




这一节,我们讲一下MySQL的读写分离,了解下什么是读写分离,为什么读写分离,何时读写分离,以及读写分离的方法。
1 What 读写分离
1.1 读写分离介绍
一句话描述,多个具有相同数据的MySQL实例,让主数据库(master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库(slave)分担处理SELECT查询操作,这种方法通常称为“读写分离”。
在单台mysql实例的情况下,所有的读写操作都集中在这一个实例上。当读压力太大,单台mysql实例扛不住时,此时DBA一般会将数据库配置成集群,一个master(主库),多个slave(从库),master将数据通过binlog的方式同步给slave,可以将slave节点的数据理解为master节点数据的全量备份。关于如何配置mysql主从同步,可以参考mysql官方文档:https://dev.mysql.com/doc/refman/5.7/en/replication.html
从应用的角度来说,需要对读(select、show、explain等)、写(insert、update、delete等)操作进行区分。如果是写操作,就走主库,主库会将数据同步给从库;之后有读操作,就走从库,从多个slave中选择一个,查询数据。上述流程如下图所示:

1.2 主从同步
1.2.1 binlog是什么?有什么作用?
全名binarylog,一种日志文件,保存了Mysql服务器实例上数据修改的日志信息,包含全量的mysql增删改查数据。
用于主从复制,在主从结构中,binlog 作为操作记录从 master 被发送到 slave,slave服务器从 master 接收到的日志保存到 relay log 中。
用于数据备份,在数据库备份文件生成后,binlog保存了数据库备份后的详细信息,以便下一次备份能从备份点开始。
我们可以通过mysql提供的查看工具mysqlbinlog查看文件中的内容,例如 mysqlbinlog mysql-bin.00001 | more,binlog文件大小和个数会不断的增加,后缀名会按序号递增,例如mysql-bin.00002等。
1.2.2 主从复制
mysql主从复制需要三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread)
binlog dump线程:主库中有数据更新时,根据设置的binlog格式,将更新的事件类型写入到主库的binlog文件中,并创建log dump线程通知slave有数据更新。当I/O线程请求日志内容时,将此时的binlog名称和当前更新的位置同时传给slave的I/O线程。
I/O线程:该线程会连接到master,向log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的relay log中。
SQL线程:该线程检测到relay log有更新后,会读取并在本地做redo操作,将发生在主库的事件在本地重新执行一遍,来保证主从数据同步。
下图描述了复制的过程:
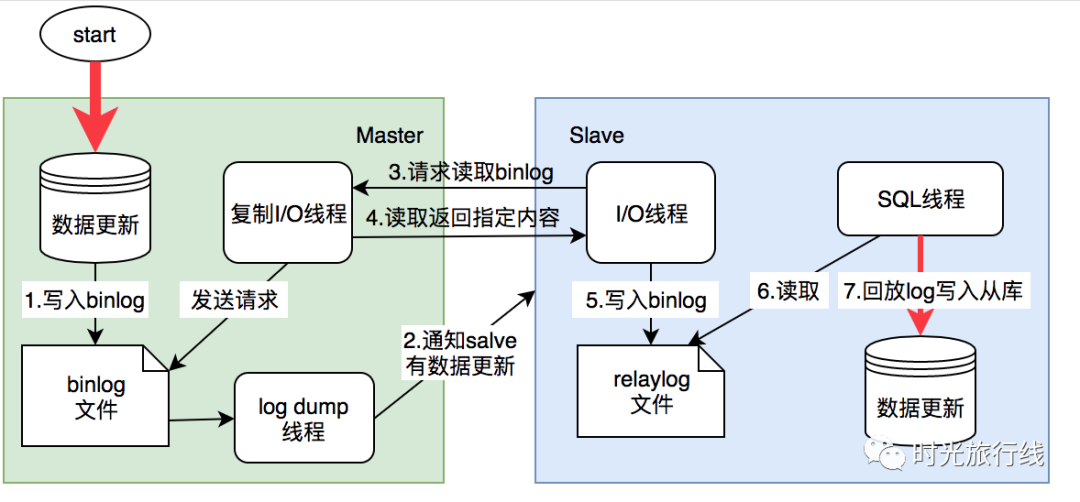
过程解析
主库写入数据并且生成binlog文件。该过程中MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。
在事件写入二进制日志完成后,master通知存储引擎提交事务。
从库服务器上的IO线程连接Master服务器,请求从执行binlog日志文件中的指定位置开始读取binlog至从库。
主库接收到从库的IO线程请求后,其上复制的IO线程会根据Slave的请求信息分批读取binlog文件然后返回给从库的IO线程。
Slave服务器的IO线程获取到Master服务器上IO线程发送的日志内容、日志文件及位置点后,会将binlog日志内容依次写到Slave端自身的Relay Log(即中继日志)文件的最末端,并将新的binlog文件名和位置记录到master-info文件中,以便下一次读取master端新binlog日志时能告诉Master服务器从新binlog日志的指定文件及位置开始读取新的binlog日志内容。
从库服务器的SQL线程会实时监测到本地Relay Log中新增了日志内容,然后把RelayLog中的日志翻译成SQL并且按照顺序执行SQL来更新从库的数据。
从库在relay-log.info中记录当前应用中继日志的文件名和位置点以便下一次数据复制。
2 Why 读写分离
当单台MySQL无法满足要求的时候,只能用多个MySQL实例来承担大量的读写请求。MySQL和大部分常用的关系型数据库一样,都是典型的单机数据库,不支持分布式部署。用一个单机数据库的多个实例来组成一个集群,提供分布式数据库服务,是一个非常困难的事儿。
在部署集群的时候,需要做很多额外的工作,而且很难做到对应用透明,那你的应用程序也要为此做较大的架构调整。所以,除非系统规模真的大到只有这一条路可以走,不建议你对数据进行分片,自行构建MySQL集群,代价非常大。
一个简单而且非常有效的方案是即采用数据库的读写分离。读写分离之所以能够解决问题,它实际上是基于一个对我们非常有利的客观情况,那就是,很多系统,特别是面对公众用户的互联网系统,对数据的读写比例是严重不均衡的。读写比一般都在几十左右,平均每发生几十次查询请求,才有一次更新请求。换句话来说,数据库需要应对的绝大部分请求都是只读查询请求。
一个分布式的存储系统,想要做分布式写是非常非常困难的,因为很难解决好数据一致性的问题。但实现分布式读就相对简单很多,我只需要增加一些只读的实例,只要能够把数据实时的同步到这些只读实例上,保证这这些只读实例上的数据都随时一样,这些只读的实例就可以分担大量的查询请求。
2.1 读写分离优点
避免单点故障。
负载均衡,读能力水平扩展。通过配置多个slave节点,可以有效的避免过大的访问量对单个库造成的压力。
通过读写分离这样一个简单的存储架构升级,就可以让数据库支持的并发数量增加几倍到十几倍。所以,当你的系统用户数越来越多,读写分离应该是你首先要考虑的扩容方案。
3 How 读写分离
主库负责执行应用程序发来的所有数据更新请求,然后异步将数据变更实时同步到所有的从库中去,这样,主库和所有从库中的数据是完全一样的。多个从库共同分担应用的查询请求。
然后我们简单说一下,如何来实施MySQL的读写分离方案。你需要做两件事儿:
3.1 分离步骤
部署一主多从多个MySQL实例,并让它们之间保持数据实时同步。
分离应用程序对数据库的读写请求,分别发送给从库和主库。
MySQL自带主从同步的功能,经过简单的配置就可以实现一个主库和几个从库之间的数据同步,部署和配置的方法,你看MySQL的官方文档照着做就可以。
3.2 分离应用程序的读写请求方法的三种方式:
纯手工方式:修改应用程序的DAO层代码,定义读写两个数据源,指定每一个数据库请求的数据源。
组件方式:也可以使用像Sharding-JDBC这种集成在应用中的第三方组件来实现,这些组件集成在你的应用程序内,代理应用程序的所有数据库请求,自动把请求路由到对应数据库实例上。
代理方式:在应用程序和数据库实例之间部署一组数据库代理实例,比如说Atlas或者MaxScale。对应用程序来说,数据库代理把自己伪装成一个单节点的MySQL实例,应用程序的所有数据库请求被发送给代理,代理分离读写请求,然后转发给对应的数据库实例。
这三种方式,我最推荐的是第二种,使用读写分离组件。这种方式代码侵入非常少,并且兼顾了性能和稳定性。如果你的应用程序是一个逻辑非常简单的微服务,简单到只有几个SQL,或者是,你的应用程序使用的编程语言没有合适的读写分离组件,那你也可以考虑使用第一种纯手工的方式来实现读写分离。
一般情况下,不推荐使用第三种代理的方式,原因是,使用代理加长了你的系统运行时数据库请求的调用链路,有一定的性能损失,并且代理服务本身也可能出现故障和性能瓶颈等问题。但是,代理方式有一个好处是,它对应用程序是完全透明的。所以,只有在不方便修改应用程序代码这一种情况下,你才需要采用代理方式。
另外,如果你配置了多个从库,推荐你使用“HAProxy+Keepalived”这对儿经典的组合,来给所有的从节点做一个高可用负载均衡方案,既可以避免某个从节点宕机导致业务可用率降低,也方便你后续随时扩容从库的实例数量。因为HAProxy可以做L4层代理,也就是说它转发的是TCP请求,所以用“HAProxy+Keepalived”代理MySQL请求,在部署和配置上也没什么特殊的地方,正常配置和部署就可以了。
4 读写分离挑战
对sql类型进行判断。如果是select等读请求,就走从库,如果是insert、update、delete等写请求,就走主库。
主从数据同步延迟问题。因为数据是从master节点通过网络同步给多个slave节点,因此必然存在延迟。因此有可能出现我们在master节点中已经插入了数据,但是从slave节点却读取不到的问题。对于一些强一致性的业务场景,要求插入后必须能读取到,因此对于这种情况,
降低多线程大事务并发的概率,优化业务逻辑
优化SQL,避免慢SQL,减少批量操作,建议写脚本以update-sleep这样的形式完成。
提高从库机器的配置,减少主库写binlog和从库读binlog的效率差。
尽量采用短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。
实时性要求的业务读强制走主库,从库只做灾备,备份。
事务问题。如果一个事务中同时包含了读请求(如select)和写请求(如insert),如果读请求走从库,写请求走主库,由于跨了多个库,那么jdbc本地事务已经无法控制,属于分布式事务的范畴。而分布式事务非常复杂且效率较低。因此对于读写分离,目前主流的做法是,事务中的所有sql统一都走主库,由于只涉及到一个库,jdbc本地事务就可以搞定。
高可用问题。主要包括:
新增slave节点:如果新增slave节点,应用应该感知到,可以将读请求转发到新的slave节点上。
slave宕机或下线:如果其中某个slave节点挂了/或者下线了,应该对其进行隔离,那么之后的读请求,应用将其转发到正常工作的slave节点上。
master宕机:需要进行主从切换,将其中某个slave提升为master,应用之后将写操作转到新的master节点上。

若有收获,就点个赞吧
