




前言
总结Flink通过DataStream API读写Hudi Demo示例,主要是自己备忘用。
最开始学习Flink时都是使用Flink SQL,所以对于Flink SQL读写Hudi比较熟悉。但是对于写代码实现并不熟悉,而有些需求是基于Flink代码实现的,所以需要学习总结一下。
仅为了实现用代码读写Hudi的需求,其实有两种方式,一种是在代码里通过Flink Table API,也就是代码中执行Flink SQL,这种方式其实和通过SQL实现差不多,另一种方式是通过DataStream API实现。(现实中包括网上教程使用最多的应该是Flink Table API)
本文主要是总结DataStream API方式
DataStream API方式有一种好处是方便IDEA本地调试Hudi源码,便于学习,当然Table API也是可以进行本地调试源码的,但是因为我对Flink SQL源码不熟悉,调试起来比较费劲。Table API调试源码的难点在于我不知道从Flink SQL的源码到Hudi源码的入口在哪,因为这里牵扯到SQL解析的源码,可能比较麻烦(没有研究过)。比如我之前总结的Hudi Spark SQL源码相关的文章:Hudi Spark SQL源码学习总结-Create Table
代码
GitHub地址:https://github.com/dongkelun/hudi-demo/tree/master/hudi0.13_flink1.15
官网地址:https://hudi.apache.org/docs/flink-quick-start-guide/
package com.dkl.hudi.flink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.GenericRowData;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.data.StringData;
import org.apache.hudi.configuration.FlinkOptions;
import org.apache.hudi.util.HoodiePipeline;
import java.util.HashMap;
import java.util.Map;
public class HudiDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String targetTable = "t1";
if (args.length > 0) {
targetTable = args[0];
}
String basePath = "/tmp/flink/hudi/" + targetTable;
Map<String, String> options = new HashMap<>();
options.put(FlinkOptions.PATH.key(), basePath);
// options.put(FlinkOptions.TABLE_TYPE.key(), HoodieTableType.MERGE_ON_READ.name());
// options.put(FlinkOptions.PRECOMBINE_FIELD.key(), "ts");
// options.put(FlinkOptions.HIVE_SYNC_ENABLED.key(), "true");
options.put("hive_sync.mode", "hms");
options.put("hive_sync.conf.dir", "/usr/hdp/3.1.0.0-78/hive/conf");
options.put("hive_sync.db", "hudi");
options.put("hive_sync.table", targetTable);
options.put("hive_sync.partition_fields", "dt");
options.put("hive_sync.partition_extractor_class", "org.apache.hudi.hive.HiveStylePartitionValueExtractor");
options.put("hoodie.datasource.write.hive_style_partitioning", "true");
options.put("hoodie.datasource.hive_sync.create_managed_table", "true");
// options.put(FlinkOptions.READ_AS_STREAMING.key(), "true"); // this option enable the streaming read
// options.put(FlinkOptions.READ_START_COMMIT.key(), "'20210316134557'"); // specifies the start commit instant time
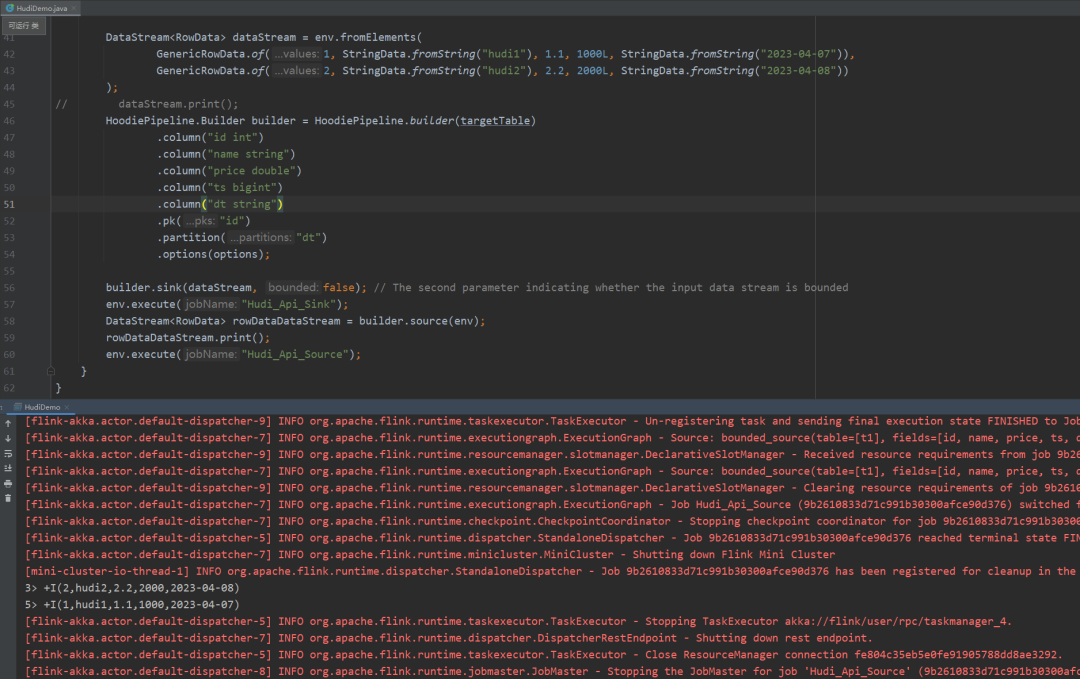
DataStream<RowData> dataStream = env.fromElements(
GenericRowData.of(1, StringData.fromString("hudi1"), 1.1, 1000L, StringData.fromString("2023-04-07")),
GenericRowData.of(2, StringData.fromString("hudi2"), 2.2, 2000L, StringData.fromString("2023-04-08"))
);
// dataStream.print();
HoodiePipeline.Builder builder = HoodiePipeline.builder(targetTable)
.column("id int")
.column("name string")
.column("price double")
.column("ts bigint")
.column("dt string")
.pk("id")
.partition("dt")
.options(options);
builder.sink(dataStream, false); // The second parameter indicating whether the input data stream is bounded
env.execute("Hudi_Api_Sink");
DataStream<RowData> rowDataDataStream = builder.source(env);
rowDataDataStream.print();
env.execute("Hudi_Api_Source");
}
}
因为本地连接服务器上的hive比较麻烦,所以本地运行的话,需要把同步hive关掉,如果在服务器上运行,把同步hive的配置项打开就可以了
这里的代码和官方文档是差不多的,主要是官方文档没有提供如何构造写Hudi的数据集
DataStream
,这里给出简单的示例
pom
我在GitHub上提交pom的引用的依赖比较多,是因为在Idea本地调试和在服务器上运行需要的依赖不太一样,本地运行需要的依赖比较多,而且还有很多依赖冲突。如果只需要在服务器上运行,则只需要下面三个依赖:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.15-bundle</artifactId>
<version>${hudi.version}</version>
</dependency>
</dependencies>
github上的依赖既可以在本地进行调试,也可以打包直接在服务器上运行。因为打包时没有将依赖打到包里面,这需要在服务器上面的flink lib下提前配置好相应的jar包。
服务器运行
bin/flink run -c com.dkl.hudi.flink.HudiDemo /opt/dkl/hudi0.13_flink1.15-1.0.jar flink_hudi_dmeo

本地运行调试
🧐 分享、点赞、在看,给个3连击呗!👇
