




升级过程中如果出现部分数据错误,如何回滚? 如做回滚,新数据可能在回滚前落入新库,回滚后落入旧库,一部分数据在用户层面将看不到;如果错误只出现一次还好,可以通过洗数解决;但如果升级过程反复发现 bug,反复修订,一定会对业务造成影响; 迁移至分库分表后,为了保证数据被查询到且保证查询的性能,一般情况下 sql 的查询条件需要带上分表(片)键,但一个已经运转多年的业务系统它的 sql 肯定不能完全满足这个要求,如果进行全量的 sql 改写将是一个巨大的工作量,且有些业务场景根本就无法进行 sql 改写,比如辅营交易系统表的分表键一般是自身业务的订单号,但它有根据第三方券码查订单的客观需求( 一般是三方回调接口中)。 如何确定分库分表后的系统数据业务等价于分库分表前的系统。
对数据进行双写;在分表键的基本之上增加了分表键映射的概念,通过 sql 条件分析自动或手动路由控制数据读写单库单表或分库分表; 再通过一种特殊的事务来实现的两套系统的一致性; 通过 iff 来确定两套数据库系统数据是等价的。
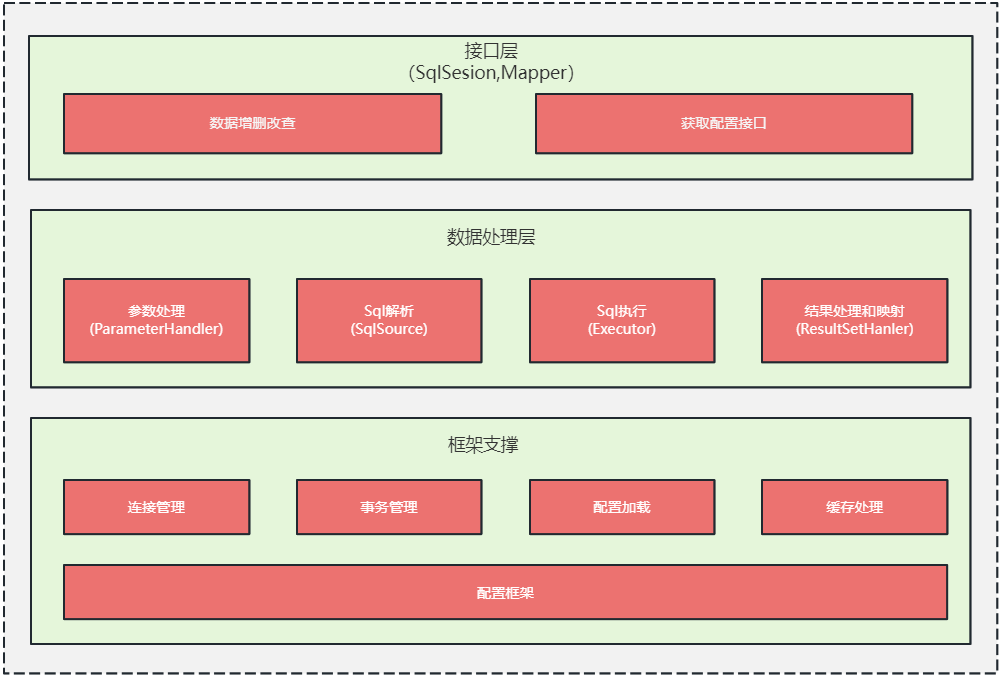
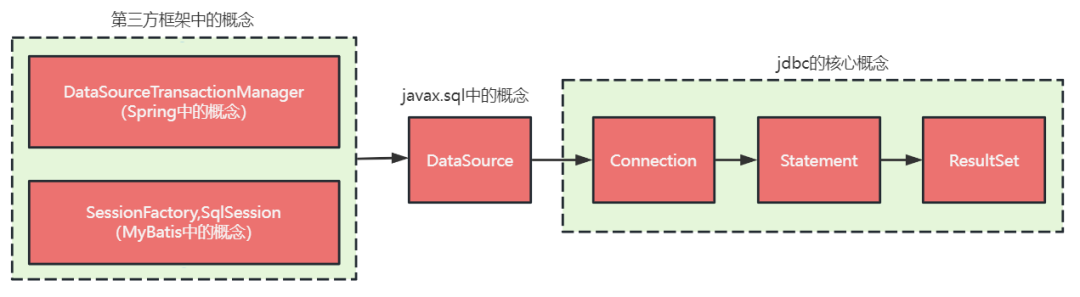
接口层: 是 mybatis 提供给开发人员的 api,其主要是 SqlSession 对象, 开发人员通过 SqlSession 和 Mapper 接口来操作数据;平时我们做业务开发的时候感知不到 SqlSession,只是声明了一下 Dao 层的 Mapper 接口,就可以在 Spring 容器中拿到对应 Mapper 接口的实现来操作数据,这是因为框架帮我们做了很多事情,实际内部就是通 SqlSession 完成的,只是这个 SqlSession 的操作过程封装到了一个实现了 Mapper 接口的动态代理中,mybatis-spring 框架在扫苗包路径的时候将 Mapper 对应的动态代理实现注入到了 Spring 容器;对这块原理感兴趣的读取可以查询 mybatis 源码中 MapperProxy 及其相关类的实现。 数据处理层: mybatis 的核心实现,主要是参数处理及 sql 解析、映射、执行、结果构建,详细处理流程见后文说明。 基础支撑层: 主要包括连接管理、事务管理、配置加载和缓存处理,将他们抽取出来作为最基础的组件,为上层的数据处理层提供最基础的支撑。
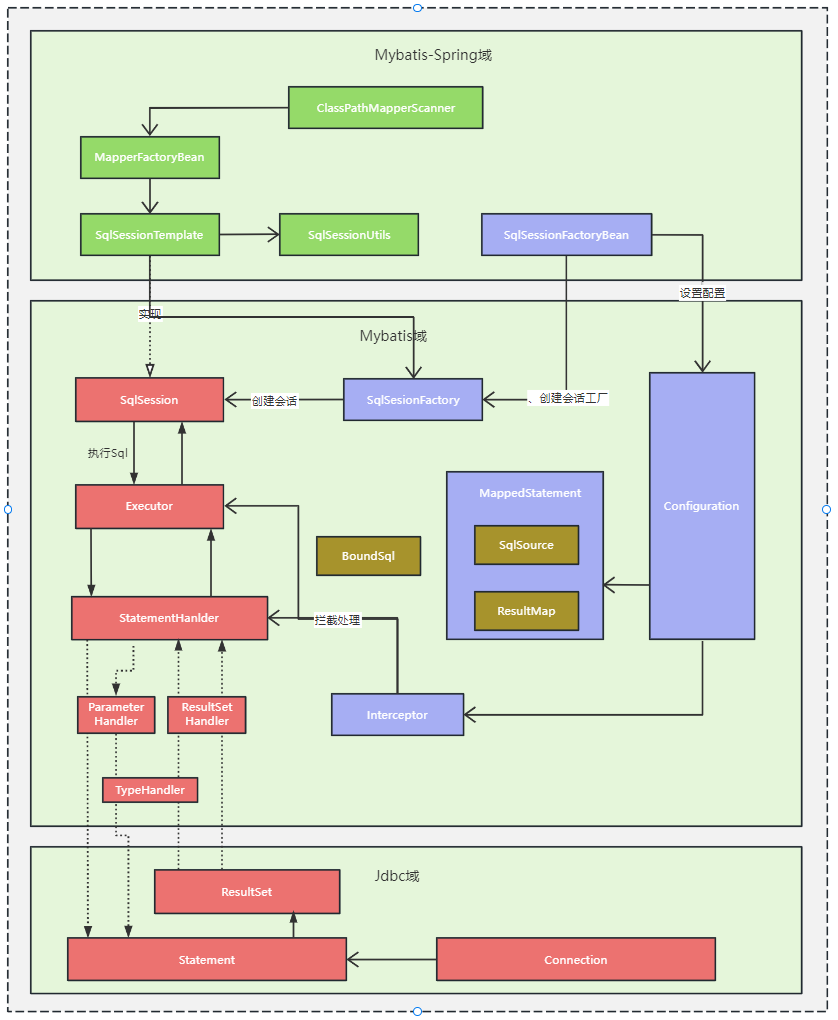
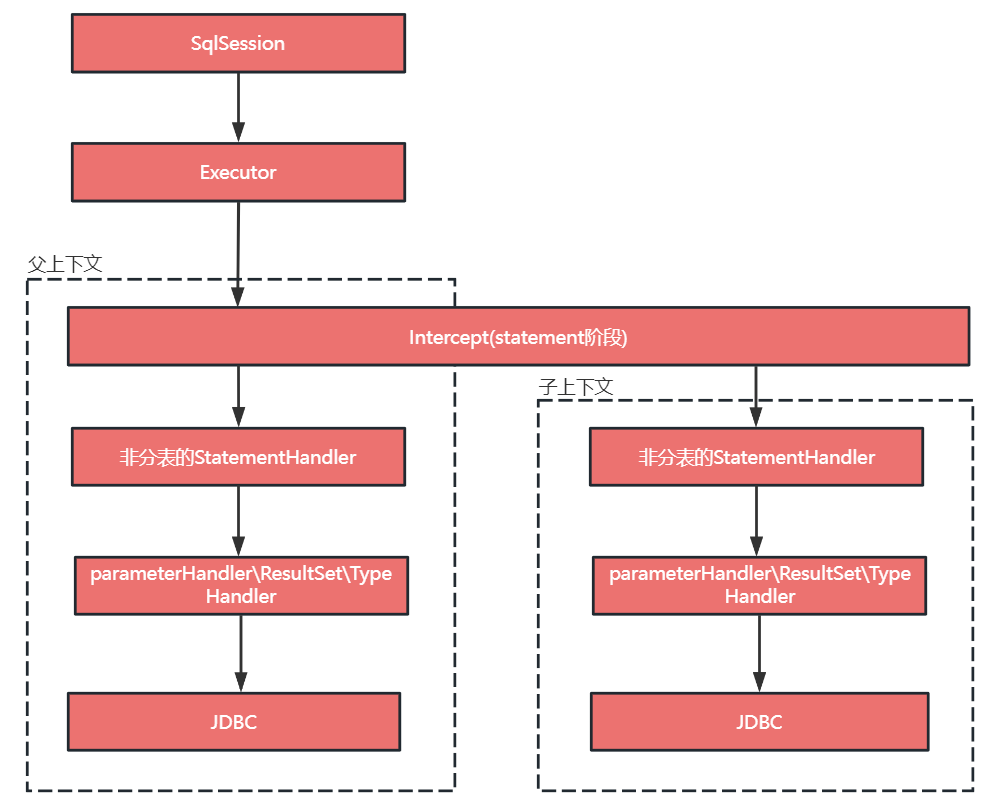
由 SqlSession 开始, SqlSession 如上文所提及的是 mybatis 开放给用户顶层 api,它定义了 sql 操作的一个会话;SqlSession 通过Executor来完成操作; Executor 是调度核心,它负责SQL语句的生成,调用 StatementHandler 访问数据库,查询缓存的维护,将 MappedStatement 对象进行解析,sql 参数转化、动态 sql 拼接,生成 jdbc Statement 对象; StatementHandler 封装了 JDBC Statement 操作,负责对 JDBCstatement 的操作,设置参数、将 Statement 结果集转换成List 集合,是真正访问数据库的地方;在 StatementHandler 和 JDBC Statement 之间可以通过:
ParameterHandler 负责将用户传递的参数转换成; ResultSetHandler 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合;处理查询结果; TypeHandler 负责 java 数据类型和 jdbc 数据类型之间的映射和转换。
ClassPathBeanDefinitionScanner 负现扫苗由 @MapperScan 注解描述的包路径,对符合条件的 Dao 接口通过 Spring 的 BeanDefinitionRegistry 进行注册,并将 BeanDefinition 的 beanClass 属性设置为 MapperFactoryBean; 大家在业务代码中通过 Spring 容器拿到的 Dao 的实际其实就是 MapperFactoryBean 的通过调用 FactoryBean 接口的 getObject() 获取的; getObject() 方法是通过 SqlSession 的 getMapper 方法(参数是 Dao 接口的类名)获取到了,前文提到过了 MapperProxy 实例,它体质就是动态代码调用 SqlSession,只是调过过程中的参数是由环境、Configuration 及上下文中获取; MapperFactoryBean 的 SqlSession 一般就是 SessionTemplate,SessionTemplate 是 Mybatis-Spring 给的 SqlSession 的标准实现,它的核心功能是通过 SqlSessionFactory 来获取实际的 SqlSession 和对 SqlUtils 对获取过程进行拦截; SqlUtils 对获取 SqlSession 的拦截主要目的就是联结 Spring 的事务处理环境,它会判定如果是在事务环境中,同一事务下通过 SqlSessionHolder 复用 SqlSession。
SqlSessionFactoryBean 对过继承 Spring 的扩展接口FactoryBean、InitializingBean 在 Spring 初始化 bean 的时候SqlSessionFactoryBean 通过调用自身的 buildSqlSessionFactory 来构建 SqlSessionFactory,这个构建过程要么是通过 xml 要么是通过注解,构建的时候也完成的 Configuration 的设置,这个Configuration 主要包括了 MappedStatement 和 Interceptor(插件)。 MappedStatement 就是用来存放我们 SQL 映射文件中的信息包括 sql 语句,输入参数,输出参数等等。一个 Dao 方法对应一个 MappedStatement 对象。 Interceptor 就是 mybatis 的插件,它通过责任链模式实现,可分别在 Executor 阶段或 StatementHanlder 执行价段进行拦截。
测试开发不友好,分库分表的设计很重,如果所写的测试关系到数据层的话则需要依赖一整套分库分表环境,这个环境的建立是有成本的,结果大家只是依赖公共的测试环境,多人依赖测试数据容易有冲突,且对于本地测试极度不友好,集中表现在写本地单元测试时,启动一套分库分表过程很慢。 维护成本有点高,这个与方案本身的关系可能不太大,主要是技术实现细节上造成的。早期,主分之间的路由判定依赖于大量的注解和配置中心的配置,还有项目中的各种配置,新加分表关注点很多,如果不是很了解原理和技术的实现细节很容易错配,从而导致事故。 不好复用,实现上有一些业务侵入,比如依赖从spring 容器中取数据源的 bean; 分库分表规则也是一次性的,如果未来有变化也没有扩展点,比如说从一月分一次分表,改为一周分一次分表,那么就会出现新旧不兼容。这套代码也不好做到从一个项目迁一到另一个需要分库分表的项目中直接复用,迁代码需要大量修订。
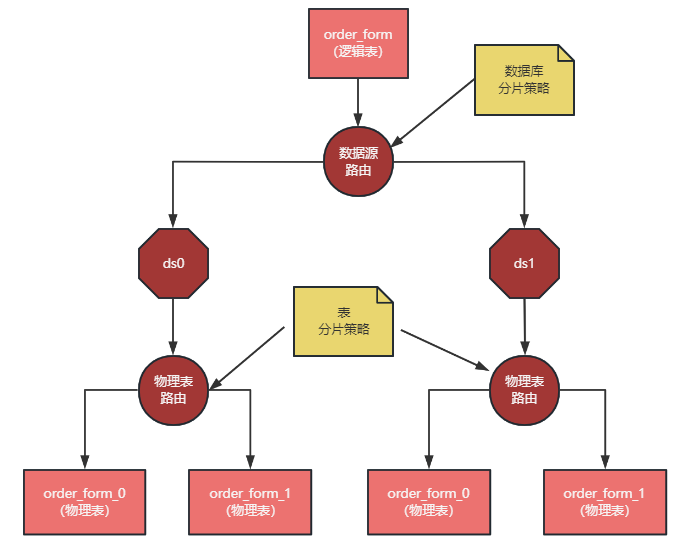
分⽚键: ⽤于分⽚的字段,是将数据库(表)⽔平拆分的关键字段。 逻辑表: 是指一组具有相同逻辑和数据结构表的总称。 物理表: 与逻辑表对应,一个 order_form 可以被拆成多个物理表。 分片策略: 分⽚键 + 分⽚算法, 分片策略是 sql 进行路由的依据。
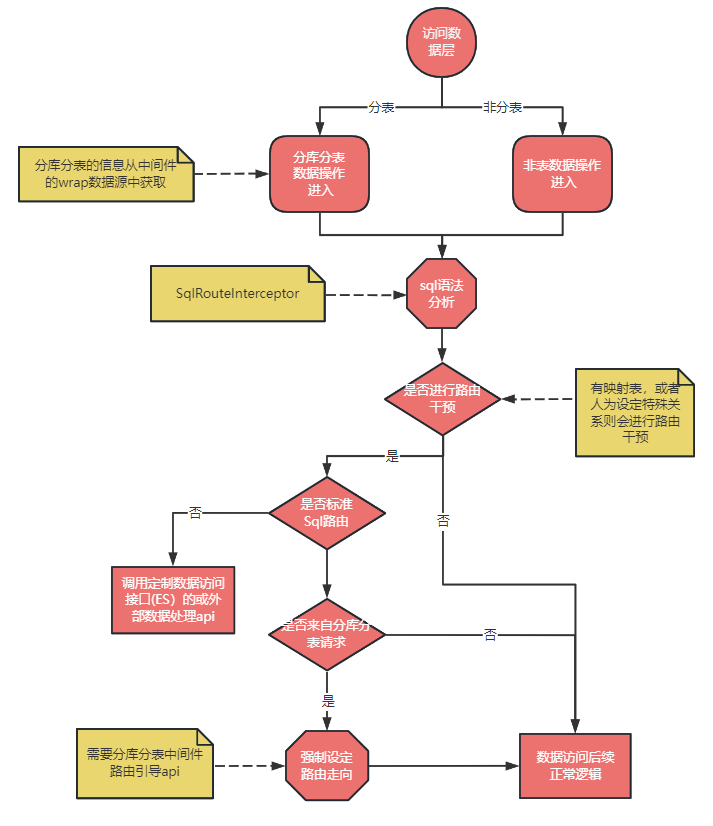
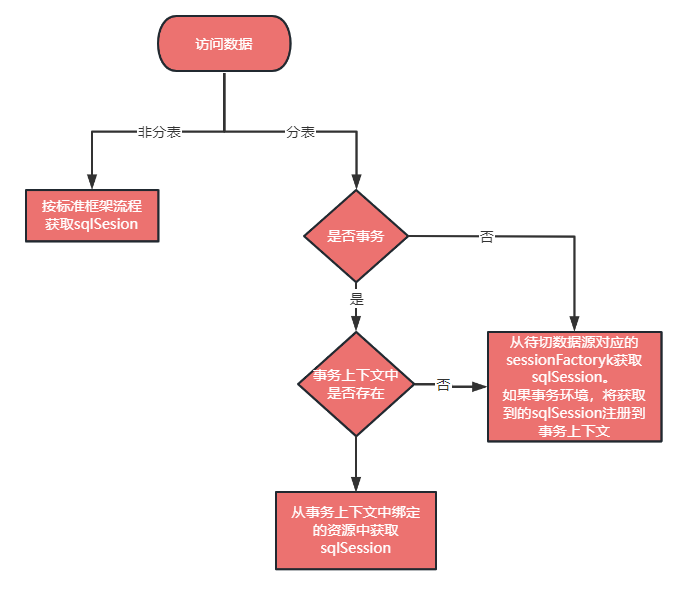
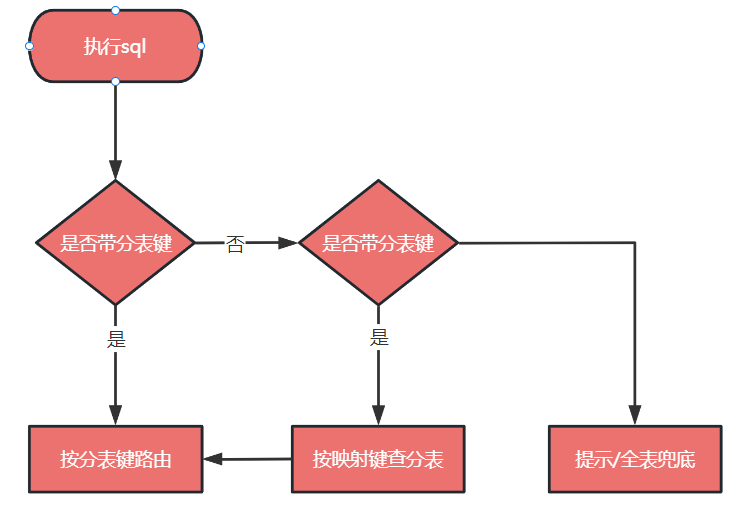
对于走分库还是非分库是在最开始的时候由用户配置来决定,如果用户配置中有分库分表中间件,走分库分表逻辑;如果是单库则走单库逻辑;如果分表库和非分表都有则两个各配置配置一个 SessionFactory,分库的 SessionFactory 管理的表走分表库逻辑,单库的 SessionFactory 管理的表走单库逻辑;这一点与辅营交易现有的 SessionFactory 的分工是不同的,辅营交易现有分库分表上实现上,主表库的 SessionFactory 还管理着分表库的表。 值得说明的一点的是,在我们的设计里不强调全局表和广播表的概念,取之以单独的主库表替代,这种方式经营成本更低,缺点是表分别位于分表库和主表库中,无法进行 join 查询。 事实上,我们在划分表空间时,根据 DDD 结果也会尽量将同一个业务领域的表划分到一起,以便其可以进行 join 查询;所以一般不会出来主表库要和分表库进行 join 的场景。 无论是分表还是单表,执行流程都会进入 SqlRouteInterceptor (mybatis的插件),都会进行路由干预,因为主表库至少也是有读写分离控制要求的嘛。 是否进行路由干预是由有无映射表逻辑或业务层面调用路由干预 api 来进行判定的,如果没有那么直接走后面逻辑即可,如果有,则对 sql 类型和条件进行判定,对于有复杂查询条件的 sql 查询可以走 ES 和数据组宽表查询的接口(初版没有开发这个功能,后续可按情况添加)。 对于有映射表逻辑的 sql 操作,先从映射表中找出分表键,然后再能通过分库分表中间的路由引导 api 来指导分库分表中间的执行。
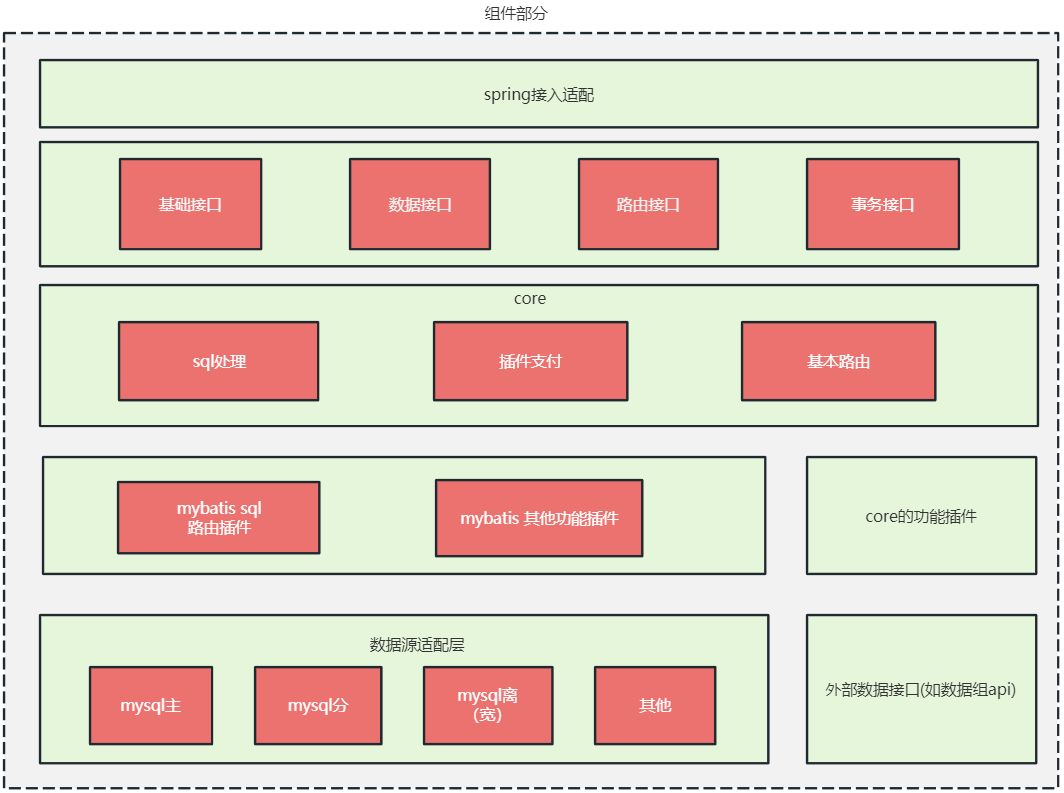
接入层:负责给应用接入提供稳定和兼容的接口, 其中的 spring 接入适配是在项目稳定后再视情况开发,一般是在 spring 环境上提供一些注解和 starter; core 层: 路由逻辑的核心实现,并基于路由逻辑建立生命周期,提供插件化的扩展点,使外围功能可以以插件的方式开发; 存储层: 负责最终 sql 的执行,数据的最后落地, 与接入层配合实现事务,主要由数据源和 mybatis 组成。
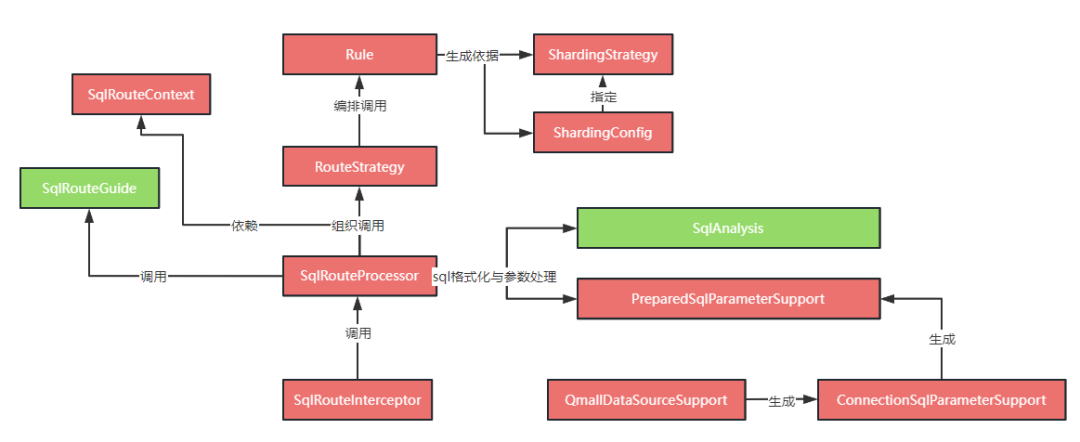
调用语法分析行到 SqlInfo, SqlInfo 中包含了后续 sql 路由分析的所有数据结构,如sql中含有的查询条件、sql中关系到的表和列、sql的类型等; 调用参数处理,将 DAO 中传递的参数填充到 SqlInfo 结构中, 以使后续流程可以很方便的找到列或条件对应的实参值; 根据 SqlInfo 的内容选择合适的路由策略 RouteStrategy,选择的路由策略过程就是匹配得分最高的一个策略,比如有两个读的策略,一个是按分片键路由,一个是按映射键路由,当 sql 条件中有分片键时会优先命中分片键路由,而没有分片键的时候将命中映射键路由,路由也可以定制化,当对于某个特殊的 sql 想走 es 索引时可以针对这个 sql 的 Dao 名加方法特定命中一个走 es 索引的路由; 路由策略根据操作的类型来组织路由规则,对于写是所有路由规则都执行,对于读只要一个规则判定成功就返回,这个写的路由规则通常就是维护映射键的映射表数据,而读的路由规则是从多个映射键中选择一个可行的映射规则找到映射键的值,然后通过映射键的值找到分表键的值,通过分表键加分片策略算出待查数据的物理坐标; 根据计算出物理坐标,调用分库分表的路由中间件的引导 api 来执行路由引导,这个引导 api 就是图中定义的 SqlRouteGuide 接口,不同的分库分表中间件可以对这个接口进行实现来完成与本组件的基础能力对接。(完整对接还要有配置适配上的对接)
#库的前缀(这么做完全是为了照顾qdb的配置)db.prefix=qmall_supply_#分库配置db.index.qmall.flight={dbIndex: 0}db.index.qmall.inter={dbIndex: 1}db.index.qmall.ticket={dbIndex: 2}db.index.qmall.hermes={dbIndex: 3}#分表键配置sharding.user_info=[{shardingKey: 'last_name',intervalMonth:2,hashCount:0,startTime: '2020-11-01'},{shardingKey: 'last_name',intervalMonth:2,hashCount:2,startTime: '2024-07-01'},{shardingKey: 'last_name',intervalMonth:2,hashCount:1,startTime: '2021-07-01'},{shardingKey: 'last_name',intervalMonth:1,hashCount:2,startTime: '2022-07-01'}]sharding.supply_order=[{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2022-11-01', hashGroupReg: '20[0-9]{2}(0[1-9]|1[0-2])[0-9]{6}'}]sharding.supply_order_ext=[{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2022-11-01'}]#分表键日期提取正则(视情况可选)shardingKey.extract.date.pattern={supply_order_id: '20[0-9]{2}(0[1-9]|1[0-2])'}#映射键配置, priority越大,优先级越高, priority不可出现相同的值table.supply_order=[{mapKey: 'business_order_id', type: 'one2many', priority: 1, maintain: 'auto_manual'}]table.user_info=[{mapKey: 'id', type: 'one2one', priority: 1},{mapKey: 'phone', type: 'one2one', priority: 1, maintain: 'auto_manual'}]
sharding.supply_order=[{shardingKey: 'supply_order_id',intervalMonth:0,hashCount:1,startTime: '2000-01-01'},{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2023-11-01', hashGroupReg: '20[0-9]{2}(0[1-9]|1[0-2])[0-9]{6}'}]
新的组件是对已有分库分表中间件做 plus,所以必然会有一些新的配置需求,这些新的配置需求最好能很直观的与已有分库分表配置关联; 不要对已有分库分表中间件的配置文件做修改或对其有代码侵入,否则会增加用户的学习成本,而且从长期来看也会形成耦合,一旦分库分表中间件有大版本升级就不方便跟进了;
我们的组件不直接依赖任何底层数据源或分库分表的配置,只依赖 sharding.properties,数据源按标准接口接入即可。 分库分表中间件的配置统一使用自定义分片策略配置,由我们的组件根据不同的分库分表中间件的自定义分片策略接口来实现具体的分片,然后在分库分表中间件的配置文件中只配置我们自己的分片策略。

以上就是本次分享的所有内容啦!
最后,给大家带来一些岗位招聘信息。
你与驼厂只差一份简历的距离
快扫码投递吧



文章转载自Qunar技术沙龙,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
