




Table of Contents
一. 问题描述
今天接到一个新需求,hive表里面有个字段存储的是XML类型数据
数据格式:
<a> <b>bb</b> <c>cc</c> </a>复制
二. 解决方案
2.1 官方文档
遇到不懂的问题,首先上官方文档查询相关文档,然后照着官网的demo改改,一般就能解决问题了
官方文档地址:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+XPathUDF
丰富的XML相关函数及测试用例
代码:
-- 求路径 a/b下面的值
SELECT xpath_string ('<a><b>bb</b><c>cc</c></a>', 'a/b') LIMIT 1 ;
复制测试记录:
hive> > SELECT xpath_string ('<a><b>bb</b><c>cc</c></a>', 'a/b') LIMIT 1 ; OK bb Time taken: 1.477 seconds, Fetched: 1 row(s) hive>复制
2.2 XML格式不规范
因为Hive不支持XML数据格式,后端写入数据库存的是一个String类型,此时格式就没那么规范了,会有一些特殊字符
解析xml报错,原来是有特殊字符
https://stackoverflow.com/questions/730133/what-are-invalid-characters-in-xml
xml不符合规范的字符
https://blog.csdn.net/u014589856/article/details/107151252
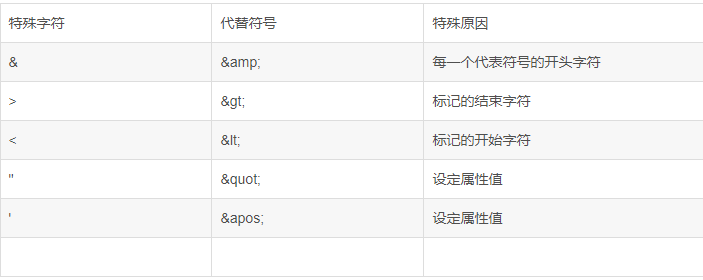
通过正则表达式删除特殊字符:
- 下面几个是常用的特殊字符
@&$#% regexp_replace(the_gifts,'[@&$#%]','')复制
- 只保留 大小写字母 数字 及中文 以及 xml标签
regexp_replace(the_gifts,'(^[a-z]+|[A-Z]+|[0-9]+|[\\u4E00-\\u9FA5]+[</>])','')复制
最后修改时间:2023-05-26 10:00:13
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
