




连续图上的子图匹配(Continuous Subgraph Matching) 连续子图匹配(CSM)算法是一类在线地查找给定模式在数据图流中的出现实例的算法。数据图流既对数据图的修改以数据流的形式不断给出。本文将介绍针对这个问题
背景介绍
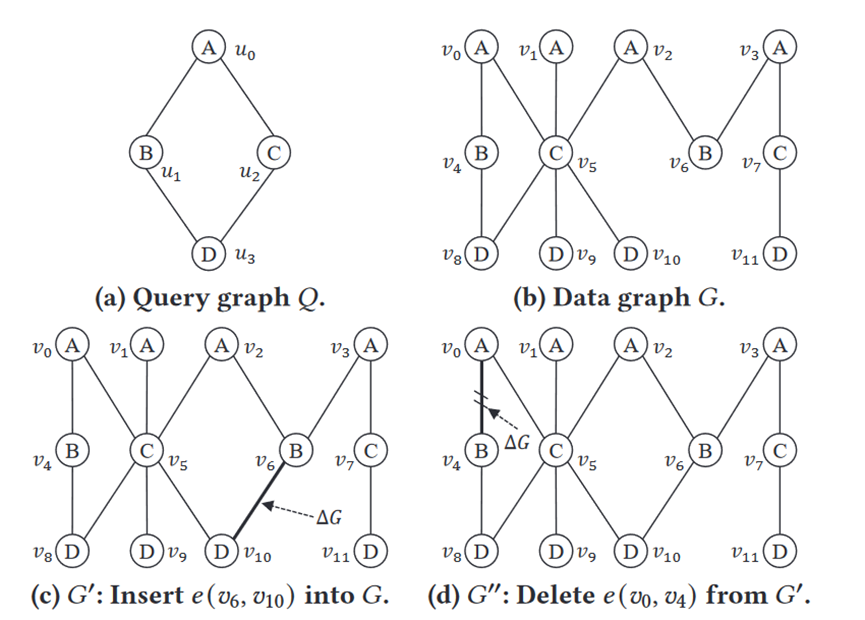
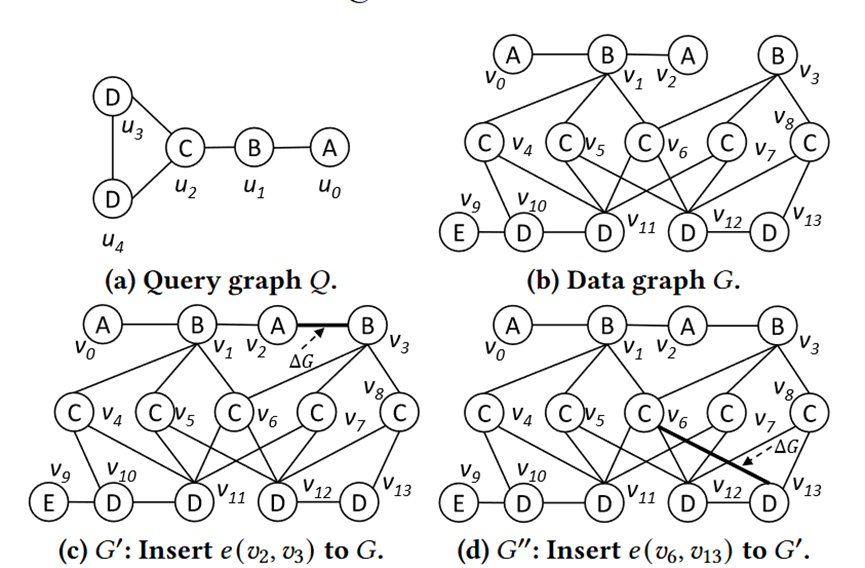
子图匹配可以看成是找到一个映射函数,将查询图上的点映射到数据图上,满足标签的要求以及连边的要求。例如上图中的(a)(b),{ u0à0, u2à5, u3à8, u1à4}就是一个满足要求的映射。
子图匹配问题的主要的优化方向有,设计剪枝策略,优化枚举顺序,以及通过辅助数据结构减少重复的计算等等。
而连续图上的子图匹配,每次有一条边或者多条边的修改,然后要求包含这些发生改变的边的匹配实例。
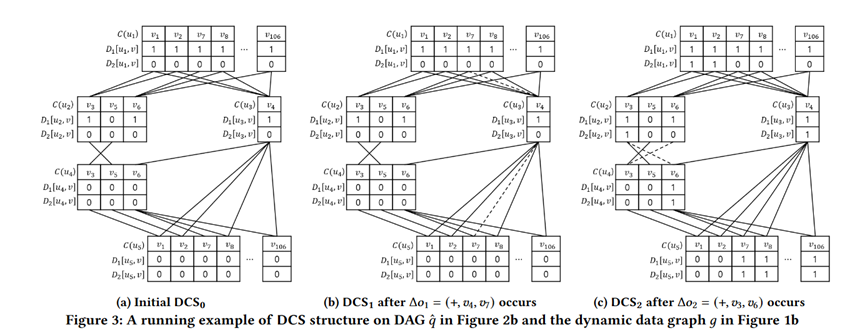
c图是一个添加的例子,d图是一个删除的例子,先找到包含删除的边的匹配实例,然后再执行删除。


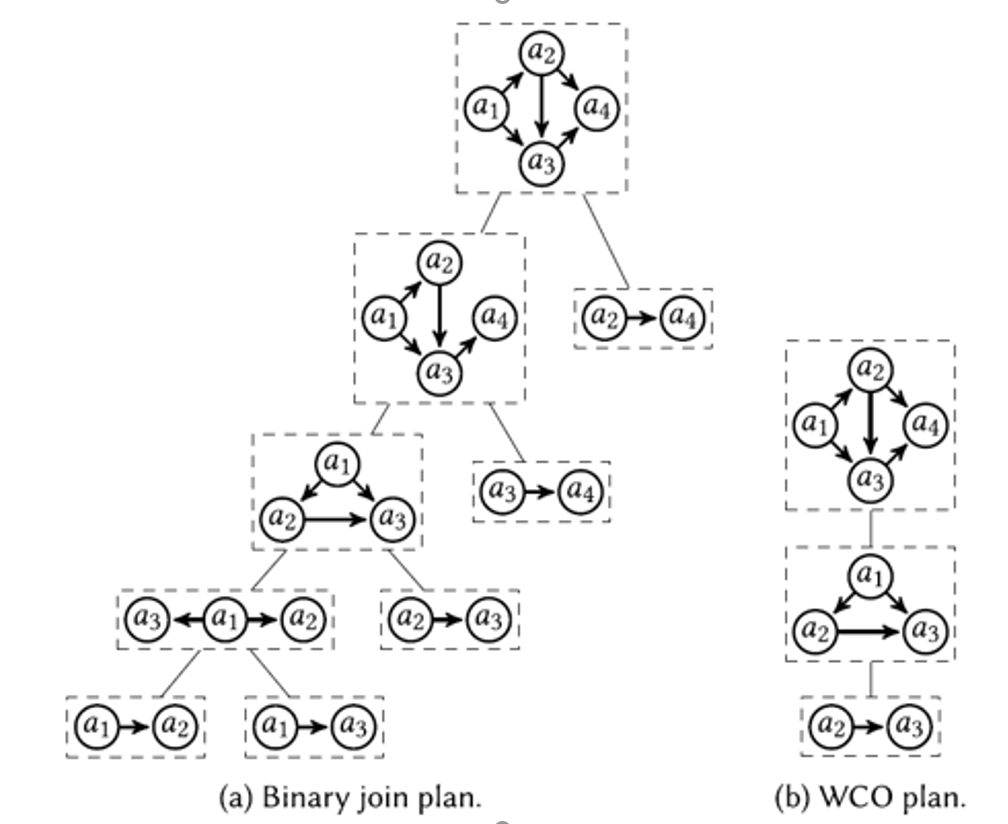

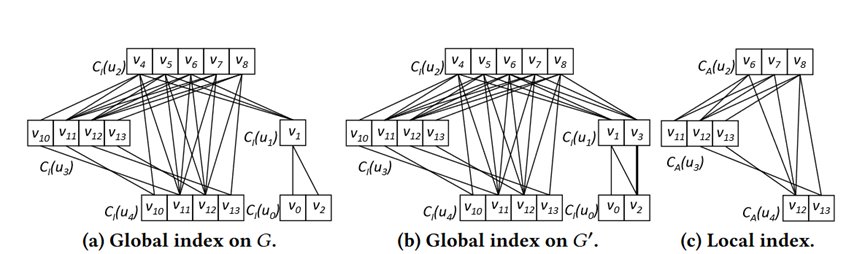
这一篇工作的主要思路是构建一个Subgraph join tree,一个基于binary join plan构成的左伸树,叶子节点是每一条边,匹配的部分结果存储在非叶子节点上。当有一条边发生更新时,只需要更新从当前点到根的路径上的节点。




参考文献
X. Sun, S. Sun, Q. Luo, and B. He, “An in-depth study of continuous subgraph matching,” Proc. VLDB Endow., vol. 15, no. 7, pp. 1403–1416, Mar. 2022, doi: 10.14778/3523210.3523218.
C. Kankanamge, S. Sahu, A. Mhedbhi, J. Chen, and S. Salihoglu, “Graphflow: An Active Graph Database,” in Proceedings of the 2017 ACM International Conference on Management of Data, Chicago Illinois USA: ACM, May 2017, pp. 1695–1698. doi: 10.1145/3035918.3056445.
S. Choudhury, L. Holder, and G. Chin, “A Selectivity based approach to Continuous Pattern Detection in Streaming Graphs”.
K. Kim et al., “TurboFlux: A Fast Continuous Subgraph Matching System for Streaming Graph Data,” in Proceedings of the 2018 International Conference on Management of Data, Houston TX USA: ACM, May 2018, pp. 411–426. doi: 10.1145/3183713.3196917.
M. Idris, M. Ugarte, and S. Vansummeren, “The Dynamic Yannakakis Algorithm: Compact and Efficient Query Processing Under Updates,” in Proceedings of the 2017 ACM International Conference on Management of Data, Chicago Illinois USA: ACM, May 2017, pp. 1259–1274. doi: 10.1145/3035918.3064027.
[1]
M. Idris, M. Ugarte, S. Vansummeren, H. Voigt, and W. Lehner, “Conjunctive Queries with Theta Joins Under Updates.” arXiv, May 23, 2019. Accessed: Apr. 10, 2023. [Online]. Available: http://arxiv.org/abs/1905.09848
S. Min, S. G. Park, K. Park, D. Giammarresi, G. F. Italiano, and W.-S. Han, “Symmetric continuous subgraph matching with bidirectional dynamic programming,” Proc. VLDB Endow., vol. 14, no. 8, pp. 1298–1310, Apr. 2021, doi: 10.14778/3457390.3457395.
M. Han, H. Kim, G. Gu, K. Park, and W.-S. Han, “Efficient Subgraph Matching: Harmonizing Dynamic Programming, Adaptive Matching Order, and Failing Set Together,” in Proceedings of the 2019 International Conference on Management of Data, Amsterdam Netherlands: ACM, Jun. 2019, pp. 1429–1446. doi: 10.1145/3299869.3319880.
S. Sun, X. Sun, B. He, and Q. Luo, “RapidFlow: an efficient approach to continuous subgraph matching,” Proc. VLDB Endow., vol. 15, no. 11, pp. 2415–2427, Jul. 2022, doi: 10.14778/3551793.3551803.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

