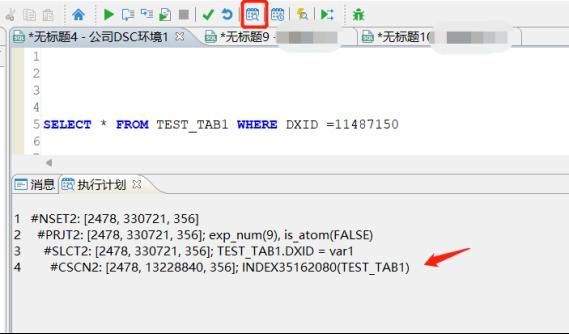
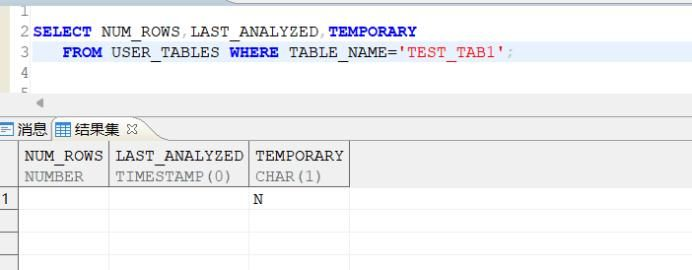
达梦数据库的优化,我平常使用的最多的还是,达梦数据库优化“三把斧”(统计信息收集,合理的索引建立,dm.ini参数的优化),在实践中发现可以排除93%(百分比数值只是个人以往解决性能问题的估算百分比)以上的性能问题,在使用三把斧过程中,我们首先要预检查下SQL,以及SQL编写的初级错误问题,例如:OR语句、困难正则表达式、未加过滤条件、笛卡尔、隐式转换等先简单过一遍。在实际过程中,大部分SQL优化可以通过收集统计信息、新增索引、索引调整、达梦DM.INI参数调整等得到优化处理。而进阶一些比较难SQL分析,就涉及到了增加HINT、SQL改写等。在处理过程中,都需要根据具体SQL来判断,常见的有关联临时表查询、层次查询等容易需要Hint辅助,文章中给出浅显的例子来说明,实际优化过程中,还是需要不断的去实践,根据不同的SQL,分析执行计划,这样才能积累更加丰富的经验。达梦数据库是基于代价的优化器,达梦数据库统计信息不准,会影响到执行计划的估算,导致SQL解析到错误的执行计划,如何判断统计信息有没有收集呢?我们看如下SQL,主要看NUM_ROWS字段,如果没有收集通常是空,第二个LAST_ANALYZED 代表收集的时间,如果没有收集这个字段也是空,第三个TEMPORARY字段附带说明,N表示不是临时表,Y表示是临时表,通常如果TEMPORARY=Y 是不用收集的,这个大家查询的时候注意下,临时表无需收集统计信息。SELECT NUM_ROWS,LAST_ANALYZED,TEMPORARY FROM USER_TABLES WHERE TABLE_NAME=‘TEST_TAB1’;
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(USER,‘TEST_TAB1’,NULL,100,TRUE,‘FOR ALL COLUMNS SIZE AUTO’);
END;
DBMS_STATS.GATHER_TABLE_STATS参数说明:第一个参数:USER是所属用户,如果你要指定其它用户,单独填写,默认USER是当前用户下的表;第三个参数:一般不是分区表名填写NULL即可,默认也是 NULL,区分大小写;第四个参数:采样百分比,收集的百分比,范围为 0.000001~100,默认系统自定;第五个参数:TRUE,保留参数,是否使用随机块代替随机行,默认我们填写 TRUE即可。第六个参数:控制列的统计信息集合和直方图的创建的格式默认我们填写FOR ALL COLUMNS SIZE AUTO即可,表示所有列收集。需要深入理解的可以参考达梦官方手册《DM8系统包使用手册.pdf》,平常我比较常用的还是DBMS_STATS.GATHER_TABLE_STATS。什么时候需要收集统计信息?通常执行计划估算数据量不准的时候就需要收集了,相差不大一般没有影响,如果比较大就要收集了,否则会影响性能;这里用以下例子说明,只是对表未收集统计信息导致执行计划估算有差异的案例:步骤1:直接创建2个表,一般新创建的表统计信息是不会自动收集的(否则开启AUTO_STAT_OBJ全表监控的自动收集),我们查一下它的执行计划,这个时候结果集应该是估算有差异的;CREATE TABLE TEST1208_1 AS
select * from dba_TAB_COLUMNS WHERE TABLE_NAME=‘ALL_ALL_TABLES’;
CREATE TABLE TEST1208_2 AS
select * from dba_TAB_COLUMNS WHERE TABLE_NAME=‘ALL_ALL_TABLES’;
DISQL登录当前用户
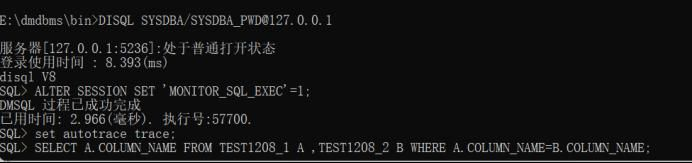
E:\dmdbms\bin>DISQL SYSDBA/SYSDBA_PWD@127.0.0.1
然后执行如下命令:
ALTER SESSION SET ‘MONITOR_SQL_EXEC’=1;
set autotrace trace;
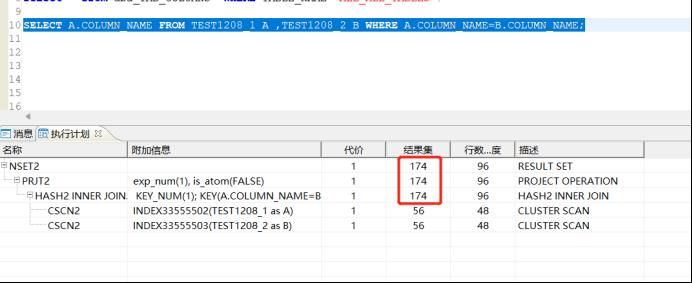
SELECT A.COLUMN_NAME FROM TEST1208_1 A ,TEST1208_2 B WHERE A.COLUMN_NAME=B.COLUMN_NAME;
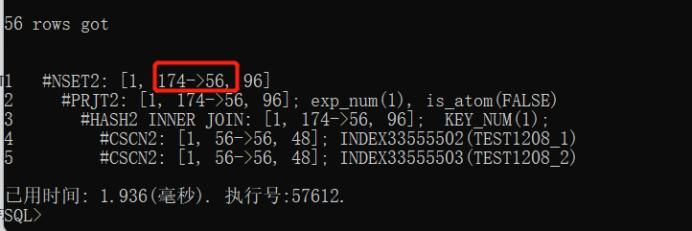
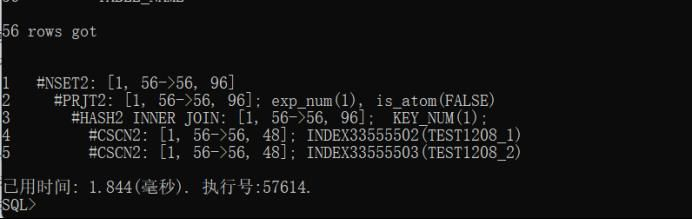
从服务器上的执行计划这里可以看出,实际56,估算174;步骤3:达梦客户端,我们对这连个表统计信息进行收集;BEGIN
DBMS_STATS.GATHER_TABLE_STATS(USER,‘TEST1208_1’,NULL,100,TRUE,‘FOR ALL COLUMNS SIZE AUTO’);
DBMS_STATS.GATHER_TABLE_STATS(USER,‘TEST1208_2’,NULL,100,TRUE,‘FOR ALL COLUMNS SIZE AUTO’);
END;
/
步骤5:我们重复步骤2看真实SQL计划,那继续再看收集统计信息后执行计划情况:发现并没有变化,这是为什么呢?我们思考一下就会想到,因为之前在未收集统计信息的时候,我们执行了一遍这个SQL,所以SQL缓存了计划,那遇到这样的情况,我们应该对这个SQL的缓存计划进行清理;SELECT * FROM v$cachepln where SQLSTR LIKE ‘%TEST1208_2 B WHERE A.COLUMN_NAME%’;
SP_CLEAR_PLAN_CACHE(1034139736);
对这个SQL语句的缓存计划进行清理;
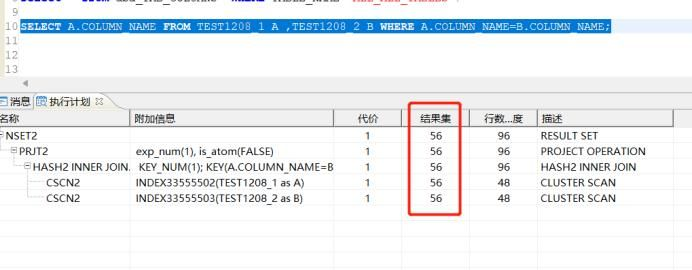
清理后,我们再来看下它的服务器计划,这次就正确了。步骤7:我们再次重复步骤2登录查询下它的真实执行计划,看如下图,执行计划也是准确的;总结:通过如上案例,可以直观的显示收集统计前后的状态,以此案例,可以对照我们实际工作中,在分析SQL的时候,当我们发现数据量差异非常大,而且SQL性能低的时候,我们就应该第一直觉想到该要收集统计信息了,如果结果集相差不大,则性能也不会有太大问题。大家主要关注相差特别大的情况。2.3、达梦数据库索引创建
合理的索引建立(过多的索引会导致插入的性能下降,我们要根据实际业务情况合理的建立索引)有助于性能的提升,通常表,记录数300以上,离散度高,而且又是SQL的关联列,这种情况可以建立索引,提升查询速度;
例子说明:
没有索引情况下:
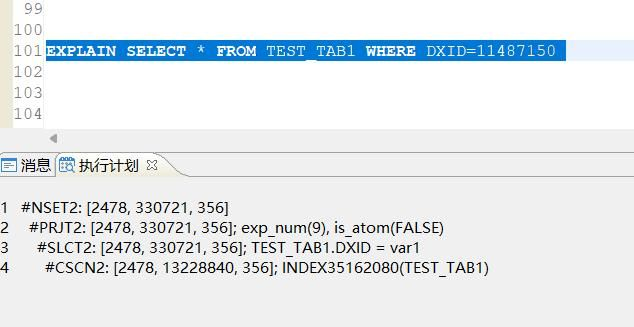
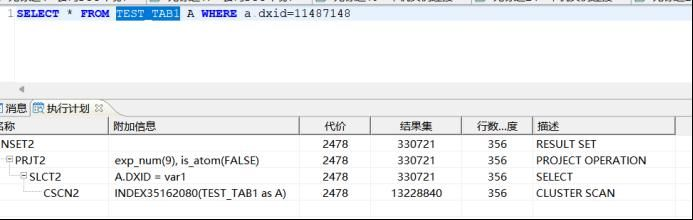
TEST_TAB1 有1300万记录,DXID是唯一值;[执行语句1]:
SELECT * FROM TEST_TAB1 A WHERE a.dxid=11487148
执行成功, 执行耗时4秒 18毫秒. 执行号:108767008
1条语句执行成功执行:
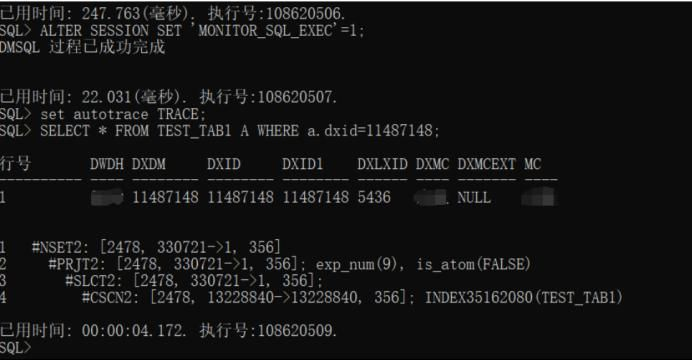
从执行计划上看,SSEK2操作符,已经是二级索引扫描了,说明索引生效了,结果集也是在330721上,而不是13228840,查询速度28毫秒就完成了查询,这里可以说明,加上索引后,速度有140倍的提升;[执行语句1]:
SELECT * FROM TEST_TAB1 A WHERE a.dxid=11487148;
执行成功, 执行耗时28毫秒. 执行号:108767013
1条语句执行成功
总结:这是一个非常简单的单表过滤SQL语句,主要用例子来说明,不加索引和加索引的查询速度对比,在数据量越大的时候,差别就越大。侧面也可以看到统计信息,全表扫描和二级索引扫描的结果集相差比较大;存储过程性能问题总是让人头痛,这个时候达梦调试工具就发挥还不错的作用,我们可以直接要调试的存储过程SQL进去,进行单步调试,确定他的性能SQL问题处,然后获取出SQL单独分析处理,这里演示下工具的使用:
2.4.1 点击客户端的绿色小飘虫;
2.4.2再点击执行:2.4.3点击进入箭头,就进入过程内了,在调试过程中,不断点下一步,则可以真实执行,快速定位下慢的段落了,具体工具使用,在手册中《DM8_SQL程序设计.pdf》中有简单说明,操作方法,如下截图:DMSQL调试工具已经满足日常的性能调试,平常我们还可以观测变量的输出,这样就可以很完整的看出变量获取异常等问题。对数据库开发人员来说也比较实用。