





背景
在授信贷款业务场景中,客户经理需要编写企业授信调查报告,将其作为银行向企业授信贷款依据。为避免客户经理将历史调查报告稍加修改作为一份新报告提交到信贷系统,进而引发因前期调研不足引起信贷损失风险,信贷审批人员需对当前报告以及历史报告进行重检验证,已确保文档质量。
该业务场景主要涉及两方面工作:第一、需要对word文档必要章节的文本、图、表内容进行是否缺失检测;第二、与历史文档进行比对查重,保证必要章节内容低重复率。其中,对word文档下的文本、图、表进行定位并判别属于哪个章节是完成上述工作的关键,而人工核对审核会消耗大量人力成本,同时也不符合当前银行业数字化转型发展规划,本文主要论述如何快速、自动定位word下各表格、图片所属章节位置,协助业务人员快速进行图、表定位并节约工作量,针对历史文档的查重方案,将在后续给大家分享。

问题分析及方案设计
为实现word文档操作的自动化处理,部分开发语言集成了word操作组件,支持对word段落、字体、页眉、页脚、表格、图像、写入、读取、解析和更新文档等操作,但这些组件往往只会一次性渲染所有段落、表格及图像,无法明确给出表格及图像具体属于哪个章节。为自动判别word文档中图片、表格属于哪个章节并进行识别,需要解决如下3个关键问题:
1. 对章节、段落进行定位
判别某段文本/表格/图片属于哪个章节,需要提取对应文本的样式,如Headding1代表的是标题1,Heading2代表标题2;
2. 段落类型判别及定位
在读取每段文本时,需判别当前段落具体类型,如文本、表格、图片。基于判别结果,记录对应类型段落内容、位置以及类型;
3. 块内容读取
基于不同类型的块内容,需配置块读取模块来实现具体内容识别,从而提取具体内容方便后处理验证;
1.1
docx文档结构解析
为解决以上问题,需对word文档结构进行解析,相对于doc文档,docx文档采用的文件组织方式是基于一种压缩文件的新型可扩展标记语言(ExtensibleMarkupLanguage,XML)构成的,可加载语音、文字、图像、视频、链接等多媒体材料。而doc结构相对晦涩,考虑到doc转docx相对简单,在设计该方案时,统一以docx作为word文档的主要分析对象,下文中所有word也均以docx格式文档为主。
docx文档的目录结构与压缩文件组织形式类似,均以树状结构排列,包含目录和子目录,其中叶子节点是一些文件流。
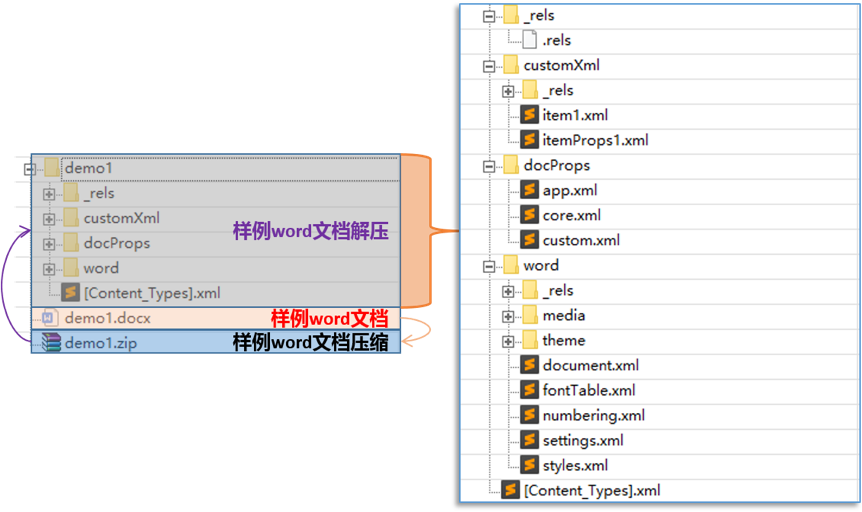
图1 docx文档对应目录结构
如图1所示,构建demo1.docx文档,修改后缀为zip,并解压得到docx文档目录结构,其中所包含的文件夹和文件各自定义数据和属性,一般来说,docx文档包含[Content_Types].xml文件、rels类文件和word文档内容类文件,下面详细描述各文件及文件夹作用。
[Content_Types].xml文件
[Content_Types].xml文件负责对整个文档中内容所对应的媒体类型进行记录,在docx文档中每使用一类媒体或元数据,[Content_Types].xml都要增加一项类型包定义来说明,如文档中涉及到jpg和png图像,会分别有jpeg和png的记录。
rels文件
rels是relationships的缩写,用来定义文档格式与媒体类型之间的对应关系。根_rels文件夹和word文件夹下都存有rels类文件。其中根_rels文件夹下的rels文件记录了主部件app.xml、core.xml和document.xml定义了对应系;word文件夹下的rels文件document.xml.rels列出document.xml所需的其他部件。
word文件夹
word文件夹中包含了大量xml文件,用来对应文档的页眉、页脚、批注、脚注、尾注、web设置、自定义设置、格式、内容等;同时,media文件夹存储文档中涉及的多媒体材料。document.xml最为重要,以xml形式存储了文档正文内容,包括body、p、tbl、drawing、r、t等多种标签,其中body标签代表整个文档、p代表段落、tbl代表表格、drawing代表图像、r代表字符格式、t代表具体文本,内容如下图2所示;styles.xml用于存储当前文档中涉及到的所有样式以及对应样式的id。
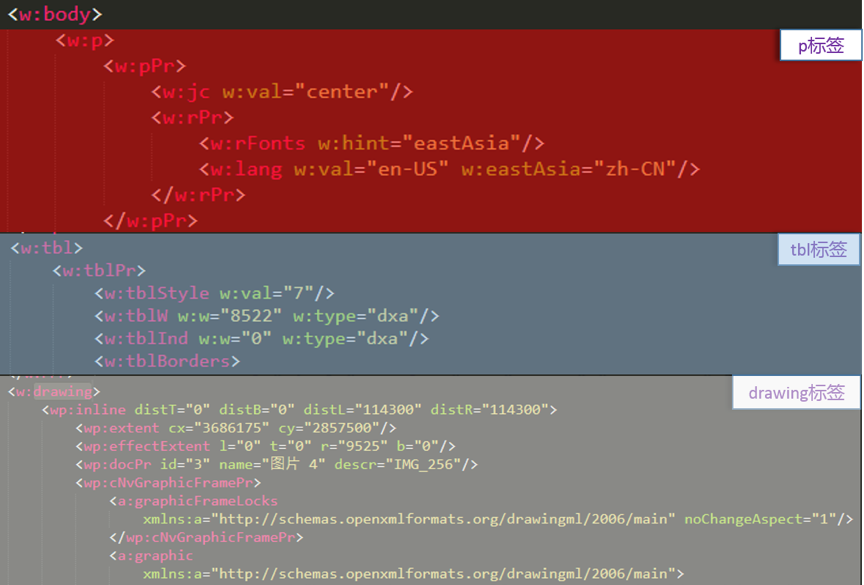
图2 document.xml多标签
1.2
方案设计
基于docx目录结构分析,可通过关联查询方式来解决难点问题1和难点问题2,基于抽取结果,可采用Python或Java语言对结果进行识别实现对表格以及图像所属章节定位及识别。
基于样式查找定位
如图3所示,通过document.xml抽取每个段落的style对应的id,关联style.xml抽取对应样式value,获取到的value中包含norml、heading1、heading2代表正常文本、一级标题、二级标题用来构建章节树。
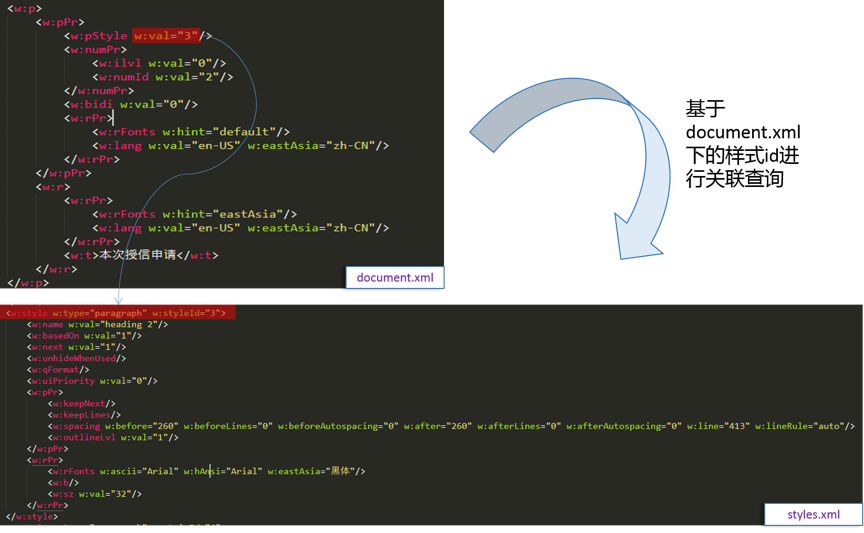
图3 基于样式id查找对应value
基于document关联rels查找图片
如图4所示,通过document.xml找到图片id,关联document.xml.rels获取到对应图片位置,并抽取出对应图片。
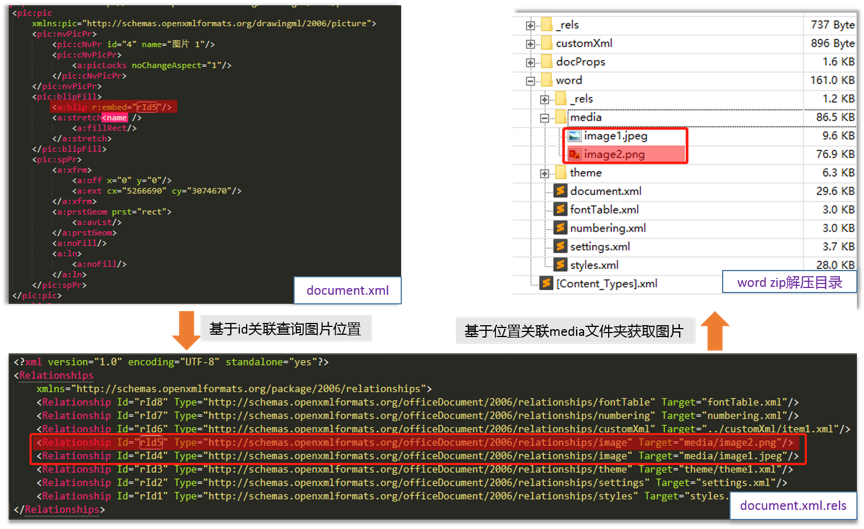
图4 基于document关联rels查找图片
对表格内容进行解析
抽取document.xml下的tbl标签,并按照tr、tc对表格行及单元格遍历,组合形成表格,完成对表格内容的解析。

具体实现
基于以上方案,设计如下处理流程,如图5所示,首先将docx文档格式修改为压缩格式,并进行解压,获取到document.xml、styles.xml、rels等必要文件,通过遍历document.xml对样式进行关联、表格抽取并解析、提取图片并进行关联查找,最终实现对文本内容、表格、图像所属章节定位。
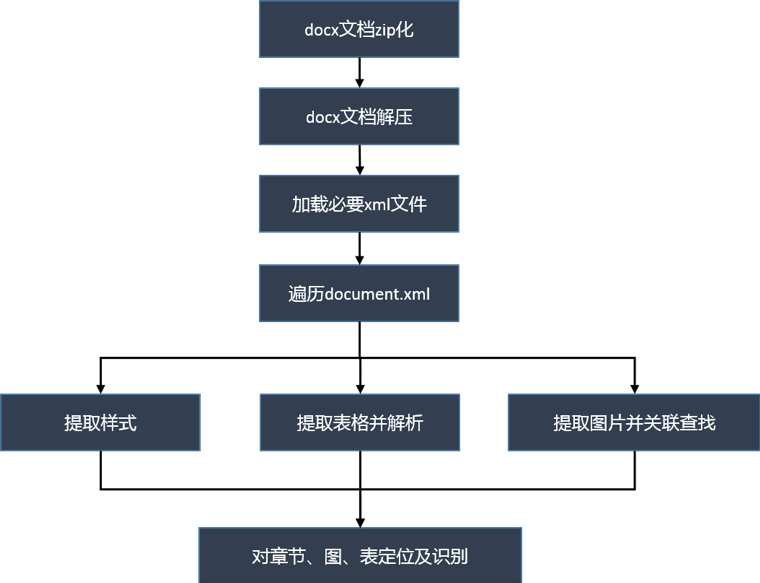
图5 按章节对图、表定位及识别处理流程
尽管以上流程是完成该需求的必要过程,但其中部分操作已有相关代码进行封装实现,大可不必从头构建,在已有工具的基础上构建新的工具,将会事半功倍。通过分析python-docx源码,该包已实现了docx文档目录的映射并封装了相关操作对象和方法,大大方便了docx文档的内容抽取。其映射关系以及具体对象说明如图6所示。
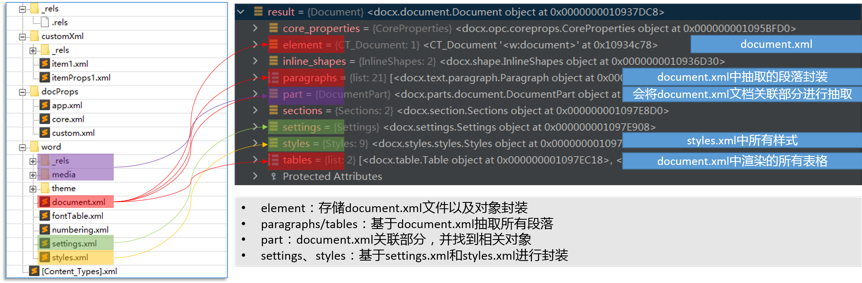
图6 python-docx包对文档目录映射及对象封装
基于python-docx包对文档目录映射及对象封装,可将最初的处理流程进行改造,如图7所示。
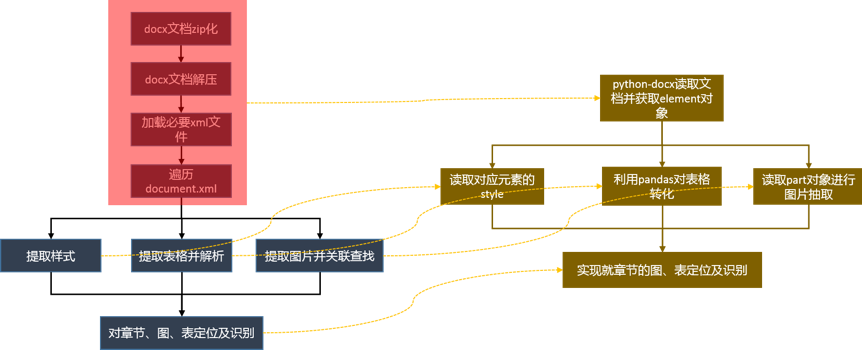
图7 基于包对处理流程进行改造
其具体代码实现包含如下主要部分:
1. 对文档的读取并抽取element下所有块

2. 提取样式

3. 提取表格并定位

4. 提取图片并定位


最终效果
构建demo1.docx文档,包含表格、图片,同时又具有多个章节。现通过已编写代码自动定位图片、表格属于哪个章节。原始文档如图8所示,最终结果如图9所示,基于结果文件可看出表格、图片所属章节与原始文件一致,从而验证该方案的有效性。

图8 构建测测试文档截图
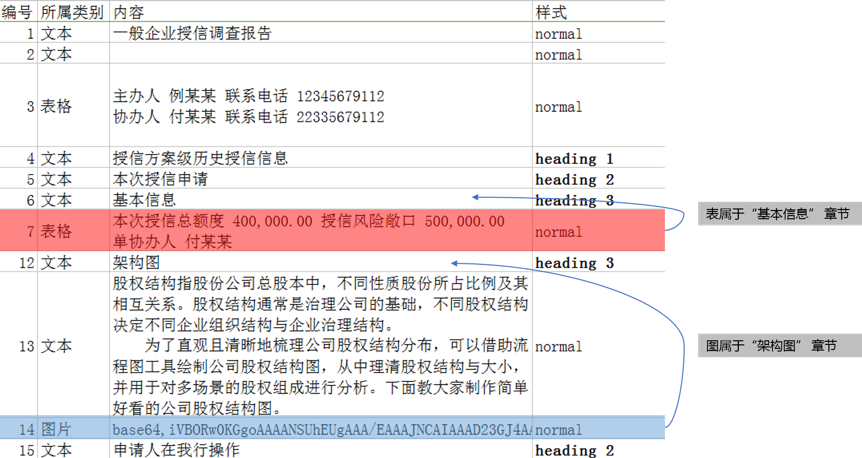
图9 确定文本内容、图片、表格属于对应章节

总结
通过本次实现word文档表格、图像所属章节定位,研究了docx文档的目录结构,设计了表格、图像章节定位方案,最终利用Python以及python-docx实现该功能。有助于快速解决表格、图像所属章节自动定位问题,基于定位结果再进一步分析章节具体内容,其可作为一项基础AI能力进一步提升业务效率。

作者 | 黄 彪
视觉 | 王朋玉
统筹 | 郑 洁



