




Vertica基于支持大规模并行计算,同时采用列式存储、数据压缩、以及基于查询时的PROJECTIONS优化等方式,保证了大数据量下的快速分析。在支持数据快速分析的基础上,通过为装载数据和分析数据存储分离的方式,支持数据实时的插入、更新和删除等操作,与IMPALA相比,为使用人员提供了更高的灵活性。以下记录下其典型特征:
1、集群化部署:
集群支持横向扩展,提供更高的可靠性和计算能力。按官方建议,当集群规模小于120为普通集群,所有节点为对称节点,承载相同功能(备用节点等除外);当集群规模超过120后,需要设置专用的控制节点。
2、部署方式
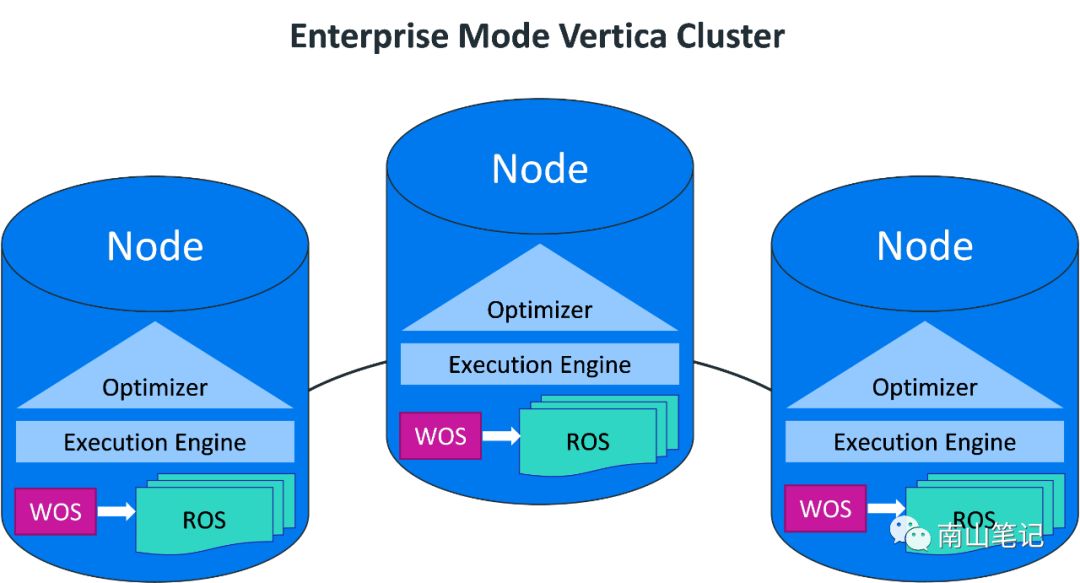
Vertica支持基于企业级部署和EON MODE两种部署方式,前者数据分别存放在集群的各个节点,后者则采用集中共享的方式,存储数据。
EON MODE
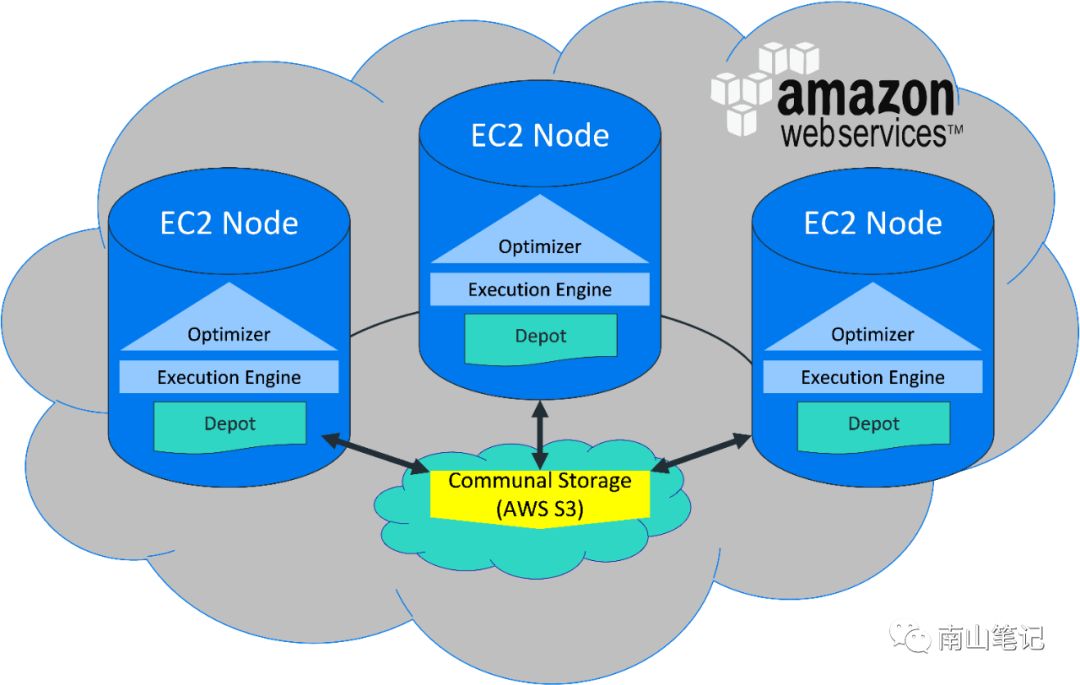
两者的主要优缺点见下表:
项目 | Enterprise Mode | Eon Mode |
性能方面 | 高性能 | 取决于数据是否在本地节点缓存,整体而言低于企业模式的部署 |
安装 | 相对简单 | 部署公用存储相关,云环境的部署比本地方式简单一些 |
负载隔离 | 资源池方式,隔离查询和ETL负载 | 支持在现有集群划分子集群,用于查询或者ETL操作 |
伸缩性 | 增加节点,需对数据分布再平衡 | 易于扩展,方便增加或者去除节点 |
扩展性 | 增加节点 | 增加存储盘 |
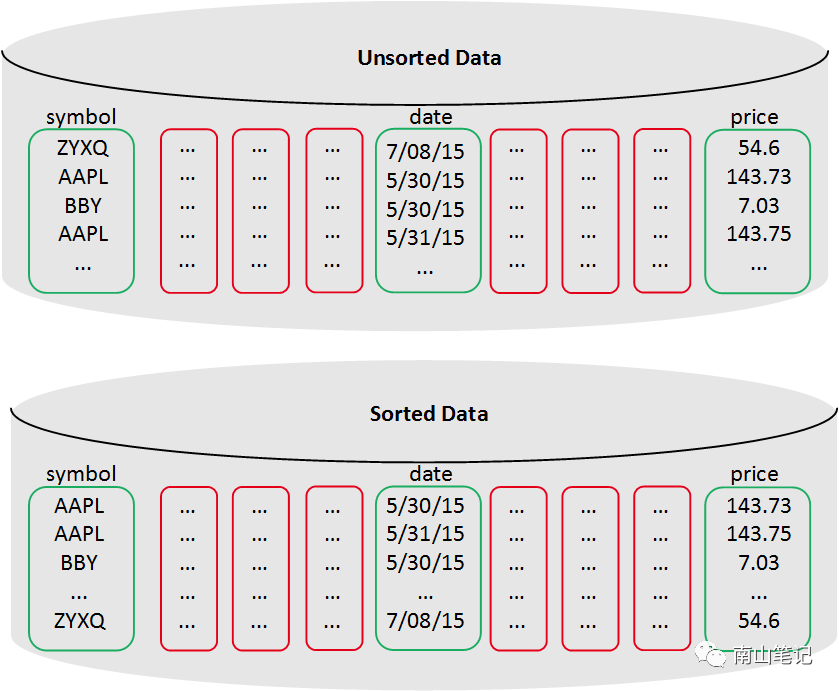
3、列式存储
这个概念已经众所周知,但是在实际开发使用中,大家会经常犯一个错误,就是把列式数据库用作行式存储的数据库,导致性能优势没有发挥出来。
一个基本要求就是,只访问所需要的列。
4、数据存储管理
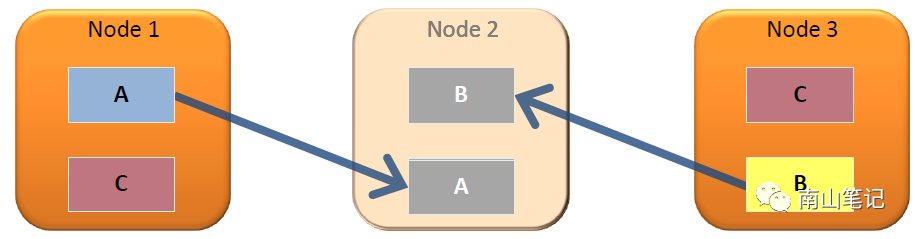
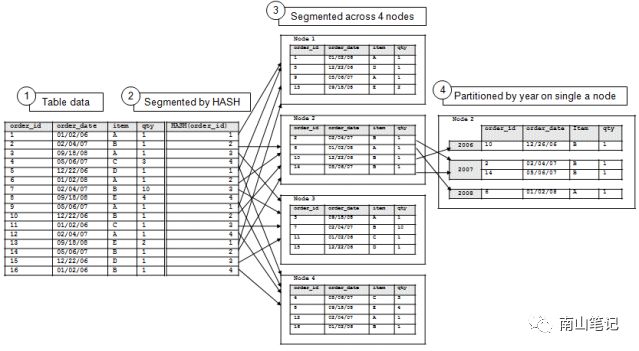
对于大表和小表,采用不同的存储方式,大表采用分段存储在不同的节点,小表则采用复制的方式,每个节点存储相同的数据。
分段是指跨群集节点组织和分发数据,以便实现快速数据清除和提升查询性能。分段的目的是使数据在多个数据库节点上均匀分布,以便所有节点均参与查询执行。对于关联的模型,可以指定的相同的分布字段,保证相同键值数据分布在同一节点。
5、事务支持
作为一个MPP数据,支持读提交和序列读两种事务模式,可以拿来兼做OLTP数据库的部分功能了。
当然,还有其它特征,如数据在具体存储,支持对数据进行编码和压缩;提供了PROJECTIONS的机制,类似于ORACLE的物化视图,在查询时自动进行查询重写优化性能等等。
