




1、MySQL中查看表结构主要有哪些方式? ABD
A、show create table tabl_name;
B、information_schema.columns
C、show table status like tabl_name;
D、desc tabl_name / explain tabl_name;
2、下列哪个命令可以在windows命令提示符下关闭mysql服务? D
A、net start mysql
B、stop mysql
C、net stop
D、net stop mysql
3、下面MySQL哪种数字数据类型不可以存储数据256? A
A、tinyint
B、smallint
C、int
D、bigint
为何对慢SQL进行治理
从数据库角度看:每个SQL执行都需要消耗一定I/O资源,SQL执行的快慢,决定资源被占用时间的长短。假设总资源是100,有一条慢SQL占用了30的资源共计1分钟。那么在这1分钟时间内,其他SQL能够分配的资源总量就是70,如此循环,当资源分配完的时候,所有新的SQL执行将会排队等待。 从应用的角度看:SQL执行时间长意味着等待,在OLTP应用当中,用户的体验较差
治理的优先级上
master数据库->slave数据库
目前数据库基本上都是读写分离架构,读在从库(slave)上执行,写在主库(master)上执行。
由于从库的数据都是从主库上复制过去的,主库等待较多的,会加大与从库的复制时延。
执行次数多的SQL优先治理
如果有一类SQL高并发集中访问某一张表,应当优先治理。
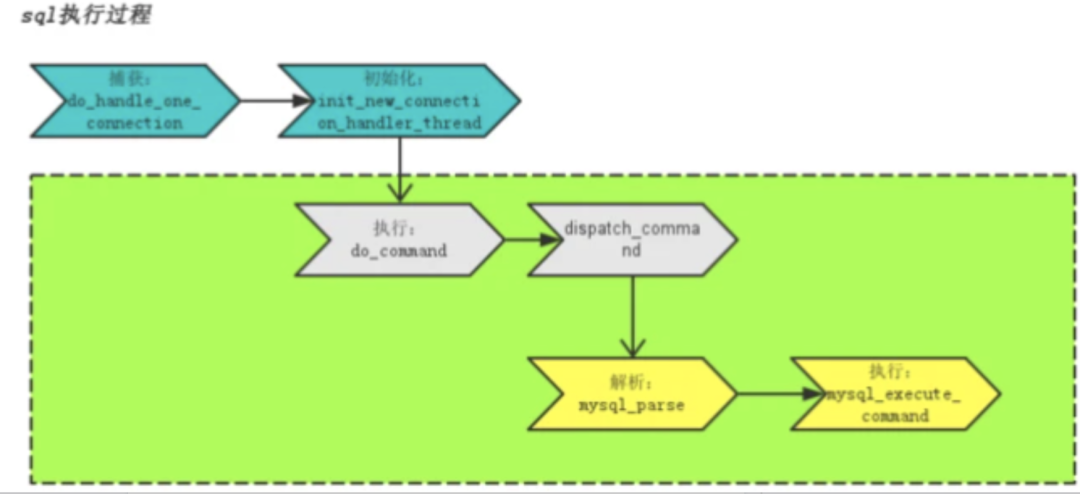
Mysql执行原理
绿色部分为SQL实际执行部分,可以发现SQL执行2大步骤:解析,执行。
以com_query为例,dispatch_command会先调用alloc_query为query buffer分配内存,之后调用解析
解析:词法解析->语法解析->逻辑计划->查询优化->物理执行计划
检查是否存在可用查询缓存结果,如果没有或者缓存失效,则调用mysql_execute_command执行 执行:检查用户、表权限->表上加共享读锁->取数据到query cache->取消共享读锁
影响因素
如不考虑MySQL数据库的参数以及硬件I/O的影响, 则影响SQL执行效率的因素主要是I/O和CPU的消耗量 总结:
数据量:数据量越大需要的I/O次数越多
取数据的方式
数据在缓存中还是在磁盘上
是否可以通过索引快速寻址
数据加工的方式
排序、子查询等,需要先把数据取到临时表中,再对数据进行加工
增加了I/O,且消耗大量CPU资源
解决思路
将数据存放在更快的地方。
如果数据量不大,变化频率不高,但访问频率很高,此时应该考虑将数据放在应用端的缓存当中或者Redis这样的缓存当中,以提高存取速度。如果数据不做过滤、关联、排序等操作,仅按照key进行存取,且不考虑强一致性需求,也可考虑选用NoSQL数据库。
适当合并I/O
分别执行select c1 from t1与select c2 from t1,与执行select c1,c2 from t1相比,后者开销更小。
合并时也需要考虑执行时间的增加。
利用分布式架构
在面对海量的数据时,通常的做法是将数据和I/O分散到多台主机上去执行。
