




 是新朋友吗?记得点击下面名片,关注我哦
是新朋友吗?记得点击下面名片,关注我哦

数据准备阶段
以公开数据2008年M国国内航班数据为例:
数据下载地址:
https://www.arangodb.com/graphcourse_demodata_arangodb-1/
#airports.csv
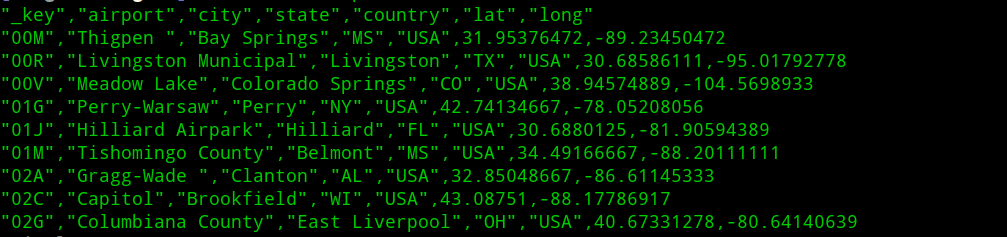
#flights.csv


数据导入--命令导入
以本机实验环境讲解
#arangoimp命令位置:
E:\yrotcerid\ArangoDB3 3.7.10\usr\bin
备注:windows环境下安装的arango
#csv文件位置:
F:\esabatad\ArangoDB\demo
#导入命令
arangoimp --file F:\esabatad\ArangoDB\demo\airports.csv --collection airports --create-collection true --type csv复制
语法参考:
arangoimp --file path to airports.csv on your machine --collection airports --create-collection true --type csv复制
提示输入密码:xxxxxx

在上面,我们使用数据“airports”可以当作图的节点,在这里我们使用“flights”中的数据作为边。
导入"flights.csv"文件
命令参考:
arangoimp --file "/home/data/flights.csv" --collection flights --create-collection true --type csv --create-collection-type edge复制
本机实验结果:
arangoimp --file F:\esabatad\ArangoDB\demo\flights.csv --collection flights --create-collection true --type csv --create-collection-type edge复制
扩展阅读:
arangoimp --file F:\esabatad\ArangoDB\demo\flights.csv --collection flights --create-collection true --type csv问题:使用上面命令导入 flights.csv 文件里面的_from 和 _to字段数据丢失了 没有导入进去注意:类型默认为document复制

web页面
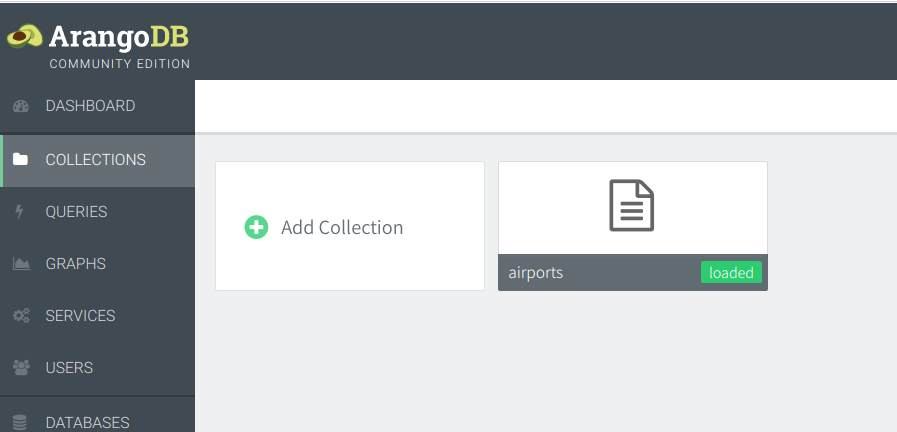
点击页面左侧按钮"COLLECTIONS",可以看到之前导入的数据集"airports",图标样式表明它是一个文本集合
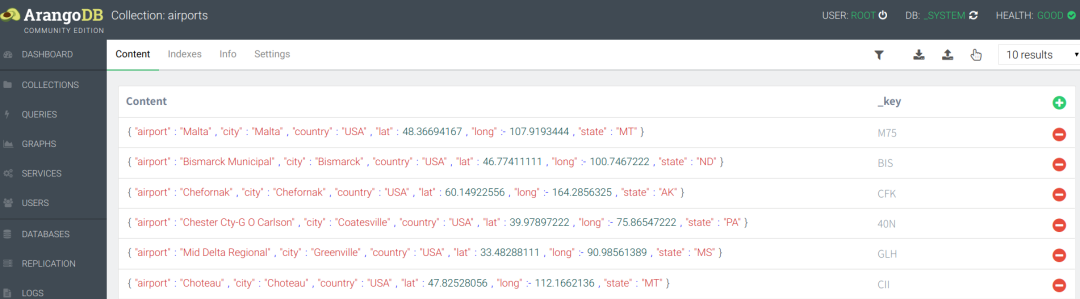
点击进入数据集"airports",该页面包含了对数据集的预览、筛选、上传、下载和删除等操作

AQL-简单的查询
ArangoDB提供了类似SQL的AQL脚本对图数据库进行查询。下面简单介绍一些查询脚本。
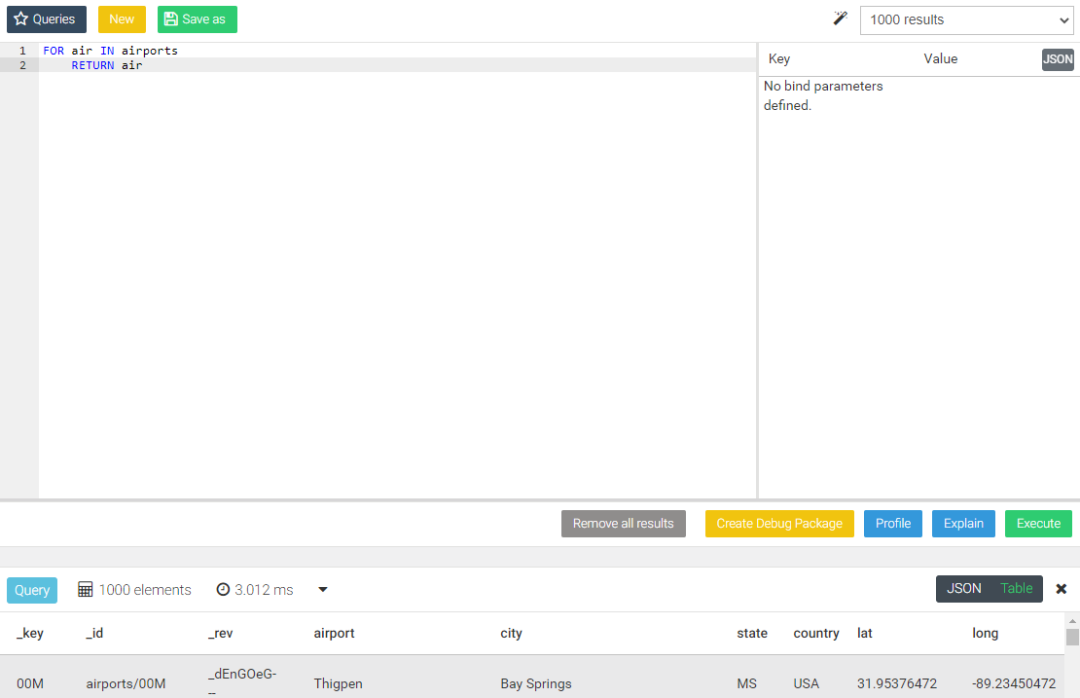
4.1、返回数据集"airports"中所有的airports: ----类比select * from airports
FOR airport IN airportsRETURN airport复制
注:for 后面是自己定义 for 和return一致即可
for 循环 in 表return 返回循环结果--中文解析从 airports表中 循环查找,定义循环名字为airport ,返回查询结果airport没有查询条件,返回全表复制
4.2、只返回California的airports: -----类比select * from airports where state = 'CA'
FOR airport IN airportsFILTER airport.state == "CA"RETURN airport复制
扩展阅读:
filter---过滤器 筛选for 循环 in 表filter 查询条件return 返回循环结果--中文解析从 airports表中 循环查找,定义循环名字为airport ,条件 字段state是CA的返回查询结果airport复制
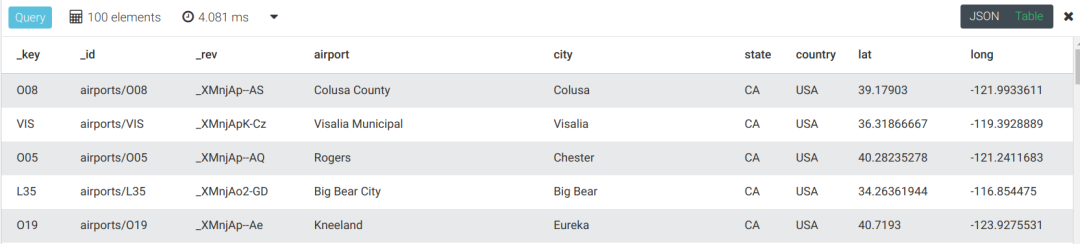
-------类比select * from airports where state = 'CA' and city ='San Andreas'
FOR airport IN airportsFILTER airport.state == "CA" AND airport.city=="San Andreas"RETURN airport复制
#filter---过滤器 筛选
for 循环 in 表filter 查询条件return 返回循环结果复制
--中文解析
从 airports表中 循环查找,定义循环名字为airport ,
条件 字段state是CA的 and city是 San Andreas 的
返回查询结果airport
4.3、返回每个州的机场数量---类比 select state ,count(state) as counter from airports group by state
FOR airport IN airportsCOLLECT state = airport.stateWITH COUNT INTO counterRETURN {state, counter}复制
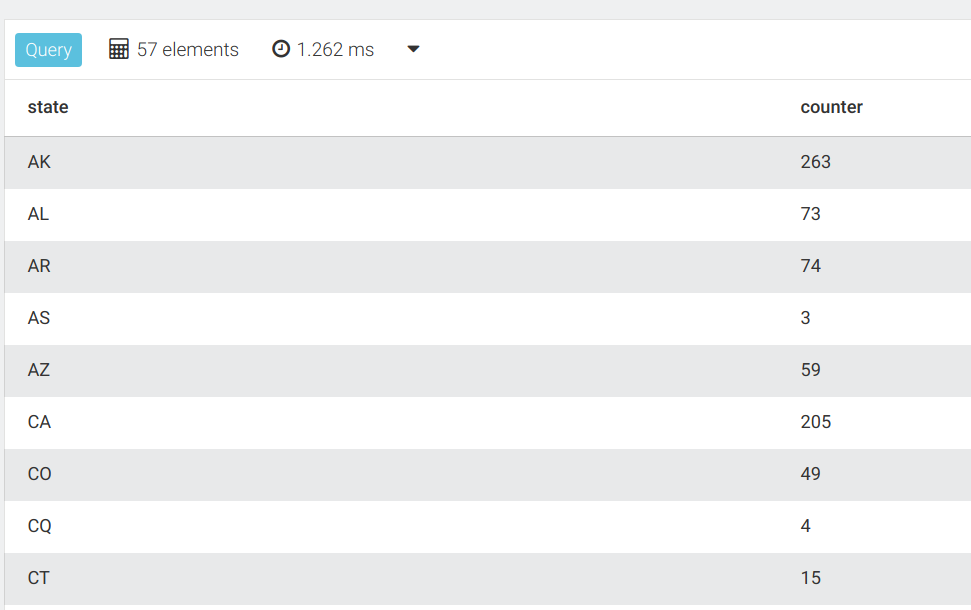
注意:在上面的代码示例中,所有关键字COLLECT、WITH和RETURN等都是大写的,但它只是一个约定。你也可以将所有关键词小写或混合大小写。但是变量名、属性名和集合名是区分大小写的。
FOR airport IN airportsCOLLECT state = airport.stateWITH COUNT INTO counterRETURN {state, counter}复制
--中文解析 count固定写法
for 循环 in 表collect 汇总字段with count into 汇总值命名字段return {汇总字段,汇总值命名字段}复制
--变量是可以变的
FOR air IN airportsCOLLECT sta= air.stateWITH COUNT INTO countstaRETURN {sta, countsta}复制

图查询
5.1、返回能到达洛杉矶国际机场(Lax)的所有机场
FOR airport IN OUTBOUND 'airports/LAX' flightsRETURN DISTINCT airport复制
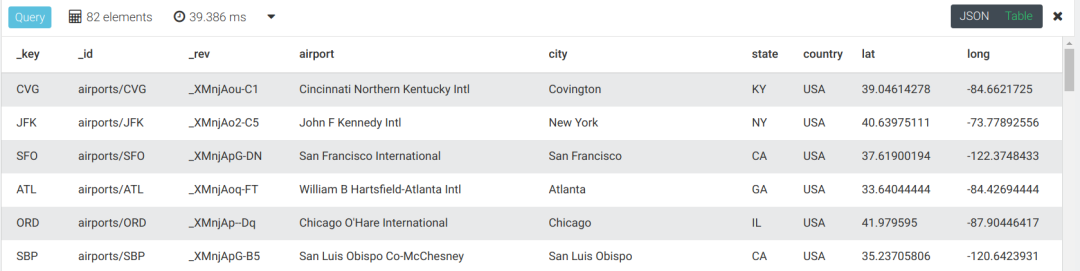
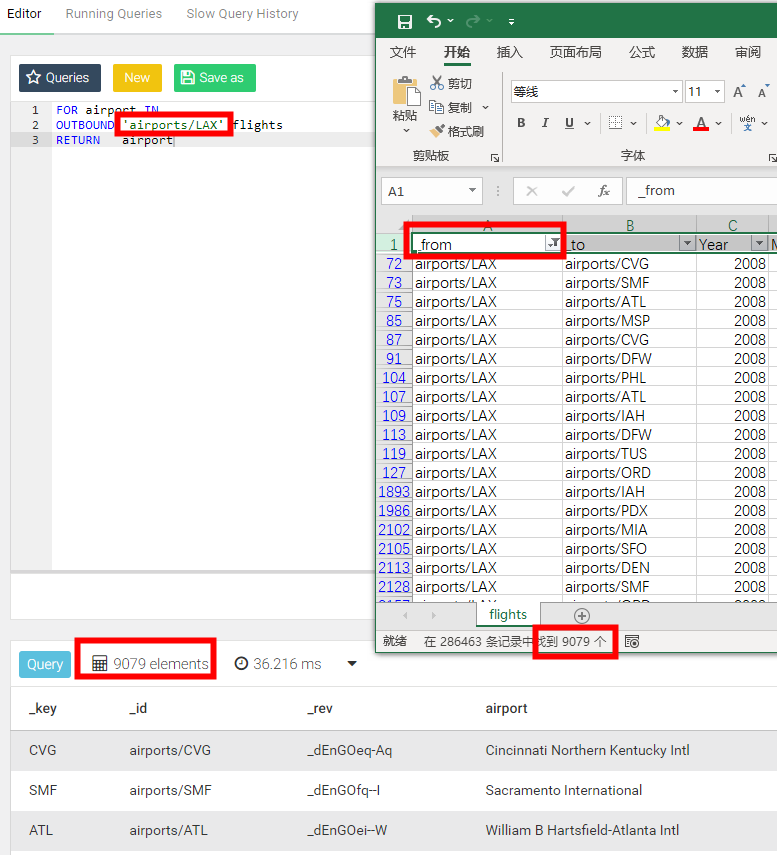
---fromkey 是 airports/LAX 的结果
FOR airportIN OUTBOUND 'airports/LAX' flightsRETURN DISTINCT airport--中文注释 OUTBOUND 向外去、出度 distinct 去重for 循环名 in outbound fromkey值 表名return 循环结果复制
--tokey是 airports/LAX 的结果
FOR airport ININBOUND 'airports/LAX' flightsRETURN airport--中文注释 INBOUND 向内来、入度复制
5.2、返回10个洛杉矶的航班和他们的目的地 ----limit 10 注意limit的位置
FOR airport, flight IN OUTBOUND 'airports/LAX' flightsLIMIT 10RETURN {airport, flight}复制
5.3、ATL机场能够到达的机场
FOR airport IN flightsFILTER airport._from=="airports/ATL"limit 100RETURN airport复制


查询语法
the concepts of the query options:
FOR vertex[, edge[, path]]IN [min[..max]]OUTBOUND|INBOUND|ANY startVertexedgeCollection[, more…]复制
Explanation:
FOR 有三个参数‣ vertex (object): 遍历中的当前顶点‣ edge (object, optional): 遍历中的当前边‣ path (object, optional): 两个对象的路径表示‣ vertices: 此路径上所有顶点的数组‣ edges: 此路径上所有边的数组IN min..max: 定义遍历的最小深度和最大深度。如果未指定,默认为1!OUTBOUND/INBOUND/ANY :定义搜索的方向edgeCollection: 保存在遍历中要考虑的边缘的集合的一个或多个名称OPTIONS options(object,optional):用于修改遍历的执行。只有以下属性有效果,所有其他属性将被忽略:uniqueVertices(string):可选地确保顶点唯一性“path” - 保证没有路径返回一个重复的顶点“global” - 保证在遍历期间每个顶点最多被访问一次,无论从起始顶点到这个顶点有多少路径。如果您从最小深度 min depth > 1之前发现的顶点开始,可能根本不会返回(它仍然可能是路径的一部分)。注意:使用此配置,结果不再是确定性的。如果从startVertex到顶点有多条路径,则选择其中一条路径。“none”(默认) - 不对顶点应用唯一性检查uniqueEdges(string):可选地确保边缘唯一性“path”(默认) - 保证没有路径返回一个重复的边“global” - 保证在遍历过程中,每个边缘最多被访问一次,无论从起始顶点到该边缘有多少条路径。如果从a开始, min depth > 1在最小深度之前发现的边缘根本不会被返回(它仍然可能是路径的一部分)。注意:使用此配置,结果不再是确定性的。如果有从多个路径startVertex超过边缘的那些中的一个被拾取。“none” - 不对边缘应用唯一性检查。注意:使用此配置,遍历将跟随边沿周期。bfs(bool):可选地使用可选的宽度优先遍历算法true - 遍历将被执行宽度优先。结果将首先包含深度1的所有顶点。比深度2处的所有顶点等等。false(默认) - 遍历将以深度优先执行。它首先将深度1的一个顶点的最小深度的最小深度返回到最大深度。对于深度1处的下一个顶点,依此类推。复制
模糊查询
#以某些字符开头的模糊查询AQL
FOR airport IN airportsfilter airport.city like 'T%'limit 100RETURN airport复制
#以某个字段等于固定值或某些固定值为查询条件的aql
FOR airport IN airportsfilter airport.city=='Tower'limit 100RETURN airportFOR airport IN airportsfilter airport.city in ["Tuskegee","Tower"]RETURN airportFOR airport IN airportsFILTER airport.state == "CA" AND airport.city=="San Andreas"RETURN airport复制
兴趣是最好的老师,唯有热爱不可辜负!
Have fun!
少侠,请留步,欢迎点赞关注转发
