




理解执行计划
GP在执行sql时,执行过程可以参考下图:
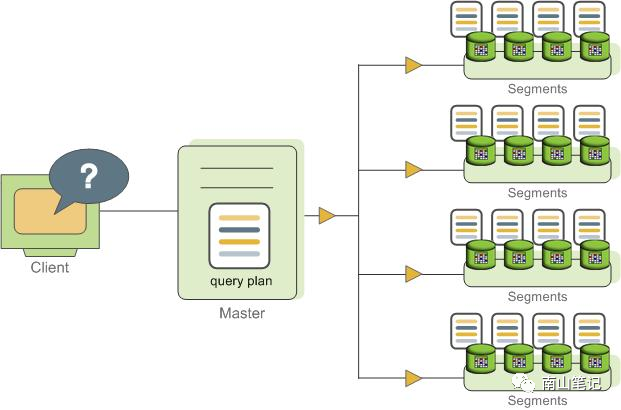
1、客户端请求首先发送到master节点;
2、master节点接收请求后,进行语句解析,优化和生成执行计划;
3、当sql仅涉及特定segment时,则分发到特定segment实例进行执行;
4、当sql涉及到并发执行时,则将该执行计划分发到参与执行的segment实例,并发执行;
5、segment实例负责具体语句执行,执行过程中,根据需要进行数据重分布,并在segment实例间进行数据传输;
6、当所有参与执行的segment实例执行完成后,结果返回到master节点;
7、master节点将sql执行结果返回到客户端。
SQL语句执行计划典型的操作包括表扫描,连接,聚合,排序等典型操作,执行计划顺序自下向上执行,计划中可独立执行的单元称之为分片,分片间可独立并发执行。在GP的执行计划包含一个motion类型的操作,motion又包括了再分布motion和汇集motion,前者主要是查询访问的数据进行再分布后在segment实例间进行传输的过程,后者则是在需要将查询结果返回时在segment实例和master节点间的数据传输。
GP数据库创建模型时需要指定分布键,根据分布键,GP决定数据存储的实例;当查询中包括多张表关联时,不同表的分布键可能存在差异,这个时候就需要将其中的表根据关联列重新进行分布,并在参与执行的segment实例间进行数据传输。从这个角度来看,如果能为关联表指定相同的分布键和分布策略,则会减少执行过程的再分布操作。
SELECT customer,amountFROM sales JOIN customer USING (cust_id)WHERE dateCol = '04-30-2016';
上述SQL执行计划如下图,模型创建时customer表以cust_id为分布键,而sales表以sale_id进行分布,则上述sql执行过程中需要对sales表进行扫描后重新再分布,之后再执行hash join操作。
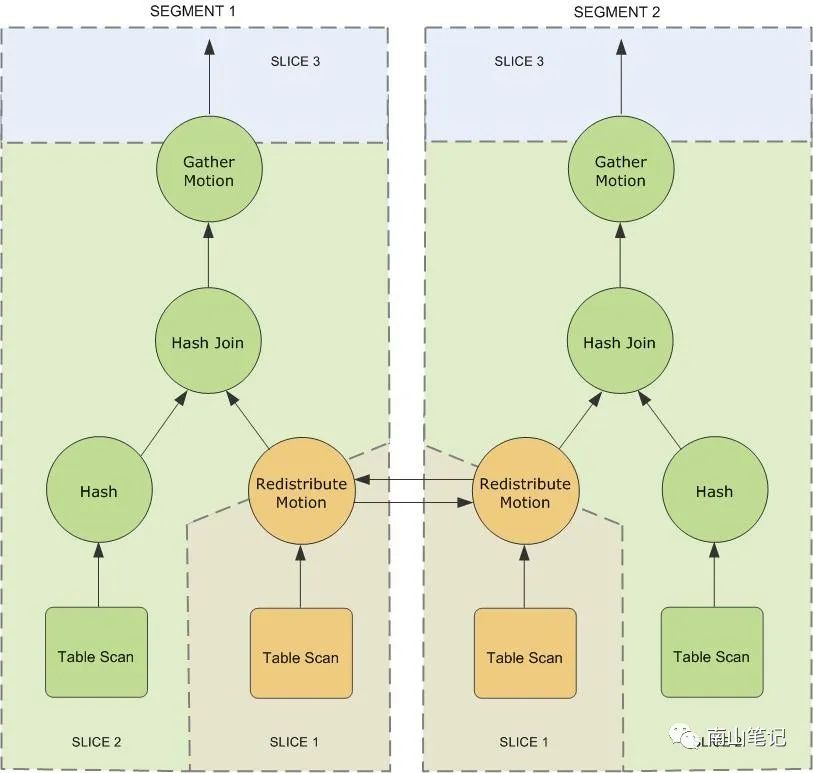
并行执行:
GP在执行SQL的过程中会多个查询工作进程,其中master节点上的工作进程被称作查询分发器(QD),segment实例上的工作进程被称作查询执行器(QE)。QD负责创建并且分发查询计划,以及收集返回最终查询结果;QE则负责完成查询计划中的某个分片,并将处理结果返回到下一个QE。
查询计划的每一个切片至少要分配一个QE,当一部分查询计划需要不同的SEGMENT上的QE进程协作完成时,这相关的QE进程被称作gang。随着部分工作的完成,元组会从一个gang流向查询计划中的下一个gang。其情况如下图:
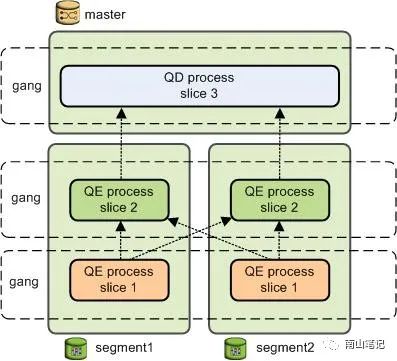
今天重读了GP文档中关于执行计划的讲解,有了更清晰的理解:
1、基于GP进行模型设计时,分布键设计至关重要,不仅仅影响了模型自身的合理分布,而且对后续模型间的关联也会产生较大的影响。
2、之前一直认为聚合类操作可能需要master节点参与,而可能导致master负载过重影响整体性能。今天理解下来,通过再分布操作,segment实例间已经完成相关数据的汇集,应该是不需要master节点来参与。
No.19。
