




Vertica官方给自己的定义,独立于硬件平台之上的最快的、可扩展的数据分析平台,提供了大规模并行处理、高级分析和机器学习等高性能服务。国外在美国银行、Uber、Cerner等公司使用,国内了解到在光大证券和东方财富等公司投入使用。
其主要有以下特征,大规模并行处理,列式存储,高性能压缩和数据映射等机制,以及广泛的生态系统整合。后续学习中会一一深入了解。
初步印象,与基于hadoop平台的impala相比,其在提供高性能的数据分析服务的同时,支持数据插入和更新,为开发和维护提供了更高的灵活性。Impala数据不可更新的机制还是对开发提出了较多的约束和限制。
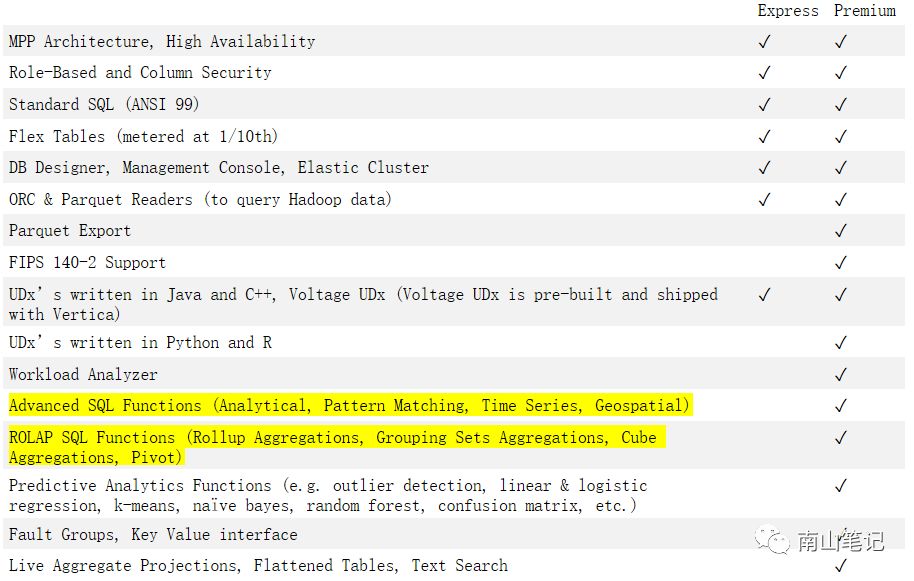
版本选择上,提供了标准版和企业版,从特征上,标准版有较多有价值的功能缺失,见下表,如SQL分析函数、模式匹配和时间序列,以及对机器学习算法的支持等等。
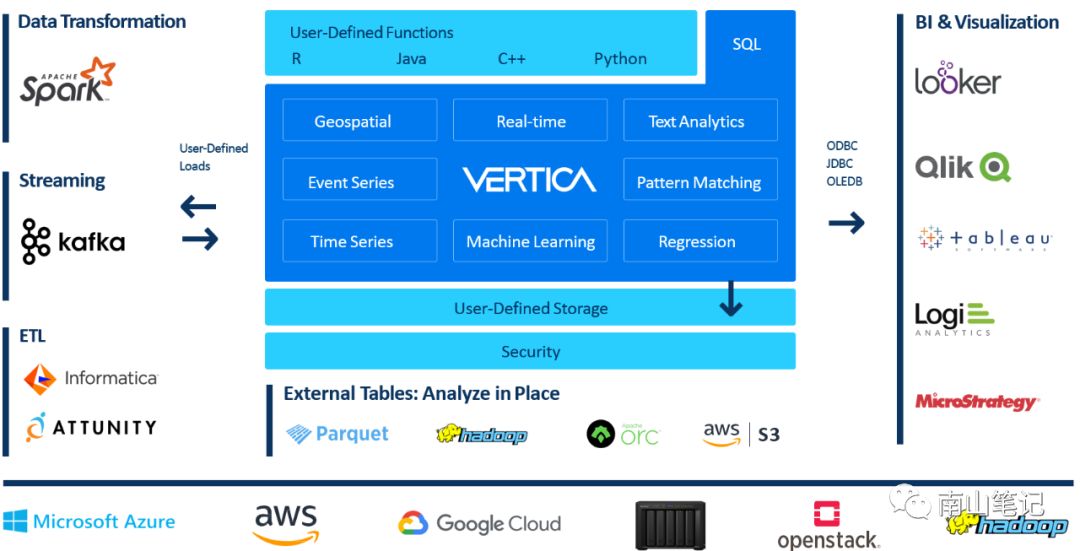
生态系统整合方面,vertica作为数据存储与服务方,可以方便支持hadoop,云计算平台等底层基础平台;数据输入方面,一方面支持传统的ETL工具,如Informatica,同时也对Kafka和spark等新的实时流处理有着较好的支持;在对外输出方面,通过ODBC/JDBC/OLEDB等接口方式,可以和多种BI工具整合使用。
文章转载自南山笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
