




Kaggle Models
Kaggle推出全新的Models页面,集成了数百个预训练模型,涵盖图像分类、物体检测、图像特征提取等多种应用场景,为机器学习领域的开发者提供了一个高效、方便的模型托管和部署平台。
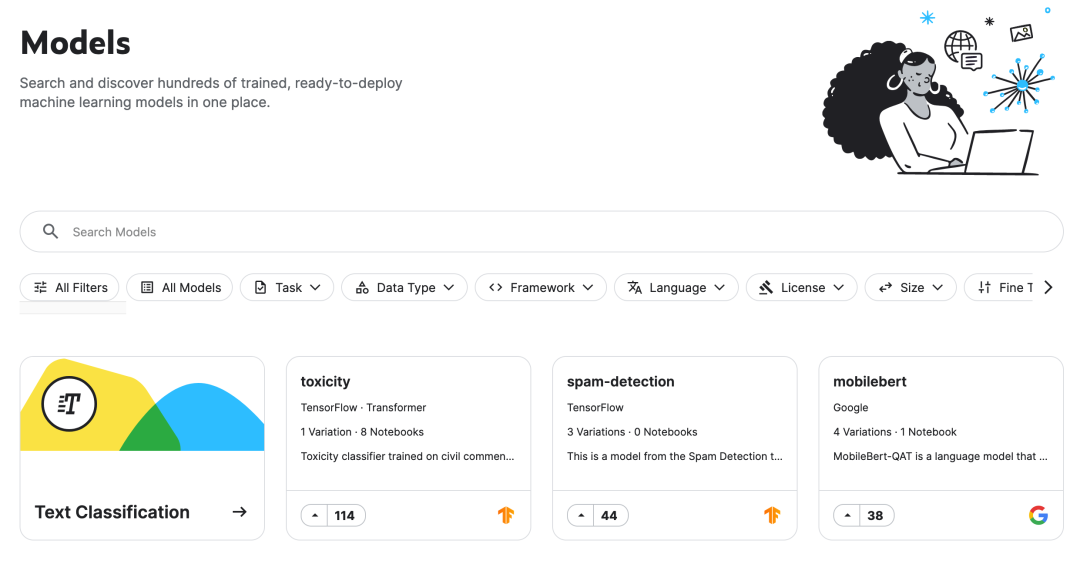
https://www.kaggle.com/models
模型筛选逻辑
据这些预训练模型不仅分类明确,还按照训练数据进行了划分,包括文本、语音、图像、视频、表格、类型和多模态。
模型还可以按照深度学习框架划分,包括TensorFlow2和Pytorch。其中,TensorFlow2的模型占据了大多数。
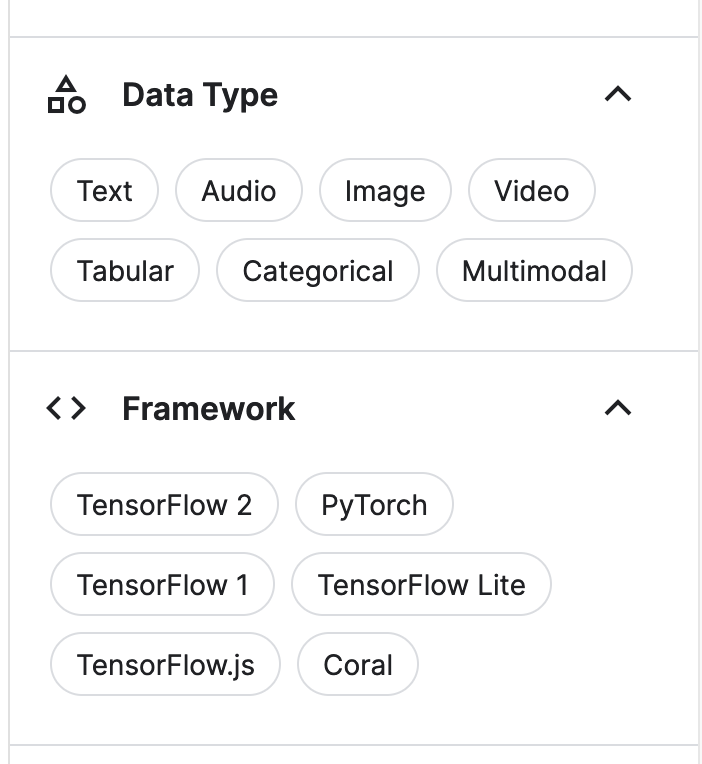
为方便开发者选择合适的模型,该页面还提供了按照版权划分、是否可以微调、模型权重大小等多个维度的筛选。每个模型都有详细的描述和性能指标,用户可以根据自己的需求进行选择。
模型使用方法
模型封装为预训练模型的方式,让开发者可以轻松地加载已经训练好的模型文件到notebook中,从而避免了复杂的模型训练过程和数据准备。
m = tf.keras.Sequential([
hub.KerasLayer("https://kaggle.com/models/google/resnet-v2/frameworks/TensorFlow2/variations/101-classification/versions/2")
])
m.build([None, 224, 224, 3]) # Batch input shape.
部分模型列表
文本分类
toxicity: Toxicity classifier trained on civil comments dataset. spam-detection: This is a model from the Spam Detection tutorial mobilebert: MobileBert-QAT is a language model that trained for SQuAD task
图像分类
resnet_v2: Imagenet (ILSVRC-2012-CLS) classification with ResNet V2 mobilenet_v2: SSD-based object detection model trained on Open Images V4 with ImageNet pre-trained MobileNet V2 as image feature extractor
Models 功能展望
笔者认为这个新功能虽然提供了很多通用的预训练模型,但是由于大部分都是TensorFlow相关的模型,这可能确实是谷歌推广自己框架的尝试。
为每个比赛包含一些优胜方案的模型是一个更好的想法。通过这种方式,Kaggle可以帮助用户更好地了解比赛中获胜的模型是如何训练和构建的,并为用户提供更多的学习资源和实践经验。
Kaggle介绍
Kaggle是一个旨在促进数据科学和机器学习发展的开放性社区,已经成为全球数据科学领域的知名品牌。
在过去的几年里,Kaggle一直致力于为数据科学家和机器学习从业者提供更便捷、高效的工具和资源。
而这一次,Kaggle推出的Models页面,则为开发者提供了一个更加便捷、快速的模型托管和部署平台。
学习交流群已成立


文章转载自Coggle数据科学,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
