




Vertica的开发主要从支持的开发接口、SQL开发、数据处理特性和负载均衡管理4个方面进行学习。
标准开发接口方面,Vertica提供了基于ODBC、JDBC和ADO.NET的接口,在此基础上还提供了原生的Python和PERL接口。除了上述的标准接口外,Vertica提供了Kafka的集成,可以将Vertica作为Kafka的数据生产者和消费者,支持将Kafka的topic数据采用COPY加载的方式,快速装入vertica数据。
SQL开发方面,Vertica支持标准的DDL,DML和DCL语句,为了快速数据加载,有特有的COPY语句,以及EXPORT语句等。
以下内容可以关注:
1 Vertica为了提高数据处理效率,针对delete和update语句进行了优化,delete并不执行真正的删除操作,而只是打上删除标记;而update语句则转化为delete/insert的结合,先标记数据删除,然后执行数据插入。这种处理方式带来问题,是需要在后期数据库维护时,进行定期的空间回收操作,通过select purge()语句进行数据清理。
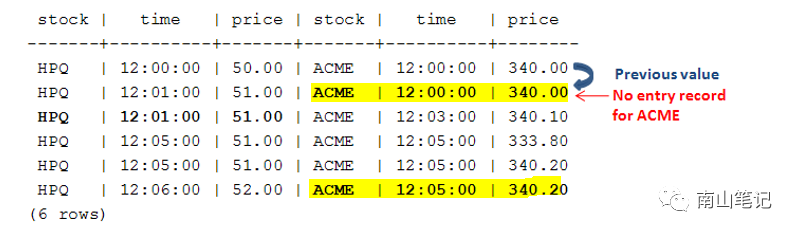
2 SELECT语句在支持常规的表关联外,引入了事件序列关联 ,这是外部联接的扩展,但当不存在匹配时,事件序列联接不使用空值填充未保留的边,而是将其从上一个值中插入的未保留的边值填充。非常适合于基于时间序列进行关联匹配的场景。
示例:

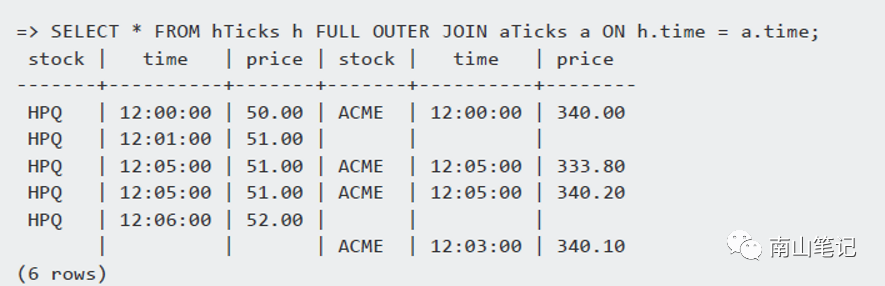
常规的全连接:
采用事件序列关联:
SELECT* FROM hTicks h FULL OUTER JOIN aTicks aON (h.time INTERPOLATE PREVIOUS VALUEa.time);
3 WITH语句处理机制优化
支持2种执行方式,一种以内嵌子查询的方式执行,适合于只引用一次的情况;对于多次引用的with子句,适合于打开物化选项,将子查询结果写入临时表,便于主查询多次引用,查询结束后临时表自动清理。如下:
ALTER SESSION SET PARAMETER EnableWithClauseMaterialization=1;--Begin WITHclauseWITHstore_orders_fact_new AS(SELECT * FROM store.store_orders_factWHERE date_shipped between '2007-12-15' and '2007-12-31')--End WITH clause-- Begin main primary querySELECTstore_key, product_key, product_version, SUM(quantity_ordered*unit_price) AStotal_priceFROM store_orders_fact_newGROUP BY store_key, product_key, product_versionORDER BY total_price;
这是我的第12篇。
文章转载自南山笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
