




常用SQL技巧主要介绍有:MySQL正则表达式。提取随机行函数RAND()。WITH ROLLUP子句。Bit GROUP Functions 做统计。数据库库名、表名大小写注意事项。使用外键注意事项。
只停留在看上面,提升效果甚微。应该带着思考去测试佐证,或者使用(同类书籍)新版本进行对比,这样带来的效果更好。最重要的一环,养成阅读官方文档,是一个良好的习惯。能编写官方文档,至少证明他们在这个领域是有很高的造诣,对用法足够熟练。
示例数据库使用MySQL官方提供的sakila-db(模拟电影出租信息管理系统)和world-db数据库,类似于Oracle的scott用户,文末有提供下载地址。
如果没有进行特别说明,一般是基于MySQL8.0.28进行测试验证。官方文档非常具有参考意义。你可以将这篇博文,当成过度到MySQL8.0的参考资料。
友情提示:经验是用来参考,不是拿来即用。如果您能看到并分享这篇文章,我很荣幸。如果有误导您的地方,我表示抱歉。

注意:在某些情况,你自己测试的结果可能与我演示有所不同,我省略了查询结果的部分参数。
如果你是从MySQL5.6或者5.7版本过渡到MySQL8.0。学习之前,建议看官方文档这一章节:1.3 What Is New MySQL8.0 。在做对比的时候,文档中带有Note标识是你应该注意的地方。比如下面这张截图:

常用SQL技巧主要介绍有:正则表达式。正则表达式泛用性比较广,无论在数据库SQL中还是Java语言以及Linux操作系统grep搜索匹配都用得上,甚至网页爬虫也很实用。
01
使用正则表达式
在MySQL8.0文档中,你可以找到参考使用方法:
12.8.2 Regular Expression Function and Operator Descriptions MySQL8.0官网文档:refman-8.0-en.pdf
正则表达式(Regular Expression)是指用来描述或匹配一系列符合某个句法规则的字符串的单个字符串。在多数文本编辑器或其它工具里,正则表达式通常被用来检索或替换哪些符合某个模式的文本内容。许多程序语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式最初是由UNIX中的工具软件(例如SED和GREP)普及开来,通常写成REGEX 或者 REGEXP。
穿插一点额外知识,在Linux操作系统中输入pcretest即可进入练习使用正则表达式(新版本pcre2test):
$ wget https://download.fastgit.org/PhilipHazel/pcre2/releases/download/pcre2-10.39/pcre2-10.39.tar.gz$ tar -zxvf pcre2-10.39.tar.gz$ cd pcre2-10.39$ ./configure$ make && make install$ pcre2test
MySQL利用REGEXP命令提供给用户扩展正则表达式功能,REGEXP实现的功能类似于UNIX上GREP和SED功能,并且REGEXP在进行模式匹配是是区分大小写的。熟悉掌握REGEXP用法,可以使模式匹配事半功倍。接下来将介绍一些在MySQL中的用法。
正则表达式函数和操作符如下表格所示:
名称 | 描述 |
NOT REGEXP | 否定的REGEXP |
REGEXP | 正则表达式是否匹配字符串 |
REGEXP_INSTR() | 匹配正则表达式子字符串的起始索引 |
REGEXP_LIKE() | 正则表达式是否匹配字符串 |
REGEXP_REPLACE() | 替换正则表达式匹配的子字符串 |
REGEXP_SUBSTR() | 返回正则表达式匹配的子字符串 |
RLIKE | 正则表达式是否匹配字符串 |
在MySQL中一些正则表达式匹配符号含义:
符号 | 含义 |
^ | 在字符开始处进行匹配(行首) |
$ | 字符串末尾进行匹配(行尾) |
. | 匹配任意单个字符,包括换行符 |
[......] | 匹配括号中任意字符 |
[^......] | 匹配不包含括号中任意字符 |
a* | 匹配0个或多个a(包含空串) |
a+ | 匹配1个或多个a(不包含空串) |
a? | 匹配1个或0个a |
a1 | a2 | 匹配a1或a2 |
a(m) | 匹配m个a |
(……) | 将模式元素组成单一元素 |
下面将带来实际示例REGEXP用法:


REGEXP_INSTR用法:
SELECT REGEXP_INSTR('dog cat dog', 'dog');-- 返回结果: 1SELECT REGEXP_INSTR('dog cat dog', 'dog', 2);-- 返回结果: 9SELECT REGEXP_INSTR('aa aaa aaaa', 'a{2}');-- 返回结果: 1SELECT REGEXP_INSTR('aa aaa aaaa', 'a{4}');-- 返回结果: 8
REGEXP_LIKE用法:
SELECT REGEXP_LIKE('CamelCase', 'CAMELCASE');-- 返回结果:1
不做过多演示,使用比较容易上手,可以参考官方文档。
02
RAND() 提取随机行
大多数数据库都会提供产生随机数的包或者函数,通过这些包或者函数可以产生用户需要的随机数。也可以从数据表中抽取随机产生的记录,这对抽样分析有一定的帮助。个人在MySQL开发篇进行测试生成1kw条数据,就用到了随机数RAND()函数。在Oracle数据库中可以使用DBMS_RANDOM包产生随机数。例如在Oracle中学表随机生成1kw条数据:
-- 创建表
CREATE TABLE test.student(
ID NUMBER not null primary key,
STU_NAME VARCHAR2(60) not null,
STU_AGE NUMBER(4,0) NOT NULL,
STU_SEX VARCHAR2(2) not null)
-- 学生表随机生成1kw数据
insert into test.studentselect rownum,
dbms_random.string('*',dbms_random.value(6,10)),
dbms_random.value(14,16),'女' from dualconnect by level<=10000000
上面只是提一下穿插一点Oracle中的用法,主要介绍重点是MySQL。在MySQL中,产生随机数是RAND() 函数。
创建表 t 以及插入测试数据。提示:不用创建表,你也可以直接在RAND后面圆括号中加入数字进行测试。
mysql> CREATE TABLE t (i INT);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO t VALUES(1),(2),(3);
Query OK, 3 rows affected (0.01 sec)Records: 3 Duplicates: 0 Warnings: 0
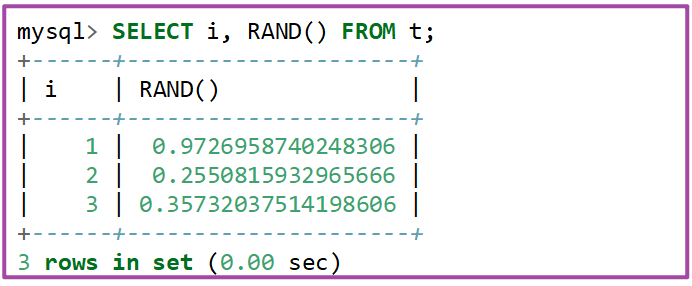
演示查询RAND():
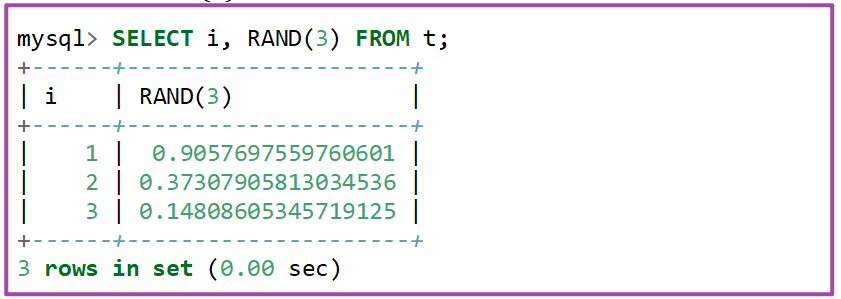
演示查询 RAND(X) 加入参数:X=3
RAND()函数用法有好几种,如下:
RAND():最原始用法,不加参数;
RAND(X):加入一个X参数,比如RAND(3);
RAND(X,D):加入两个参数表示范围,比如RAND(1,2);
示例:RAND(X,D)用法
SELECT ROUND(1.298,1);
*************************** 1. row ***************************
ROUND(1.298, 1): 1.31 row in set (0.00 sec)
补充一点:RAND() 可以配合 ORDER BY 和 GROUP BY 以及 LIMIT 进行使用。
SELECT * FROM tbl_name ORDER BY RAND();
SELECT * FROM table1, table2 WHERE a=b AND c<d ORDER BY RAND() LIMIT 1000;
03
GROUP BY 与 WITH ROLLUP 子句
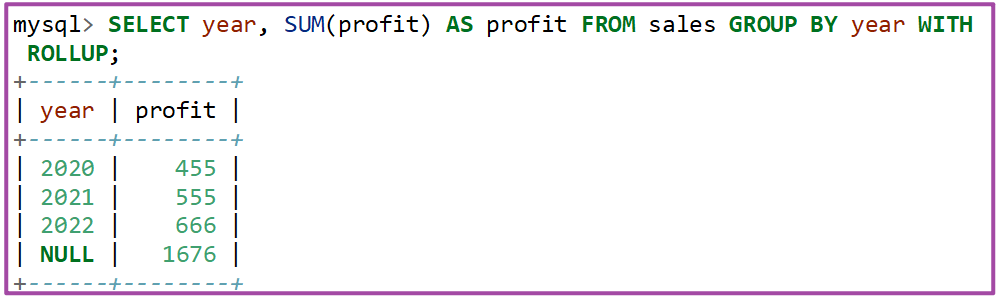
在SQL语句中,使用GROUP BY配合WITH ROLLUP 子句可以检索出更多分组聚合信息,不仅仅局限于GROUP BY检索出各组聚合信息,而且还能检索出本组类的整体聚合信息,创建实例如下所示。
创建一张某产品销售利润统计表进行演示:

根据年度进行分组,然后查询统计年度某产品利润:

使用ROLLUP检索出更多信息。显示每年的总利润,要确定所有年份的总利润,必须自己加起来,或者运行一个额外的查询。或者您可以使用ROLLUP,它提供两种级别的分析。
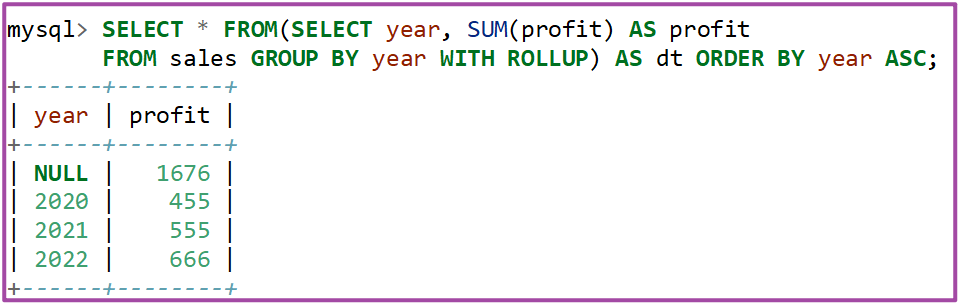
配合WITH ROLLUP使用GROUP BY分组后面可以接多个字段使用,以及使用IF条件加入GROUPING进行统计,这里不做演示。
注意事项:以前,MySQL不允许在带有WITH ROLLUP选项的查询中使用DISTINCT或ORDER BY。这个限制在MySQL 8.0.12及更高版本中被取消(Bug #87450,Bug #86311,Bug #26640100,Bug #26073513)。此外,LIMIT在ROLLUP后面。
我所展示版本是MySQL8.0.28,支持WITH ROLLUP选项的查询中使用DISTINCT或ORDER BY。
04
Bit GROUP Functions 做统计
你可以找到参考文档:
12.13 Bit Functions and Operators MySQL8.0官网文档:refman-8.0-en.pdf
此处,不做详细解释,只展示具体使用。
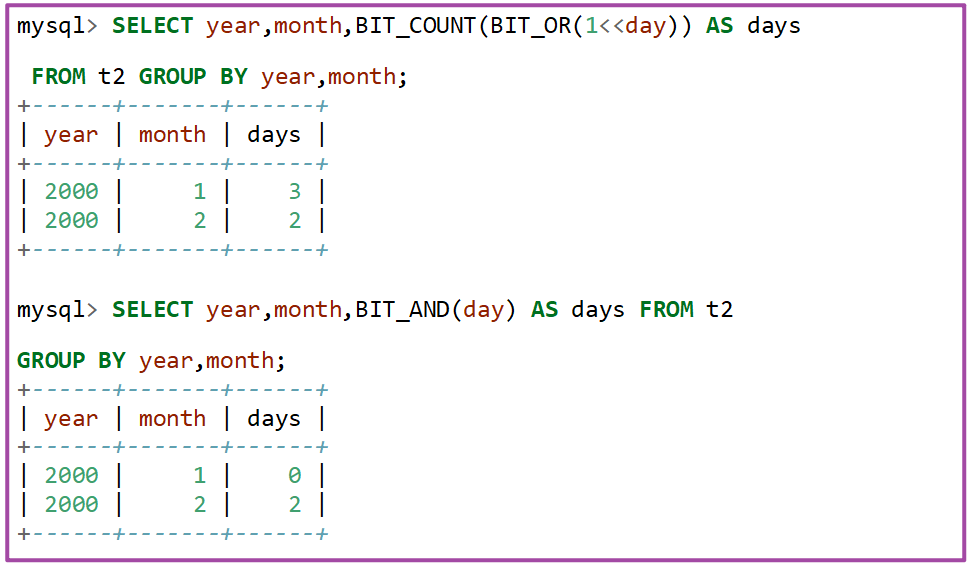
以下演示GROUP BY语句和BIT_OR、BIT_AND函数完成统计工作。这两个函数一般用于做数值间的逻辑运算,当将它们与GROUP BY子句联合使用时可以做一些其它的任务。
以下是创建一张示例表t2并插入6条测试数据:

使用BIT_COUNT以及BIT_OR、BIT_AND进行查询:
05
数据库库名、表名大小写问题
MySQL数据库对应操作系统下的数据目录。数据库中每张表至少对应数据库目录中一个文件(也可能是多个,存储引擎类型不同,有所差异)。
因此,使用的操作系统大小写敏感性决定了数据库名、表名大小写的敏感性。
在Unix操作系统中,操作系统对大小敏感,导致数据库名、表名对大小写敏感。
而Windows平台MySQL数据库对大小写不敏感,因为操作系统本身对大小写不敏感。
列、索引、存储子程序和触发器名在任何平台上对大小写不敏感。默认情况,表别名在Unix中对对大小敏感,但在Windows平台对大小写并不敏感。如下在Linux平台进行演示,由于区分大小写,所以抛出错误提示:
mysql> select * from girl;ERROR 1146 (42S02):
Table 'test.girl' doesn't exist
正常情况,使用大写表名进行查找:

如上报错以及正常返结果查询操作在Windows平台都可以正常执行。如果想尽可能避免出现差错,统一规范,例如创建时统一使用小写创建库名、表名。
MySQL数据库中,如何在硬盘中保存使用表名、数据库名是由lower_case_table_names系统变量决定的,用户可以在启动MySQL服务之前设置系统变量值(由于Dynamic=no,非动态)。具体设置对应操作系统、以及含义如下表格:
参数值 | 操作系统 | 含义 |
0 | Unix默认值 | 如果设置为0,表名将按指定的方式存储,并且比较是区分大小写的。对大小写敏感。如果在不区分大小写的文件系统上强制使用0,并使用不同字母大小写访问MyISAM表,可能会导致索引损坏。 |
1 | Windows默认值 | 如果设置为1,表名在磁盘上以小写存储,MySQL在存储和查找时将所有表名转换为小写。同样使用数据库名和别名。 |
2 | macOS默认值 | 如果设置为2,表名将以给定的形式存储,比较时使用小写。MySQL将其转换为小写以便查找,适用于不区分大小写的文件系统。 |
例如:Windows平台使用如下SQL语句进行查询系统默认设置lower_case_table_names值,返回结果是1

设置--lower-case-table-names[=#]参数值,在Windows平台直接编辑my.ini文件,在Linux操作系统可以使用vim编辑/etc/my.cnf中新增如下设置:
# my.cnf or my.ini[mysqld]## --lower-case-table-names[=#] #命令行格式:参数值可以为0 1 2,根据系统平台设定#examplelower-case-table-names=1 # Windows平台默认值lower-case-table-names=0 # Linux默认值为0,设置0和1都可以成功启动
tips:如果在单个平台使用,影响不是很大。使用时尽可能在同一查询中使用相同大小写来引用数据库名或表名,养成一个良好习惯。
06
使用外键注意事项
在MySQL中,InnoDB存储引擎支持对外部关键字约束条件检查。对于其它类型存储引擎的表,当使用REFERENCES tbl_name(col_name,...)子句定义列时可以使用外部关键字,但该子句没有实际效果,可以作为注释提醒用户目前定义的列指向另一表中的一个列。具体语法在此处,不做演示,在第三章节锁问题(InnoDB锁问题:外键与锁有说明)。
接下来,演示不同类型存储引擎使用外键效果,具体也只演示MyISAM和InnoDB存储引擎使用外键创建父(parent)表和子(child)表。示例如下:
6.1 MyISAM存储引擎建立有外键父表与子表


测试插入数据:父表(parent)插入一条演示数据,子表(child)插入3条演示数据,有级联关系。如果父表内容被修改,子表三条关联外键内容也应该修改过来。实际上MyISAM存储引擎并不支持外键,所以不生效。
INSERT INTO parent (id) VALUES (1);
INSERT INTO child (id,parent_id) VALUES(1,1),(2,1),(3,1);
UPDATE parent SET id = 2 WHERE id = 1;
最后验证查询有关联的子表,数据并没有变化:

你还可以使用语句show create table tbl_name命令查看创建的表child并没有显示外键信息,而InnoDB存储引擎会显示外键信息。

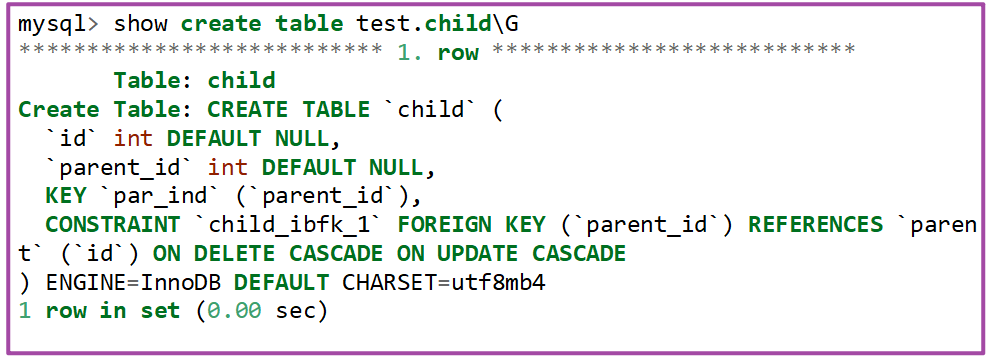
6.2 InnoDB存储引擎建立有外键父表与子表
DROP TABLE parent;-- 删除原有parent,创建子表CREATE TABLE parent (id INT NOT NULL,PRIMARY KEY (id)) ENGINE=INNODB;
DROP TABLE child;
-- 重新创建子表child,并加入给update与delete条件加入CASCADE
CREATE TABLE child (
id INT,parent_id INT,
INDEX par_ind (parent_id),
FOREIGN KEY (parent_id)
REFERENCES parent(id)
ON UPDATE CASCADEON DELETE CASCADE) ENGINE=INNODB;
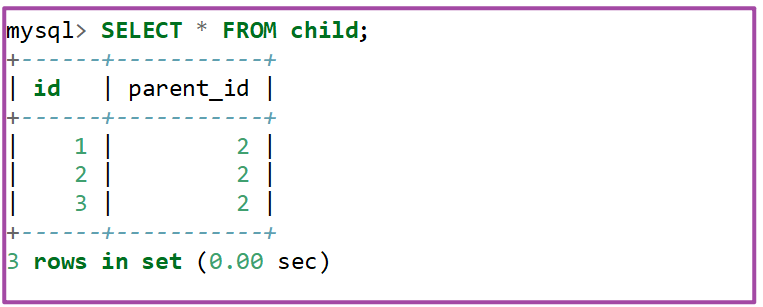
测试插入数据:父表(parent)插入一条演示数据,子表(child)插入3条演示数据,有级联关系。如果父表内容被修改,子表三条关联外键内容也应该修改过来。InnoDB存储引擎支持外键,所以级联修改起作用,parent_id值被集体修改为2。
INSERT INTO parent (id) VALUES (1);
INSERT INTO child (id,parent_id) VALUES(1,1),(2,1),(3,1);
UPDATE parent SET id = 2 WHERE id = 1;
最后验证查询有关联的子表,查询演示数据:
更加详细演示,在下面外键与锁章节描述比较详细。也可以参考官方文档示例:product_order、product、customer这三张表之间使用外键进行操作。模拟产品(product)、顾客(customer)、订单(product_order)三张表关联关系,订单表设置级联(CASCADE)关系,并且同时引用产品与顾客相应字段作为外键引用。
CREATE TABLE product (
category INT NOT NULL,
id INT NOT NULL,
price DECIMAL,
PRIMARY KEY(category, id)
) ENGINE=INNODB;
CREATE TABLE customer (
id INT NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB;
CREATE TABLE product_order (
no INT NOT NULL AUTO_INCREMENT,
product_category INT NOT NULL,product_id INT NOT NULL,
customer_id INT NOT NULL,PRIMARY KEY(no),
INDEX (product_category, product_id),
INDEX (customer_id),
FOREIGN KEY (product_category, product_id)
REFERENCES product(category, id)
ON UPDATE CASCADE ON DELETE RESTRICT,
FOREIGN KEY (customer_id)REFERENCES customer(id)) ENGINE=INNODB;
07
MySQL官方示例数据库
给出sakila-db数据库包含三个文件,便于大家获取与使用:
sakila-schema.sql:数据库表结构;
sakila-data.sql:数据库示例模拟数据;
sakila.mwb:数据库物理模型,在MySQL workbench中可以打开查看。
最后附上官方示例数据库,sakila-db数据库一个非常完整的示例。包含:视图、函数、触发器以及存储过程,当然也存在使用外键。
https://downloads.mysql.com/docs/sakila-db.zip
world-db数据库,只包含三张表:city、country、countrylanguage。
https://downloads.mysql.com/docs/world-db.zip
08
MySQL官方文档下载地址
左侧导航栏有个Download this Manual:MySQL文档下载地址。
以下给出目前比较火热的三个版本下载地址:
MySQL8.0在线文档
https://dev.mysql.com/doc/refman/8.0/en
MySQL8.0文档PDF文件下载地址https://downloads.mysql.com/docs/refman-8.0-en.a4.pdf
MySQL5.7在线文档
https://dev.mysql.com/doc/refman/5.7/en/
MySQL5.7文档PDF文件下载地址https://downloads.mysql.com/docs/refman-5.7-en.a4.pdf
MySQL5.6在线文档
https://dev.mysql.com/doc/refman/5.6/en/
MySQL5.6文档PDF文件下载地址[https://downloads.mysql.com/docs/refman-5.6-en.a4.pdf
参考资料&鸣谢:
《深入浅出MySQL 第2版 数据库开发、优化与管理维护》。
《MySQL技术内幕InnoDB存储引擎 第2版》。
MySQL8.0官网文档:refman-8.0-en.pdf,如果学习新版本,官方文档是非常不错的选择。
虽然书籍年份比较久远(停留在MySQL5.6.x版本),但仍然具有借鉴意义。
最后,对以上书籍和官方文档所有作者表示衷心感谢。
莫问收获,但问耕耘
能看到这里的,都是帅哥靓妹。以上是本次MySQL优化篇(上部分)全部内容,希望能对你的工作与学习有所帮助。如果感觉总结的不到位,希望能留下您宝贵的意见,我会在文章中定期进行调整优化。
好记性不如烂笔头,多实践多积累。你会发现,自己的知识宝库越来越丰富。
markdown源文件不定期上传到github仓库:
https://github.com/cnwangk/wangk-stick
--END--
