





和美大“家”

作者 | Jhon
编辑 | 品牌部
现在这个时代数据量越来越大,结构化的数据可以用spark统计计算,也可以用tableu这样的展示工具浏览。但例如社会网络中人与人之间的关系,这种关联性的连接图数据,如果用一般的sql数据库和表格形式,只能看见每个人的具体信息,看不见人与人之间的关联信息。那么怎样进行计算然后以方便浏览的方式进行展示呢?这就需要用到图数据库以及周边一套技术,这些技术有的用于存储、有的用于计算、有的用于展示,本文介绍的arangodb就是用于存储的。
★ 目录 ★
01 | 什么是arangodb? |
02 | arangodb的网页功能介绍 |
03 | 如何使用aql |
04 | python api使用 |
05 | arangodb的应用 |
一、什么是arangodb?

从宏观上来看
它是一种图数据库, 可分布式、社区版本免费、 高级版付费、具有高级功能。特点是多数据模型,可以存储json文档, key/value键值对, 图数据;可支持各种字段索引来提升查询速度,且支持字段内容的全文搜索;支持常用图遍历算法, 比如用于寻找两点之间最短途径的算法,和更高级的最小子图等,这些都是在大数据分布式上实现了自带的api。
官方文档:https://www.arangodb.com/documentation/
从微观和传统sql数据库视角看基本的数据存储结构
1、基本文档数据模型:
arangodb也有数据库(db), 表(collection)、记录(document)的概念,document上是有用户保存的,例如:
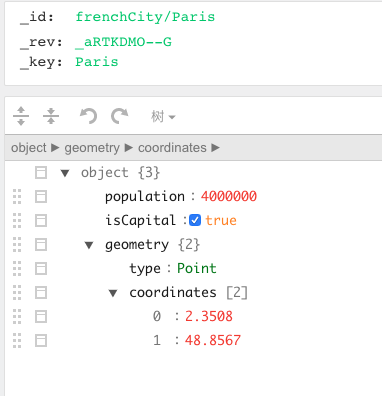
object:{"geometry":{"type":"Point","coordinates"[2.3508,48.8567]},"isCapital":true,"population":4000000}
还额外有_id和_key,_rev
注:key可以自动生成也可以用户指定(不能存中文),而_id 等于表名加_key, _rev用的少。

2、图数据模型的存储结构
图模型的数据模型其实就是基于文档模型,只不过是节点放在document类型的表,和边信息放在edge类型的表。通过edge表里的_from 和_to字段指向的document类型表里的文档id来关联起的关系。一切的处理是基于这两个表,就像mysql里的表一样,能支持想象不到的很多用处。这两种表结构类似,唯一不同的是后者多了两个_from和_to字段用于指定起始和终点节点的_id 。
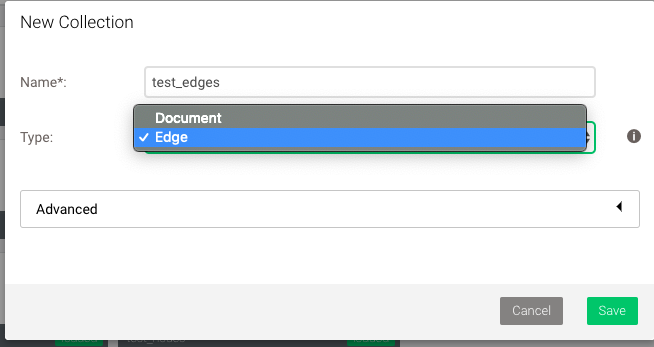
创建表的时候需要选对应的类型
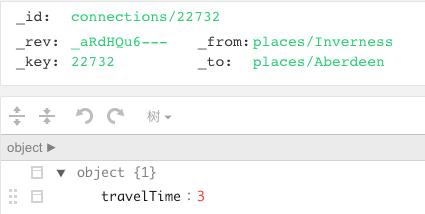
单个记录的机构
二、arangodb的网页功能介绍
arangodb自带了一个web页面用于管理服务和查询记录,使用http://localhost:8529/登录, mac版本的默认账号是root,密码为空。
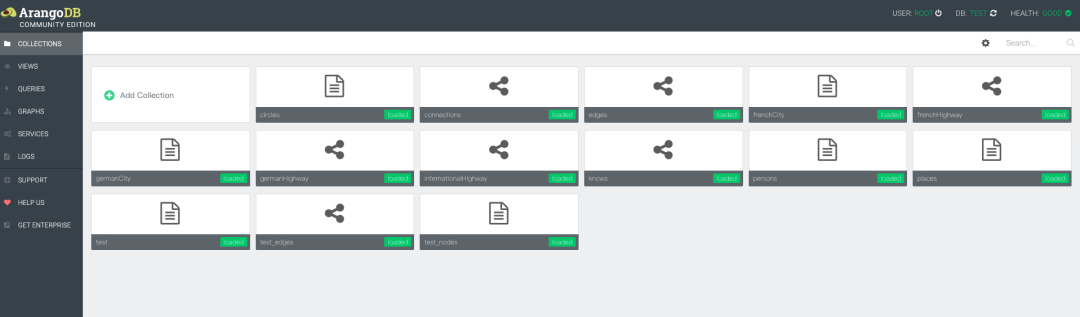
COLLECTIONS用于管理表,简单查询表等的操作功能,还可以设置用户访问的权限
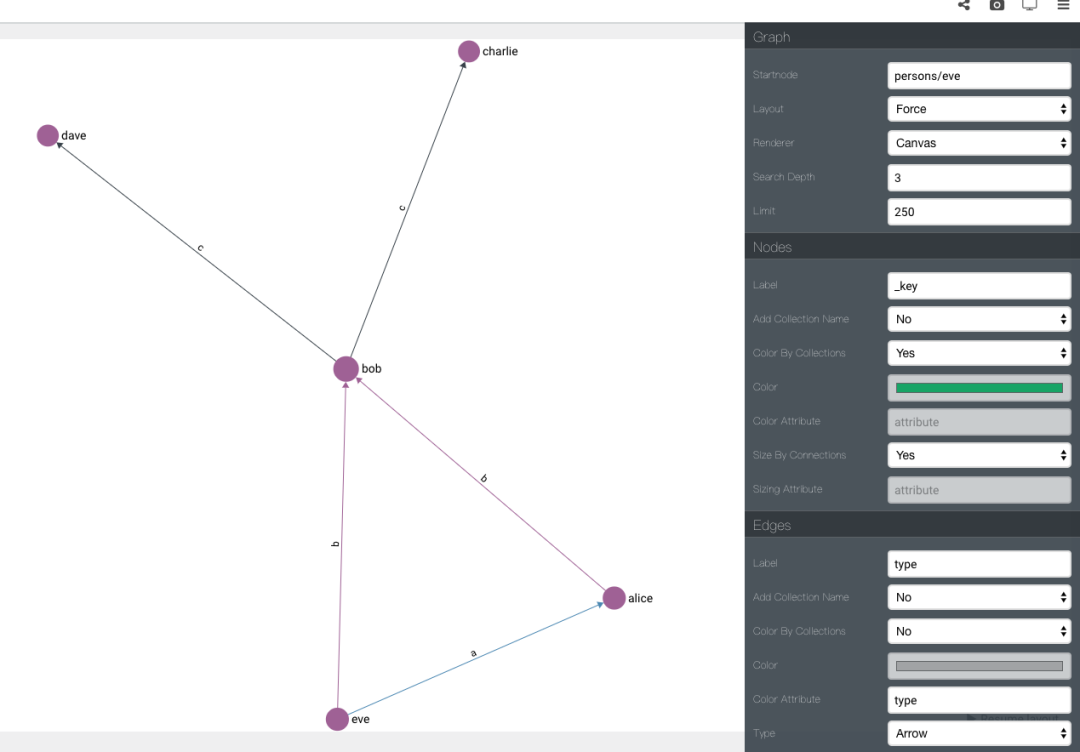
可以在web上使用graph功能探索图,它的功能简单易用,不用自己去写前端代码就能看见图的大致轮廓, 可以设定起始节点id、 图的深度、 节点和边颜色样式, 甚至是使用的布局算法。但是节点多了、深度深了,机器性能消耗比较大,画一张图会需要比较久的时间。
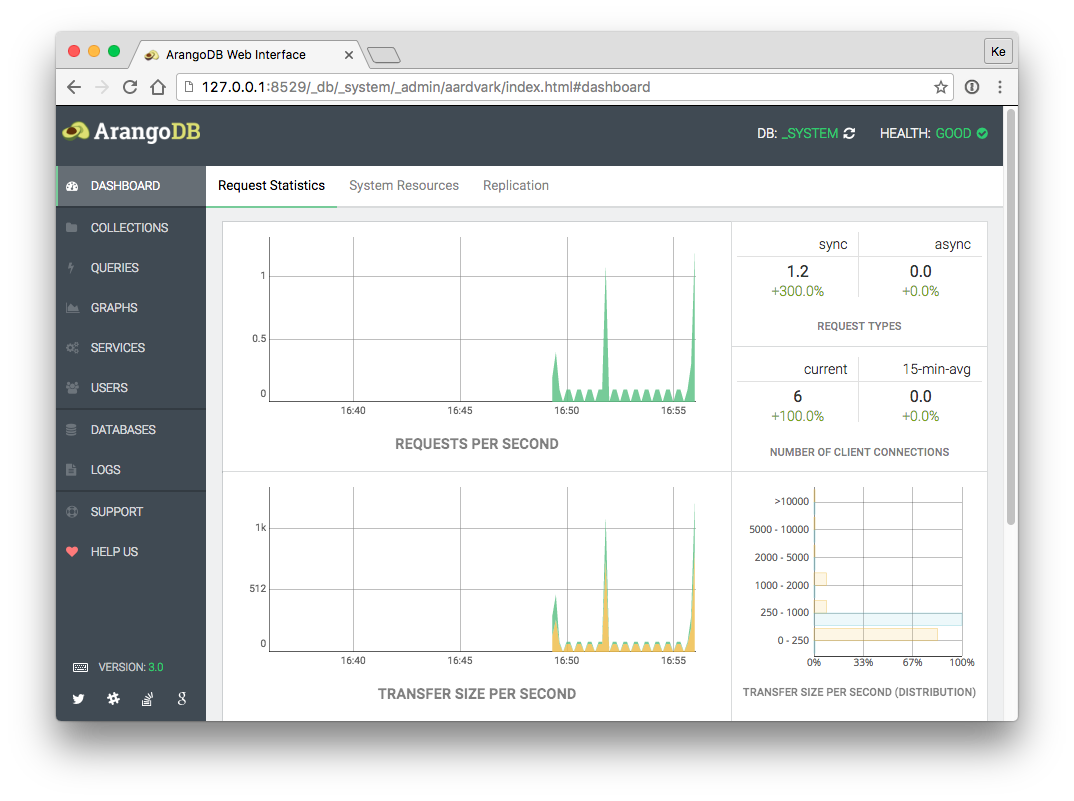
可以用上面的dashboard页面观察当前arangodb服务器性能消耗的各种指标:
1、请求统计:每秒请求数、 请求类型、客户端连接数、转移大小、 转移规模(分布)、 平均请求时间、平均请求时间(分配);
2、 系统资源:线程数,内存,虚拟大小,主要页面错误,使用的CPU时间。
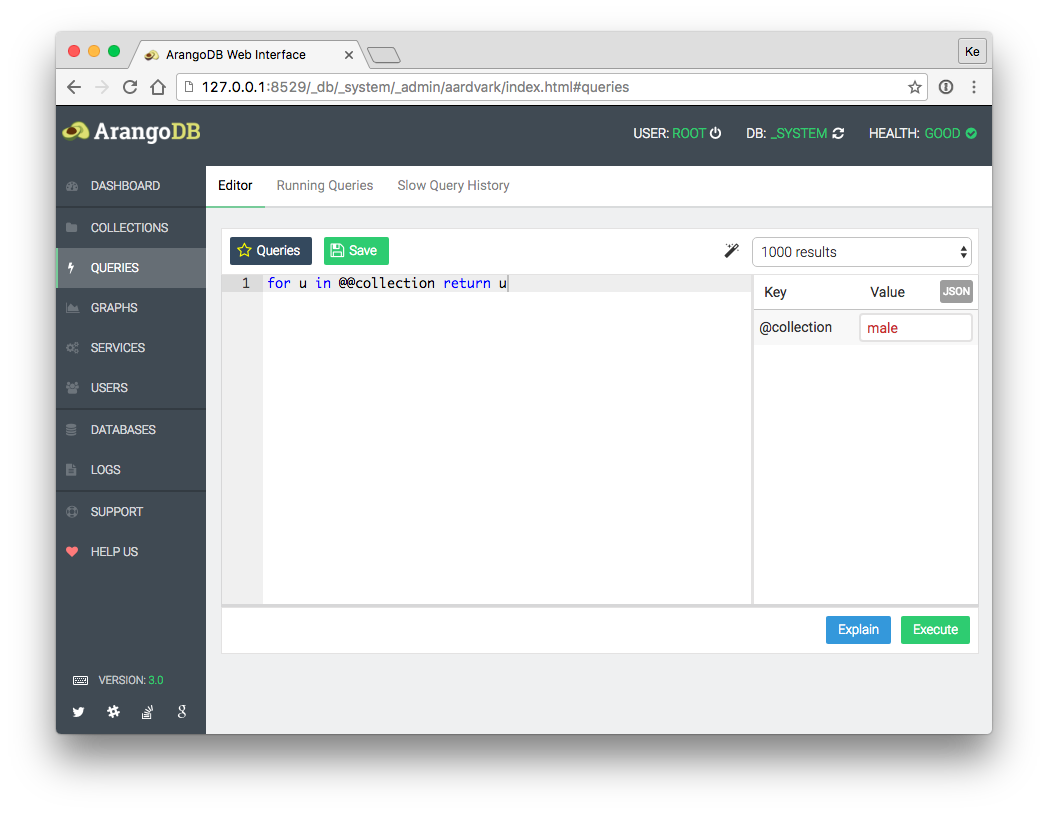
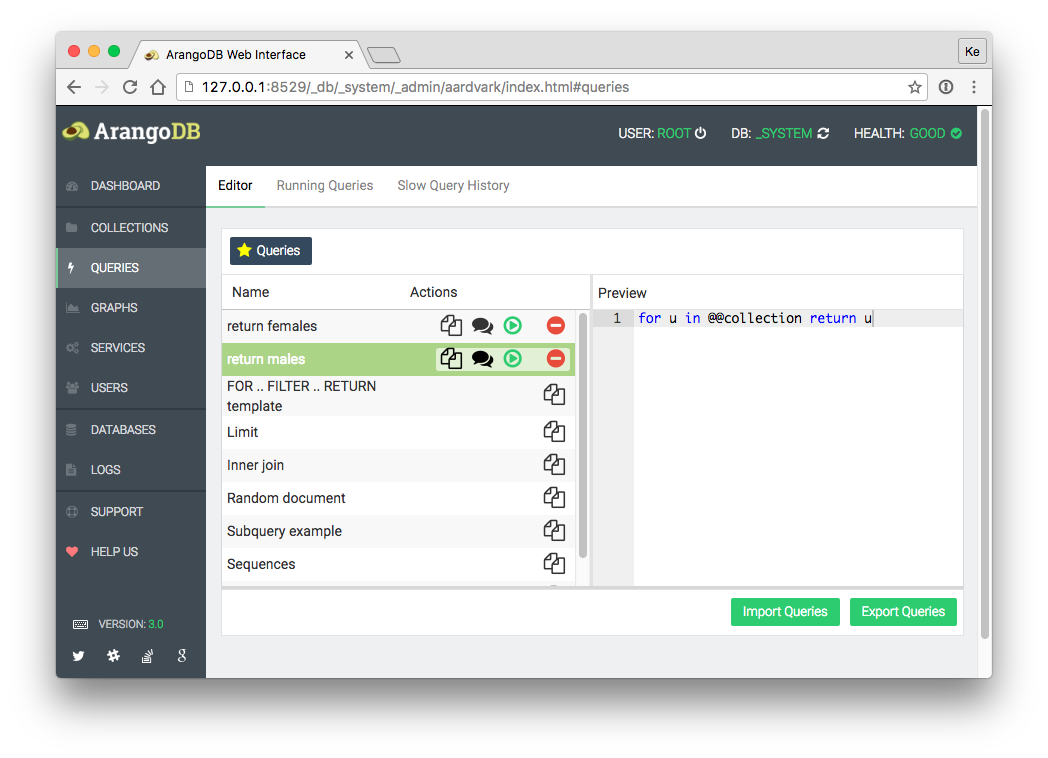
QUERIES页面可用于手动执行和观察aql语句的执行结果,查看aql执行效率等,常常用于调试aql语句, 对新手很有用处。
其他管理功能,如VIEWS和SERVICES用的比较少,其余的管理功能和foxx, fulltext search有关。
三、如何使用aql
(上部分介绍页面的管理功能, 但是针对开发的同学,更多需要学会aql的使用,它就像sql语句一样之于mysql,但是语法更灵活, 功能强大)
1、arangodb提供了类似sql那样的语法去操作数据
https://www.arangodb.com/docs/stable/aql/
能完成类似sql的数据增删改查:
基本的:
let arr = [1,2,3]
for p in tablename
filter p.name == 'Alice'
filter contains(arr, p.age)
return p
(解释:在tablename表里面查询name都等于Alice并且age等1,2或是3的记录)
for v,e,p in 2..4
any
'nodes/id1'
graph 'graph_large'
return e
(解释:在graph_large图里面查询起始点为nodes/id1,最长长度为3,最短长度为2的所有路径)
稍复杂的:
let label_dict = {'label1':{'name':['name1','name2']},'label2':{'name':['n1','n2']}}
start_band = 1
end_band = 10
for v,e,p in 1..3
any
'test1_nodes/id2’
graph 'army1'
filter p.vertices[1].label != 'include'
let node = p.vertices[-1]
let label_value = label_dict[node.label]
let f1 = node[ATTRIBUTES[label_value][0]] in label_value[ATTRIBUTES[label_value][0]]
filter !label_value or f1
bands = FLATTEN(device.band)
let bf1 = start_band >min(bands) && start_band < max(bands)
let bf2 = end_band >min(bands) && end_band < max(bands)
filter bf1 and bf2
return p
注:其中的 for 、in、 filter、contains、return都是arangodb系统里的关键词,大小写不分。语句里面还可以用多条let和filter语句,可见aql的灵活和强大。
2、aql 还能用来执行图遍历查询,以及shortest_path查询,k_shortest_paths查询一般的图遍历:
AQL:
for v,e,p in 1..6
any
'test_nodes/a'
test_edges
filter p.vertices[-1]['is_special'] == true
prune v._key == 'b'
return {'chain':p.vertices[*]._key}
注: 其中的'test_nodes/a' 是在遍历test_edges这个边集合时的起始节点;v,e,p 是遍历过程中的节点, 边, 路径(起始节点到当前节点的路径,所以有vertices和edges属性可以用)
Pythonapi:
start_v = {}
filter_func = ''
# 没有就返回
start_v = self.get_start_v1(relation='xx')
filter_func = js_generator.filter_func_js_generate(our_filter=our_filter)
filter_func = js_generator.filter_func_js_generate(our_filter=our_filter, enemy_filter=enemy_filter)
visitor_func = js_generator.visitor_func_js_generate()
res = self.g.traversal(arango_graph_name, start_v,direction='ANY',
strategy='breadthfirst',filter_func=filter_func,
visitor_func=visitor_func,edge_uniqueness='global')
js_generator.filter_func_js_generate 函数是自定义的产生特定js代码的函数:
if (vertex.relation === 'er') {
if (vertex.label === 'theatre' && ['aa', 'bb', 'cc'].length !== 0 && vertex.relation === 'er' && ['bb', 'dd', 'xxx'].indexOf(vertex.name) === -1) {
return ['exclude', 'prune']}
3 、aql 执行途径:
在网页写语句执行, 常用于调试和简单的展示
其他后端语言调用, 比如python,java等语言
javascript脚本调用
通过安装目录下的arangosh脚本启动一个终端, 执行类似javascript的语言调用aql
四、python api使用
因为python的易用性,利于快速上手,让大家对arangodb有个比较直接简明的认识,接下来讲一下python api的简单实用性:
使用python-arango库操作
https://python-driver-for-arangodb.readthedocs.io/en/master/document.html
常用的基本操作:
from arango import ArangoClient
# Initialize the ArangoDB client.
client = ArangoClient()
# Connect to "test" database as root user.
db = client.db('test', username='root', password='passwd')
# Get the API wrapper for "students" collection.
students = db.collection('students')
# Create some test documents to play around with.
lola = {'_key': 'lola', 'GPA': 3.5, 'first': 'Lola', 'last': 'Martin'}
# Insert a new document. This returns the document metadata.
metadata = students.insert(lola)
注: 看,是不是很简单,这个库比pyarango库支持的操作多, 尤其还支持图算法的调用
Arangodb也支持事务:
old_doc = db_transaction.collection(table).get(document["_id"])
if not old_doc:
return False
keys = list(document.keys())
for key in keys:
if key not in old_doc:
document.pop(key)
if '_rev' in document:
document.pop('_rev')
db_transaction.collection(table).update(document)
五、 arangodb的应用
上面讲完了实际编程,接下来我们就总结下使用场景。试想一下“人民的名义”那部电视局,里面是不是有很多错综复杂的人际关系, 调查案件的民警在调查时就是在不断的构建下面这张图, 有了它能给案件的侦破带来不少的便利和启发, 但是这还只是几十个人的人际关系图。
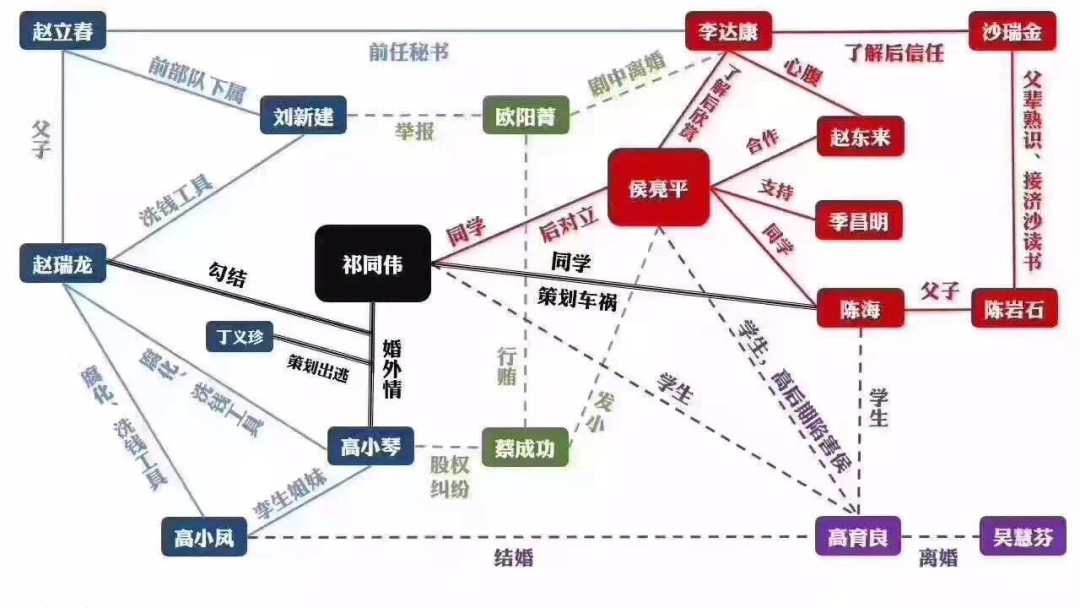
没有底层存储数据的技术,上层的计算和展示都无从谈起。要是数据是某个大圈子的全量关系呢,数据量上了几百万,那数据量就不是几个人凭借手头的一些工具就能构建清楚的。传统的sql数据库不能很好的体现关系之间的数据,这时候就需要图数据库这类新时代的nosql数据库去存储这样海量的关系,arangodb就是这类图数据库中的佼佼者, 不乏常见的neo4j(好用,但分布式版本的要收费), titan(不出名),JanusGraph(有名,hadoop生态圈的)。图数据库最常见的应用就是作为知识图谱的一个重要底层存储组件。
精彩回顾
领取和美信息产品资料,请联系:

如涉及图片及文章内容版权问题,请立即告知,我们将在第一时间核实处理。
