





搭建Hadoop3.x分布式集群文章,或者在公众号后台回复
20230116获取该图文)和Zookeeper分布式协调服务(若没有安装Zookeeper,请查看本公众号中的
搭建Zookeeper分布式协调服务文章,或者在公众号后台回复
20230127获取该图文)。
| master | slave1 | slave2 | |
|---|---|---|---|
| NameNode | √ | √ | √ |
| DataNode | √ | √ | √ |
| ResourceManager | √ | √ | √ |
| NodeManager | √ | √ | √ |
| JournalNode | √ | √ | √ |
| Zookeeper | √ | √ | √ |
| ZKFC | √ | √ | √ |
hadoop-env.sh文件,使用
vim usr/local/hadoop/etc/hadoop/hadoop-env.sh命令,在原有配置中最后追加以下参数。
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
core-site.xml文件,使用
vim usr/local/hadoop/etc/hadoop/core-site.xml命令,替换原有配置(此配置文件参考官网文档,详细请查看该网址:
https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
<description>The default path for Hadoop clients to use the new HA-enabled logical URI.</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<description>This lists the host-port pairs running the ZooKeeper service.</description>
</property>
</configuration>
hdfs-site.xml文件,使用
vim usr/local/hadoop/etc/hadoop/hdfs-site.xml命令,替换原有配置(此配置文件参考官网文档,详细请查看该网址:
https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html)。
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/dfs/journalnode</value>
<description>The path where the JournalNode daemon will store its local state.</description>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
<description>The logical name for this new nameservice.</description>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2,nn3</value>
<description>Unique identifiers for each NameNode in the nameservice.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:8020</value>
<description>The fully-qualified RPC address for nn1 to listen on.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:8020</value>
<description>The fully-qualified RPC address for nn2 to listen on.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn3</name>
<value>slave2:8020</value>
<description>The fully-qualified RPC address for nn3 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:9870</value>
<description>The fully-qualified HTTP address for nn1 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:9870</value>
<description>The fully-qualified HTTP address for nn2 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn3</name>
<value>slave2:9870</value>
<description>The fully-qualified HTTP address for nn3 to listen on.</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
<description>The URI which identifies the group of JNs where the NameNodes will write/read edits.</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>The Java class that HDFS clients use to contact the Active NameNode.</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
<description>
A list of scripts or Java classes which will be used to fence the Active NameNode during a failover.
sshfence - SSH to the Active NameNode and kill the process
shell - run an arbitrary shell command to fence the Active NameNode
</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>Set SSH private key file.</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>Automatic failover.</description>
</property>
</configuration>
yarn-site.xml文件,使用
vim usr/local/hadoop/etc/hadoop/yarn-site.xml命令,将原有配置中的
yarn.resourcemanager.hostname参数删除,并在最后追加以下参数(此配置文件参考官网文档,详细请查看该网址:
https://hadoop.apache.org/docs/r3.3.4/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html)。
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>Enable RM HA.</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
<description>Identifies the cluster.</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
<description>List of logical IDs for the RMs. e.g., "rm1,rm2".</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
<description>Set rm1 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
<description>Set rm2 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>slave2</value>
<description>Set rm3 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master:8088</value>
<description>Set rm1 web application addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave1:8088</value>
<description>Set rm2 web application addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>slave2:8088</value>
<description>Set rm3 web application addresses.</description>
</property>
<property>
<name>hadoop.zk.address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<description>Address of the ZK-quorum.</description>
</property>
rm -rf usr/local/hadoop/dfs命令,删除之前创建的存储路径,同时在master节点上执行
mkdir -p usr/local/hadoop/dfs/name usr/local/hadoop/dfs/data usr/local/hadoop/dfs/journalnode,再次创建存储路径。
rm -rf usr/local/hadoop/tmp usr/local/hadoop/logs && mkdir -p usr/local/hadoop/tmp usr/local/hadoop/logs命令,重置临时路径和日志信息。
$ZOOKEEPER_HOME/bin/zkServer.sh start # 开启Zookeeper进程(所有节点上执行)
$HADOOP_HOME/bin/hdfs --daemon start journalnode # 开启监控NameNode的管理日志的JournalNode进程(所有节点上执行)
$HADOOP_HOME/bin/hdfs namenode -format # 命令格式化NameNode(在master节点上执行)
scp -r /usr/local/hadoop/dfs slave1:/usr/local/hadoop # 将格式化后的目录复制到slave1中(在master节点上执行)
scp -r /usr/local/hadoop/dfs slave2:/usr/local/hadoop # 将格式化后的目录复制到slave2中(在master节点上执行)
$HADOOP_HOME/bin/hdfs zkfc -formatZK # 格式化Zookeeper Failover Controllers(在master节点上执行)
$HADOOP_HOME/sbin/start-dfs.sh && $HADOOP_HOME/sbin/start-yarn.sh # 启动HDFS和Yarn集群(在master节点上执行)
$ZOOKEEPER_HOME/bin/zkServer.sh start # 开启Zookeeper进程(所有节点上执行)
$HADOOP_HOME/sbin/start-dfs.sh && $HADOOP_HOME/sbin/start-yarn.sh # 启动HDFS和Yarn集群(在master节点上执行)
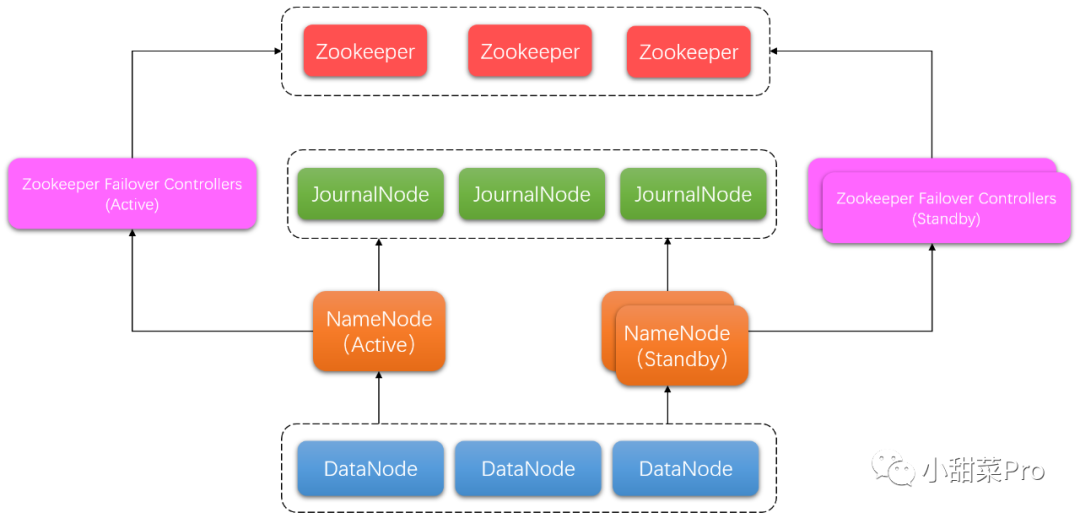
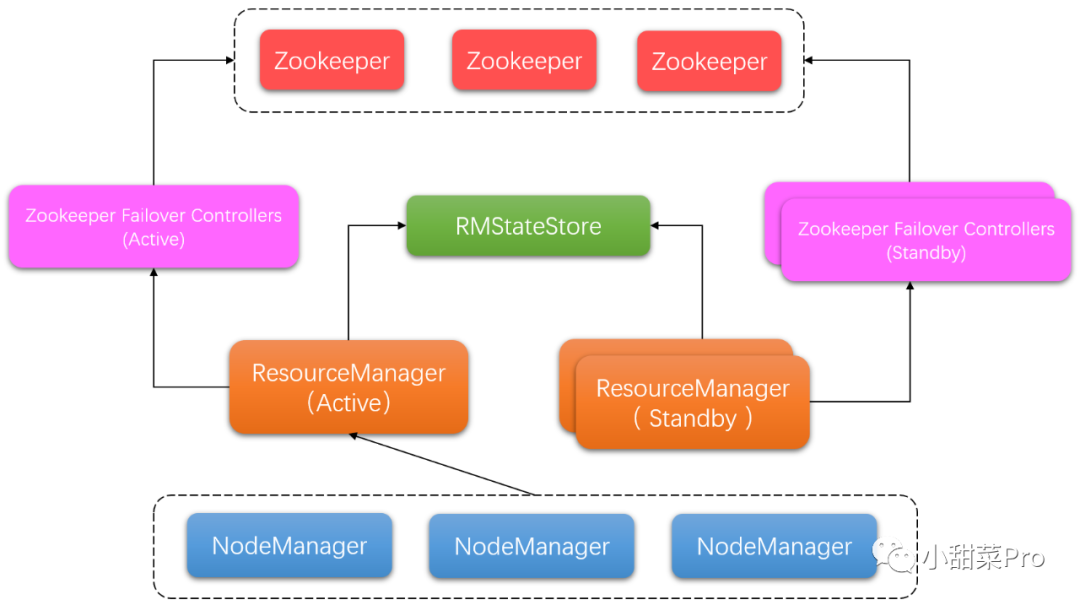
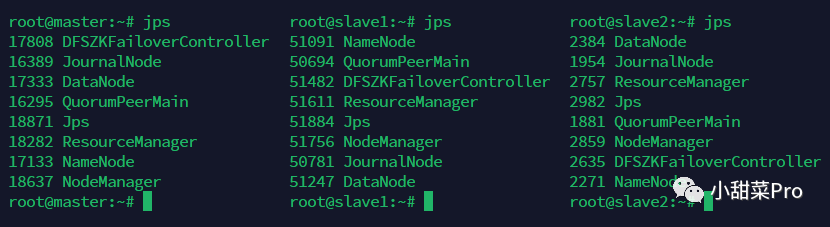
jps命令会出现
NameNode、
DataNode、
ResourceManager、
NodeManager、
JournalNode、
DFSZKFailoverController、
QuorumPeerMain和
Jps8个进程。
$HADOOP_HOME/sbin/stop-yarn.sh && $HADOOP_HOME/sbin/stop-dfs.sh # 关闭HDFS和Yarn集群(在master节点上执行)
$ZOOKEEPER_HOME/bin/zkServer.sh stop # 关闭Zookeeper进程(所有节点上执行)
$HADOOP_HOME/bin/hdfs haadmin -getAllServiceState命令查看各个节点NameNode状态,接下来停止active状态节点的NameNode进程,随后再启动该节点NameNode进程,最后再次查看状态,可以发现HDFS HA是安装成功的。
root@master:~# $HADOOP_HOME/bin/hdfs haadmin -getAllServiceState # 查看各个节点NameNode状态
master:8020 active
slave1:8020 standby
slave2:8020 standby
root@master:~# jps | grep NameNode # 查看NameNode进程pid
3613 NameNode
root@master:~# kill -9 3613 # 停止NameNode进程
root@master:~# $HADOOP_HOME/bin/hdfs --daemon start namenode # 再次启动NameNode进程
root@master:~# jps | grep NameNode # 查看NameNode进程pid
5490 NameNode
root@master:~# $HADOOP_HOME/bin/hdfs haadmin -getAllServiceState # 查看各个节点NameNode状态
master:8020 standby
slave1:8020 active
slave2:8020 standby
$HADOOP_HOME/bin/yarn rmadmin -getAllServiceState命令查看各个节点ResourceManager状态,接下来停止active状态节点的ResourceManager进程,随后再启动该节点ResourceManager进程,最后再次查看状态,可以发现YARN HA是安装成功的。
root@master:~# $HADOOP_HOME/bin/yarn rmadmin -getAllServiceState # 查看各个节点ResourceManager状态
master:8033 active
slave1:8033 standby
slave2:8033 standby
root@master:~# jps | grep ResourceManager # 查看ResourceManager进程pid
4756 ResourceManager
root@master:~# kill -9 4756 # 停止ResourceManager进程
root@master:~# $HADOOP_HOME/bin/yarn --daemon start resourcemanager # 再次启动ResourceManager进程
root@master:~# jps | grep ResourceManager # 查看ResourceManager进程pid
5828 ResourceManager
root@master:~# $HADOOP_HOME/bin/yarn rmadmin -getAllServiceState # 查看各个节点ResourceManager状态
master:8033 standby
slave1:8033 active
slave2:8033 standby
文章转载自小甜菜Pro,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
