控制查询延迟。Parquet 读取器可以使用多种技术来改善此任务的延迟和吞吐量,就像在 Rust 实现中所做的那样。
向量化解码
大多数分析系统一次将多个值解码为列式内存格式,而不是逐行处理数据,例如 Apache Arrow。这通常称为向量化或列式处理,该处理是有益的,因为它:
• 分摊调度开销以切换正在解码的列的类型
• 通过从 ColumnChunk 中读取连续的值来改进缓存局部性
• 通常允许在一条指令中解码多个值
• 使用单个大分配避免许多小堆分配,从而为字符串和字节数组等可变长度类型节省大量开销
因此 Rust Parquet Reader 实现了专门的解码器,用于将 Parquet 直接读入列式内存格式[13](Arrow 数组)。
流式解码
跨 ColumnChunks 的哪些行存储在哪些 Pages 之间没有关系。例如第 10,000 行的逻辑值可能位于 A 列的第一页和 B 列的第三页。矢量化解码的最简单方法,也是最初通常在 Parquet 解码器中实现的方法,是一次解码整个 RowGroup(或 ColumnChunk)。然而考虑到 Parquet 的高压缩率,单个 RowGroup 很可能包含数百万行。一次解码这么多行不是最优的,因为它:
• 需要大量中间 RAM:针对处理进行了优化的典型内存格式(例如 Apache Arrow)需要的远远超过其 Parquet 编码形式。
• 增加查询延迟:后续处理步骤(如过滤或聚合)只能在整个 RowGroup(或 ColumnChunk)被解码后才能开始。
因此最好的 Parquet 读取器支持通过按需生成可配置大小的行批次来“流式传输”数据。批处理大小必须足够大以分摊解码开销,但又要足够小以实现高效内存使用并允许下游处理在解码后续批处理的同时开始。
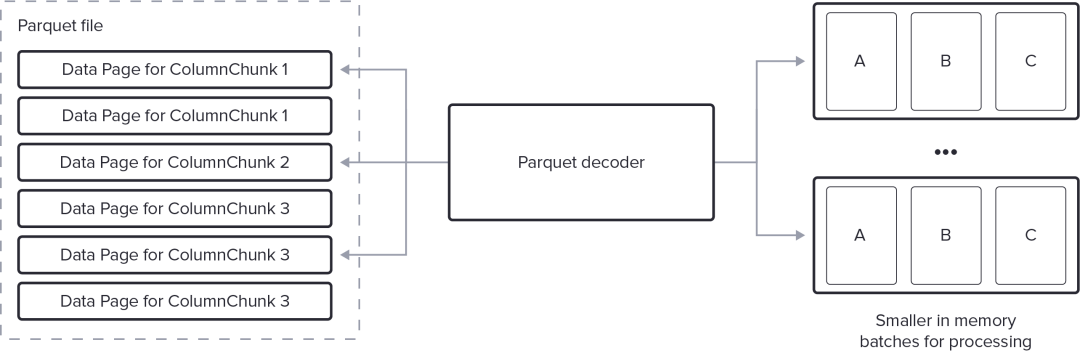
虽然流式传输不是一个解释起来复杂的特性,但解码的状态性质,尤其是跨多列和任意嵌套数据,其中行和值之间的关系不固定,需要复杂的中间缓冲和大量的工程工作才能正确处理。
字典编码
字典编码,也称为分类[14]编码,是一种技术,其中不直接存储列中的每个值,而是存储称为“字典”的单独列表中的索引。对于具有重复值(低基数[15])的列,此技术实现了第三范式[16]的许多好处,并且对于字符串列(例如“City”)特别有效。
ColumnChunk 中的第一页可以选择是字典页,包含列类型的值列表。此 ColumnChunk 中的后续页可以将索引编码到此字典中,而不是直接对值进行编码。
考虑到这种编码的有效性,如果 Parquet 解码器简单地将字典数据解码为本机类型,它将一遍又一遍地低效地复制相同的值,这对于字符串数据来说是灾难性的。为了有效地处理字典编码的数据,必须在解码期间保留编码。方便的是,许多列式格式(例如 Arrow DictionaryArray[17])都支持此类兼容编码。
保留字典编码可显着提高读取 Arrow 数组时的性能,在某些情况下性能提高超过 60 倍[18],并且使用的内存也显着减少。
保留字典的主要复杂因素是字典是按 ColumnChunk 存储的,因此字典在 RowGroup 之间发生变化。读取器必须自动为跨越多个行组的批次重新计算字典,同时还针对批次大小均匀划分为每个行组的行数的情况进行优化。此外,列可能只是部分字典编码[19],进一步复杂化实现。有关此技术的更多信息请参阅有关将此技术应用于 C++ Parquet 阅读器的博客文章[20]。
投影下推
最基本的 Parquet 优化,也是对 Parquet 文件最常描述的优化,是投影下推,减少 I/O 和 CPU 。在这种情况下,投影意味着“选择一些但不是所有的列”。考虑到 Parquet 组织数据的方式,只读取和解码引用列所需的 ColumnChunks 是很简单的。例如考虑以下形式的 SQL 查询
SELECT B from table where A > 35
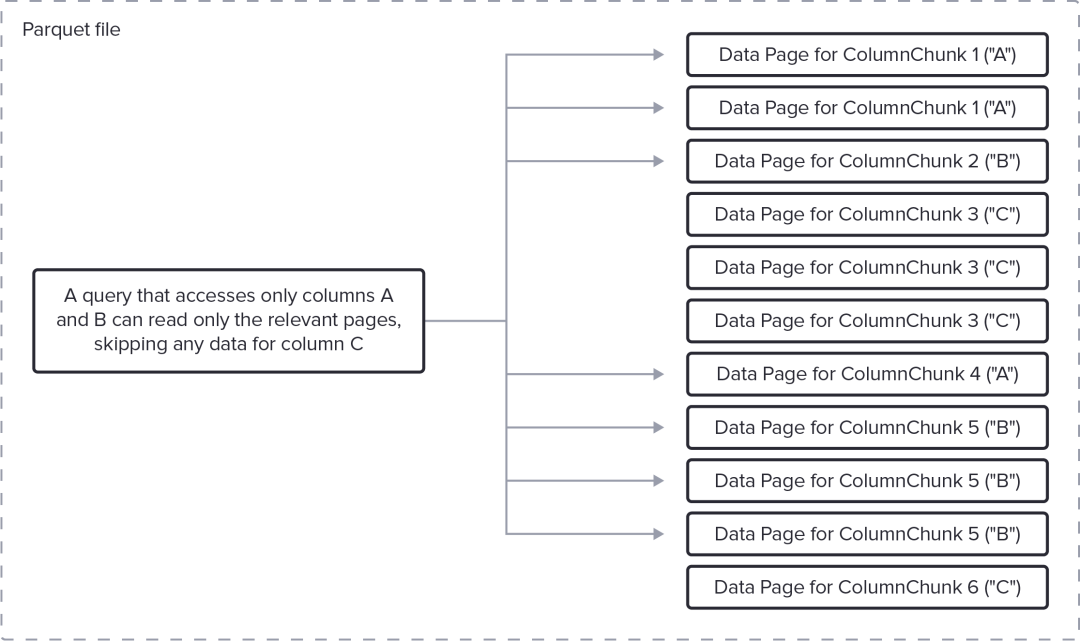
此查询只需要 A 列和 B 列(而不是 C)的数据,并且投影可以“下推”到 Parquet 读取器。
具体来说,使用页脚中的信息,Parquet 读取器可以完全跳过为 C 列(我们的示例中的 ColumnChunk 3 和 ColumnChunk 6)存储数据的数据页的提取 (I/O) 和解码 (CPU)。
谓词下推
与投影下推类似,谓词下推也避免了从 Parquet 文件中获取和解码数据,而是使用过滤器表达式来实现。这种技术通常需要与 DataFusion[21] 等查询引擎更紧密地集成,以确定有效的谓词并在扫描期间对其进行评估。不幸的是如果没有仔细的 API 设计,Parquet 解码器和查询引擎最终可能会紧密耦合,从而阻止重用(例如,在 Cloudera Parquet Predicate Pushdown 文档[22]中有不同的 Impala 和 Spark 实现)。Rust Parquet 阅读器使用 RowSelection[23] API 来避免这种耦合。
RowGroup行组裁剪
许多基于 Parquet 的查询引擎都支持谓词下推的最简单形式,它使用存储在页脚中的统计信息来跳过整个行组。我们称此操作为 RowGroup 裁剪,它类似于许多经典数据仓库系统中的分区裁剪[24]。
对于上面的示例查询,如果特定 RowGroup 中 A 的最大值小于 35,则解码器可以跳过从整个 RowGroup 中提取和解码任何 ColumnChunks。
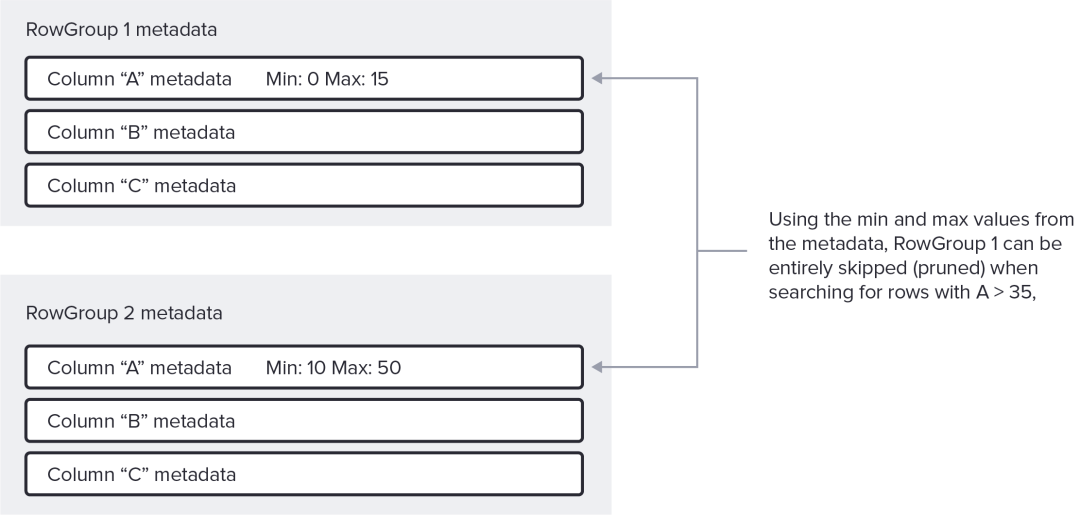
请注意,裁剪最小值和最大值对许多数据布局和列类型都有效,但并非全部。具体来说,它对于具有许多不同的伪随机值(例如标识符或 uuid)的列不是那么有效。值得庆幸的是,对于这个用例,Parquet 还支持每个 ColumnChunk Bloom Filters[25]。我们正在积极致力于在 Apache Rust 的实现中添加布隆过滤器支持[26]。
Page页裁剪
一种更复杂的谓词下推形式使用页脚元数据中的可选页索引来排除整个数据页。解码器仅解码来自其他列的相应行,通常会跳过整个页。
由于各种原因,不同 ColumnChunk 中的页面通常包含不同数量的行,这一事实使这种优化变得复杂。虽然页索引可以从一列中识别出所需的页,但从一列中修剪页并不会立即排除其他列中的整个页。
页裁剪过程如下:
• 结合使用谓词和页索引来识别要跳过的页
• 使用偏移量索引来确定哪些行范围对应于未跳过的页
• 计算跨非跳过页的范围的交集,并仅解码那些行
最后一点实现起来非常重要,特别是对于单行可能对应多个值的嵌套列表[27]。幸运的是,Rust Parquet 读取器在内部隐藏了这种复杂性,并且可以解码任意 RowSelections[28]。
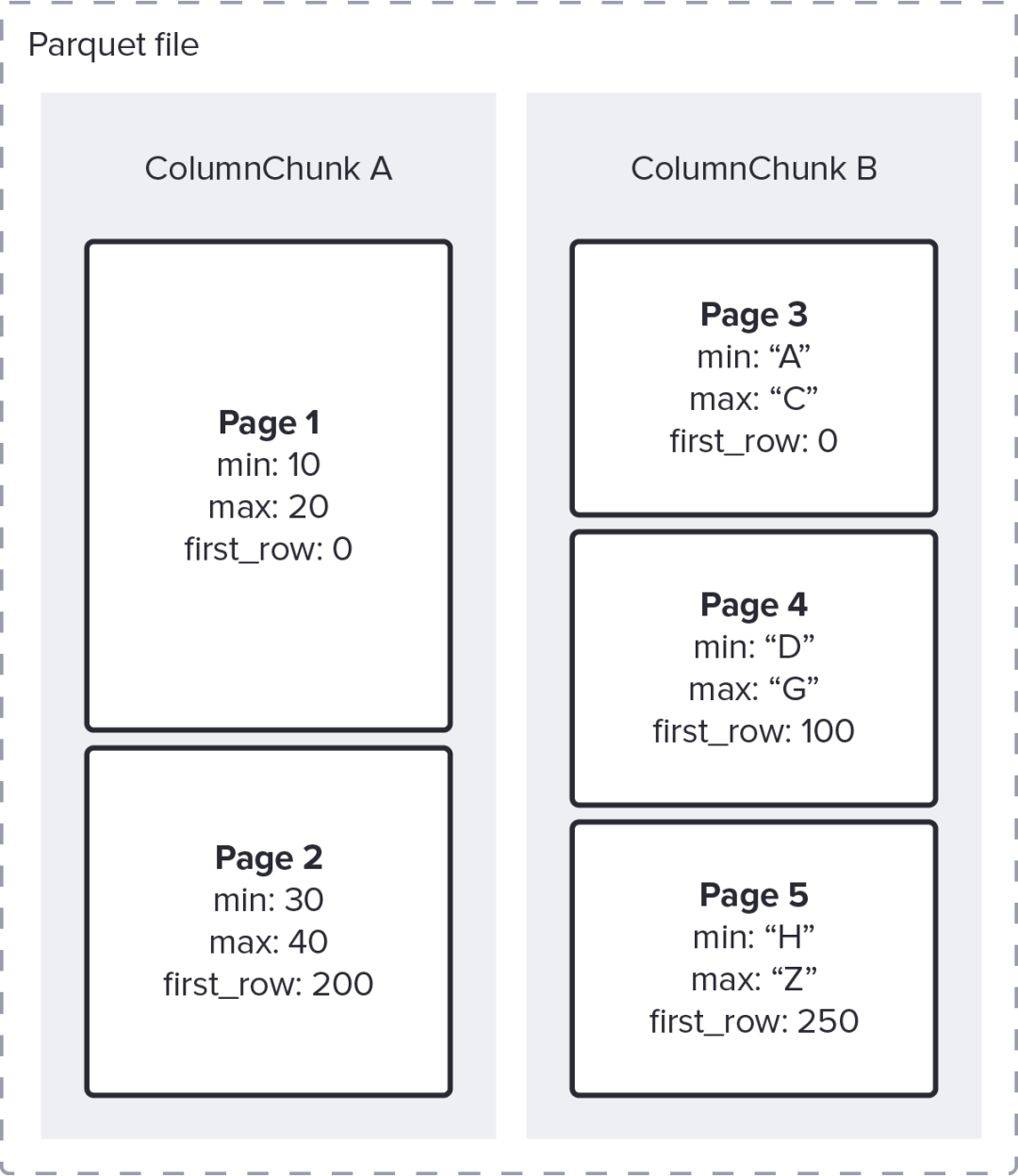
例如扫描A列和B列,分别存储在5个数据页中,如下图:
如果谓词是 A > 35,
• 使用页索引(最大值为 20)裁剪第 1 页,留下 [200->onwards] 的 RowSelection,
• Parquet 读取器完全跳过第 3 页(因为它的最后一行索引是 99)
• (仅)通过读取第 2、4 和 5 页来读取相关行
如果谓词改为 A > 35 AND B = "F" 页面索引会更有效
• 使用 A > 35,像以前一样产生 [200->onwards] 的 RowSelection
• 在 B 的剩余第 4 页和第 5 页上使用 B = "F",产生 [100-244] 的 RowSelection
• 将两个 RowSelection 相交留下组合的 RowSelection [200-244]
• Parquet 读取器仅解码第 2 页和第 4 页中的那 50 行
在 PARQUET-1404[29] 中跟踪支持从 Arrow C++ 以及扩展 pyarrow/pandas 读取和写入这些索引。
延迟物化
前两种形式的谓词下推仅在解码值之前对为 RowGroups、ColumnChunks 和数据页存储的元数据进行操作。然而,相同的技术也可以扩展到一个或多个列的值在解码之后但在解码其他列之前,这通常被称为“延迟物化”。这种技术在以下情况下特别有效:
• 谓词是非常有选择性的,即过滤掉大量的行
• 每行都很大,要么是因为行很宽(例如 JSON blob),要么是因为列很多
• 所选数据聚集在一起
• 谓词所需的列解码起来相对便宜,例如 原始数组/字典数组
在 SPARK-36527[30] 和 Impala[31] 中还有关于此技术优势的其他讨论。
例如,给定上面的谓词 A > 35 AND B = "F",其中引擎使用页面索引来确定 [100-244] 的 RowSelection 中只有 50 行可以匹配,使用延迟物化,Parquet 解码器:
• 解码 A 列的 50 个值
• 在这 50 个值上评估 A > 35
• 在这种情况下,只有 5 行通过,导致 RowSelection:
• 行选择[205-206]
• 行选择[238-240]
• 仅解码这些选择的 B 列的 5 行

在某些情况下,例如我们的 B 存储单个字符值的示例,延迟物化机制的成本可能超过解码节省的成本。但是当满足上面列出的某些条件时,可以节省大量开销。查询引擎必须决定下推哪些谓词以及以何种顺序应用它们以获得最佳结果。
虽然它超出了本文档的范围,但可以将相同的技术应用于多个谓词以及多个列上的谓词。有关详细信息,请参阅 Parquet crate 中的 RowFilter[32] 接口,以及 DataFusion 中的 row_filter[33] 实现。
I/O 下推
虽然 Parquet 是为在 HDFS 分布式文件系统上进行高效访问而设计的,但它与对象存储系统(如 AWS S3)配合得很好,因为它们具有非常相似的特征:
• 相对较慢的“随机访问”读取:在每个请求中读取大 (MB) 数据部分比发出许多小部分数据请求更有效
• 检索第一个字节之前的显着延迟
• 每次请求高成本:通常按请求计费,无论读取的字节数如何,尽量减少读取请求次数,每次请求读取大量连续数据。
要从此类系统中以最佳方式读取,Parquet 读取器必须:
1. 尽量减少 I/O 请求的数量,同时应用各种下推技术来避免获取大量无用的数据。
2. 与适当的任务调度机制集成,以交错 I/O 和对获取的数据进行处理,以避免管道瓶颈。
由于这些是巨大的工程和集成挑战,许多 Parquet 读取器仍然需要将文件完整地提取到本地存储。出于以下几个原因,获取整个文件以处理它们并不理想:
1. 高延迟:在获取整个文件之前无法开始解码(Parquet 元数据位于文件末尾,因此解码器必须在解码其余部分之前看到末尾)
2. 开销大:获取整个文件会获取所有必要的数据,但也可能会获取许多不必要的数据,这些数据将在阅读页脚后被跳过。这不必要地增加了成本。
3. 需要昂贵的“本地附加”存储(或内存):许多云环境不提供具有本地附加存储的计算资源——它们要么依赖昂贵的网络块存储,例如 AWS EBS,要么将本地存储限制在某些类别的 VM 上。
避免缓存整个文件的需要需要一个复杂的 Parquet 解码器,与 I/O 子系统集成,它可以首先获取和解码元数据,然后是相关数据块的范围获取,与 Parquet 数据的解码交错。这种优化需要仔细的工程设计,以从对象存储中获取足够大的数据块,从而使每个请求的开销不会超过减少传输字节数带来的收益。 SPARK-36529[34] 更详细地描述了顺序处理的挑战。
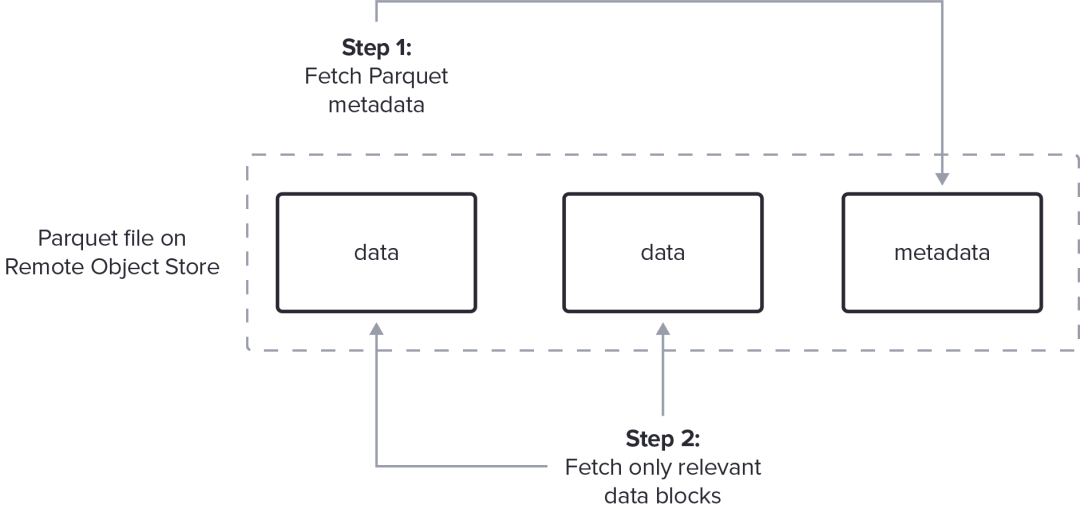
此图表中未包含合并请求和确保实际实施所需的最小请求大小等详细信息。
Rust Parquet crate提供了一个异步 Parquet 读取器,可以有效地从任何 AsyncFileReader[35] 读取:
• 从支持范围请求的任何存储介质中高效读取
• 与 Rust 的 futures 生态系统集成以避免阻塞等待网络 I/O 的线程,并且可以轻松地交错 CPU 和网络[36]
• 同时请求多个范围,以允许实现合并相邻范围、并行获取范围等
• 使用前面描述的下推技术尽可能避免获取数据
• 与 Apache Arrow object_store[37] crate 轻松集成,您可以在此[38]处阅读更多信息
为了了解可能发生的情况,下图显示了从远程文件获取页脚元数据、使用该元数据确定要读取的数据页、然后同时获取数据和解码的时间线。为了匹配网络延迟、带宽和可用 CPU,通常必须一次对多个文件执行此过程。

结论
希望您喜欢阅读 Parquet 文件格式以及用于快速查询 Parquet 文件的各种技术。Parquet 的大多数开源实现不具备本文中描述的所有功能的原因是它需要付出巨大的努力和成本,而这在以前只有资金雄厚的商业企业才有可能实现,这些企业将其实现闭源。
然而随着 Apache Arrow 社区、Rust 从业者和更广泛的 Arrow 社区的发展和质量的提高,我们协作和构建顶尖开源实现的能力令人振奋且非常令人满意。本博客中描述的技术是许多工程师在公司、爱好者和世界各地的多个存储库中贡献的结果,特别是 Apache Arrow DataFusion[39]、Apache Arrow[40] 和 Apache Arrow Ballista[41]。
引用链接
[1]
Apache Parquet: [https://parquet.apache.org/](https://parquet.apache.org/)[2]
Apache Arrow Rust Parquet 读取器: [https://docs.rs/parquet/27.0.0/parquet/](https://docs.rs/parquet/27.0.0/parquet/)[3]
几毫秒内: [https://github.com/tustvold/access-log-bench](https://github.com/tustvold/access-log-bench)[4]
任意结构化数据: [https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/](https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/)[5]
DuckDB: [https://duckdb.org/2021/06/25/querying-parquet.html](https://duckdb.org/2021/06/25/querying-parquet.html)[6]
Redshift: [https://docs.aws.amazon.com/redshift/latest/dg/c-using-spectrum.html#c-spectrum-overview](https://docs.aws.amazon.com/redshift/latest/dg/c-using-spectrum.html#c-spectrum-overview)[7]
TsFile: [https://github.com/apache/iotdb/blob/master/tsfile/README.md](https://github.com/apache/iotdb/blob/master/tsfile/README.md)[8]
Gorilla 格式: [https://www.vldb.org/pvldb/vol8/p1816-teller.pdf](https://www.vldb.org/pvldb/vol8/p1816-teller.pdf)[9]
Apache Arrow: [https://arrow.apache.org/](https://arrow.apache.org/)[10]
Apache Impala: [https://impala.apache.org/](https://impala.apache.org/)[11]
可用编码: [https://parquet.apache.org/docs/file-format/data-pages/encodings/](https://parquet.apache.org/docs/file-format/data-pages/encodings/)[12]
编码技术: [https://parquet.apache.org/docs/file-format/data-pages/encodings/](https://parquet.apache.org/docs/file-format/data-pages/encodings/)[13]
内存格式: [https://www.influxdata.com/glossary/column-database/](https://www.influxdata.com/glossary/column-database/)[14]
分类: [https://pandas.pydata.org/docs/user_guide/categorical.html](https://pandas.pydata.org/docs/user_guide/categorical.html)[15]
低基数: [https://www.influxdata.com/glossary/cardinality/](https://www.influxdata.com/glossary/cardinality/)[16]
第三范式: [https://en.wikipedia.org/wiki/Third_normal_form#:~:text=Third%20normal%20form%20(3NF)%20is,in%201971%20by%20Edgar%20F.](https://en.wikipedia.org/wiki/Third_normal_form#:~:text=Third%20normal%20form%20(3NF)%20is,in%201971%20by%20Edgar%20F.)[17]
DictionaryArray: [https://docs.rs/arrow/27.0.0/arrow/array/struct.DictionaryArray.html](https://docs.rs/arrow/27.0.0/arrow/array/struct.DictionaryArray.html)[18]
60 倍: [https://github.com/apache/arrow-rs/pull/1180](https://github.com/apache/arrow-rs/pull/1180)[19]
部分字典编码: [https://github.com/apache/parquet-format/blob/111dbdcf8eff2e9f8e0d4e958cecbc7e00028aca/README.md?plain=1#L194-L199](https://github.com/apache/parquet-format/blob/111dbdcf8eff2e9f8e0d4e958cecbc7e00028aca/README.md?plain=1#L194-L199)[20]
博客文章: [https://arrow.apache.org/blog/2019/09/05/faster-strings-cpp-parquet/](https://arrow.apache.org/blog/2019/09/05/faster-strings-cpp-parquet/)[21]
DataFusion: [https://arrow.apache.org/datafusion/](https://arrow.apache.org/datafusion/)[22]
Cloudera Parquet Predicate Pushdown 文档: [https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cdh_ig_predicate_pushdown_parquet.html#concept_pgs_plb_mgb](https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/cdh_ig_predicate_pushdown_parquet.html#concept_pgs_plb_mgb)[23]
RowSelection: [https://docs.rs/parquet/27.0.0/parquet/arrow/arrow_reader/struct.RowSelector.html](https://docs.rs/parquet/27.0.0/parquet/arrow/arrow_reader/struct.RowSelector.html)[24]
分区裁剪: [https://docs.oracle.com/database/121/VLDBG/GUID-E677C85E-C5E3-4927-B3DF-684007A7B05D.htm#VLDBG00401](https://docs.oracle.com/database/121/VLDBG/GUID-E677C85E-C5E3-4927-B3DF-684007A7B05D.htm#VLDBG00401)[25]
Bloom Filters: [https://github.com/apache/parquet-format/blob/master/BloomFilter.md](https://github.com/apache/parquet-format/blob/master/BloomFilter.md)[26]
添加布隆过滤器支持: [https://github.com/apache/arrow-rs/issues/3023](https://github.com/apache/arrow-rs/issues/3023)[27]
单行可能对应多个值的嵌套列表: [https://arrow.apache.org/blog/2022/10/08/arrow-parquet-encoding-part-2/](https://arrow.apache.org/blog/2022/10/08/arrow-parquet-encoding-part-2/)[28]
RowSelections: [https://docs.rs/parquet/27.0.0/parquet/arrow/arrow_reader/struct.RowSelection.html](https://docs.rs/parquet/27.0.0/parquet/arrow/arrow_reader/struct.RowSelection.html)[29]
PARQUET-1404: [https://issues.apache.org/jira/browse/PARQUET-1404](https://issues.apache.org/jira/browse/PARQUET-1404)[30]
SPARK-36527: [https://issues.apache.org/jira/browse/SPARK-36527](https://issues.apache.org/jira/browse/SPARK-36527)[31]
Impala: [https://docs.cloudera.com/cdw-runtime/cloud/impala-reference/topics/impala-lazy-materialization.html](https://docs.cloudera.com/cdw-runtime/cloud/impala-reference/topics/impala-lazy-materialization.html)[32]
RowFilter: [https://docs.rs/parquet/latest/parquet/arrow/arrow_reader/struct.RowFilter.html](https://docs.rs/parquet/latest/parquet/arrow/arrow_reader/struct.RowFilter.html)[33]
row_filter: [https://github.com/apache/arrow-datafusion/blob/58b43f5c0b629be49a3efa0e37052ec51d9ba3fe/datafusion/core/src/physical_plan/file_format/parquet/row_filter.rs#L40-L70](https://github.com/apache/arrow-datafusion/blob/58b43f5c0b629be49a3efa0e37052ec51d9ba3fe/datafusion/core/src/physical_plan/file_format/parquet/row_filter.rs#L40-L70)[34]
SPARK-36529: [https://issues.apache.org/jira/browse/SPARK-36529](https://issues.apache.org/jira/browse/SPARK-36529)[35]
AsyncFileReader: [https://docs.rs/parquet/latest/parquet/arrow/async_reader/trait.AsyncFileReader.html](https://docs.rs/parquet/latest/parquet/arrow/async_reader/trait.AsyncFileReader.html)[36]
轻松地交错 CPU 和网络: [https://www.influxdata.com/blog/using-rustlangs-async-tokio-runtime-for-cpu-bound-tasks/](https://www.influxdata.com/blog/using-rustlangs-async-tokio-runtime-for-cpu-bound-tasks/)[37]
object_store: [https://docs.rs/object_store/latest/object_store/](https://docs.rs/object_store/latest/object_store/)[38]
在此: [https://www.influxdata.com/blog/rust-object-store-donation/](https://www.influxdata.com/blog/rust-object-store-donation/)[39]
Apache Arrow DataFusion: [https://github.com/apache/arrow-datafusion](https://github.com/apache/arrow-datafusion)[40]
Apache Arrow: [https://github.com/apache/arrow-rs](https://github.com/apache/arrow-rs)[41]
Apache Arrow Ballista: [https://github.com/apache/arrow-ballista](https://github.com/apache/arrow-ballista)
