





PostgreSQL 15 通过尝试最大限度地减少 I/O 停滞,改进了一些大型且非常繁忙的数据库的崩溃恢复和物理复制性能。备用服务器现在可能更容易跟上主服务器。
如何?PostgreSQL15 的变化是恢复现在使用设置(默认值为 10,但您可以增加它)来决定尝试启动多少个并发 I/O,而不是一次执行一个随机读取 I/O。对于大型繁忙数据库,当 I/O 并发性增加时,可以减少复制延迟。maintenance_io_concurrency
在这篇博文中,您将了解恢复预取如何最大限度地减少 PostgreSQL 15 中的 I/O 停滞并减少复制滞后,以及这项工作如何适应更大的提案集,以便将来将 PostgreSQL 从传统的 UNIX 风格的 I/O 迁移到高效的现代 I/O API。让我们来看看:
PostgreSQL 15 中的恢复预取
如何使用 WAL 进行恢复
恢复可能会在 I/O 上停止
目标:恢复中理想的 I/O
关于同步 I/O 的一些历史
PostgreSQL 15:添加更多并发性,但尚未真正异步
未来:真正的异步 I/O
我们只是触及了表面
致谢和感谢

在 PostgreSQL 15 中尝试恢复预取
让我们从恢复预取可能的最佳案例改进的快速示例开始。
您可以通过以不适合 RAM 的规模运行 pgbench
来看到这个新的恢复预取功能的完美演示。为什么?因为所涉及的随机数据块不太可能在PostgreSQL的缓冲池或内核的页面缓存中。
对真实世界数据的影响范围从本测试中看到的急剧加速到如果它们已经很好地缓存在内存中则完全没有变化。恢复预取的主要受益者将是:
具有超出内存的工作集的非常大的繁忙数据库,以及
在
full_page_writes
设置为关闭的情况下运行的系统(通常不推荐)。
在以后的版本中,我们的目标是在此基础结构上进行构建,以改进缓存良好的工作负载。
测试配置,这是我所做的:
安装 PostgreSQL 15
在相当基本的开发人员系统上设置具有 1000 个客户端的 32 个 TCP-B 规模测试
pgbench运行流式复制副本
然后将maintenance_io_concurrency
设置为 0 以禁用恢复预取,即行为类似于 PostgreSQL 14设置为 off,以使效果立即可见(否则,由于检查点,加速电位会随着时间的推移而以锯齿状模式变化)
full_page_writes
在此特定系统上,复制滞后(在下面的图表中以紫色显示)开始攀升,因为副本无法跟上重放 WAL 所需的所有随机 I/O。(复制滞后或重播滞后是衡量副本落后于主服务器的程度的度量,以秒为单位;接近零且稳定表示良好。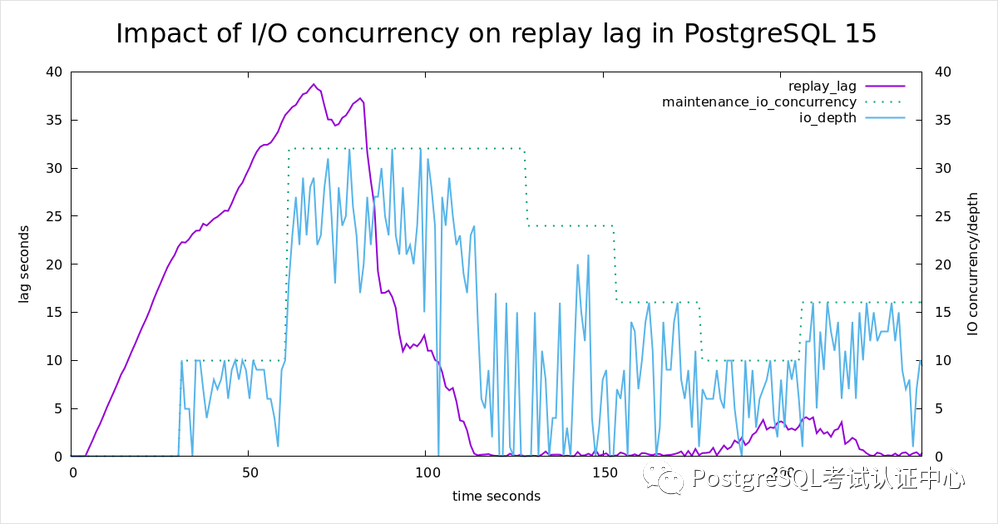 图 1:此图表描述了影响复制滞后(以紫色显示,也称为重播滞后)的 I/O 并发性(以蓝色显示)。前 30 秒模拟 PostgreSQL 14 的行为,其中没有 I/O 并发性,副本无法跟上主服务器的步伐,因此复制延迟增加。在 30 秒标记处,一旦maintenance_io_concurrency设置设置为 10(然后更高),您就可以看到恢复预取和 I/O 并发的好处:复制延迟减少。
图 1:此图表描述了影响复制滞后(以紫色显示,也称为重播滞后)的 I/O 并发性(以蓝色显示)。前 30 秒模拟 PostgreSQL 14 的行为,其中没有 I/O 并发性,副本无法跟上主服务器的步伐,因此复制延迟增加。在 30 秒标记处,一旦maintenance_io_concurrency设置设置为 10(然后更高),您就可以看到恢复预取和 I/O 并发的好处:复制延迟减少。
该图显示了显示为绿色虚线的时刻,步长到 10(这是默认值),
maintenance_io_concurrencyALTER SYSTEM SET maintenance_io_concurrency = 10;
SELECT pg_reload_conf();复制
这导致复制延迟的增加速度变慢,这是以蓝色显示的并发 I/O 请求的结果。不过这仍然不够,所以我试着调到 32。这使滞后率回到了零。然后我尝试了一些较低的值:24,然后是16,然后是10。在 10 点时,您会看到复制滞后再次开始攀升。10 不足以全速重播这个人为的测试工作负载,但16是。
maintenance_io_concurrency
如果在家里尝试这个实验,还要注意,当前基于建议的方案只适用于带有 ext4 和 xfs 的 Linux(它也可能适用于其他系统,并且预计未来版本的 zfs 可以工作)。它尚不适用于其他操作系统。相比之下,正在为下一代开发的真正异步 I/O 提案将通过各种内核 API 在任何地方工作。
我们试图解决什么问题?
背景:如何使用预写日志记录 (WAL) 进行恢复
与许多其他数据库系统系统一样,PostgreSQL将更改记录在预写日志或WAL中。对保存表和索引的永久关系文件的更改最终会在后台写入磁盘,但用户只需在提交事务时等待日志写出到磁盘。
这种安排提供了良好的性能,因为用户只需等待顺序写入,并允许可靠的恢复。WAL将在以下情况下重播:
崩溃后,当重播自上次检查点以来的所有更改时
连续,在物理副本上
在这两种情况下重播 WAL 的工作称为恢复。(WAL 还用于逻辑复制和其他目的,但这些用途不受此处讨论的更改的影响。
恢复可能会在 I/O 上停止
WAL 由非常简单的指令组成,这些指令不需要太多的 CPU 来重放——比它们最初生成时要少得多——所以它们按顺序重放的事实远非要解决的问题列表的顶部,在这一点上。
另一方面,I/O 停滞可能是一个严重的问题。WAL 中的指令表示可能使用以下内容的许多并发会话的工作:
可能缓存良好的数据 — 或
许多 I/O 停滞同时发生(我们的 32 个 pgbench 客户端)
而在恢复中,我们按顺序重播相同的更改。我们的测试客户端正在运行以下形式的查询流:
postgres=# update pgbench_accounts set bid = $1 where aid = $2;
UPDATE 1复制
PostgreSQL记录了以下WAL记录(根据pg_waldump,输出非常简短以适应此处):
Heap lsn: 0/50DC2A80, HOT_UPDATE; blkref #0: rel 1663/5/16396 blk 163977
Transaction lsn: 0/50DC2AC8, COMMIT 2022-09-29 16:45:20.175426 NZDT复制
我们可以看到,关系 8/163977/1663 的 5KB 块16396需要修改。如果该特定块尚未在PostgreSQL的缓冲池中(即,如果该块尚未在内存中),则在恢复期间,必须加载系统调用。如果连接了 32 个客户端并同时运行类似的查询,则可能会有大量块需要依次修改。pread()
这样做的问题是:
从磁盘检索要修改的数据时,恢复可能会进入睡眠状态
我们可能还需要从磁盘传输块以供将来记录,但是我们必须一次等待一个
显然,我们可以做得更好!这就是我们在PostgreSQL 15中开始做的事情...
逐步走向解决方案
目标:恢复中的理想 I/O
当我们开始重放 WAL 记录时,理想情况下我们已经在缓冲池中拥有我们需要的每个数据页,因此我们只需要调整相关字节而无需离开 CPU(即在等待磁盘时休眠)或必须将数据从内核空间复制到我们的用户空间缓冲区。为了有机会实现这一目标,我们需要某种形式的异步 I/O,具有恰到好处的提前期和并发性,或者在硬件约束范围内尽可能接近。我们还希望有异步缓冲区替换来及时写出脏数据,以便足够快地回收缓冲区内存,这样我们就不必等待。这需要解决很多独立且相互关联的问题。
当我第一次开始在PostgreSQL 15中研究IO并发性时,我们离这个理想还很远。要了解原因,您需要了解一些操作系统历史记录。
同步 I/O 的历史背景
半个世纪前,UNIX的设计者所做的选择之一是通过缓冲和调度来隐藏I O的异步性质。当时的其他操作系统(特别是Multics和VAX/VMS)可以选择向用户空间程序公开设备I O的异步性质,但是UNIX总是使您的进程进入睡眠状态,直到数据可用,并且您无法摆脱该模型。你能希望的最好的是它已经在内核的缓存中,由于最近的使用或简单的预读启发式。对于绝大多数简单的应用程序来说,这是一个不错的选择,但对于繁忙的数据库来说则不然。
我最喜欢的Stack Overflow问题之一是“我们应该如何解释Dave Cutler对Unix的批评?”。就像这个有趣的轶事一样,PostgreSQL的读取I O基本上是get-a-block,get-a-block,get-a-ran-dom-block。为了使同步 I/O 具有合理的性能,我们仍然依赖于与古代 UNIX 中相同的缓冲和内核启发式方法,并在可能的情况下加上少量的提示/建议。
PostgreSQL 15:添加更多并发性,但尚未真正异步
虽然套接字和管道具有非阻塞模式,可以与基于就绪的 API 一起使用,例如 ,但这不适用于多路复用文件 I/O。在坚持传统的同步读取调用时,我们能做的最好的事情就是告诉内核我们很快就会使用 posix_fadvise(POSIX_FADV_WILLNEED) 读取文件的某个区域。如有必要,内核可以开始从存储中获取数据。poll()
有许多缺点使其不如真正的异步 I/O:posix_fadvise()
并非所有操作系统都有它(Linux有)
并非所有操作系统都对提示做任何有用的事情(Linux确实如此)
并非所有文件系统都对提示有用(Linux xfs 和 ext4 可以)
我们不知道 I/O 是否已经在内核的缓冲区中或 I/O 是否已启动
我们不知道任何 I/O 何时完成
当我们稍后调用时,我们必须将数据同步复制到用户空间缓冲区
pread()所有这些问题都只阅读
尽管存在上述问题,PostgreSQL 15 仍设法在此内核接口的某些情况下提高恢复性能,如上述实验所示。基本思想是假设每个调用都启动一个 I/O,并且相应的调用完成它,然后尝试一次保持 N 个 I/O 处于运行状态。对于 ,这将产生一系列系统调用重叠,如下所示:posix_fadvise()pread()maintenance_io_concurrency = 3
posix_fadvise(1) ╮
posix_fadvise(2) │ ╮
posix_fadvise(3) │ │ ╮
pread(1) ╯ │ │
posix_fadvise(4) ╮ │ │
pread(2) │ ╯ │
posix_fadvise(5) │ ╮ │
pread(3) │ │ ╯
posix_fadvise(6) │ │ ╮
pread(4) ╯ │ │
posix_fadvise(7) ╮ │ │
pread(5) │ ╯ │
posix_fadvise(8) │ ╮ │
pread(6) │ │ ╯
posix_fadvise(9) │ │ ╮
pread(7) ╯ │ │
posix_fadvise(10) ╮ │ │
pread(8) │ ╯ │
posix_fadvise(11) │ ╮ │
pread(9) │ │ ╯
posix_fadvise(12) │ │ ╮
pread(10) ╯ │ │
pread(11) ╯ │
pread(12) ╯复制
在最好的情况下,即随机读取超过RAM大小的数据集,这种技术可以实现目标级别的I / O并发(或根据工具的平均队列深度)。在最坏的情况下,我们会为内核缓存中已有的数据生成额外的系统调用,或者已经能够通过简单的顺序启发式方法进行预测。>iostat
围绕这些糟糕的内核 API 构建基础设施的长期动机是为真正的异步 I/O 提供垫脚石。
未来:真正的异步 I/O
真正的异步 I/O 不基于就绪情况或提示,而是基于完成事件。
1990 年代引入了几个基于完成的 API,但至少 POSIX API 没有被广泛使用。也许是因为它们难以使用,被流行系统不完全实现,并且范围有限。近年来,Linux 的io_uring通过提供一个优雅、高效和通用的接口,通过提交和完成队列与内核进行通信,引起了人们对基于完成的 I/O 的新一轮兴趣。存在一个正在进行的项目,用于向PostgreSQL添加对io_uring和其他异步I / O API的支持,或将I / O操作作为可移植回退选项推送到后台工作线程中。
在恢复预取的基于完成的第 2 阶段(目前以原型形式存在并依赖于大量其他修补程序)中,数据页不会只是预加载到内核缓存中。相反,它们将被异步传输到PostgreSQL的缓冲区中,并可选择使用直接I / O完全跳过内核的缓冲区。
我们只是在PostgreSQL 15中触及了表面!
我们只是触及了可能的优化的表面,现在我们可以进一步了解 WAL。最容易实现的果实是用于大型随机工作负载的 I/O 停滞。虽然并非所有工作负载都将受益于 PostgreSQL 15 中发布的第一阶段功能,甚至是未来基于完成的 I/O,但早期的实验表明,通过整合缓冲区引脚、锁和可能的重新排序操作的管理,甚至有可能加速完全缓存的恢复工作负载。
要试验恢复预取对您自己的副本服务器的影响,请尝试:
调整设置,以及 maintenance_io_concurrency检查
pg_stat_recovery_prefetch
视图中的统计数据增加
wal_decode_buffer_size
设置也可能很有用
关于开发过程的致谢、感谢和说明
我最初受到Sean Chittenden在PGCon 2018上关于pg_prefaulter的演讲的启发。这是一个外部工具,它显示了我们剩下的恢复 I/O 性能;我从其他演讲中得知,他的团队大规模使用了ZFS,大概使问题更加明显。然后,我开始了一个漫长的过程,找出以紧密集成的方式将逻辑移动到PostgreSQL所需的WAL分析和同步的所有问题,并具有通往真正异步I / O的途径。full_page_writes=off
翻译文献:
https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/reducing-replication-lag-with-io-concurrency-in-postgres-15/ba-p/3673169#wal



