




Tutorialspoint PostgreSQL 教程
来源:易百教程
PostgreSQL教程™
这篇PostgreSQL教程提供SQL的基本和高级概念。此PostgreSQL系列教程是专为初学者和专业人士编写提供的,需要读者有一些基本的数据库和编程基础。
PostgreSQL是一个开源对象关系数据库管理系统(ORDBMS)。
这篇PostgreSQL系列教程包括PostgreSQL语言的所有主题,如创建数据库,创建表,删除数据库,删除表,选择数据库,选择表,插入记录,更新记录,删除记录,触发器,功能,过程,游标等。帮助您更好地了解PostgreSQL语言和使用PostgreSQL数据库。
什么是PostgreSQL?
PostgreSQL是一个功能强大的开源对象关系数据库管理系统(ORDBMS)。 用于安全地存储数据; 支持最佳做法,并允许在处理请求时检索它们。
PostgreSQL(也称为Post-gress-Q-L)由PostgreSQL全球开发集团(全球志愿者团队)开发。 它不受任何公司或其他私人实体控制。 它是开源的,其源代码是免费提供的。
PostgreSQL是跨平台的,可以在许多操作系统上运行,如Linux,FreeBSD,OS X,Solaris和Microsoft Windows等。
PostgreSQL的特点
PostgreSQL的特点如下 -
- PostgreSQL可在所有主要操作系统(即Linux,UNIX(AIX,BSD,HP-UX,SGI IRIX,Mac OS X,Solaris,Tru64)和Windows等)上运行。
- PostgreSQL支持文本,图像,声音和视频,并包括用于C/C++,Java,Perl,Python,Ruby,Tcl和开放数据库连接(ODBC)的编程接口。
- PostgreSQL支持SQL的许多功能,例如复杂SQL查询,SQL子选择,外键,触发器,视图,事务,多进程并发控制(MVCC),流式复制(9.0),热备(9.0))。
- 在PostgreSQL中,表可以设置为从“父”表继承其特征。
- 可以安装多个扩展以向PostgreSQL添加附加功能。
PostgreSQL工具
有一些开放源码以及付费工具可用作PostgreSQL的前端工具。 这里列出几个被广泛使用的工具:
1. psql:
它是一个命令行工具,也是管理PostgreSQL的主要工具。 pgAdmin是PostgreSQL的免费开源图形用户界面管理工具。
2. phpPgAdmin:
它是用PHP编写的PostgreSQL的基于Web的管理工具。 它基于phpMyAdmin工具管理MySQL功能来开发。它可以用作PostgreSQL的前端工具。
3. pgFouine:
它是一个日志分析器,可以从PostgreSQL日志文件创建报告。 专有工具有 -
Lightning Admin for PostgreSQL, Borland Kylix, DBOne, DBTools Manager PgManager, Rekall, Data Architect, SyBase Power Designer, Microsoft Access, eRWin, DeZign for Databases, PGExplorer, Case Studio 2, pgEdit, RazorSQL, MicroOLAP Database Designer, Aqua Data Studio, Tuples, EMS Database Management Tools for PostgreSQL, Navicat, SQL Maestro Group products for PostgreSQL, Datanamic DataDiff for PostgreSQL, Datanamic SchemaDiff for PostgreSQL, DB MultiRun PostgreSQL Edition, SQLPro, SQL Image Viewer, SQL Data Sets 等等。
前提条件
在学习PostgreSQL之前,您必须具备SQL和编程语言(如C)的基本知识。
面向读者
这篇PostgreSQL系列教程旨在帮助初学者和专业人士。
问题
我们不能保证您在使用此PostgreSQL教程中不会遇到问题。但是如果有任何错误,请以联系我们并反馈问题给我们。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL教程
PostgreSQL是什么? - PostgreSQL教程™
什么是PostgreSQL?
PostgreSQL是一个功能强大的开源对象关系数据库管理系统(ORDBMS)。 用于安全地存储数据; 支持最佳做法,并允许在处理请求时检索它们。
PostgreSQL(也称为Post-gress-Q-L)由PostgreSQL全球开发集团(全球志愿者团队)开发。 它不受任何公司或其他私人实体控制。 它是开源的,其源代码是免费提供的。
PostgreSQL是跨平台的,可以在许多操作系统上运行,如Linux,FreeBSD,OS X,Solaris和Microsoft Windows等。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL是什么?
PostgreSQL历史 - PostgreSQL教程™
PostgreSQL由计算机科学教授Michael Stonebraker在UCB创建。 它最初叫做Postgres。 1986年由Michael Stonebraker教授作为后续项目和Ingres项目启动,克服了当代数据库系统的问题。 PostgreSQL现在是任何地方都很先进的开源数据库。
历史简介:
1977 - 1985年:开发了一个名为INGRES的项目。
- 关系数据库的概念证明。
- 1980年成立Ingres公司。
- 1994年被Computer Associates购买。
1986-1994: POSTGRES
- 开发INGRES中的概念,重点是面向对象和查询语言Quel。
- INGRES的代码基础未被用作POSTGRES的基础。
- 商业化为Illustra(由Informix购买,之后由IBM购买)。
1994-1995: Postgres95
- 1994年增加了对SQL的支持。
- 1995年发布为Postgres95。
- 1996年重新发布为PostgreSQL 6.0。
- 建立PostgreSQL全球开发团队。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL历史
PostgreSQL特点 - PostgreSQL教程™
PostgreSQL的特点如下 -
- PostgreSQL可在所有主要操作系统(即Linux,UNIX(AIX,BSD,HP-UX,SGI IRIX,Mac OS X,Solaris,Tru64)和Windows等)上运行。
- PostgreSQL支持文本,图像,声音和视频,并包括用于C/C++,Java,Perl,Python,Ruby,Tcl和开放数据库连接(ODBC)的编程接口。
- PostgreSQL支持SQL的许多功能,例如复杂SQL查询,SQL子选择,外键,触发器,视图,事务,多进程并发控制(MVCC),流式复制(9.0),热备(9.0))。
- 在PostgreSQL中,表可以设置为从“父”表继承其特征。
- 可以安装多个扩展以向PostgreSQL添加附加功能。
PostgreSQL工具
有一些开放源码以及付费工具可用作PostgreSQL的前端工具。 这里列出几个被广泛使用的工具:
1. psql:
它是一个命令行工具,也是管理PostgreSQL的主要工具。 pgAdmin是PostgreSQL的免费开源图形用户界面管理工具。
2. phpPgAdmin:
它是用PHP编写的PostgreSQL的基于Web的管理工具。 它基于phpMyAdmin工具管理MySQL功能来开发。它可以用作PostgreSQL的前端工具。
3. pgFouine:
它是一个日志分析器,可以从PostgreSQL日志文件创建报告。 专有工具有 -
Lightning Admin for PostgreSQL, Borland Kylix, DBOne, DBTools Manager PgManager, Rekall, Data Architect, SyBase Power Designer, Microsoft Access, eRWin, DeZign for Databases, PGExplorer, Case Studio 2, pgEdit, RazorSQL, MicroOLAP Database Designer, Aqua Data Studio, Tuples, EMS Database Management Tools for PostgreSQL, Navicat, SQL Maestro Group products for PostgreSQL, Datanamic DataDiff for PostgreSQL, Datanamic SchemaDiff for PostgreSQL, DB MultiRun PostgreSQL Edition, SQLPro, SQL Image Viewer, SQL Data Sets 等等。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL特点
PostgreSQL命令语法大全 - PostgreSQL教程™
可以使用help语句查看所有postgreSQL语句的语法。 按照以下步骤查看PostgreSQL中所有语句的语法。
- 安装postgreSQL后,打开psql为:程序文件 -> PostgreSQL 9.2 -> SQL Shell(psql)
- 使用以下语句查看特定语句的语法。 postgres-#\ help&
所有PostgreSQL语句
在这里,我们提供了所有postgreSQL语句及其语法的列表:
ABORT语句:
语法:
ABORT [ WORK | TRANSACTION ]
ALTER AGGREGATE语句:
语法:
ALTER AGGREGATE name ( type ) RENAME TO new_name
ALTER AGGREGATE name ( type ) OWNER TO new_owner
ALTER CONVERSION语句:
语法:
ALTER CONVERSION name RENAME TO new_name
ALTER CONVERSION name OWNER TO new_owner
ALTER DATABASE语句:
语法:
ALTER DATABASE name SET parameter { TO | = } { value | DEFAULT }
ALTER DATABASE name RESET parameter
ALTER DATABASE name RENAME TO new_name
ALTER DATABASE name OWNER TO new_owner
ALTER DOMAIN语句:
语法:
ALTER DOMAIN name { SET DEFAULT expression | DROP DEFAULT }
ALTER DOMAIN name { SET | DROP } NOT NULL
ALTER DOMAIN name ADD domain_constraint
ALTER DOMAIN name DROP CONSTRAINT constraint_name [ RESTRICT | CASCADE ]
ALTER DOMAIN name OWNER TO new_owner
ALTER FUNCTION语句:
语法:
ALTER FUNCTION name ( [ type [, ...] ] ) RENAME TO new_name
ALTER FUNCTION name ( [ type [, ...] ] ) OWNER TO new_owner
ALTER GROUP语句:
语法:
ALTER GROUP groupname ADD USER username [, ... ]
ALTER GROUP groupname DROP USER username [, ... ]
ALTER GROUP groupname RENAME TO new_name
ALTER INDEX语句:
语法:
ALTER INDEX name OWNER TO new_owner
ALTER INDEX name SET TABLESPACE indexspace_name
ALTER INDEX name RENAME TO new_name
ALTER LANGUAGE语句:
语法:
ALTER LANGUAGE name RENAME TO new_name
ALTER OPERATOR语句:
语法:
ALTER OPERATOR name ( { lefttype | NONE } , { righttype | NONE } )
OWNER TO new_owner
ALTER OPERATOR CLASS语句:
语法:
ALTER OPERATOR CLASS name USING index_method RENAME TO new_name
ALTER OPERATOR CLASS name USING index_method OWNER TO new_owner
ALTER SCHEMA语句:
语法:
ALTER SCHEMA name RENAME TO new_name
ALTER SCHEMA name OWNER TO new_owner
ALTER SEQUENCE语句:
语法:
ALTER SEQUENCE name [ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ RESTART [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
ALTER TABLE语句:
语法:
ALTER TABLE [ ONLY ] name [ * ]
action [, ... ]
ALTER TABLE [ ONLY ] name [ * ]
RENAME [ COLUMN ] column TO new_column
ALTER TABLE name
RENAME TO new_name
ALTER TABLESPACE语句:
语法:
ALTER TABLESPACE name RENAME TO new_name
ALTER TABLESPACE name OWNER TO new_owner
ALTER TRIGGER语句:
语法:
ALTER TRIGGER name ON table RENAME TO new_name
ALTER TYPE语句:
语法:
ALTER TYPE name OWNER TO new_owner
ALTER USER语句:
语法:
ALTER USER name [ [ WITH ] option [ ... ] ]
ALTER USER name RENAME TO new_name
ALTER USER name SET parameter { TO | = } { value | DEFAULT }
ALTER USER name RESET parameter
ANALYSE语句:
语法:
ANALYZE [ VERBOSE ] [ table [ (column [, ...] ) ] ]
BEGIN语句:
语法:
BEGIN [ WORK | TRANSACTION ] [ transaction_mode [, ...] ]
CHECKPOINT语句:
语法:
CHECKPOINT
CLOSE语句:
语法:
CLOSE name
CLUSTER语句:
语法:
CLUSTER index_name ON table_name
CLUSTER table_name
CLUSTER
COMMIT语句:
语法:
COMMIT [ WORK | TRANSACTION ]
COPY语句:
语法:
COPY table_name [ ( column [, ...] ) ]
FROM { 'filename' | STDIN }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE NOT NULL column [, ...] ]
COPY table_name [ ( column [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ WITH ]
[ BINARY ]
[ OIDS ]
[ DELIMITER [ AS ] 'delimiter' ]
[ NULL [ AS ] 'null string' ]
[ CSV [ QUOTE [ AS ] 'quote' ]
[ ESCAPE [ AS ] 'escape' ]
[ FORCE QUOTE column [, ...] ]
CREATE AGGREGATE语句:
语法:
CREATE AGGREGATE name (
BASETYPE = input_data_type,
SFUNC = sfunc,
STYPE = state_data_type
[ , FINALFUNC = ffunc ]
[ , INITCOND = initial_condition ]
)
CREATE CAST语句:
语法:
CREATE CAST (source_type AS target_type)
WITH FUNCTION func_name (arg_types)
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CAST (source_type AS target_type)
WITHOUT FUNCTION
[ AS ASSIGNMENT | AS IMPLICIT ]
CREATE CONSTRAINT TRIGGER语句:
语法:
CREATE CONSTRAINT TRIGGER name
AFTER events ON
table_name constraint attributes
FOR EACH ROW EXECUTE PROCEDURE func_name ( args )
CREATE CONVERSION语句:
语法:
CREATE [DEFAULT] CONVERSION name
FOR source_encoding TO dest_encoding FROM func_name
CREATE DATABASE语句:
语法:
CREATE DATABASE name
[ [ WITH ] [ OWNER [=] db_owner ]
[ TEMPLATE [=] template ]
[ ENCODING [=] encoding ]
[ TABLESPACE [=] tablespace ] ]
CREATE DOMAIN语句:
语法:
CREATE DOMAIN name [AS] data_type
[ DEFAULT expression ]
[ constraint [ ... ] ]
CREATE FUNCTION语句:
语法:
CREATE [ OR REPLACE ] FUNCTION name ( [ [ arg_name ] arg_type [, ...] ] )
RETURNS ret_type
{ LANGUAGE lang_name
| IMMUTABLE | STABLE | VOLATILE
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
[ WITH ( attribute [, ...] ) ]
CREATE GROUP语句:
语法:
CREATE GROUP name [ [ WITH ] option [ ... ] ]
Where option can be:
SYSID gid
| USER username [, ...]
CREATE INDEX语句:
语法:
CREATE [ UNIQUE ] INDEX name ON table [ USING method ]
( { column | ( expression ) } [ opclass ] [, ...] )
[ TABLESPACE tablespace ]
[ WHERE predicate ]
CREATE LANGUAGE语句:
语法:
CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE name
HANDLER call_handler [ VALIDATOR val_function ]
CREATE OPERATOR语句:
语法:
CREATE OPERATOR name (
PROCEDURE = func_name
[, LEFTARG = left_type ] [, RIGHTARG = right_type ]
[, COMMUTATOR = com_op ] [, NEGATOR = neg_op ]
[, RESTRICT = res_proc ] [, JOIN = join_proc ]
[, HASHES ] [, MERGES ]
[, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ]
[, LTCMP = less_than_op ] [, GTCMP = greater_than_op ]
)
CREATE OPERATOR CLASS语句:
语法:
CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type
USING index_method AS
{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ]
| FUNCTION support_number func_name ( argument_type [, ...] )
| STORAGE storage_type
} [, ... ]
CREATE RULE语句:
语法:
CREATE [ OR REPLACE ] RULE name AS ON event
TO table [ WHERE condition ]
DO [ ALSO | INSTEAD ] { NOTHING | command | ( command ; command ... ) }
CREATE SCHEMA语句:
语法:
CREATE SCHEMA schema_name
[ AUTHORIZATION username ] [ schema_element [ ... ] ]
CREATE SCHEMA AUTHORIZATION username
[ schema_element [ ... ] ]
CREATE SEQUENCE语句:
语法:
CREATE [ TEMPORARY | TEMP ] SEQUENCE name
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ]
[ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
CREATE TABLE语句:
语法:
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name (
{ column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]
| table_constraint
| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ] } [, ... ]
)
[ INHERITS ( parent_table [, ... ] ) ]
[ WITH OIDS | WITHOUT OIDS ]
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ]
[ TABLESPACE tablespace ]
CREATE TABLE AS语句:
语法:
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name
[ (column_name [, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]
AS query
CREATE TABLESPACE语句:
语法:
CREATE TABLESPACE tablespace_name [ OWNER username ] LOCATION 'directory'
CRFEATE TRIGGER语句:
语法:
CREATE TRIGGER name { BEFORE | AFTER } { event [ OR ... ] }
ON table [ FOR [ EACH ] { ROW | STATEMENT } ]
EXECUTE PROCEDURE func_name ( arguments )
CREATE TYPE语句:
语法:
CREATE TYPE name AS
( attribute_name data_type [, ... ] )
CREATE TYPE name (
INPUT = input_function,
OUTPUT = output_function
[ , RECEIVE = receive_function ]
[ , SEND = send_function ]
[ , ANALYZE = analyze_function ]
[ , INTERNALLENGTH = { internal_length | VARIABLE } ]
[ , PASSEDBYVALUE ]
[ , ALIGNMENT = alignment ]
[ , STORAGE = storage ]
[ , DEFAULT = default ]
[ , ELEMENT = element ]
[ , DELIMITER = delimiter ]
)
CREATE USER语句:
语法:
CREATE USER name [ [ WITH ] option [ ... ] ]
CREATE VIEW语句:
语法:
CREATE [ OR REPLACE ] VIEW name [ ( column_name [, ...] ) ] AS query
DEALLOCATE语句:
语法:
DEALLOCATE [ PREPARE ] plan_name
DECLARE语句:
语法:
DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ]
CURSOR [ { WITH | WITHOUT } HOLD ] FOR query
[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]
DELETE语句:
语法:
DELETE FROM [ ONLY ] table [ WHERE condition ]
DROP AGGREGATE语句:
语法:
DROP AGGREGATE name ( type ) [ CASCADE | RESTRICT ]
DROP CAST语句:
语法:
DROP CAST (source_type AS target_type) [ CASCADE | RESTRICT ]
DROP CONVERSION语句:
语法:
DROP CONVERSION name [ CASCADE | RESTRICT ]
DROP DATABASE语句:
语法:
DROP DATABASE name
DROP DOMAIN语句:
语法:
DROP DOMAIN name [, ...] [ CASCADE | RESTRICT ]
DROP FUNCTION语句:
语法:
DROP FUNCTION name ( [ type [, ...] ] ) [ CASCADE | RESTRICT ]
DROP GROUP语句:
语法:
DROP GROUP name
DROP INDEX语句:
语法:
DROP INDEX name [, ...] [ CASCADE | RESTRICT ]
DROP LANGUAGE语句:
语法:
DROP [ PROCEDURAL ] LANGUAGE name [ CASCADE | RESTRICT ]
DROP OPERATOR语句:
语法:
DROP OPERATOR name ( { left_type | NONE } , { right_type | NONE } )
[ CASCADE | RESTRICT ]
DROP OPERATOR CLASS语句:
语法:
DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]
DROP RULE语句:
语法:
DROP RULE name ON relation [CASCADE | RESTRICT ]
DROP SCHEMA语句:
语法:
DROP SCHEMA name [, ...] [ CASCADE | RESTRICT ]
DROP SEQUENCE语句:
语法:
DROP SEQUENCE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLE语句:
语法:
DROP TABLE name [, ...] [ CASCADE | RESTRICT ]
DROP TABLESPACE语句:
语法:
DROP TABLESPACE tablespace_name
DROP TRIGGER语句:
语法:
DROP TRIGGER name ON table [ CASCADE | RESTRICT ]
DROP TYPE语句:
语法:
DROP TYPE name [, ...] [ CASCADE | RESTRICT ]
DROP USER语句:
语法:
DROP USER name
DROP VIEW语句:
语法:
DROP VIEW name [, ...] [ CASCADE | RESTRICT ]
END语句:
语法:
END [ WORK | TRANSACTION ]
EXECUTE语句:
语法:
EXECUTE plan_name [ (parameter [, ...] ) ]
EXPLAIN语句:
语法:
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
FETCH语句:
语法:
FETCH [ direction { FROM | IN } ] cursor_name
INSERT语句:
语法:
INSERT INTO table [ ( column [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) | query }
LISTEN语句:
语法:
LISTEN name
LOAD语句:
语法:
LOAD 'filename'
LOCK语句:
语法:
LOCK [ TABLE ] name [, ...] [ IN lock_mode MODE ] [ NOWAIT ]
MOVE语句:
语法:
MOVE [ direction { FROM | IN } ] cursor_name
NOTIFY语句:
语法:
NOTIFY name
PREPARE语句:
语法:
PREPARE plan_name [ (data_type [, ...] ) ] AS statement
REINDEX语句:
语法:
REINDEX { DATABASE | TABLE | INDEX } name [ FORCE ]
RESET语句:
语法:
RESET name
RESET ALL
ROLLBACK语句:
语法:
ROLLBACK [ WORK | TRANSACTION ]
ROLLBACK TO SAVEPOINT语句:
语法:
ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name
SAVEPOINT语句:
语法:
SAVEPOINT savepoint_name
SELECT语句:
语法:
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SELECT INTO语句:
语法:
SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]
* | expression [ AS output_name ] [, ...]
INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY expression [, ...] ]
[ HAVING condition [, ...] ]
[ { UNION | INTERSECT | EXCEPT } [ ALL ] select ]
[ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ]
[ LIMIT { count | ALL } ]
[ OFFSET start ]
[ FOR UPDATE [ OF table_name [, ...] ] ]
SET语句:
语法:
SET [ SESSION | LOCAL ] name { TO | = } { value | 'value' | DEFAULT }
SET [ SESSION | LOCAL ] TIME ZONE { time_zone | LOCAL | DEFAULT }
SET CONSTRAINTS语句:
语法:
SET CONSTRAINTS { ALL | name [, ...] } { DEFERRED | IMMEDIATE }
SET TRANSACTION语句:
语法:
SET TRANSACTION transaction_mode [, ...]
SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
SHOW语句:
语法:
SHOW name
SHOW ALL
START TRANSACTION语句:
语法:
START TRANSACTION [ transaction_mode [, ...] ]
TRUNCATE TABLE语句:
语法:
TRUNCATE [ TABLE ] name
UPDATE语句:
语法:
UPDATE [ ONLY ] table SET column = { expression | DEFAULT } [, ...]
[ FROM from_list ]
[ WHERE condition ]
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL命令语法大全
PostgreSQL数据类型 - PostgreSQL教程™
数据类型指定要在表字段中存储哪种类型的数据。 在创建表时,对于每列必须使用数据类型。
PotgreSQL中主要有三种类型的数据类型。 此外,用户还可以使用CREATE TYPE SQL命令创建自己的自定义数据类型。
以下是PostgreSQL中主要有三种类型的数据类型:
- 数值数据类型
- 字符串数据类型
- 日期/时间数据类型
数值数据类型
数字数据类型用于指定表中的数字数据。
名称 | 描述 | 存储大小 | 范围 |
smallint | 存储整数,小范围 | 2字节 | -32768 至 +32767 |
integer | 存储整数。使用这个类型可存储典型的整数 | 4字节 | -2147483648 至 +2147483647 |
bigint | 存储整数,大范围。 | 8字节 | -9223372036854775808 至 9223372036854775807 |
decimal | 用户指定的精度,精确 | 变量 | 小数点前最多为131072个数字; 小数点后最多为16383个数字。 |
numeric | 用户指定的精度,精确 | 变量 | 小数点前最多为131072个数字; 小数点后最多为16383个数字。 |
real | 可变精度,不精确 | 4字节 | 6位数字精度 |
double | 可变精度,不精确 | 8字节 | 15位数字精度 |
serial | 自动递增整数 | 4字节 | 1 至 2147483647 |
bigserial | 大的自动递增整数 | 8字节 | 1 至 9223372036854775807 |
字符串数据类型
String数据类型用于表示字符串类型值。
数据类型 | 描述 |
char(size) | 这里大小是要存储的字符数。固定长度字符串,右边的空格填充到相等大小的字符。 |
character(size) | 这里大小是要存储的字符数。 固定长度字符串。 右边的空格填充到相等大小的字符。 |
varchar(size) | 这里大小是要存储的字符数。 可变长度字符串。 |
character varying(size) | 这里大小是要存储的字符数。 可变长度字符串。 |
text | 可变长度字符串。 |
日期/时间数据类型
日期/时间数据类型用于表示使用日期和时间值的列。
名称 | 描述 | 存储大小 | 最小值 | 最大值 | 解析度 |
timestamp [ (p) ] [不带时区 ] | 日期和时间(无时区) | 8字节 | 4713 bc | 294276 ad | 1微秒/14位数 |
timestamp [ (p) ]带时区 | 包括日期和时间,带时区 | 8字节 | 4713 bc | 294276 ad | |
date | 日期(没有时间) | 4字节 | 4713 bc | 5874897 ad | 1微秒/14位数 |
time [ (p) ] [ 不带时区 ] | 时间(无日期) | 8字节 | 00:00:00 | 24:00:00 | 1微秒/14位数 |
time [ (p) ] 带时区 | 仅限时间,带时区 | 12字节 | 00:00:00+1459 | 24:00:00-1459 | 1微秒/14位数 |
interval [ fields ] [ (p) ] | 时间间隔 | 12字节 | -178000000年 | 178000000年 | 1微秒/14位数 |
一些其他数据类型
布尔类型:
名称 | 描述 | 存储大小 |
boolean | 它指定true或false的状态。 | 1字节 |
货币类型:
名称 | 描述 | 存储大小 | 范围 |
money | 货币金额 | 8字节 | -92233720368547758.08 至 +92233720368547758.07 |
几何类型:
几何数据类型表示二维空间对象。最根本的类型:点 - 形成所有其他类型的基础。
名称 | 存储大小 | 表示 | 描述 |
point | 16字节 | 在一个平面上的点 | (x,y) |
line | 32字节 | 无限线(未完全实现) | ((x1,y1),(x2,y2)) |
lseg | 32字节 | 有限线段 | ((x1,y1),(x2,y2)) |
box | 32字节 | 矩形框 | ((x1,y1),(x2,y2)) |
path | 16+16n字节 | 封闭路径(类似于多边形) | ((x1,y1),…) |
polygon | 40+16n字节 | 多边形(类似于封闭路径) | ((x1,y1),…) |
circle | 24字节 | 圆 | <(x,y),r>(中心点和半径) |
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL数据类型
PostgreSQL安装(Windows) - PostgreSQL教程™
按照以下步骤在您的Windows系统上安装PostgreSQL。在安装时关闭第三方防毒软件。
选择您想要的PostgreSQL的版本号以及对应系统,并从这里下载并下载:http://www.enterprisedb.com/products-services-training/pgdownload#windows
由于我的系统是 Windows 10 64位,所以选择以下对应的版本 -
- PostgreSQL9.6.2
- Windows x86-64
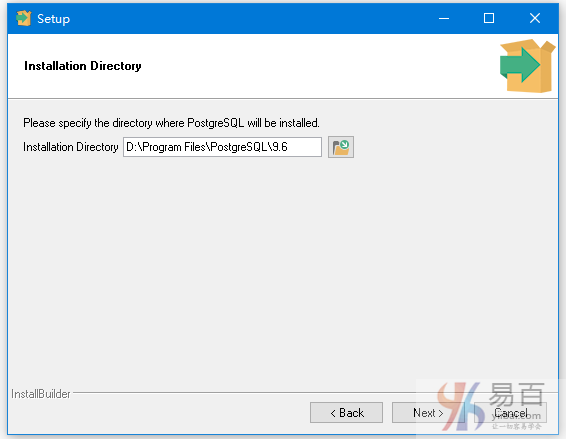
以管理员身份运行下载的Postgresql-9.6.2-windows.exe来安装PostgreSQL。与安装其它软件一样,没有什么特别之处,选择安装目录等下一步就好。

选择要安装的位置。 默认情况下,它安装在程序文件夹(C:\Program File)中。
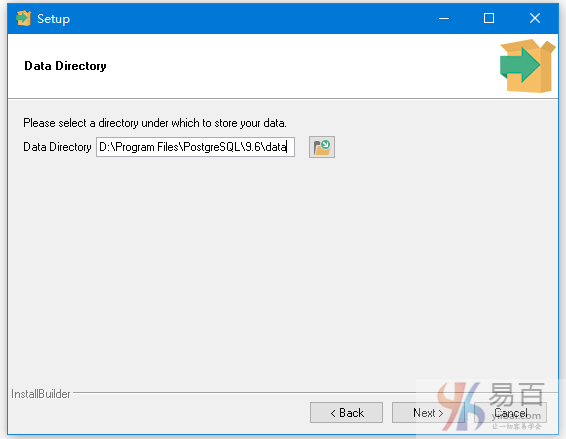
选择一个目录来存储数据。 默认情况下,它存储在PostgreSQL安装目录的data目录下,这里使用默认的就行 -
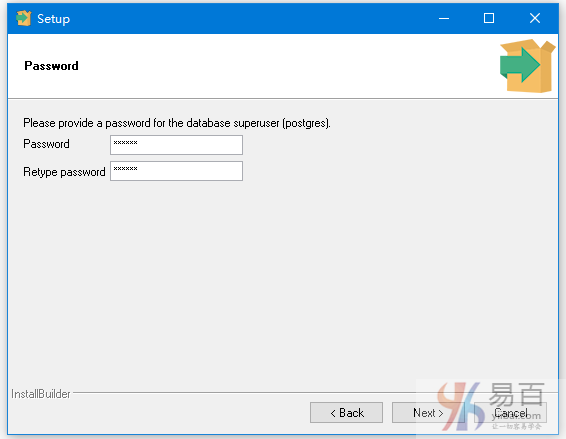
设置将要求您输入密码,因此请您输入密码,这里我输入的密码是:123456。
设置PostgreSQL服务器的端口,保持默认,点击下一步 -
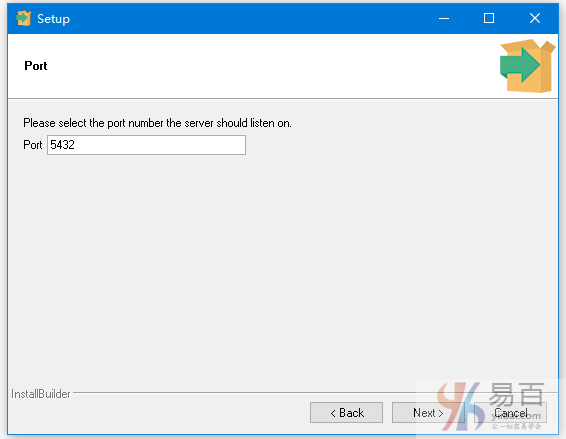
这一步将要求选择“locale”,这里保持默认。然后开始安装 -
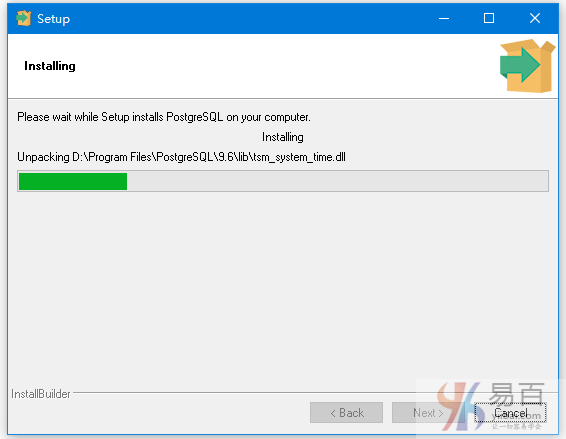
安装过程就绪。完成安装过程需要一些时间。 完成安装过程后,您将看到以下屏幕 -

取消选中复选框按钮,然后单击完成按钮完成安装。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL安装(Windows)
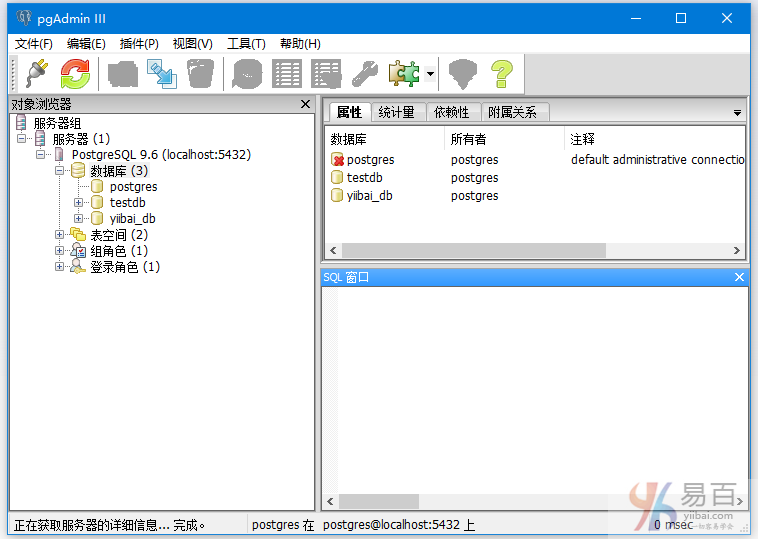
PostgreSQL创建数据库 - PostgreSQL教程™
在PostgreSQL中,可以使用CREATE DATABASE命令创建数据库。
语法:
CREATE DATABASE database_name;
这里,database_name是指定要创建的数据库的名称。
PostgreSQL使用UI创建数据库
在您的系统中安装PostgreSQL后,打开开始菜单,然后单击pgAdmin。会得到一个这样的页面:
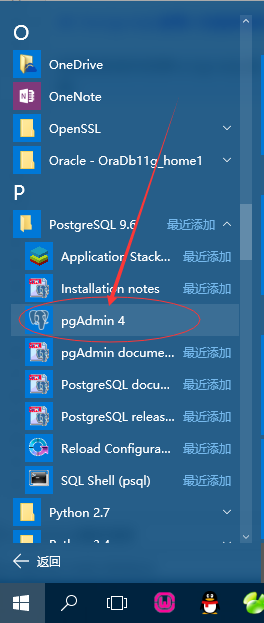
打开pgAdmin,第一次打开可能需要你输入密码,结果如下 -
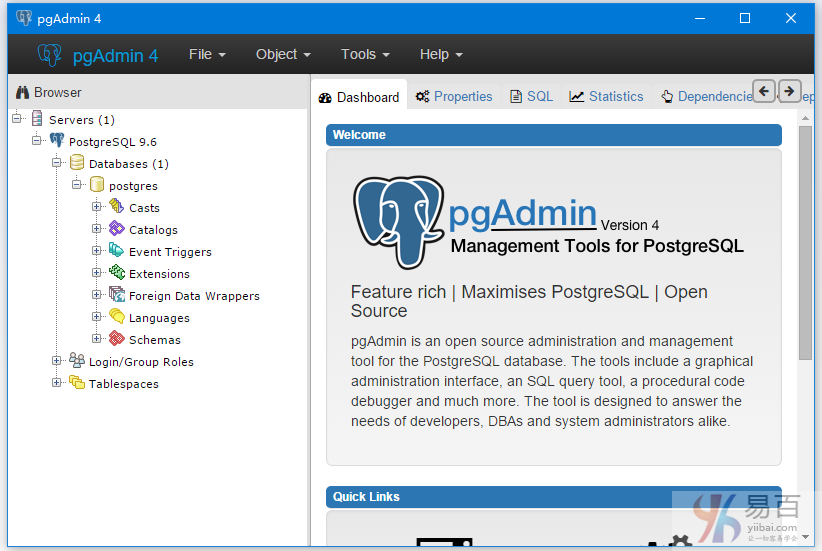
右键单击PostgreSQL 9.6并将PostgreSQL连接到本地主机服务器。
右键单击数据库(Databases),转到新数据库,将出现一个弹出框,如下图所示 -
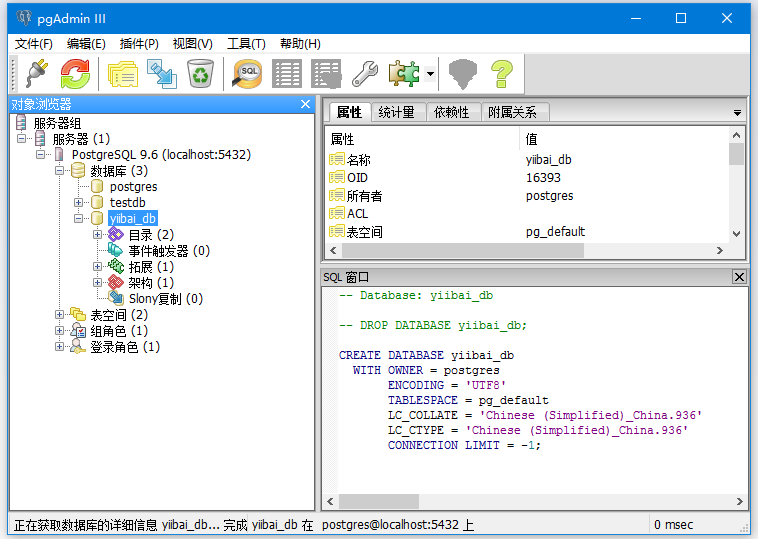
然后键入您要的数据库名称,这里创建的数据库名称是:yiibai_db,如下图所示 -
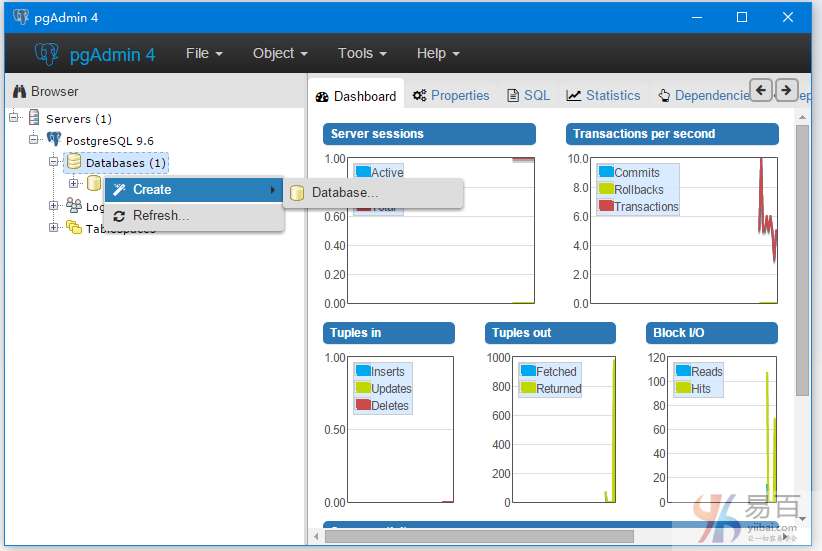
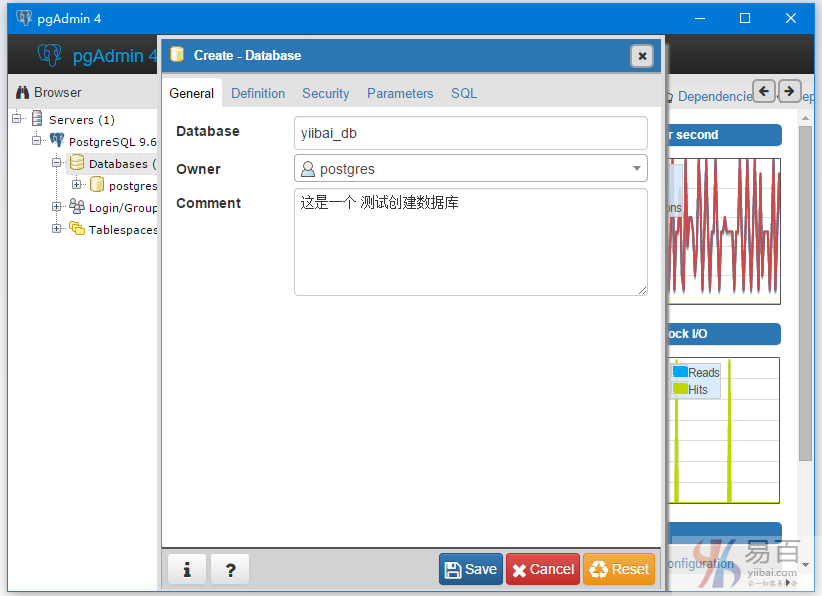
点击保存(Save)就可以了。
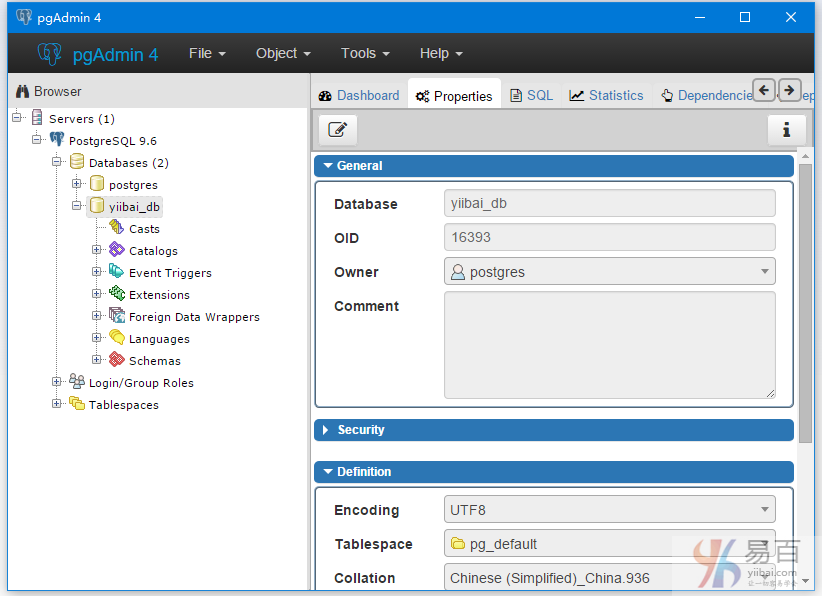
创建新的数据库(yiibai_db)如下图所示 -
PostgreSQL使用查询工具创建数据库
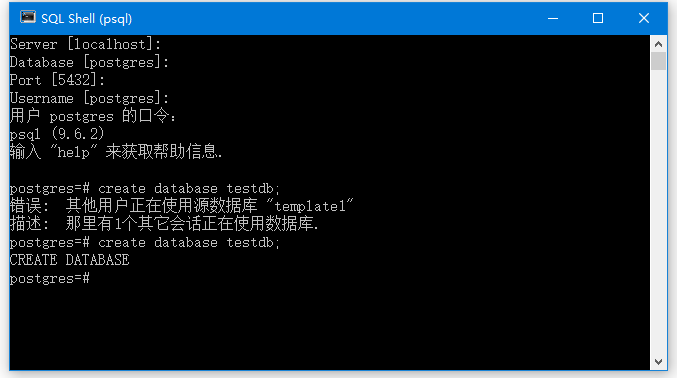
打开SQL Shell(psql),执行以下创建语句 -
create database testdb;
执行结果如下 -
查看数据库 -
postgres=# \l
数据库列表
名称 | 拥有者 | 字元编码 | 校对规则 | Ctype | 存取权限
-----------+----------+----------+--------------------------------+--------------------------------+-----------------------
postgres | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 |
template0 | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 | =c/postgres +
| | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 |
yiibai_db | postgres | UTF8 | Chinese (Simplified)_China.936 | Chinese (Simplified)_China.936 |
(5 行记录)
postgres=#
或者在 pgAdmin 的左侧中查看,结果如下 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL创建数据库
PostgreSQL删除数据库 - PostgreSQL教程™
在PostgreSQL中,您可以删除不再需要的数据库。应该遵循以下操作步骤:
- 通过左键单击数据库(database)。
- 右键单击,您将看到一个删除/删除选项。
- 单击删除/删除选项完全删除数据库。
提示:考虑到 pgAdmin4 在Windows 10运行不够稳定,Query Tool经常出现连接失败等问题,这篇文章开始,我们安装并使用 pgAdmin3 。
PostgreSQL删除/删除数据库示例(方法一)
在这里,我们将删除数据库“testdb”。
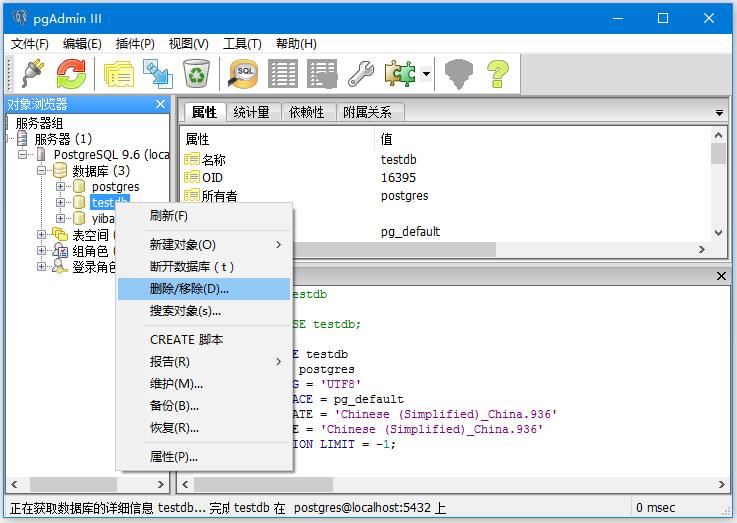
右键单击数据库:testdb,左键单击delete/drop选项。将收到以下弹出框。
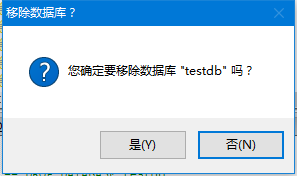
点击“是(Yes)”完全删除数据库“testdb”。
看到结果:
现在,可以看到已经删除了数据库:testdb,它不显示在左侧列表中了。
使用SQL删除数据库(方法二)
postgres=# drop database testdb;
DROP DATABASE
postgres=#
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL删除数据库
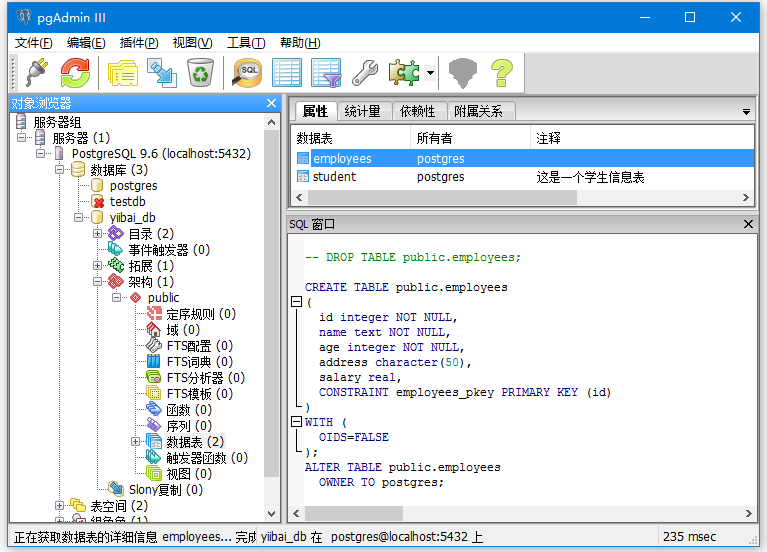
PostgreSQL创建表 - PostgreSQL教程™
在PostgreSQL中,CREATE TABLE语句用于在任何给定的数据库中创建一个新表。
语法:
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( one or more columns )
);
PostgreSQL使用UI创建表 -
- 首先选择要创建表的数据库。
- 左键单击与所选数据库关联的框类型结构,将看到目录和模式(架构)。
- 左键单击与模式(架构)关联的框类型结构。现在可以看到public。
- 左键单击与公共(public)关联的框类型结构,就可以看到有数据表。
- 选择数据表,右键单击数据表,会得到一个新的弹出表框,创建所需的表。
参见示例:
这里创建的表是:student:
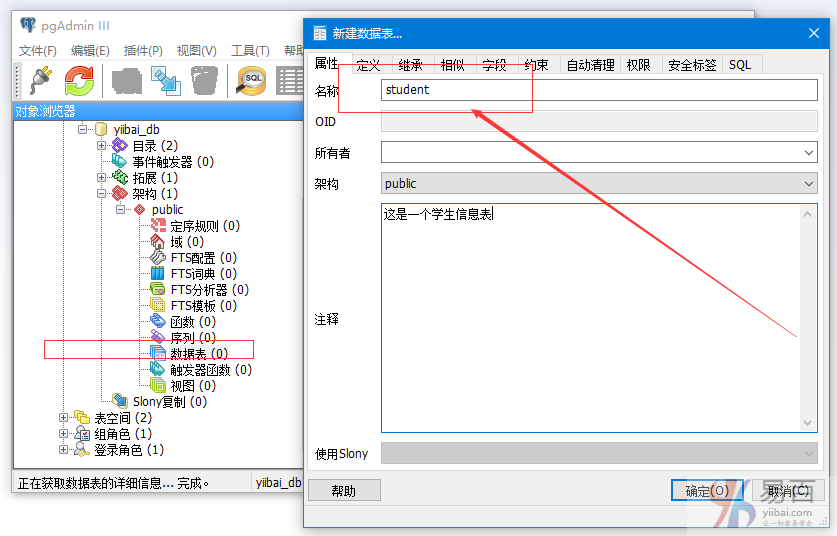
步骤2 -
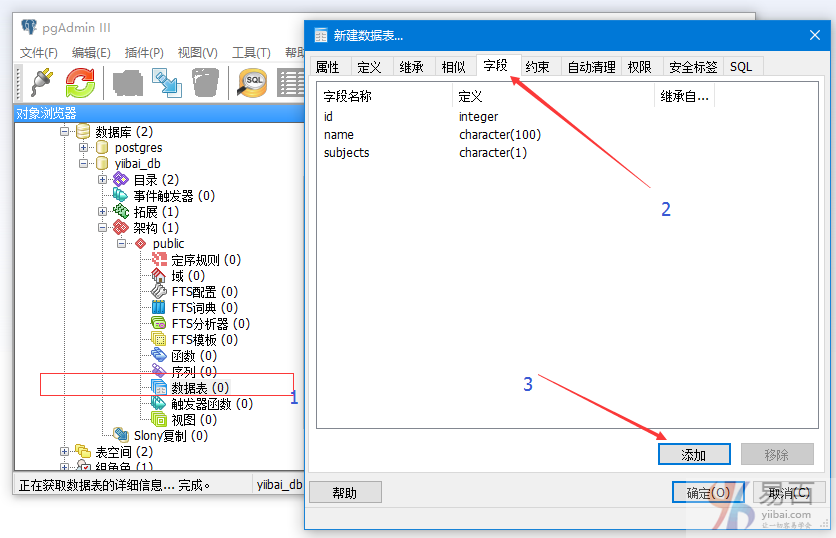
输出:

PostgreSQL使用查询工具创建表
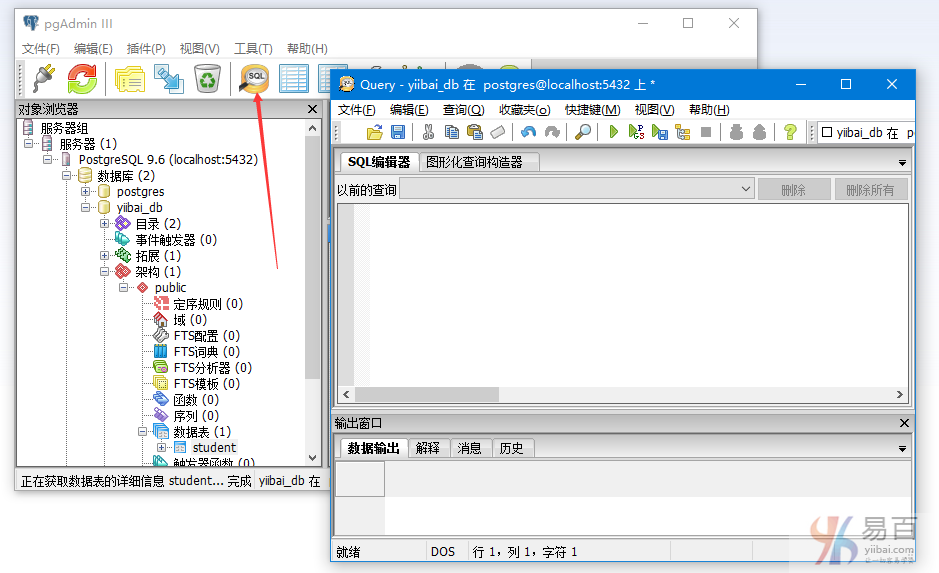
按照上述4个步骤,打一个“SQL编辑器”,如下图所示 -
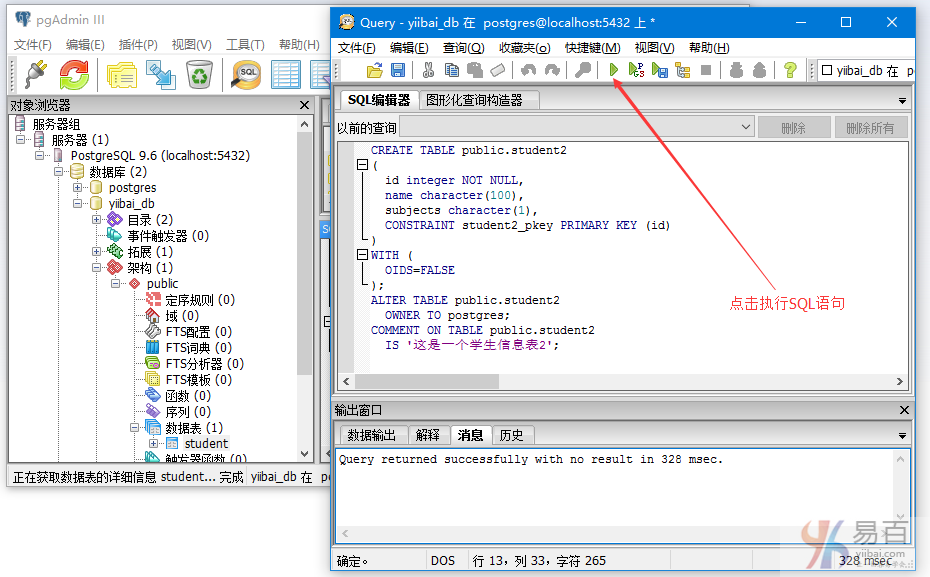
在SQL编辑器中编写以下SQL语句,来创建另一个表:student2 -
CREATE TABLE public.student2
(
id integer NOT NULL,
name character(100),
subjects character(1),
CONSTRAINT student2_pkey PRIMARY KEY (id)
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.student2
OWNER TO postgres;
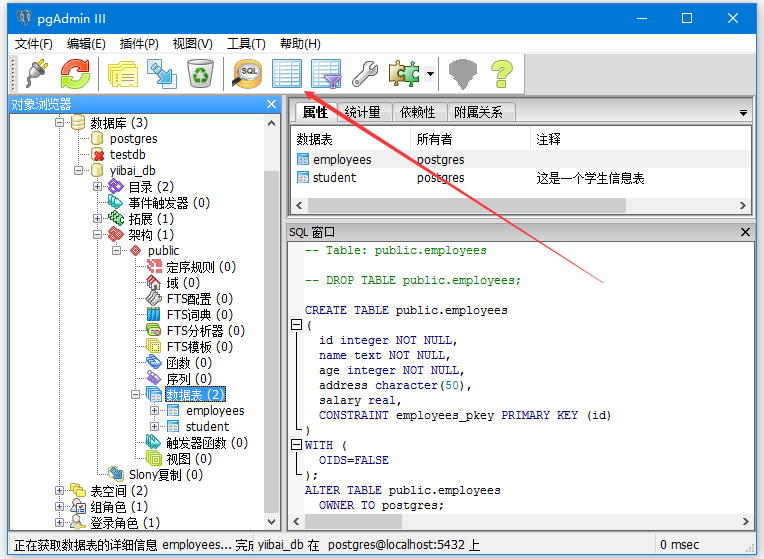
COMMENT ON TABLE public.student2
IS '这是一个学生信息表2';
如下图所示 -
在这里,您可以看到新创建的表:student2,如下图所示 -
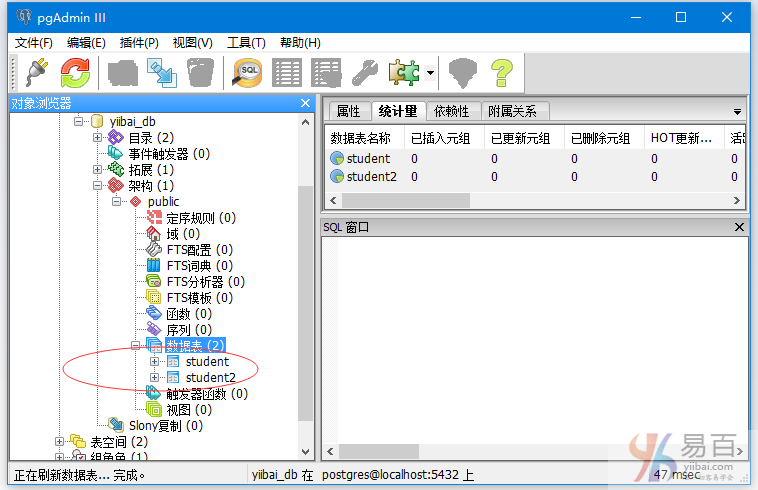
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL创建表
PostgreSQL删除表 - PostgreSQL教程™
按照以下步骤删除/删除或删除PostgreSQL中的区分表。
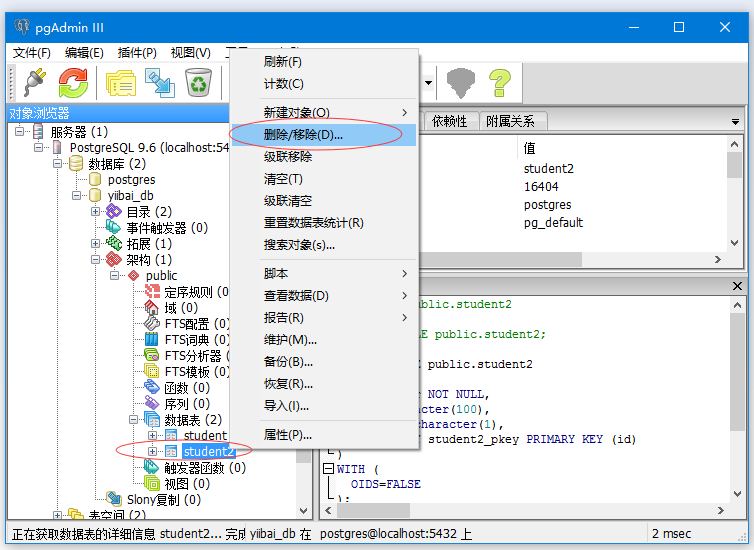
- 选择要删除或删除的表。
- 右键单击所选表,这里选择表为:student2。
- 找到表并选择点击完成。
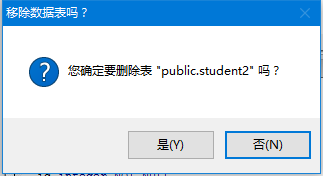
现在应该会看到这样的:
单击是(Yes),表将被删除。
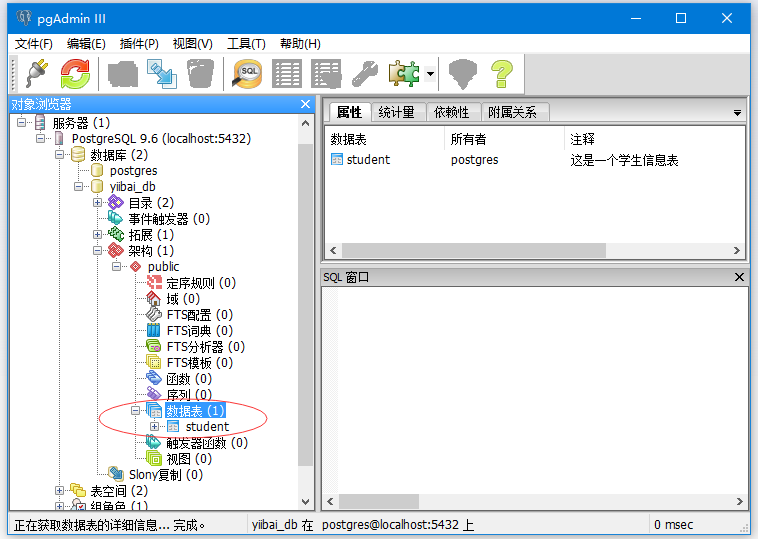
输出:
现在可以看到没有那个student2的表了。
使用SQL语句来删除表
postgres=#
postgres=# drop table student2;
DROP TABLE
postgres=#
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL删除表
PostgreSQL模式(架构) - PostgreSQL教程™
模式(也叫架构)是指定的表集合。 它还可以包含视图,索引,序列,数据类型,运算符和函数。
创建模式
在PostgreSQL中,CREATE SCHEMA语句用于创建模式。 模式不能嵌套。
语法:
CREATE SCHEMA schema_name;
通过SQL命令行直接创建 -
CREATE SCHEMA myschema;
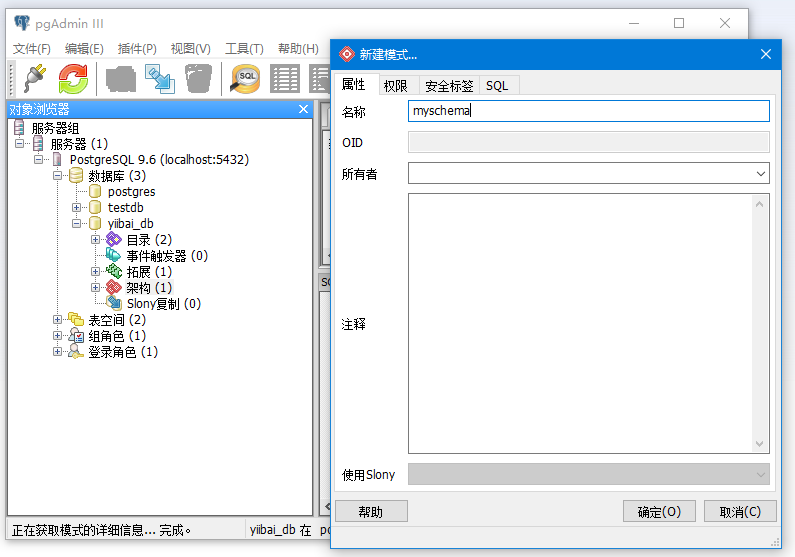
使用PostgreSQL UI创建模式
按照以下步骤创建模式:
打开pgAdmin并将PostgreSQL连接到本地主机服务器。点击加号图标展开数据库。
可以看到有三个数据库。 在这里,我们使用 yiibai_db 数据库,展开数据库“yiibai_db”。如下图所示 -
在这里,您可以看到“模式(架构)”。在架构上并右键单击它,您可以看到新建模式选项。 点击它并创建一个新的模式(架构)。如下图所示 -
创建一个名为“myschema”的模式(架构)。
PostgreSQL在Schema中创建表
按照以下步骤在模式中创建表:
展开新创建的模式“myschema”,您可以看到以下内容。
在“myschema”的模式(架构)下,选择数据表并右键点击。可以看到“新建数据表”。 单击新建数据表并创建表。
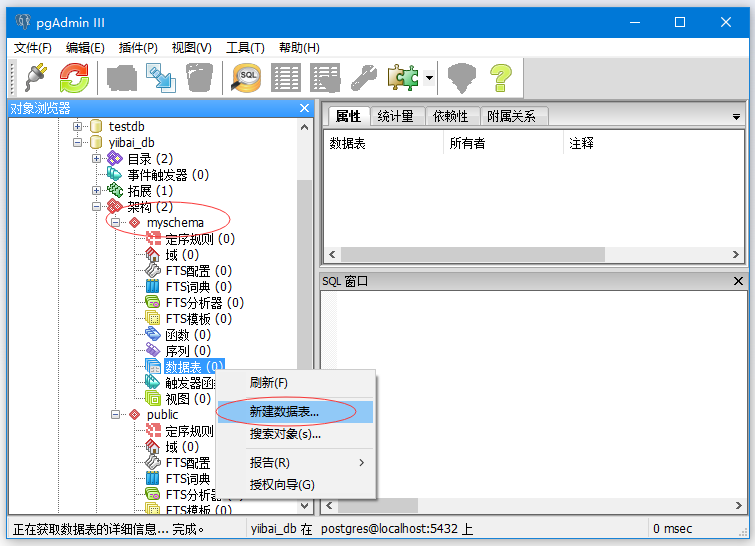
可以通过单击列并添加按钮添加列。
-- Table: myschema.tb_test
-- DROP TABLE myschema.tb_test;
CREATE TABLE myschema.tb_test
(
id integer,
name character(254)
)
WITH (
OIDS=FALSE
);
ALTER TABLE myschema.tb_test
OWNER TO postgres;
删除PostgreSQL模式
如果您不再需要它,您可以删除这个架构。
按照以下说明删除或删除模式(架构):
点击架构,选择“myschema”并点击右键。就应该看到删除/移除选项。 点击删除/移除选项。
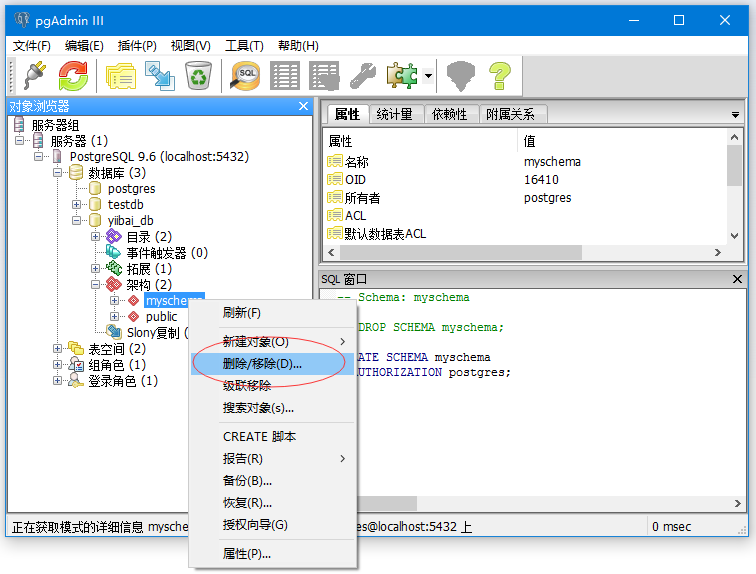
点击“是”按钮删除。 如果显示以下框。如果看到以下框,请单击确定。
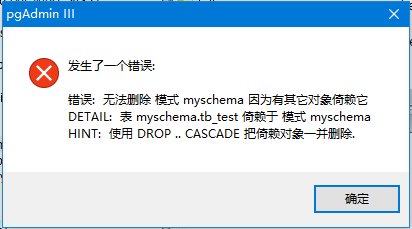
然后,可选择先删除从属对象。或直接右键点击“myschema”,选择“级联移除”,如下所示 -
单击“是”删除从属对象。删除依赖对象后,目标模式自动删除。
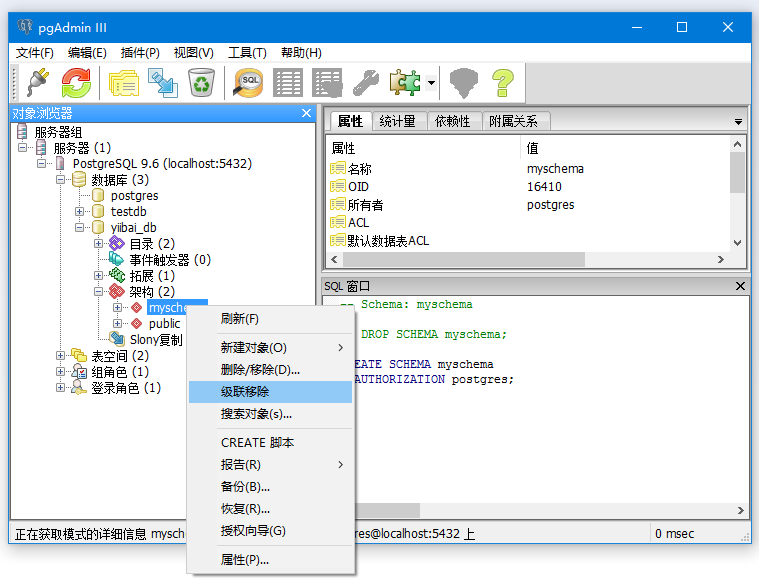
使用架构的优点:
- 模式有助于多用户使用一个数据库,而不会互相干扰。
- 它将数据库对象组织成逻辑组,使其更易于管理。
- 可以将第三方模式放入单独的模式中,以避免与其他对象的名称相冲突。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL模式(架构)
PostgreSQL插入数据(INSERT语句) - PostgreSQL教程™
在PostgreSQL中,INSERT查询用于在表中插入新行。 您可以一次插入单行或多行到表中。
语法:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);
注意:column1, column2, column3,...columnN是要插入数据的表中的列的名称。
PostgreSQL使用UI插入语句
让我们举个例子来看看如何向表中插入值。 在这里,我们有一个表名“EMPLOYEES”:
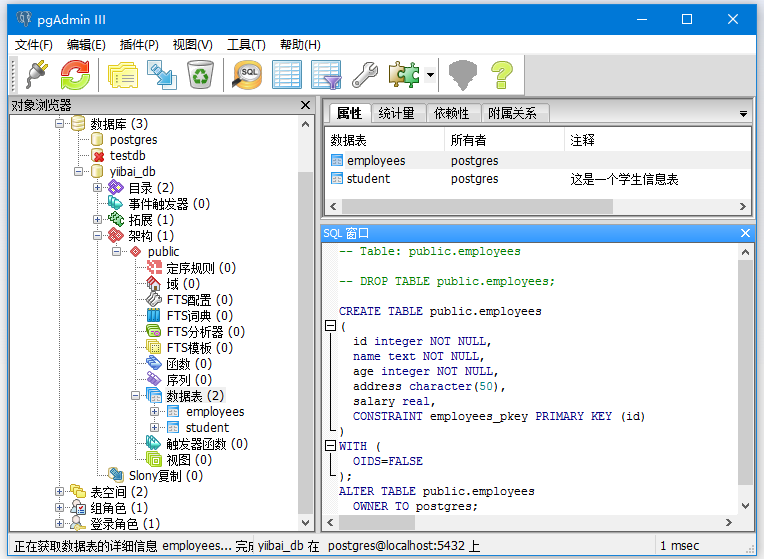
按照以下步骤在表“EMPLOYEES”中插入值:
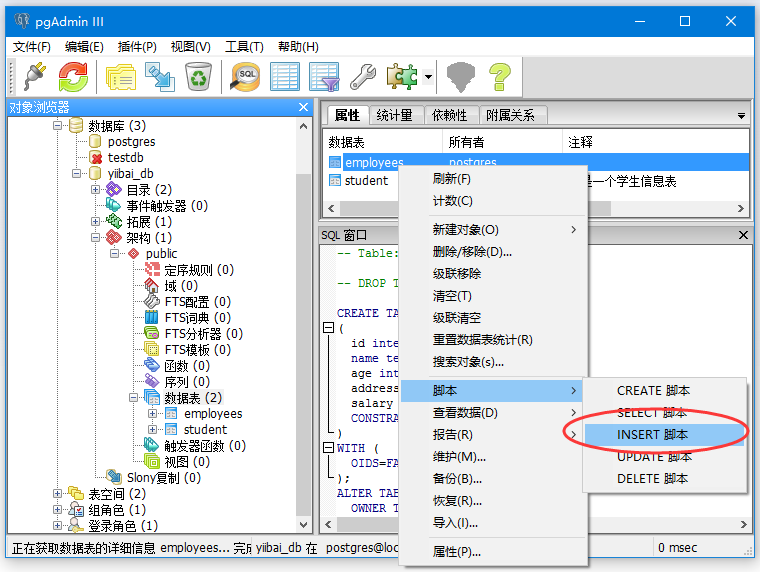
选择表“EMPLOYEES”,右键单击。将看到一个选项脚本,将光标移动到脚本上,将看到“INSERT脚本”选项。点击会得到一个这样的页面:
把值放在“?”的地方 然后单击“执行查询”按钮(以绿色开始图标)执行查询。
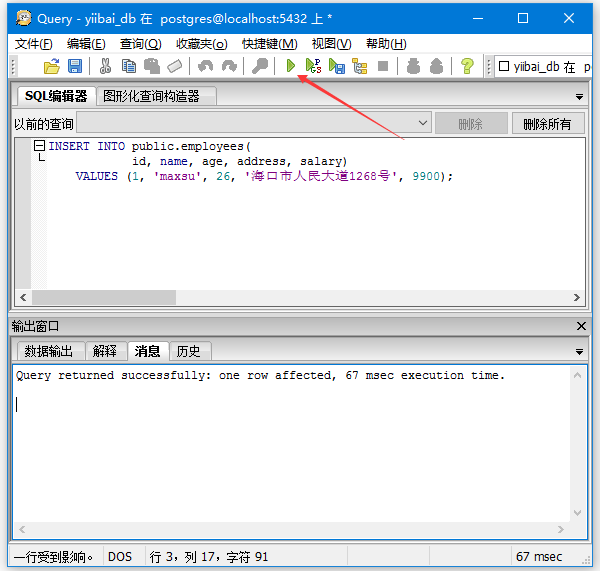
看到输出:
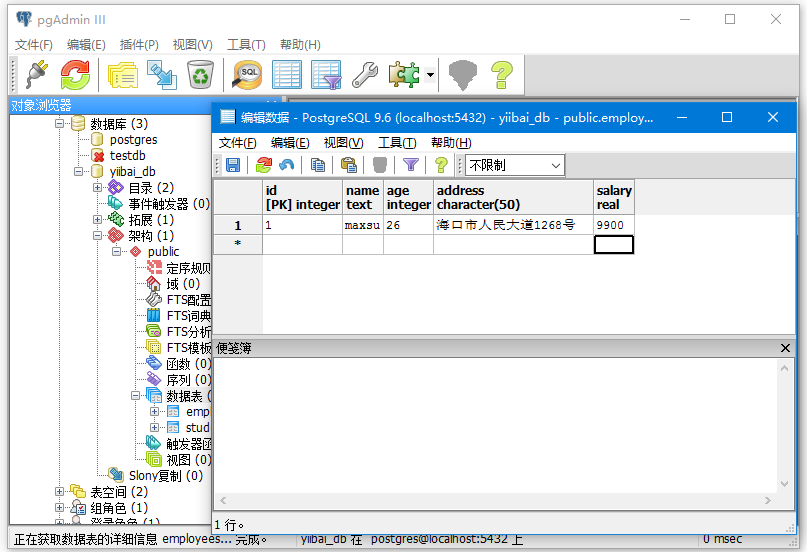
您可以通过点击像箭头指向标记的结构的表格来查看所选表格的输出。
PostgreSQL使用查询工具插入语句
打开查询工具并执行以下查询以在表中插入多个值:
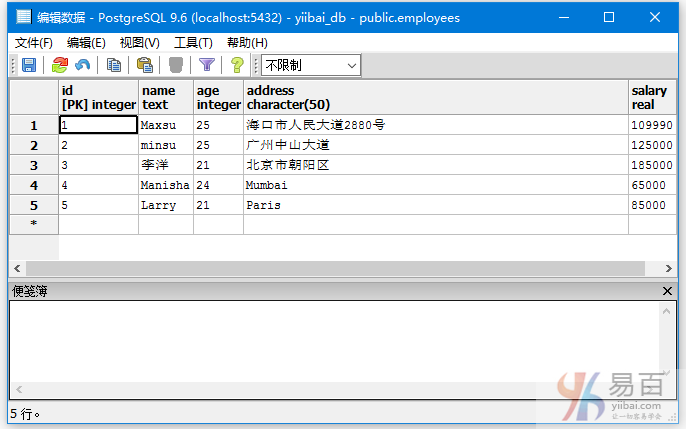
INSERT INTO EMPLOYEES( ID, NAME, AGE, ADDRESS, SALARY)
VALUES
(1, 'Maxsu', 25, '海口市人民大道2880号', 109990.00 ),
(2, 'minsu', 25, '广州中山大道 ', 125000.00 ),
(3, '李洋', 21, '北京市朝阳区', 185000.00),
(4, 'Manisha', 24, 'Mumbai', 65000.00),
(5, 'Larry', 21, 'Paris', 85000.00);
将上面的插入语句放到查询编辑器中,执行后如下图所示 -
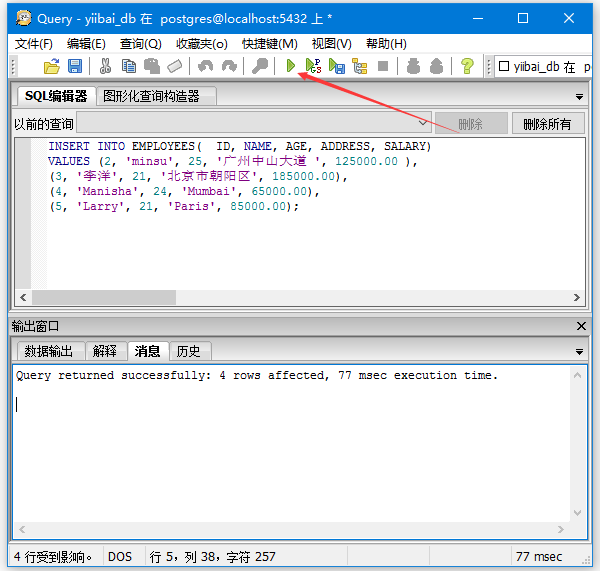
查到输出结果:
您可以通过点击箭头指向标记的结构的表格来查看所选表格的输出,如下图所示 -
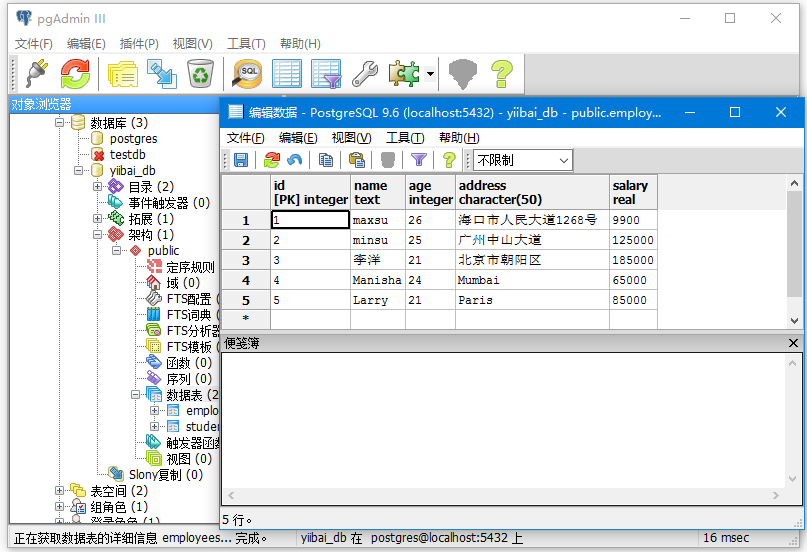
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL插入数据(INSERT语句)
PostgreSQL查询数据(SELECT语句) - PostgreSQL教程™
在PostgreSQL中,SELECT语句用于从数据库表中检索数据。 数据以结果表格的形式返回。 这些结果表称为结果集。
语法:
SELECT "column1", "column2".."column" FROM "table_name";
这里,column1,column2,.. columnN指定检索哪些数据的列。 如果要从表中检索所有字段,则必须使用以下语法:
SELECT * FROM "table_name";
示例1:
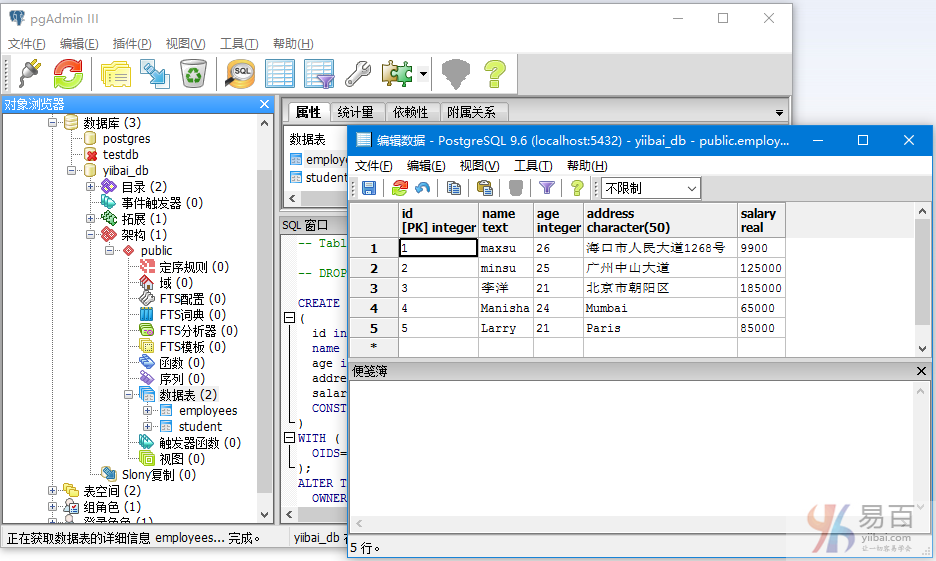
我们来看一下“EMPLOYEES”表,如下图所示 -
“EMPLOYEES”表有以下记录,如下图所示 -
按照以下步骤选择一个表
选择数据表,单击“SQL”图标。就看到“查询编辑器”。会得到一个这样的界面并在其中输入查询语句:

示例2:
执行以下查询从表中检索指定字段:
SELECT id,name FROM EMPLOYEES;
或者
SELECT ID, NAME, AGE, SALARY FROM EMPLOYEES;
两者都会得到不一样的结果:
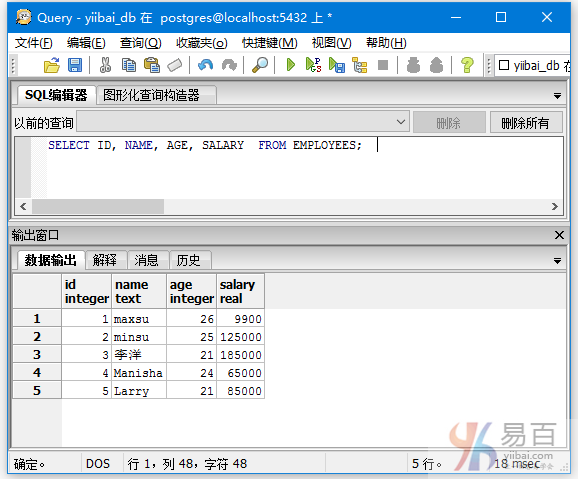
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL查询数据(SELECT语句)
PostgreSQL更新数据(UPDATE语句) - PostgreSQL教程™
在PostgreSQL中,UPDATE语句用于修改表中现有的记录。 要更新所选行,您必须使用WHERE子句,否则将更新所有行。
语法:
以下是update语句的基本语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
看看下面这个例子:
考虑一个名为“EMPLOYEES”的表,其中包含以下数据。
数据如下所示 -
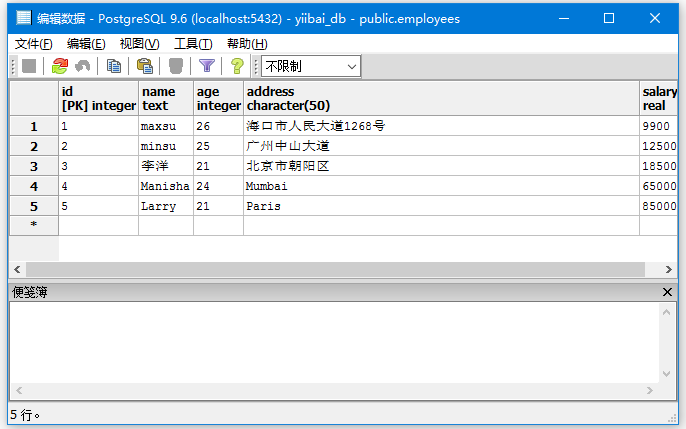
按照以下步骤更新表
选择表“EMPLOYEES”,右键单击将看到一个选项脚本,将光标移动到脚本上,您将看到“UPDATE脚本”选项,然后点击 -
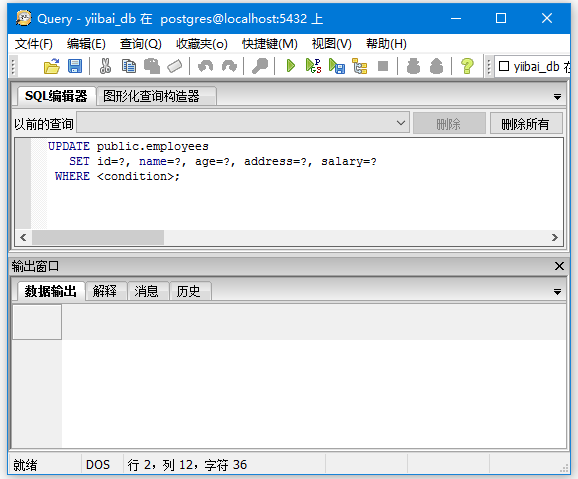
把值放在“?”的地方 并完成WHERE条件<condition>,然后点击“执行”按钮执行查询。
示例
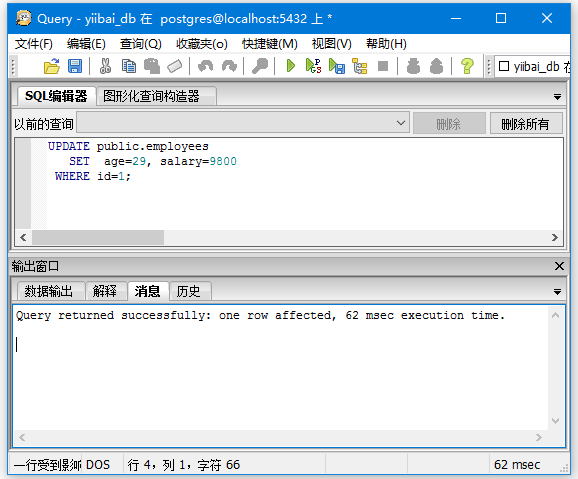
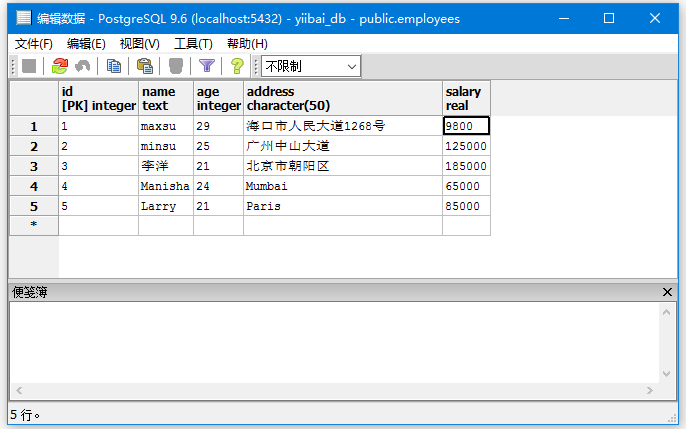
将ID为1的员工(“EMPLOYEES”表)记录更新AGE的值为29和SALARY的值为9800。
输出:
您可以看到ID为1的记录的已更新:AGE和SALARY列。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL更新数据(UPDATE语句)
PostgreSQL删除数据(DELETE语句) - PostgreSQL教程™
DELETE语句用于从表中删除现有记录。 “WHERE”子句用于指定删除所选记录的条件,如是不指定条件则将删除所有记录。
语法:
以下是DELETE语句的基本语法:
DELETE FROM table_name
WHERE [condition];
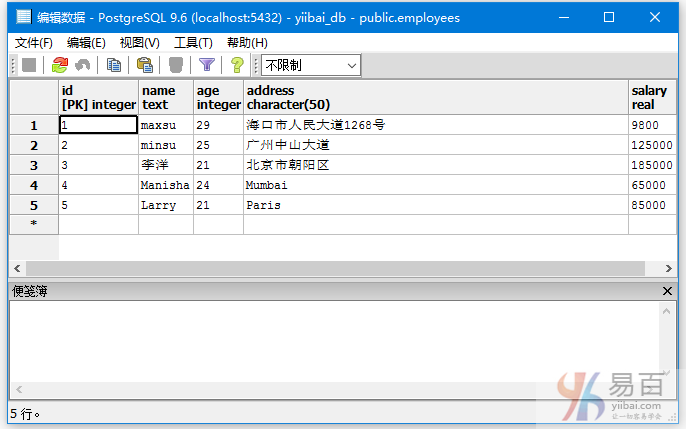
下面来看看一个例子:
考虑一个名为“EMPLOYEES”的表,其中包含以下数据。
数据如下所示 -
按照以下步骤删除表中的数据
选择表“EMPLOYEES”并右键单击。将看到一个脚本选项,将光标移动到脚本选项上,将看到“DELETE脚本”选项然后点击它。
就会得到一个这样的页面:
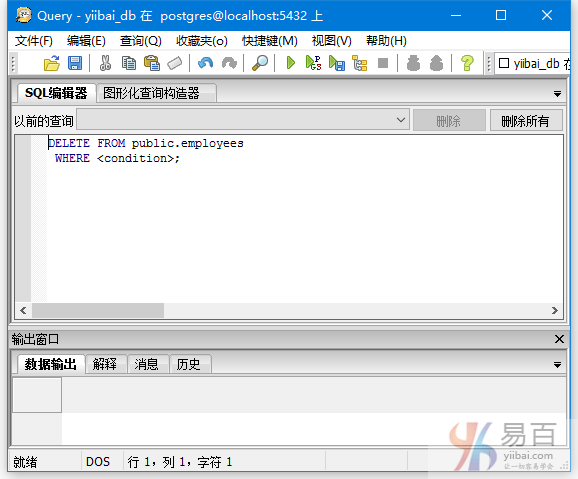
放置要删除的WHERE条件<condition>。
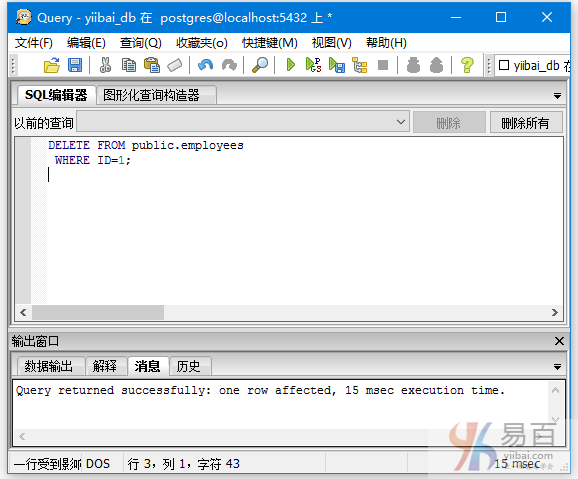
执行一个例子:
从“EMPLOYEES”中删除“ID”为1的记录。执行以下查询语句:
DELETE FROM EMPLOYEES
WHERE ID = 1;
如下图所示 -
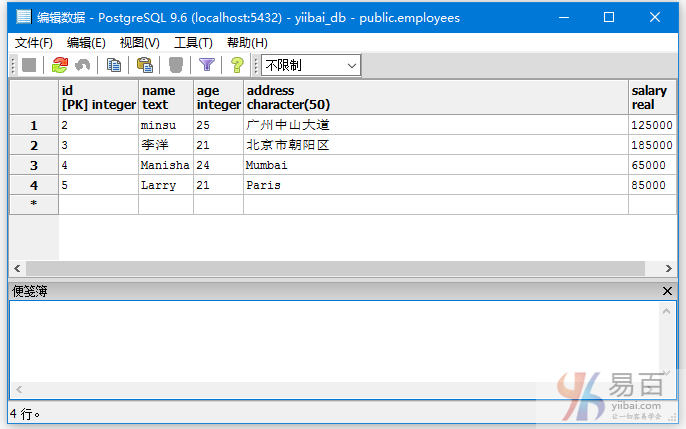
查询EMPLOYEES的数据记录,可以看到ID为1的记录已经被删除了 -
注意:如果不使用“WHERE”条件,整个表中的记录都将被删除。
看下面这个例子:
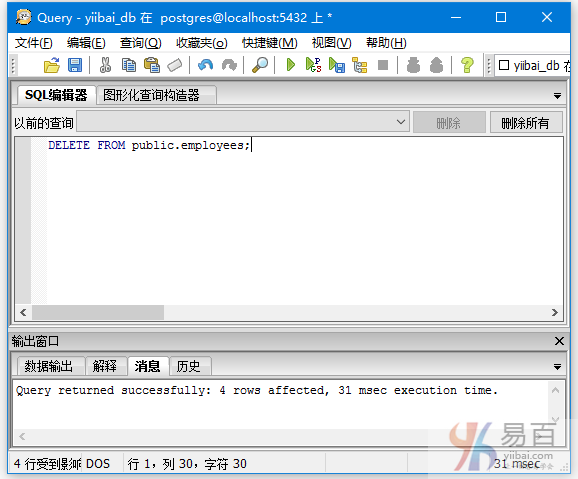
查询EMPLOYEES的数据记录,可以看到所有记录都已经被删除了 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL删除数据(DELETE语句)
PostgreSQL ORDER BY子句 - PostgreSQL教程™
PostgreSQL ORDER BY子句用于按升序或降序对数据进行排序。数据在一列或多列的基础上进行排序。
语法:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
参数说明:
- column_list:它指定要检索的列或计算。
- table_name:它指定要从中检索记录的表。FROM子句中必须至少有一个表。
- WHERE conditions:可选。 它规定必须满足条件才能检索记录。
- ASC:也是可选的。它通过表达式按升序排序结果集(默认,如果没有修饰符是提供者)。
- DESC:也是可选的。 它通过表达式按顺序对结果集进行排序。
看看下面这个例子:
我们来看一下表“EMPLOYEES”,具有以下数据。
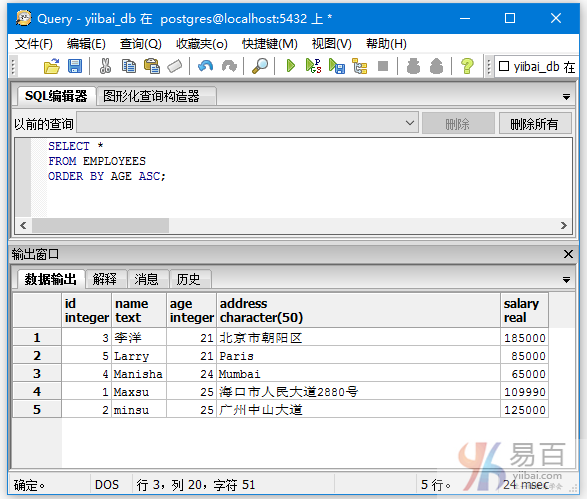
升序排序 - ORDER BY [field] ASC
执行以下查询以按升序ORDER BY AGE数据记录:
SELECT *
FROM EMPLOYEES
ORDER BY AGE ASC;
按照 age 字段升序排序,结果如下 -
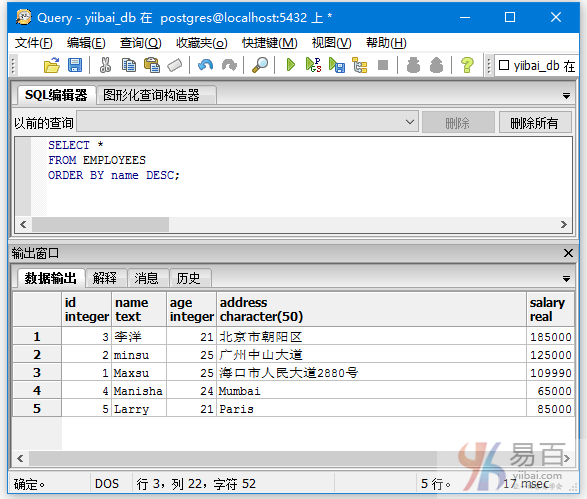
降序排序 - ORDER BY [field] DESC
执行以下查询以按降序ORDER BY name DESC数据的记录:
SELECT *
FROM EMPLOYEES
ORDER BY name DESC;
按照 name 字段降序排序,结果如下 -
多列排序 ORDER BY
您还可以使用ORDER BY子句在多列上排序记录。执行以下查询从表“EMPLOYEES”按ORDER BY NAME和ADDRESS以升序获取记录。
执行结果如下 -
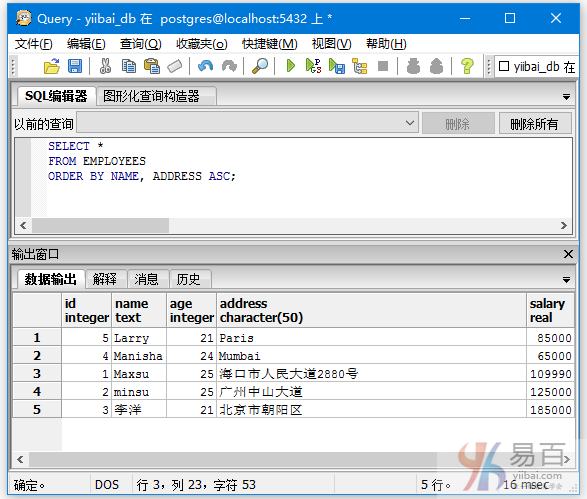
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL ORDER BY子句
PostgreSQL分组(GROUP BY子句) - PostgreSQL教程™
PostgreSQL GROUP BY子句用于将具有相同数据的表中的这些行分组在一起。 它与SELECT语句一起使用。
GROUP BY子句通过多个记录收集数据,并将结果分组到一个或多个列。 它也用于减少输出中的冗余。
语法:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
注意:在GROUP BY多个列的情况下,您使用的任何列进行分组时,要确保这些列应在列表中可用。
看看下面的例子:
我们来看一下表“EMPLOYEES”,具有以下数据。
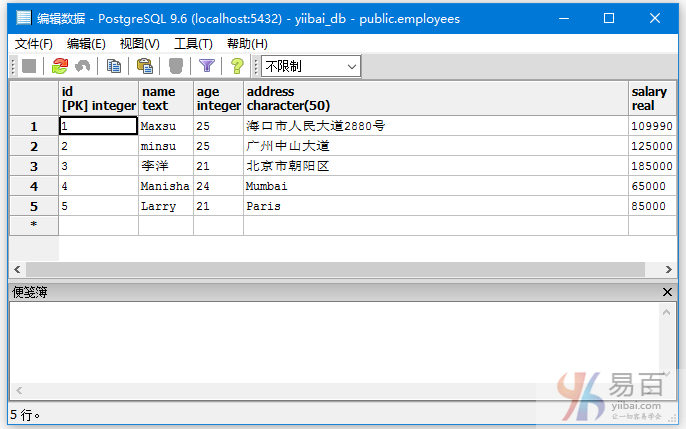
执行以下查询:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
查询得到如下结果 -

如何减少冗余数据:
再来看看下面这个例子:
我们在“EMPLOYEES”表中插入一些重复的记录。添加以下数据:
INSERT INTO EMPLOYEES VALUES (6, '李洋', 24, '深圳市福田区中山路', 135000);
INSERT INTO EMPLOYEES VALUES (7, 'Manisha', 19, 'Noida', 125000);
INSERT INTO EMPLOYEES VALUES (8, 'Larry', 45, 'Texas', 165000);
现在有以下数据,有一些数据是重复的 -
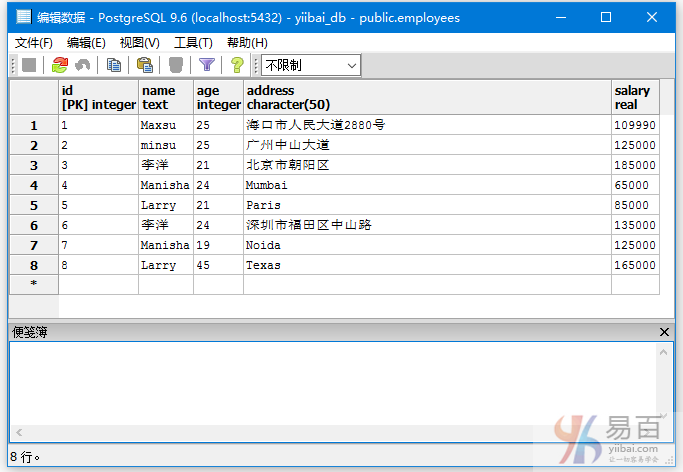
执行以下查询以消除冗余:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
上面的SQL语句是按名字(NAME)执行分组统计每个名字的薪水总额,如:两个名字叫作李洋的薪水总额是:320000等等,得到结果如下 -
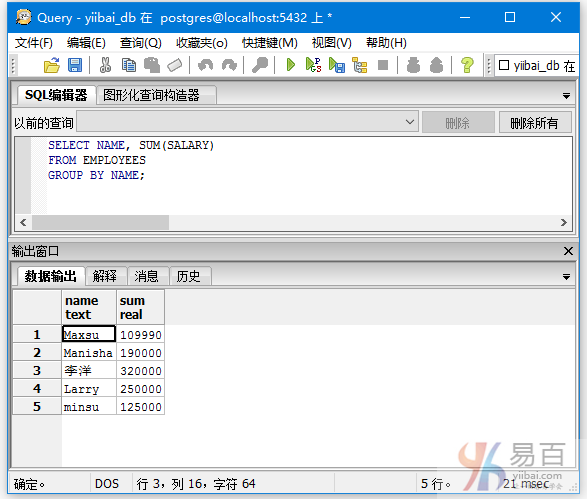
在上面的例子中,当我们使用GROUP BY NAME时,可以看到重复的名字数据记录被合并。 它指定GROUP BY减少冗余。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL分组(GROUP BY子句)
PostgreSQL Having子句 - PostgreSQL教程™
在PostgreSQL中,HAVING子句与GROUP BY子句组合使用,用于选择函数结果满足某些条件的特定行。
语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
示例1:
我们来看一下表“EMPLOYEES”,具有以下数据。
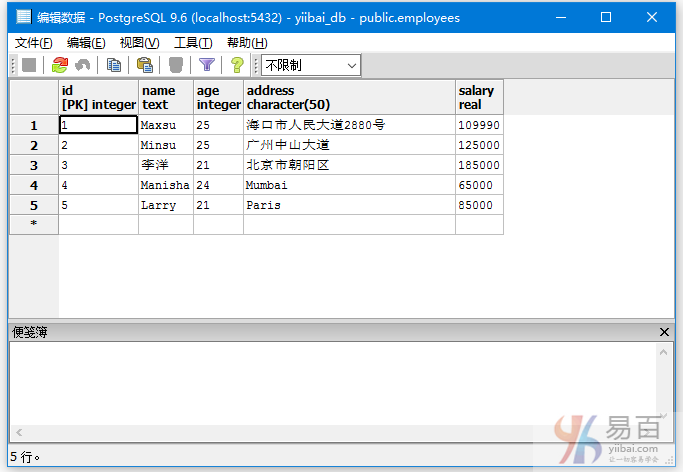
在这个例子中,它将显示名称(name)数量小于2的记录。
执行以下查询:
SELECT NAME
FROM EMPLOYEES
GROUP BY NAME HAVING COUNT (NAME) < 2;
得到结果如下 -
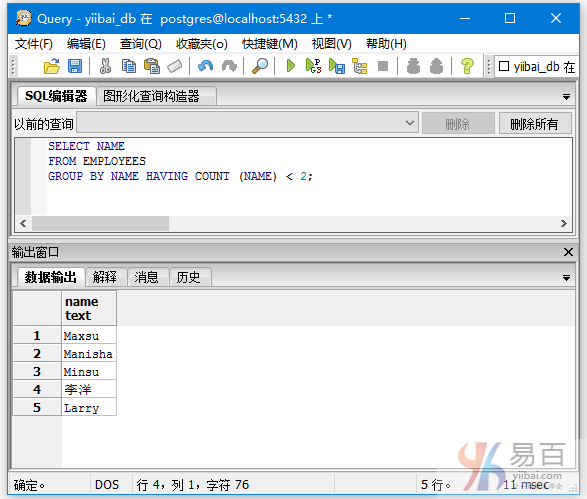
示例2:
我们在“EMPLOYEES”表中插入一些重复的记录,首先添加以下数据:
INSERT INTO EMPLOYEES VALUES (7, 'Minsu', 24, 'Delhi', 135000);
INSERT INTO EMPLOYEES VALUES (8, 'Manisha', 19, 'Noida', 125000);
现在完整的数据如下所示 -
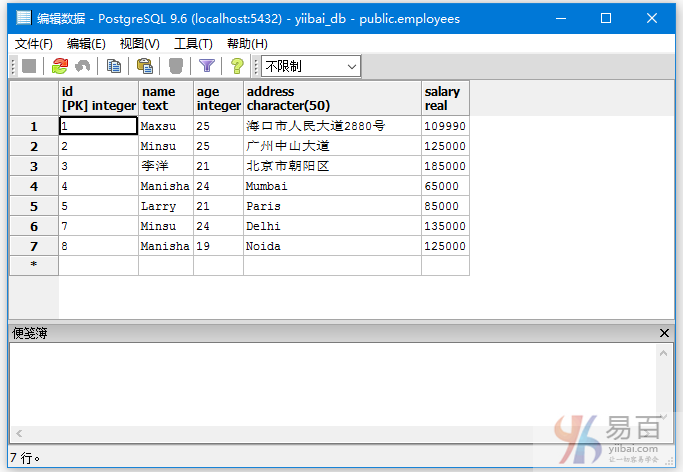
执行以下查询表“EMPLOYEES”中name字段值计数大于1的名称。
SELECT NAME,COUNT (NAME)
FROM EMPLOYEES
GROUP BY NAME HAVING COUNT (NAME) > 1;
得到结果如下 -
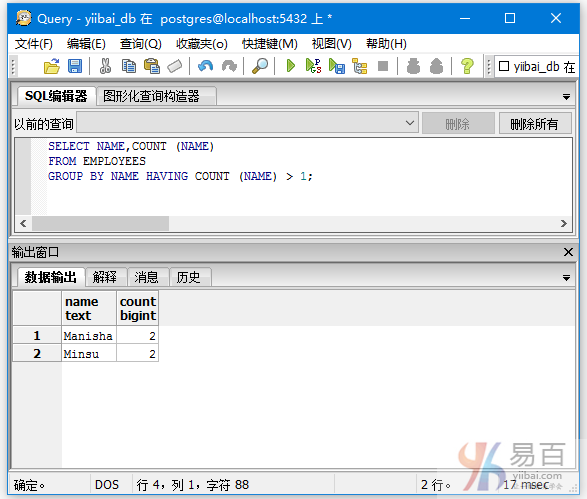
这是因为名字为 Minsu和 Manisha 有两条记录。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL Having子句
PostgreSQL条件查询 - PostgreSQL教程™
PostgreSQL条件用于从数据库获取更具体的结果。 它们通常与WHERE子句一起使用。 具有子句的条件就像双层过滤器。
以下是PostgreSQL条件的列表:
- AND 条件
- OR 条件
- AND & OR 条件
- NOT 条件
- LIKE 条件
- IN 条件
- NOT IN 条件
- BETWEEN 条件
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL条件查询
PostgreSQL AND条件 - PostgreSQL教程™
PostgreSQL AND条件与WHERE子句一起使用,以从表中的多个列中选择唯一的数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
AND [search_condition];
现在来看看 employees 表中的所有数据 -
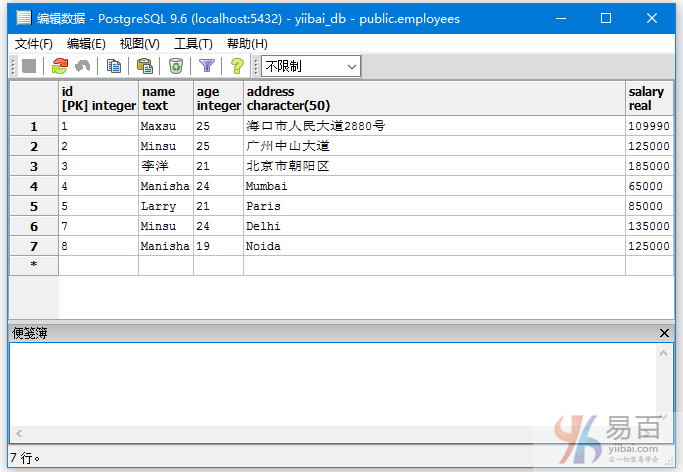
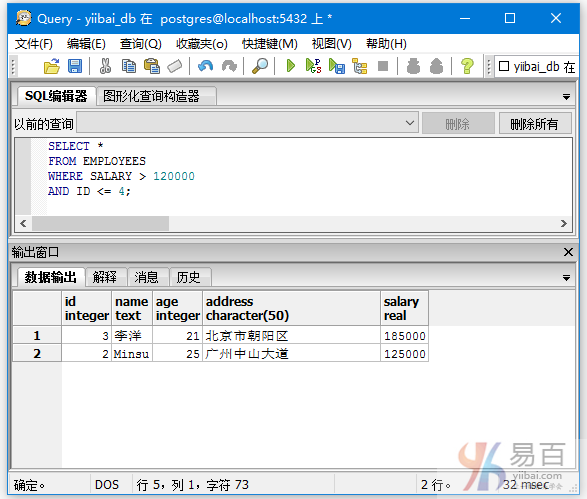
下面来查询所有ID小于4并且薪水大于120000的员工数据信息,执行以下查询语句:
SELECT *
FROM EMPLOYEES
WHERE SALARY > 120000
AND ID <= 4;
执行结果如下 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL AND条件
PostgreSQL OR条件 - PostgreSQL教程™
PostgreSQL OR条件与WHERE子句一起使用,以从表中的一列或多列列中选择唯一数据。
语法
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
OR [search_condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
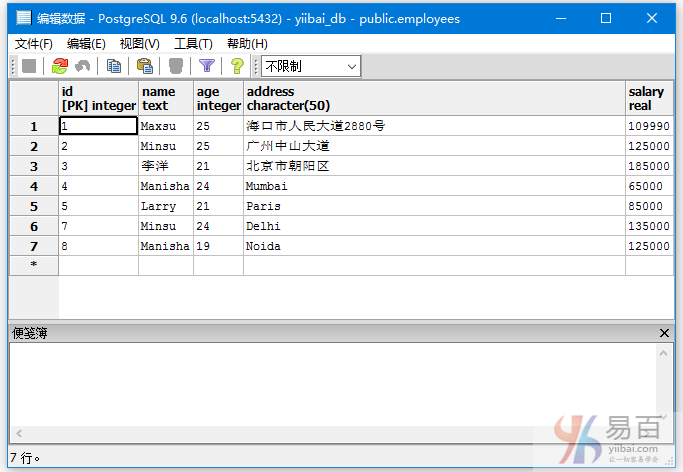
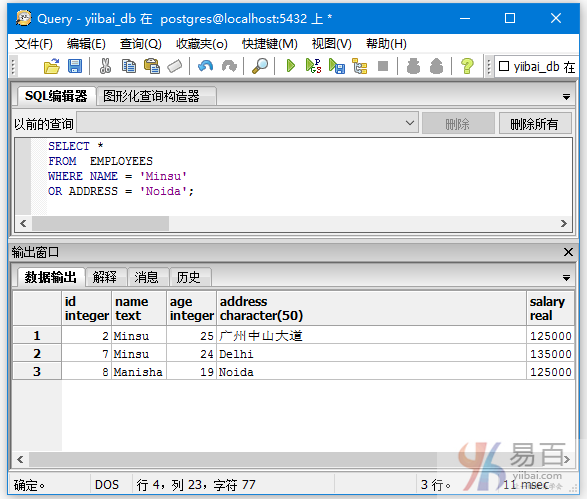
查询名字是Minsu或者地址为Noida员工信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE NAME = 'Minsu'
OR ADDRESS = 'Noida';
得到以下输出结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL OR条件
PostgreSQL OR条件 - PostgreSQL教程™
PostgreSQL OR条件与WHERE子句一起使用,以从表中的一列或多列列中选择唯一数据。
语法
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
OR [search_condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
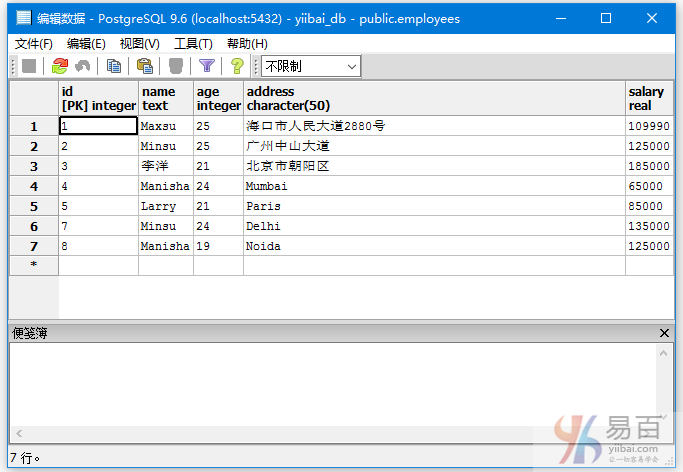
查询名字是Minsu或者地址为Noida员工信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE NAME = 'Minsu'
OR ADDRESS = 'Noida';
得到以下输出结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL OR条件
PostgreSQL AND & OR条件 - PostgreSQL教程™
PostgreSQL AND&OR条件在仅一个查询中提供了AND和OR条件的优点。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] AND [search_condition]
OR [search_condition];
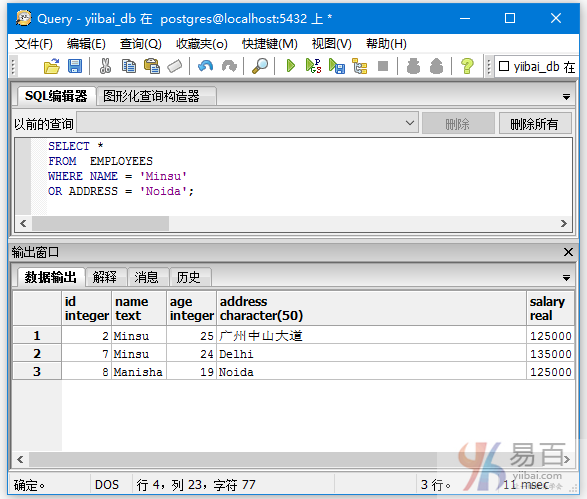
我们来看一下表“EMPLOYEES”,具有以下数据。

查询名字的值为Minsu和地址的值为’Delhi‘,或者ID值大于等8的记录信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE (NAME = 'Minsu' AND ADDRESS = 'Delhi')
OR (ID>= 8);
得到以下结果 -
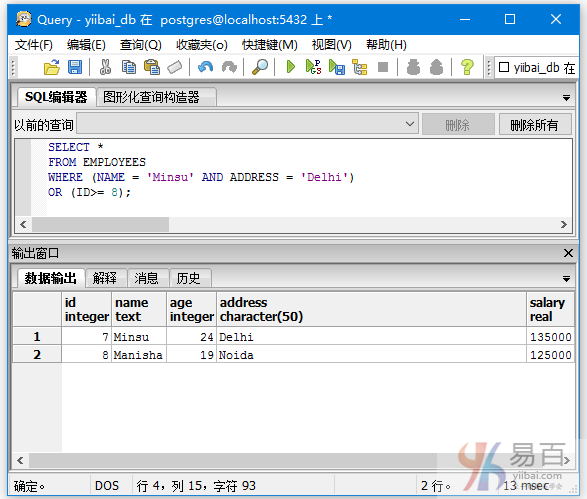
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL AND & OR条件
PostgreSQL NOT条件 - PostgreSQL教程™
PostgreSQL NOT条件与WHERE子句一起使用以否定查询中的条件。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT [condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
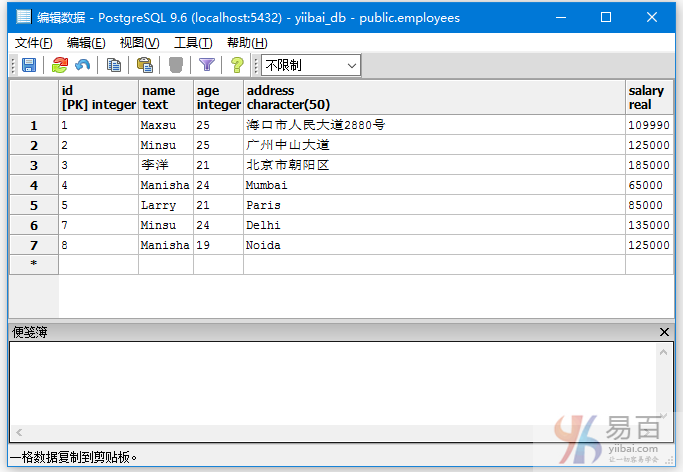
查询那些地址不为NULL的记录信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE address IS NOT NULL ;
得到以下结果 -
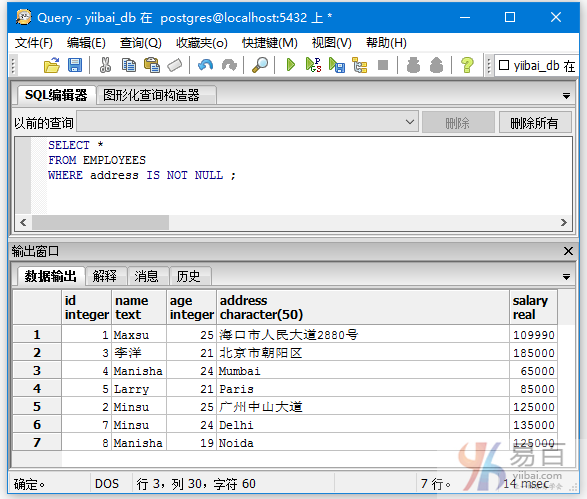
再来看另外一个示例,查询那些年龄不是21和24的所有记录,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE age NOT IN(21,24) ;
得到以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL NOT条件
PostgreSQL LIKE条件 - PostgreSQL教程™
PostgreSQL LIKE条件与WHERE子句一起用于从指定条件满足LIKE条件的表中获取数据。
语法
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] LIKE [condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
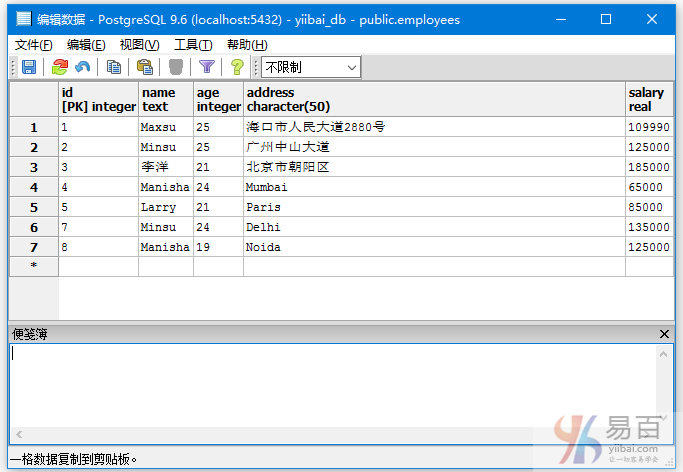
示例1
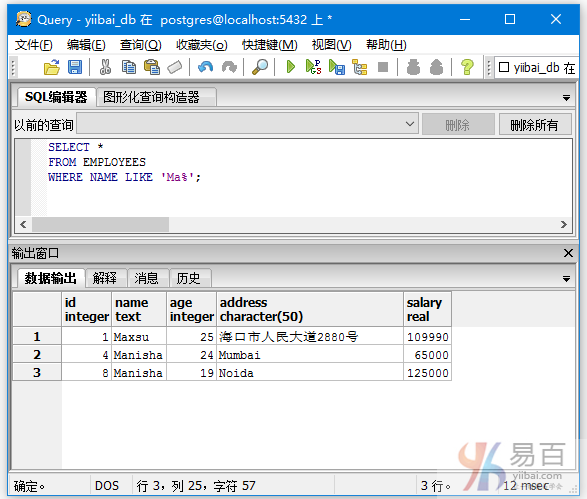
查询名字以Ma开头的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE 'Ma%';
执行后输出以下结果 -
示例2
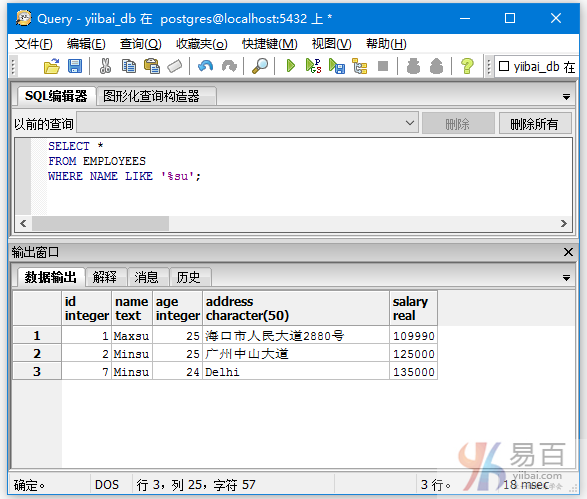
查询名字以su结尾的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE '%su';
执行后输出以下结果 -
示例3
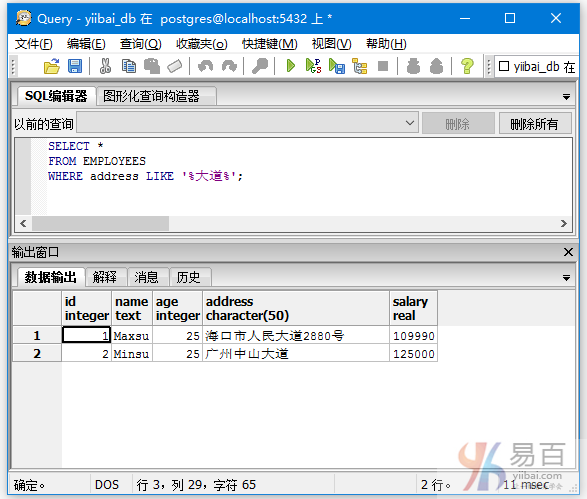
查询地址中含有大道的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE address LIKE '%大道%';
执行后输出以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL LIKE条件
PostgreSQL IN条件 - PostgreSQL教程™
PostgreSQL IN条件与WHERE子句一起使用,从指定条件满足IN条件的表中获取数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] IN [condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
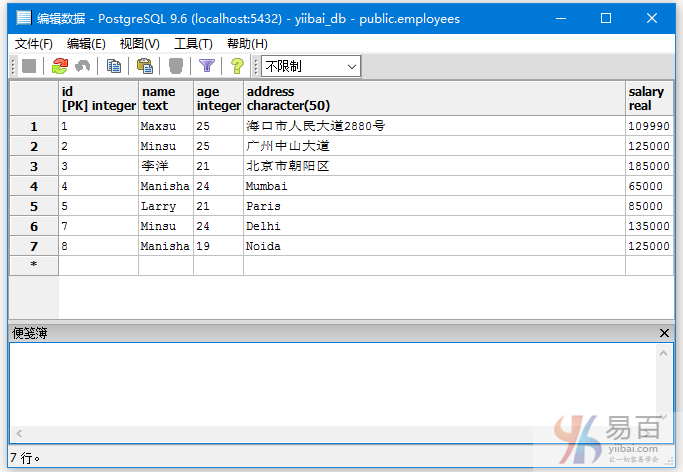
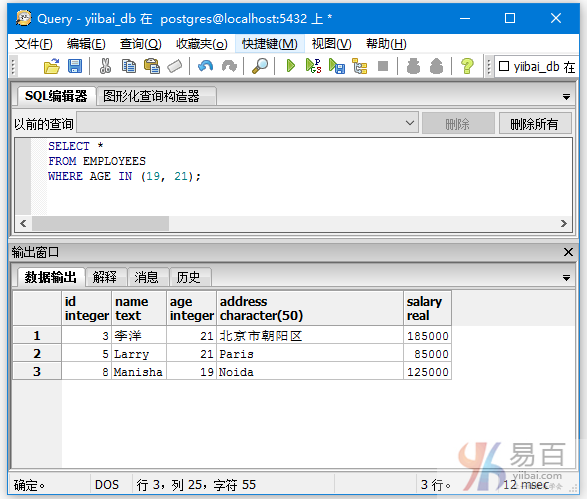
查询employee表中那些年龄为19,21的员工信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE AGE IN (19, 21);
执行上面查询语句,得到以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL IN条件
PostgreSQL NOT IN条件 - PostgreSQL教程™
PostgreSQL NOT IN条件与WHERE子句一起使用,以从指定条件否定IN条件的表中获取数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT IN [condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
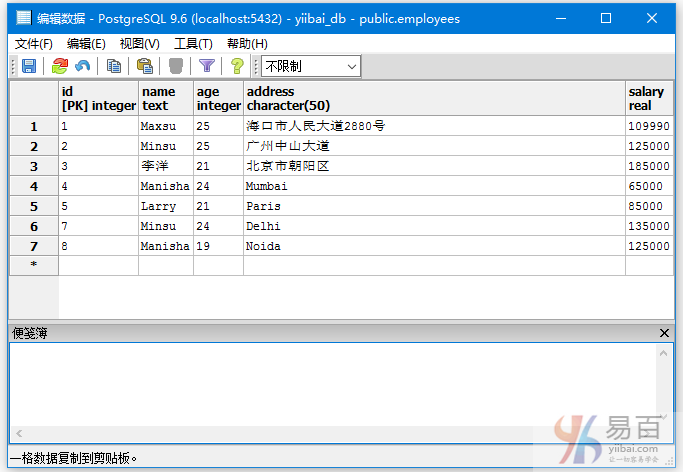
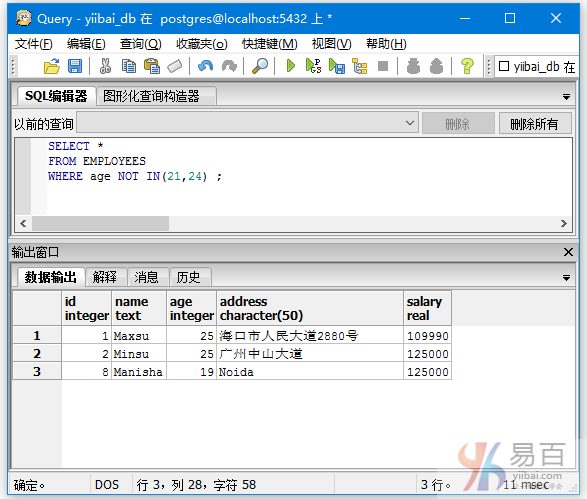
查询那些年龄不是19,25的数据,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE AGE NOT IN (19, 25);
执行上面查询语句,得到以下结果 -
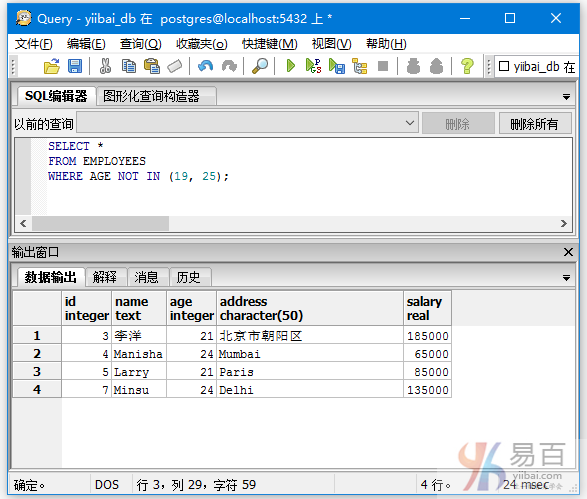
再来看看另外一个例子,查询那些名字不是Minsu,Maxsu的数据信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE name NOT IN ('Maxsu', 'Minsu');
执行上面查询语句,得到以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL NOT IN条件
PostgreSQL BETWEEN条件 - PostgreSQL教程™
PostgreSQL BETWEEN条件与WHERE子句一起使用,以从两个指定条件之间的表中获取数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] BETWEEN [condition];
我们来看一下表“EMPLOYEES”,具有以下数据。
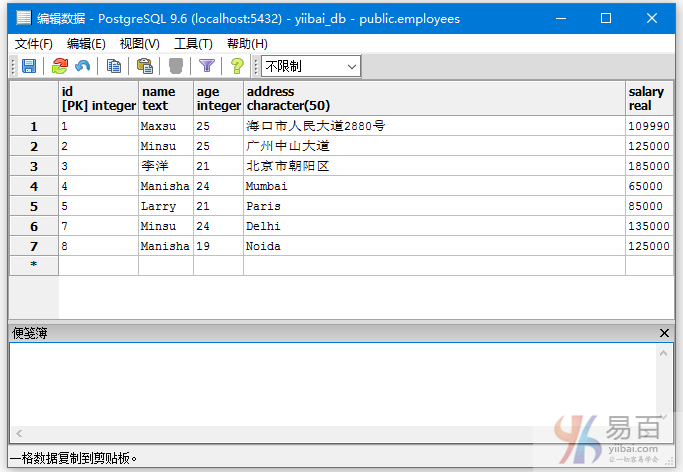
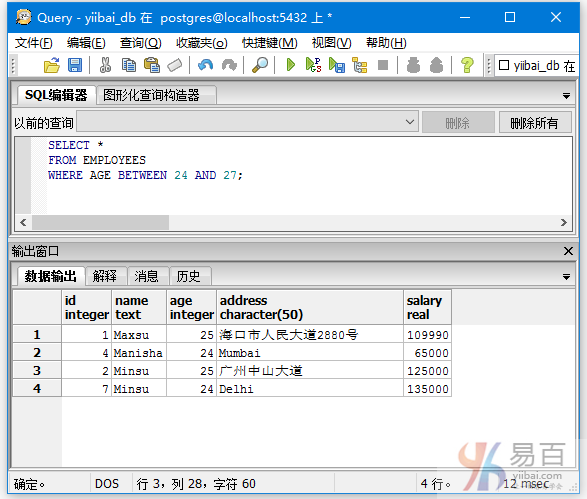
查询employees表中年龄在24~27之间(含24,27)的数据信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE AGE BETWEEN 24 AND 27;
输出结果如下 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL BETWEEN条件
PostgreSQL连接(内连接) - PostgreSQL教程™
在PostgreSQL中,有以下类型的连接:
- 内连接(INNER JOIN)
- 左外连接(LEFT OUTER JOIN)
- 右外连接(RIGHT OUTER JOIN)
- 全连接(FULL OUTER JOIN)
- 跨连接(CROSS JOIN)
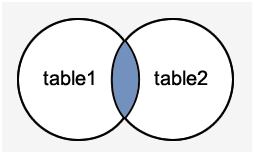
PostgreSQL INNER JOIN
PostgreSQL内部连接也被称为连接或简单连接。 这是最常见的连接类型。 此连接返回满足连接条件的多个表中的所有行。
如下图表示 -
语法:
SELECT table1.columns, table2.columns
FROM table1
INNER JOIN table2
ON table1.common_filed = table2.common_field;
PostgreSQL INNER JOIN示例
表1: EMPLOYEES有以下数据 -

表2: DEPARTMENT有以下数据 -
创建另一个表“DEPARTMENT”并插入以下值。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
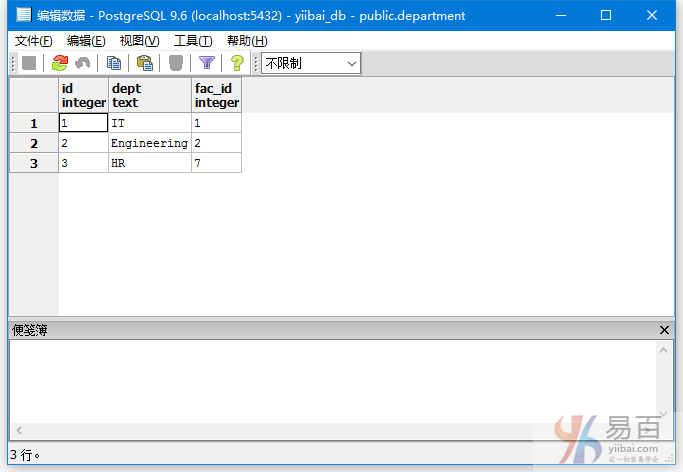
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
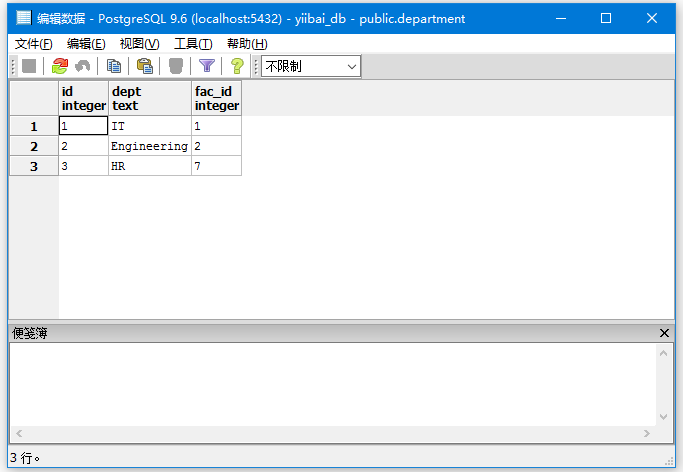
现在 department 表的数据如下 -
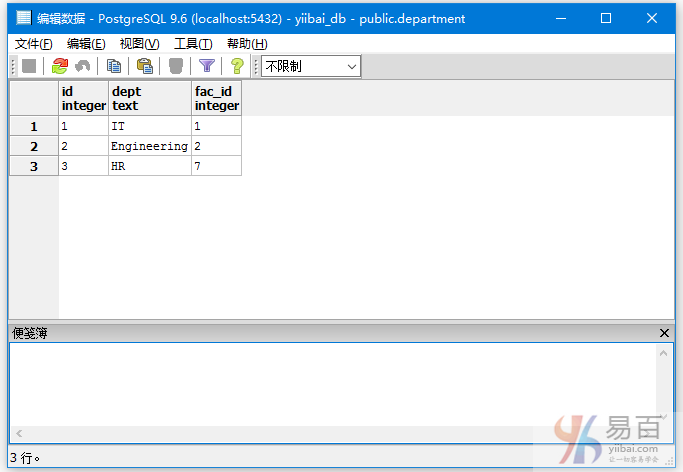
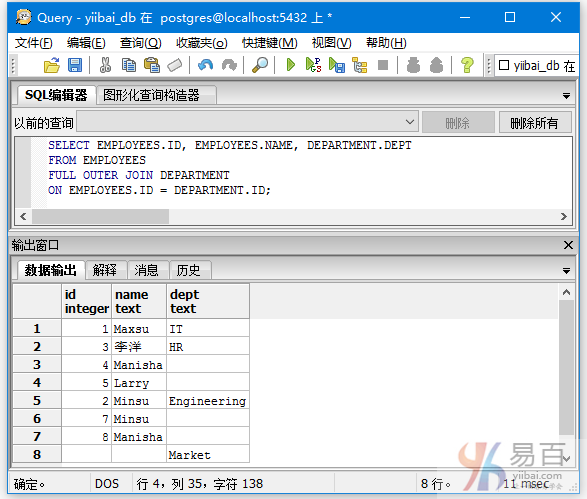
执行以下查询内连接两个表:
SELECT EMPLOYEES.ID, EMPLOYEES.NAME, DEPARTMENT.DEPT
FROM EMPLOYEES
INNER JOIN DEPARTMENT
ON EMPLOYEES.ID = DEPARTMENT.ID;
执行上面查询语句,得到以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL连接(内连接)
PostgreSQL左外连接 - PostgreSQL教程™
外连接是内联的延伸,外连接有三种类型。它们分别如下 -
- 左外连接
- 右外连接
- 全外连接
左外连接
左外连接返回从“ON”条件中指定的左侧表中的所有行,只返回满足条件的另一个表中的行。
如下图中所表示:
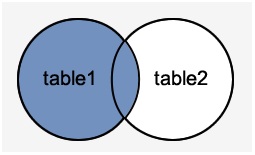
语法:
SELECT table1.columns, table2.columns
FROM table1
LEFT OUTER JOIN table2
ON table1.common_filed = table2.common_field;
示例
看这个例子,现在看看下面一个表1 - “EMPLOYEES”,具有以下数据。

表2: DEPARTMENT
创建另一个表“DEPARTMENT”并插入以下值。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
现在,DEPARTMENT有以下数据 -
执行以下左连接查询:
SELECT EMPLOYEES.ID, EMPLOYEES.NAME, DEPARTMENT.DEPT
FROM EMPLOYEES
LEFT OUTER JOIN DEPARTMENT
ON EMPLOYEES.ID = DEPARTMENT.ID;
得到以下结果 -
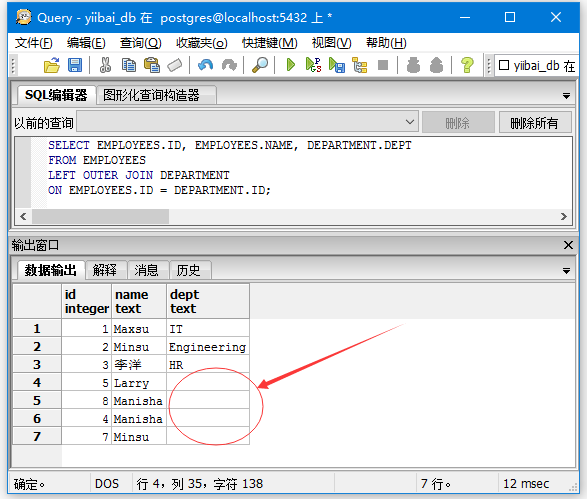
从上面图中可以看到,左表(EMPLOYEES)全部列出来,而右表(DEPARTMENT)没有匹配上的项全留为空值。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL左外连接
PostgreSQL右外连接 - PostgreSQL教程™
外连接是内联的延伸,外连接有三种类型。它们分别如下 -
- 左外连接
- 右外连接
- 全外连接
右外连接
右外连接返回从“ON”条件中指定的右侧表中的所有行,只返回满足条件的另一个表中的行。
如下图中所表示:
语法:
SELECT table1.columns, table2.columns
FROM table1
RIGHT OUTER JOIN table2
ON table1.common_filed = table2.common_field;
如下图所示(蓝色部分) -
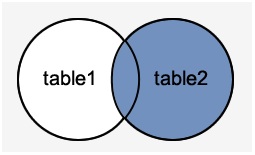
示例
看这个例子,现在看看下面一个表1 - “EMPLOYEES”,具有以下数据。
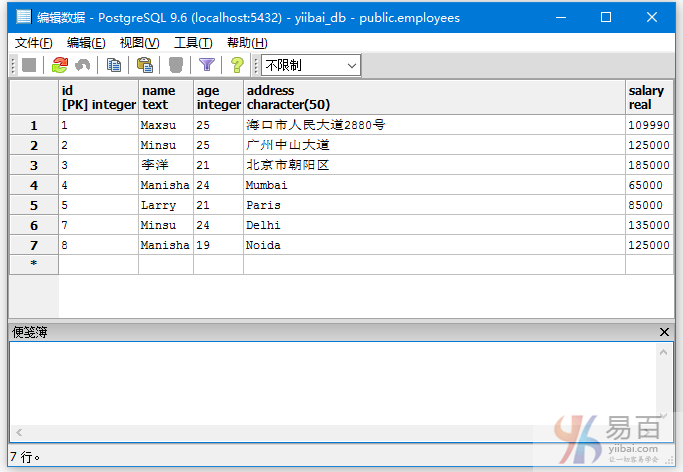
表2: DEPARTMENT
创建另一个表“DEPARTMENT”并插入以下值。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
INSERT INTO department VALUES(10,'Market', 10);
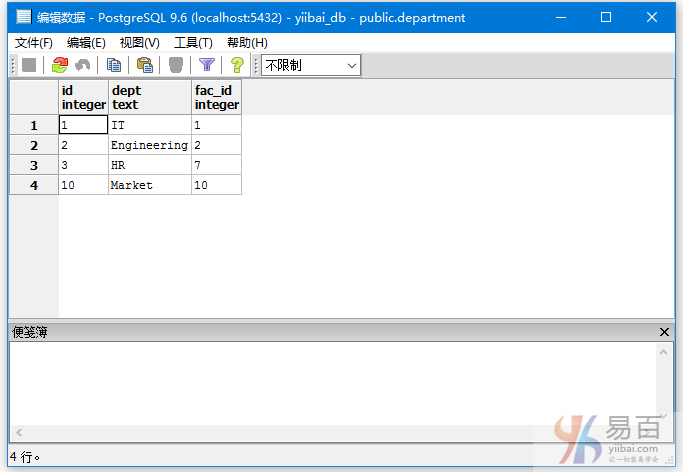
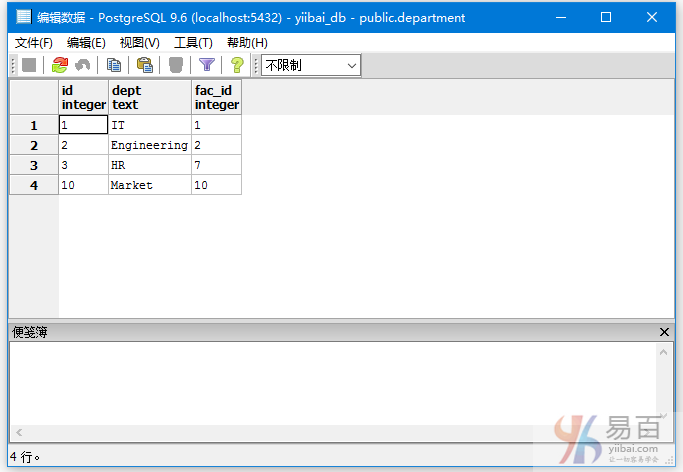
现在,DEPARTMENT有以下数据 -
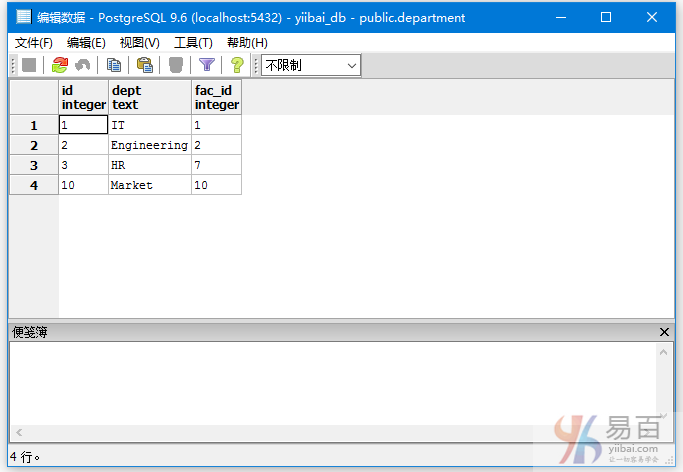
执行以下左连接查询:
SELECT EMPLOYEES.ID, EMPLOYEES.NAME, DEPARTMENT.DEPT
FROM EMPLOYEES
RIGHT OUTER JOIN DEPARTMENT
ON EMPLOYEES.ID = DEPARTMENT.ID;
得到以下结果 -
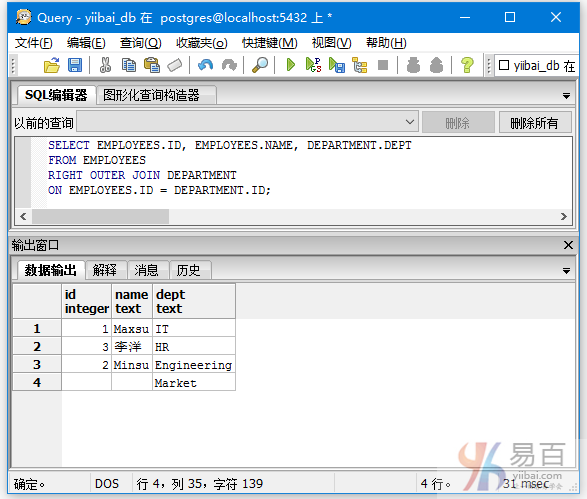
从上面图中可以看到,右表(DEPARTMENT)全部列出来,而左表(EMPLOYEES)没有匹配上的项全留为空值。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL右外连接
PostgreSQL全外连接 - PostgreSQL教程™
外连接是内联的延伸,外连接有三种类型。它们分别如下 -
- 左外连接
- 右外连接
- 全外连接
全外连接
FULL外连接从LEFT手表和RIGHT表中返回所有行。 它将NULL置于不满足连接条件的位置。
语法:
SELECT table1.columns, table2.columns
FROM table1
FULL OUTER JOIN table2
ON table1.common_filed = table2.common_field;
如下图所示(蓝色部分) -
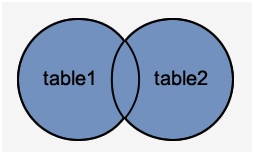
示例
看这个例子,现在看看下面一个表1 - “EMPLOYEES”,具有以下数据。

表2: DEPARTMENT
创建另一个表“DEPARTMENT”并插入以下值。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
INSERT INTO department VALUES(10,'Market', 10);
现在,DEPARTMENT有以下数据 -
执行以下左连接查询:
SELECT EMPLOYEES.ID, EMPLOYEES.NAME, DEPARTMENT.DEPT
FROM EMPLOYEES
FULL OUTER JOIN DEPARTMENT
ON EMPLOYEES.ID = DEPARTMENT.ID;
得到以下结果 -
从上面图中可以看到,左表(EMPLOYEES)和右表(DEPARTMENT)没有匹配上的项全留为空值。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL全外连接
PostgreSQL跨连接(CROSS JOIN) - PostgreSQL教程™
PostgreSQL跨连接(CROSS JOIN)将第一个表的每一行与第二个表的每一行相匹配。 它也被称为笛卡儿积分。 如果table1具有“x”列,而table2具有“y”列,则所得到的表将具有(x + y)列。
语法:
SELECT coloums
FROM table1
CROSS JOIN table2
例子:
我们来看一下表“EMPLOYEES”,具有以下数据。
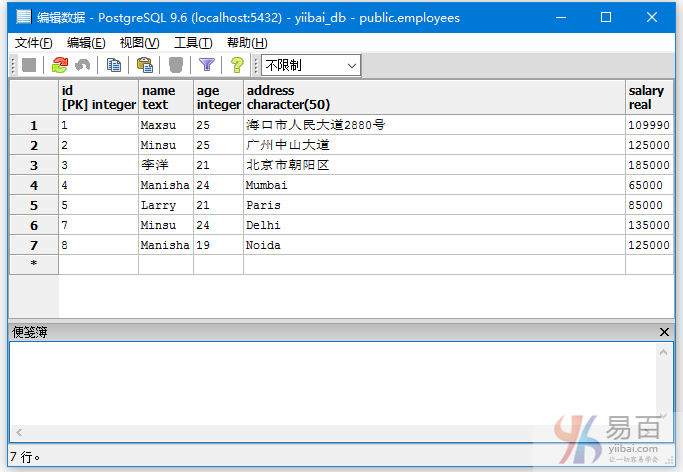
表2: DEPARTMENT
创建另一个表“DEPARTMENT”并插入以下值。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
INSERT INTO department VALUES(10,'Market', 10);
现在,DEPARTMENT有以下数据 -
执行以下跨连接查询:
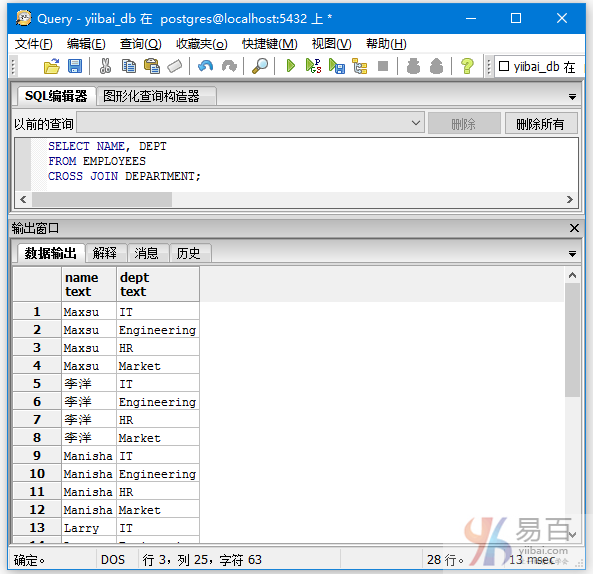
SELECT NAME, DEPT
FROM EMPLOYEES
CROSS JOIN DEPARTMENT;
得到以下结果 -
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL跨连接(CROSS JOIN)
PostgreSQL视图 - PostgreSQL教程™
在PostgreSQL中,视图(VIEW)是一个伪表。 它不是物理表,而是作为普通表选择查询。
视图也可以表示连接的表。 它可以包含表的所有行或来自一个或多个表的所选行。
视图便于用户执行以下操作:
- 它以自然和直观的方式构建数据,并使其易于查找。
- 它限制对数据的访问,使得用户只能看到有限的数据而不是完整的数据。
- 它归总来自各种表中的数据以生成报告。
PostgreSQL创建视图
可以使用CREATE VIEW语句来在PostgreSQL中创建视图。 您可以从单个表,多个表以及另一个视图创建它。
语法
CREATE [TEMP | TEMPORARY] VIEW view_name AS
SELECT column1, column2.....
FROM table_name
WHERE [condition];
PostgreSQL创建视图示例
考虑一个表“EMPLOYEES”,具有以下数据。
现在,我们从“EMPLOYEES”表创建一个视图。 此视图将仅包含EMPLOYEES表中的几个列:
执行以下查询语句:
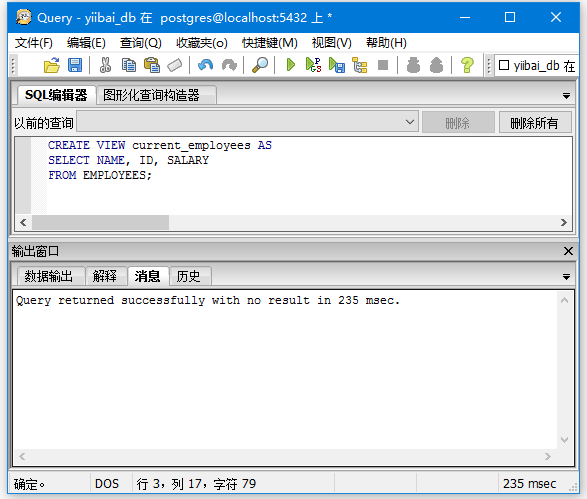
CREATE VIEW current_employees AS
SELECT NAME, ID, SALARY
FROM EMPLOYEES;
执行结果如下 -
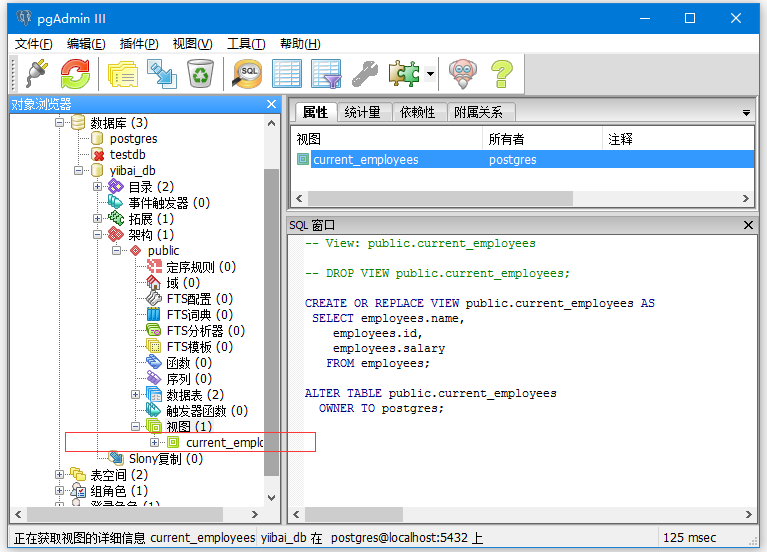
找出上面创建的视图,如下可以看到:
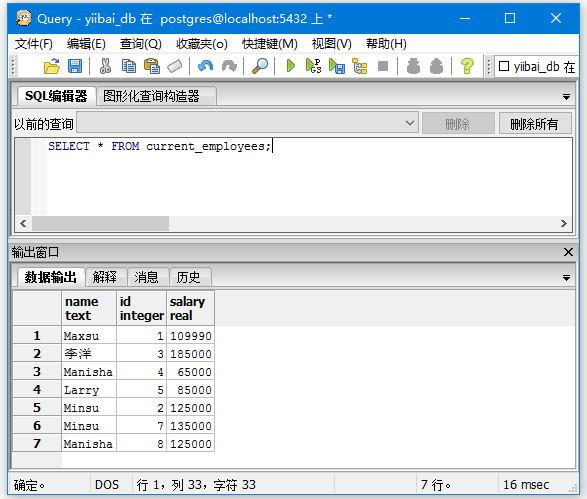
现在,您可以从视图“current_employees”中使用简单的查询语句检索数据。会看到下表:
SELECT * FROM current_employees;
执行上面的查询语句,得到以下结果 -
PostgreSQL DROP视图
按着下面这些次序操作删除就好了:
- 选择视图“current_employees”并右键点击。
- 您将看到一个删除/移除选项,点击它。
视图是永久删除的。所以一但删除了以后,在数据库中就不会存在了。
您还可以使用DROP VIEW命令删除或删除视图。
语法
DROP VIEW view_name;
要删除上面的例子中创建的视图,可执行以下SQL语句:
DROP VIEW current_employees;
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL视图
PostgreSQL函数(存储过程) - PostgreSQL教程™
PostgreSQL函数也称为PostgreSQL存储过程。 PostgreSQL函数或存储过程是存储在数据库服务器上并可以使用SQL界面调用的一组SQL和过程语句(声明,分配,循环,控制流程等)。 它有助于您执行通常在数据库中的单个函数中进行多次查询和往返操作的操作。
您可以在许多语言(如SQL,PL/pgSQL,C,Python等)中创建PostgreSQL函数。
语法:
CREATE [OR REPLACE] FUNCTION function_name (arguments)
RETURNS return_datatype AS $variable_name$
DECLARE
declaration;
[...]
BEGIN
< function_body >
[...]
RETURN { variable_name | value }
END; LANGUAGE plpgsql;
参数说明
- function_name:指定函数的名称。
- [OR REPLACE]:是可选的,它允许您修改/替换现有函数。
- RETURN:它指定要从函数返回的数据类型。它可以是基础,复合或域类型,或者也可以引用表列的类型。
- function_body:function_body包含可执行部分。
- plpgsql:它指定实现该函数的语言的名称。
例子:
下面我们来举个例子来演示PostgreSQL函数使用,我们有一个名为“EMPLOYEES”的表具有以下数据。
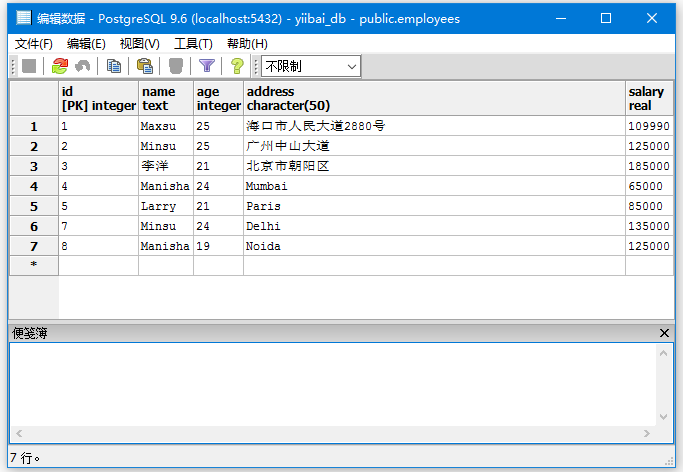
在EMPLOYEES表上创建一个名为total records()的函数。
函数的定义如下:
CREATE OR REPLACE FUNCTION totalRecords ()
RETURNS integer AS $total$
declare
total integer;
BEGIN
SELECT count(*) into total FROM EMPLOYEES;
RETURN total;
END;
$total$ LANGUAGE plpgsql;
输出:
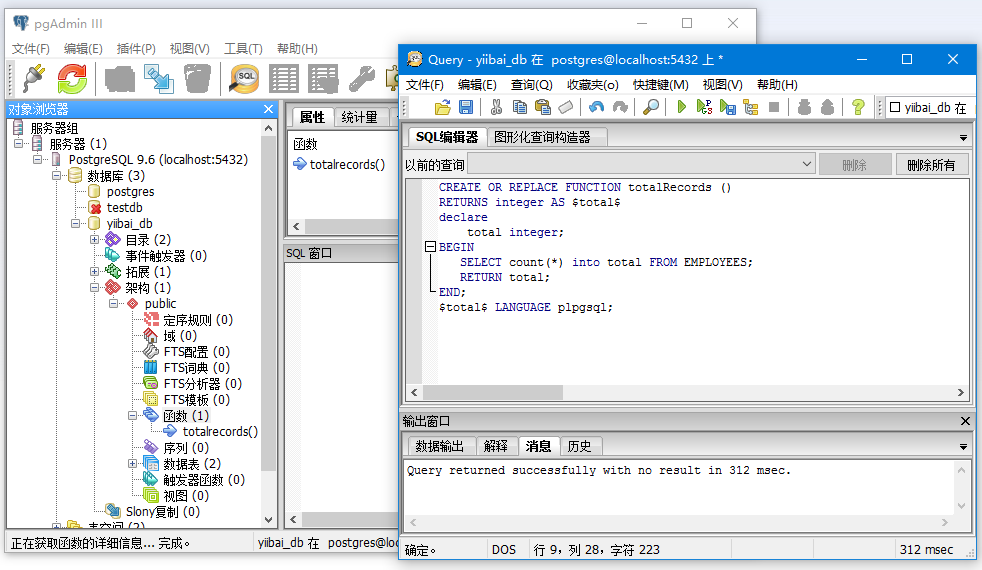
您可以看到一个名为“totalrecords”的函数被创建。现在,来执行一个调用这个函数并检查EMPLOYEES表中的记录,如下所示 -
select totalRecords();
当执行上述查询时,结果为:
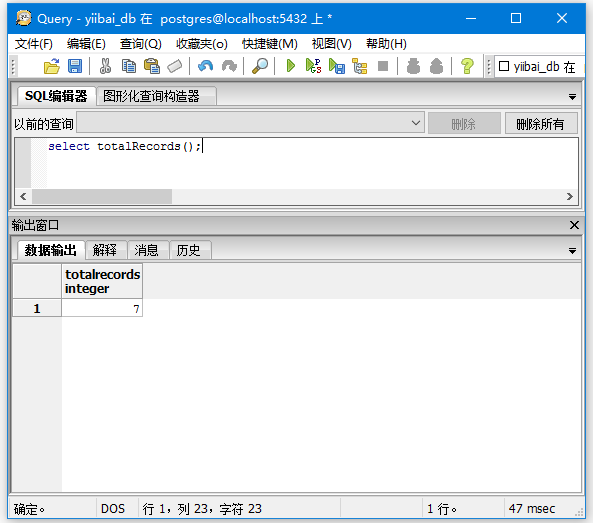
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL函数(存储过程)
PostgreSQL触发器 - PostgreSQL教程™
PostgreSQL触发器是一组动作或数据库回调函数,它们在指定的表上执行指定的数据库事件(即,INSERT,UPDATE,DELETE或TRUNCATE语句)时自动运行。 触发器用于验证输入数据,执行业务规则,保持审计跟踪等。
触发器的重点知识
- PostgreSQL在以下情况下执行/调用触发器:在尝试操作之前(在检查约束并尝试INSERT,UPDATE或DELETE之前)。或者在操作完成后(在检查约束并且INSERT,UPDATE或DELETE完成后)。或者不是操作(在视图中INSERT,UPDATE或DELETE的情况下)
- 对于操作修改的每一行,都会调用一个标记为FOR EACH ROWS的触发器。 另一方面,标记为FOR EACH STATEMENT的触发器只对任何给定的操作执行一次,而不管它修改多少行。
- 您可以为同一事件定义同一类型的多个触发器,但条件是按名称按字母顺序触发。
- 当与它们相关联的表被删除时,触发器被自动删除。
PostgreSQL创建触发器
CREATE TRIGGER语句用于在PostgreSQL表中创建一个新的触发器。 当表发生特定事件(即INSERT,UPDATE和DELETE)时,它被激活。
语法
CREATE TRIGGER trigger_name [BEFORE|AFTER|INSTEAD OF] event_name
ON table_name
[
-- Trigger logic goes here....
];
在这里,event_name可以是INSERT,UPDATE,DELETE和TRUNCATE数据库操作上提到的表table_name。 您可以选择在表名后指定FOR EACH ROW。
下面来看看看如何在INSERT操作中创建触发器的语法。
CREATE TRIGGER trigger_name AFTER INSERT ON column_name
ON table_name
[
-- Trigger logic goes here....
];
触发器例子
下面举个例子来演示PostgreSQL在INSERT语句之后创建触发器。在以下示例中,我们对每个记录插入到COMPANY表中进行审核(审计)。
使用以下查询创建一个名为COMPANY的表:
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
为了保存审计/审核,我们将创建一个名为AUDIT的新表,只要在COMPANY表中有一个新记录的条目,就会插入日志消息。
使用以下查询语句创建另一个表Audit:
CREATE TABLE AUDIT(
EMP_ID INT NOT NULL,
ENTRY_DATE TEXT NOT NULL
);
在COMPANY表上创建触发器之前,首先创建一个名为auditlogfunc()的函数/过程。
执行以下查询语句来创建函数/过程:
CREATE OR REPLACE FUNCTION auditlogfunc() RETURNS TRIGGER AS $example_table$
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$example_table$ LANGUAGE plpgsql;
执行结果如下所示-
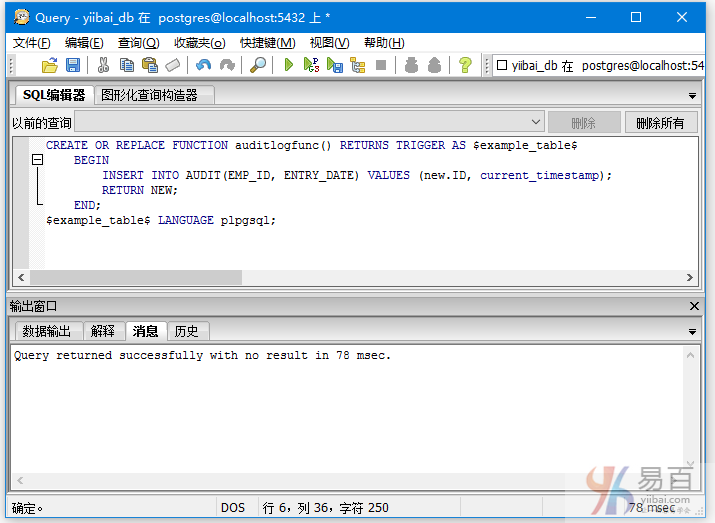
现在通过使用以下查询语句在COMPANY表上创建一个触发器:
CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY
FOR EACH ROW EXECUTE PROCEDURE auditlogfunc();
执行结果如下所示-
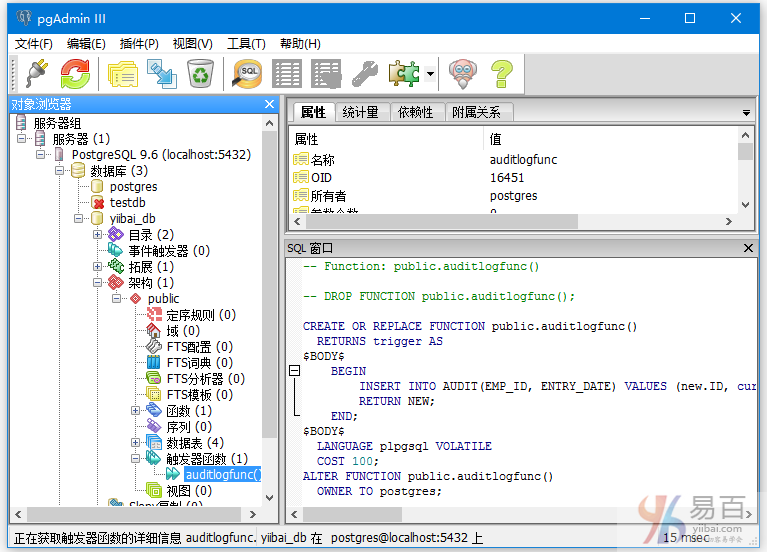
向COMPANY表中插入一些数据记录,以验证触发器执行情况。
INSERT INTO COMPANY VALUES(1, '小米科技', 8, '北京市朝阳区', 9999);
INSERT INTO COMPANY VALUES(2, '京东中科', 6, '广州市天河区', 8999);
在执行上面两条插入语句后,现我们来看AUDIT表是否有自动插入两条审核记录。
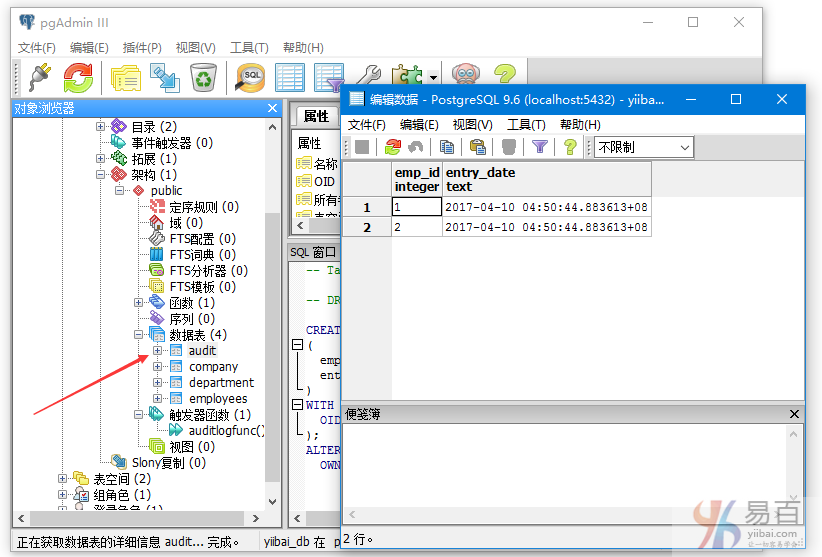
可以确定的是在插入数据后触发了触发器,PostgreSQL也自动向AUDIT表中创建/插入两个记录。 这些记录是触发的结果,这是因为我们在AFTER INSERT on COMPANY表上创建了这些记录。
PostgreSQL触发器的使用
PostgreSQL触发器可用于以下目的:
- 验证输入数据。
- 执行业务规则。
- 为不同文件中新插入的行生成唯一值。
- 写入其他文件以进行审计跟踪。
- 从其他文件查询交叉引用目的。
- 访问系统函数。
- 将数据复制到不同的文件以实现数据一致性。
使用触发器的优点
- 它提高了应用程序的开发速度。 因为数据库存储触发器,所以您不必将触发器操作编码到每个数据库应用程序中。
- 全局执法业务规则。定义触发器一次,然后将其重用于使用数据库的任何应用程序。
- 更容易维护 如果业务策略发生变化,则只需更改相应的触发程序,而不是每个应用程序。
- 提高客户/服务器环境的性能。 所有规则在结果返回之前在服务器中运行。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL触发器
PostgreSQL别名 - PostgreSQL教程™
PostgreSQL别名(Alias)用于为列或表提供临时名称。您可以使用PostgreSQL别名为列或表创建一个临时名称。
通常来说,当您执行自联接时,会创建一个临时表。
PostgreSQL列别名
语法:
SELECT column_name AS alias_name
FROM table_name
conditions... ;
参数说明
- column_name: 它指定要进行别名的列的原始名称。
- alias_name: 它指定分配给列的临时名称。
- table_name:它指定表的名称。
- AS:这是可选的。大多数程序员将在对列名进行别名时指定AS关键字,但在别名表名时不指定。
注意:
- 如果alias_name包含空格,则必须将alias_name包含在引号中。
- 在别名列名时,可以使用空格。 但是使用表名时,使用空格通常不是一个好习惯。
- alias_name仅在SQL语句的范围内有效。
示例-1
我们来看一下表“EMPLOYEES”,具有以下数据。
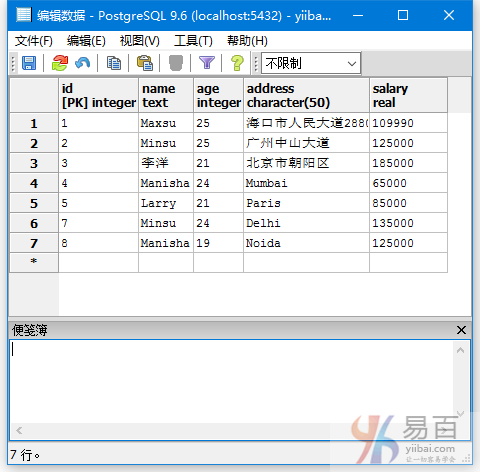
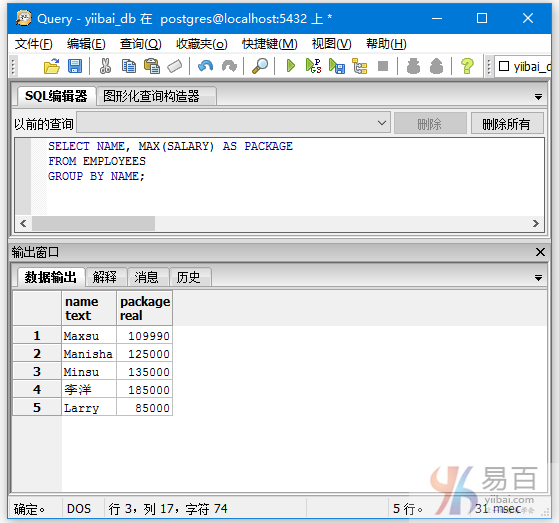
执行以下查询使用别名的语句:
SELECT NAME, MAX(SALARY) AS PACKAGE
FROM EMPLOYEES
GROUP BY NAME;
执行上面查询语句,输出结果如下 -
PostgreSQL表别名
语法:
SELECT column1, column2....
FROM table_name AS alias_name
conditions.... ;
参数说明:
- table_name:它指定要进行别名的表的原始名称。
- alias_name:它指定分配给表的临时名称。
- AS:这是可选的。大多数程序员将在对列名进行别名时指定AS关键字,但在别名表名时不指定。
注意:
- 如果alias_name包含空格,则必须将alias_name包含在引号中。
- 在别名列名时,可以使用空格。 但是,当您使用表名时,使用空格通常不是一个好习惯。
- alias_name仅在SQL语句的范围内有效。
示例-2
我们来看一下表“EMPLOYEES”,具有以下数据。

创建另一个表“DEPARTMENT”,并插入以下数据。
-- Table: public.department
-- DROP TABLE public.department;
CREATE TABLE public.department
(
id integer,
dept text,
fac_id integer
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.department
OWNER TO postgres;
-- 插入数据
INSERT INTO department VALUES(1,'IT', 1);
INSERT INTO department VALUES(2,'Engineering', 2);
INSERT INTO department VALUES(3,'HR', 7);
执行上面查询语句后,DEPARTMENT有以下数据 -
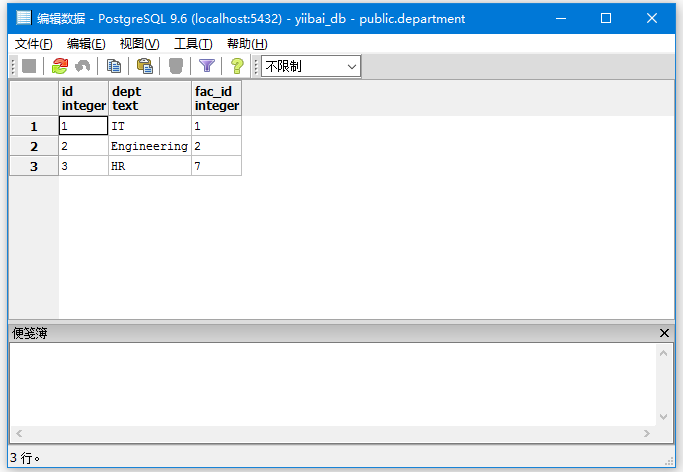
执行以下查询使用别名的语句:
SELECT E.ID, E.NAME, E.AGE, D.DEPT
FROM EMPLOYEES AS E, DEPARTMENT AS D
WHERE E.ID = D.ID;
执行上面查询语句,输出结果如下 -
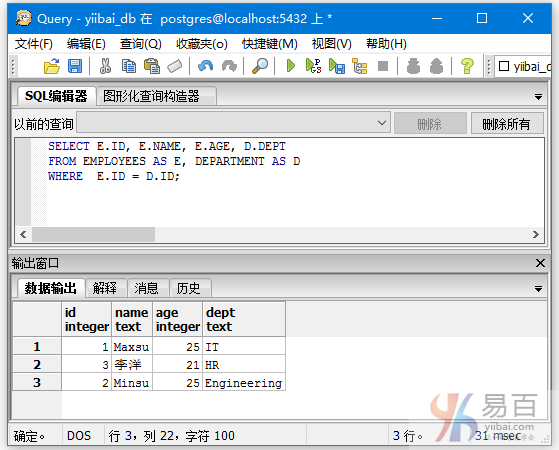
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL别名
PostgreSQL索引 - PostgreSQL教程™
什么是索引?
索引是用于加速从数据库检索数据的特殊查找表。数据库索引类似于书的索引(目录)。 索引为出现在索引列中的每个值创建一个条目。
数据库索引的重要特点
- 索引使用SELECT查询和WHERE子句加速数据输出,但是会减慢使用INSERT和UPDATE语句输入的数据。
- 您可以在不影响数据的情况下创建或删除索引。
- 可以通过使用CREATE INDEX语句创建索引,指定创建索引的索引名称和表或列名称。
- 还可以创建一个唯一索引,类似于唯一约束,该索引防止列或列的组合上有一个索引重复的项。
PostgreSQL创建索引
CREATE INDEX语句用于创建PostgreSQL索引。
语法
CREATE INDEX index_name ON table_name;
索引类型
PostgreSQL中有几种索引类型,如B-tree,Hash,GiST,SP-GiST和GIN等。每种索引类型根据不同的查询使用不同的算法。 默认情况下,CREATE INDEX命令使用B树索引。
单列索引
如果仅在一个表列中创建索引,则将其称为单列索引。
语法:
CREATE INDEX index_name
ON table_name (column_name);
示例
我们有一个名为“EMPLOYEES”的表,具有以下数据:
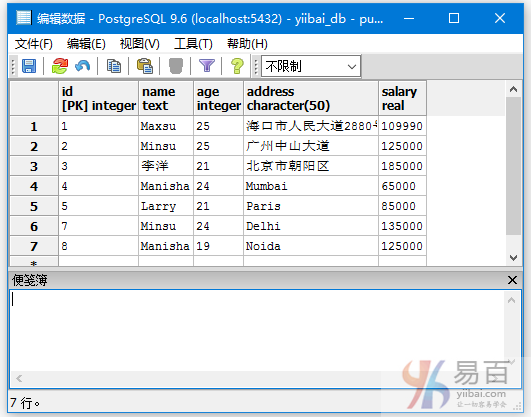
在表“EMPLOYEES”的“name”列上创建一个名为“employees_index”的索引。
执行以下创建语句:
CREATE INDEX employees_index
ON EMPLOYEES (name);
执行结果如下 -
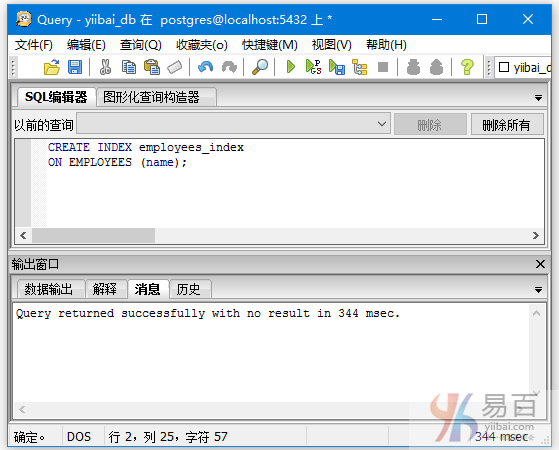
在这里,您可以看到在该表上创建了一个名为“employees_index”的索引 -
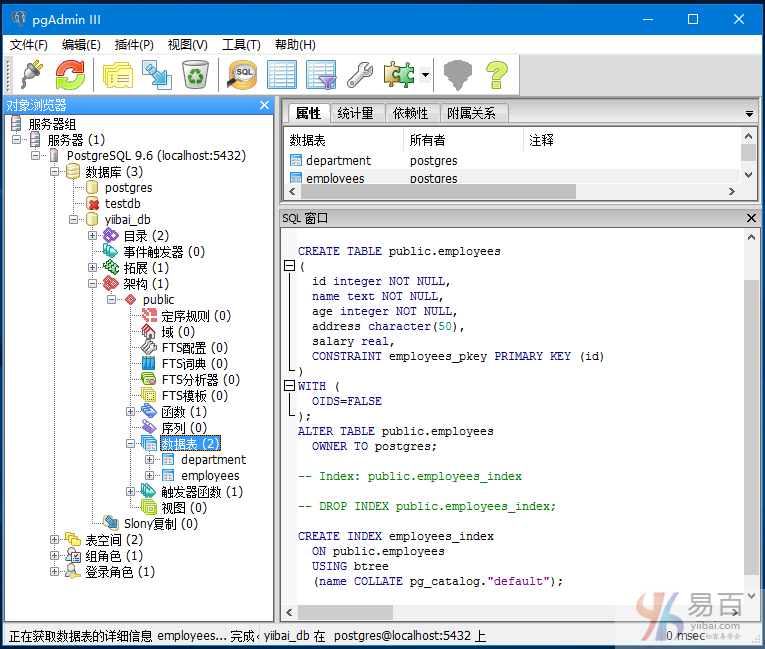
多列索引
如果通过使用表的多个列创建索引,则称为多列索引。
语法:
CREATE INDEX index_name
ON table_name (column1_name, column2_name);
让我们在同一个表“EMPLOYEES”上创建一个名为“multicolumn_index”的多列索引
执行以下创建查询语句:
CREATE INDEX multicolumn_index
ON EMPLOYEES (name, salary);
执行结果如下 -
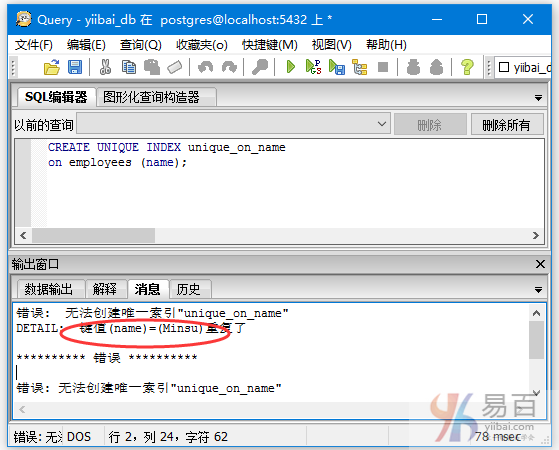
唯一索引
创建唯一索引以获取数据的完整性并提高性能。它不允许向表中插入重复的值,或者在原来表中有相同记录的列上也不能创建索引。
语法:
CREATE UNIQUE INDEX index_name
on table_name (column_name);
例如,在employees表的name字段上创建一个唯一索引,将会提示错误 -
CREATE UNIQUE INDEX unique_on_name
on employees (name);
如下所示(name字段中有两个Minsu的值) -
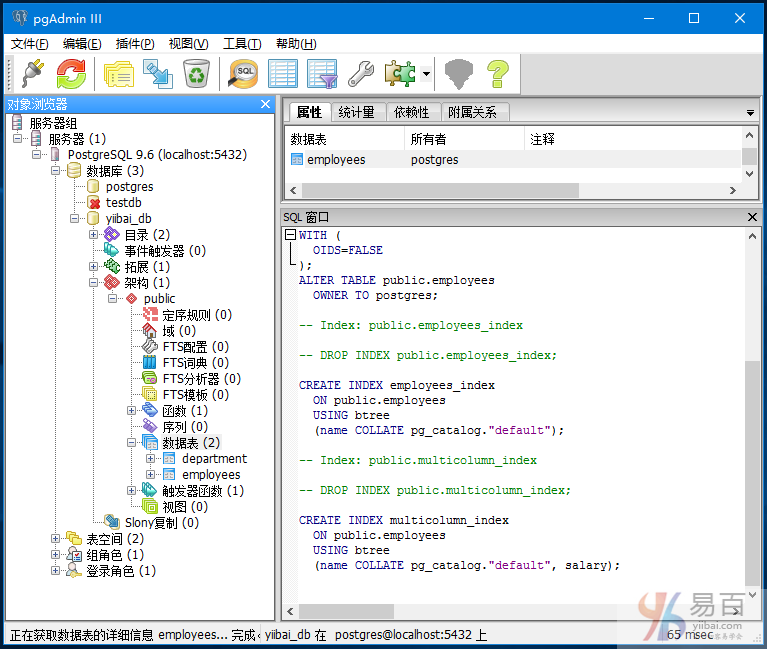
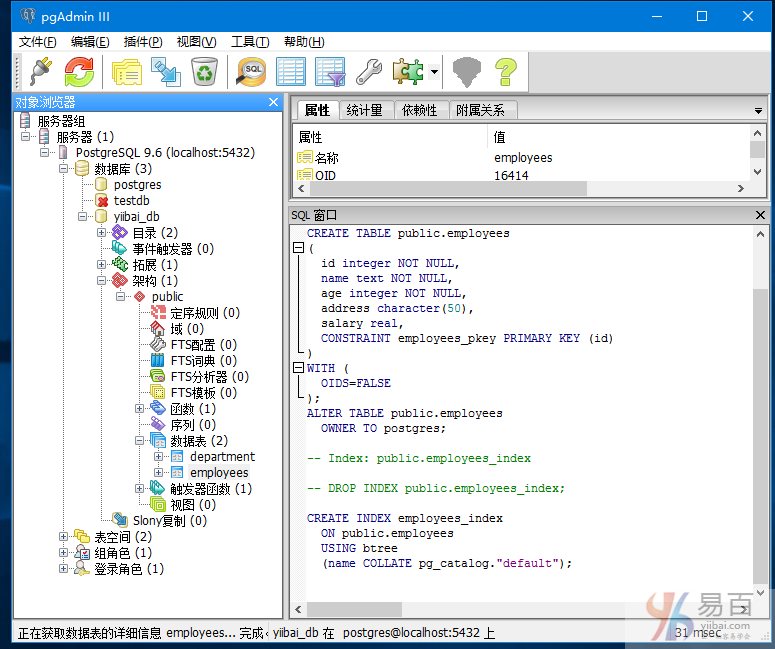
PostgreSQL删除索引
DROP INDEX方法用于删除PostgreSQL中的索引。 如果你放弃一个索引,那么它可以减慢或提高性能。
语法:
DROP INDEX index_name;
作为一个示例,我们现在来删除在前面创建的名为“multicolumn_index”的索引。
执行以下查询语句:
DROP INDEX multicolumn_index;
现在,您可以看到名为“multicolumn_index”的索引已被删除/删除。查看 employees 表的结构 -
什么时候应该避免使用索引?
- 应该避免在小表上使用索引。
- 不要为具有频繁,大批量更新或插入操作的表创建索引。
- 索引不应用于包含大量NULL值的列。
- 不要在经常操作(修改)的列上创建索引。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL索引
PostgreSQL日期和时间函数 - PostgreSQL教程™
所有重要的日期和时间相关函数如下列表所示:
函数 | 描述 |
AGE() | 减去参数 |
CURRENT DATE/TIME() | 它指定当前日期和时间。 |
DATE_PART() | 获取子字段(相当于提取) |
EXTRACT() | 获得子字段 |
ISFINITE() | 测试有限的日期,时间和间隔(非+/-无穷大) |
JUSTIFY | 调整间隔 |
AGE(timestamp,timestamp)&AGE(timestamp):
函数 | 描述 |
age(timestamp, timestamp) | 当使用第二个参数的时间戳形式调用时,age()减去参数,产生使用年数和月份的类型为“interval”的“符号”结果。 |
age(timestamp) | 当仅使用时间戳作为参数调用时,age()从current_date(午夜)减去。 |
AGE()函数例子
按Ctrl + E打开查询编辑器,执行此查询示例:
SELECT AGE(timestamp '2017-01-26', timestamp '1951-08-15');
执行上面语句得到以下结果 -
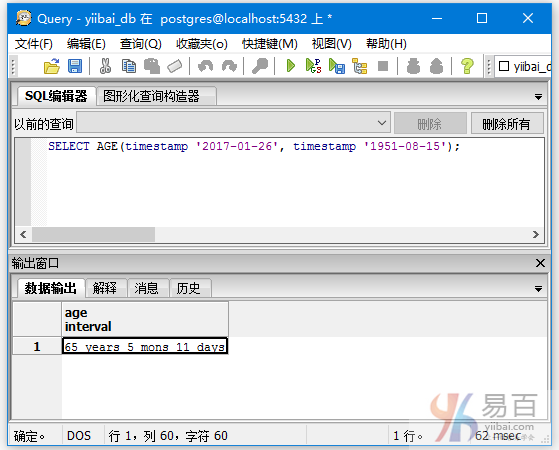
函数AGE(timestamp)的示例
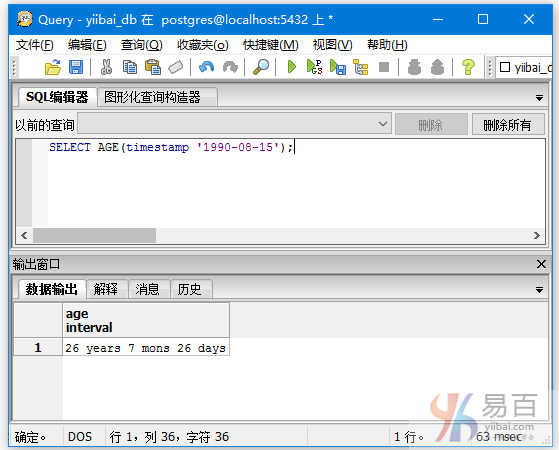
它用于生产当前年龄。
执行上面语句得到以下结果 -
SELECT AGE(timestamp '1990-08-15');
执行上面语句得到以下结果 -
当前DATE/TIME()
以下是返回与当前日期和时间相关的值的函数的列表。
函数 | 描述 |
CURRENT_DATE | 提供当前日期 |
CURRENT_TIME | 提供带时区的值 |
CURRENT_TIMESTAMP | 提供带时区的值 |
CURRENT_TIME(precision) | 可以选择使用precision参数,这将使结果在四分之一秒的范围内四舍五入到数位数。 |
CURRENT_TIMESTAMP(precision) | 可以选择使用精度参数,这将使结果在四分之一秒的范围内四舍五入到数位数。 |
LOCALTIME | 提供没有时区的值。 |
LOCALTIMESTAMP | 提供没有时区的值。 |
LOCALTIME(precision) | 可以选择使用精度参数,这将使结果在四分之一秒的范围内四舍五入到数位数。 |
LOCALTIMESTAMP(precision) | 可以选择使用精度参数,这将使结果在四分之一秒的范围内四舍五入到数位数。 |
现在,您可以来看看以下命令:
获取当前时间:
SELECT CURRENT_TIME;
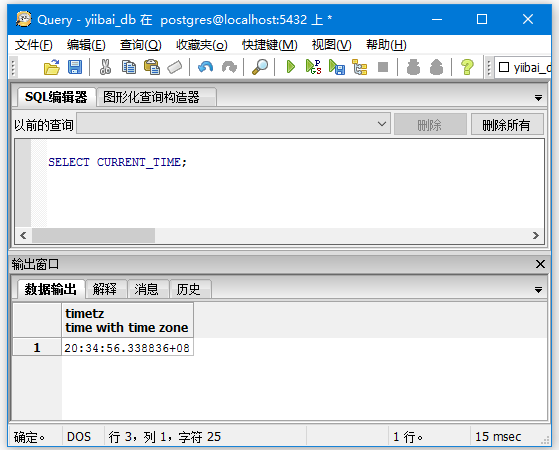
获取当前日期:
SELECT CURRENT_DATE;
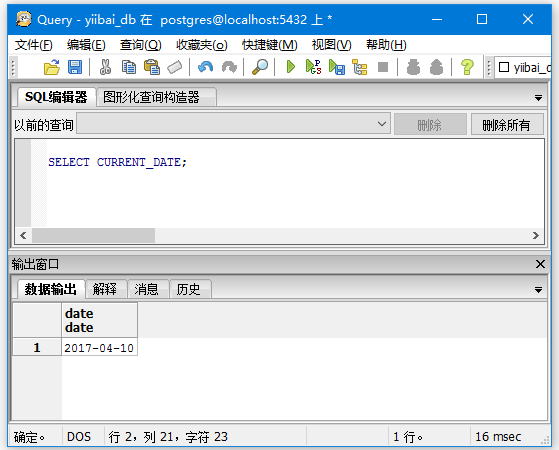
获取当前时间戳(两者的日期和时间)
SELECT CURRENT_TIMESTAMP;
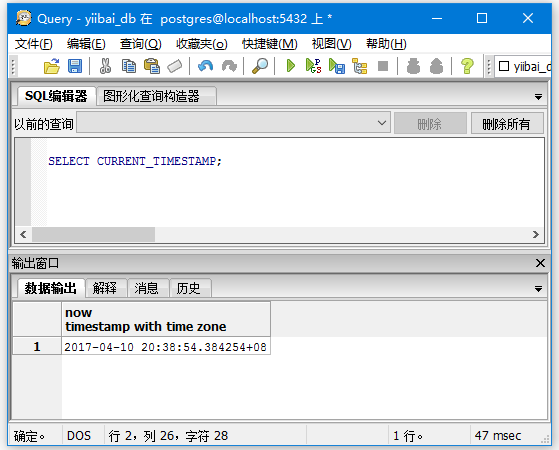
当前时间戳更精确:
SELECT CURRENT_TIMESTAMP(2);
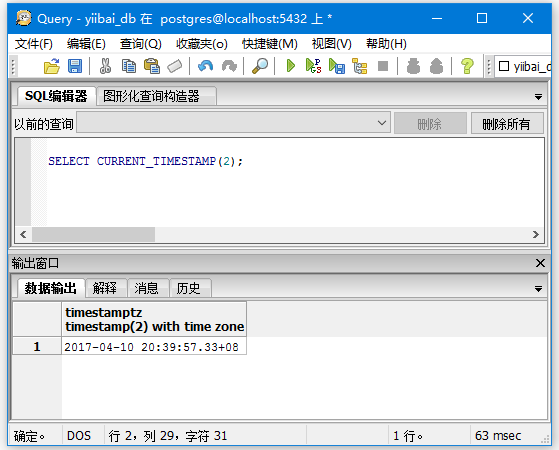
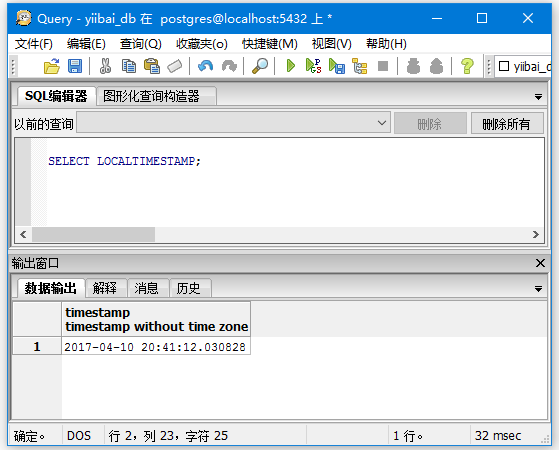
本地时间戳:
SELECT LOCALTIMESTAMP;
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL日期和时间函数
PostgreSQL UNIONS子句 - PostgreSQL教程™
PostgreSQL UNION子句/运算符用于组合两个或多个SELECT语句的结果,而不返回任何重复的行。
要使用UNION,每个SELECT必须具有相同的列数,相同数量的列表达式,相同的数据类型,并且具有相同的顺序,但不一定要相同。
语法:
UNION的基本语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
这里根据您的要求给出的条件表达式。
示例:
考虑以下两个表,COMPANY表如下:
yiibai_db=# SELECT * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
另一张表是DEPARTMENT如下:
yiibai_db=# SELECT * from DEPARTMENT;
id | dept | emp_id
----+-------------+--------
1 | IT Billing | 1
2 | Engineering | 2
3 | Finance | 7
4 | Engineering | 3
5 | Finance | 4
6 | Engineering | 5
7 | Finance | 6
(7 rows)
现在使用SELECT语句和UNION子句连接这两个表,如下所示:
yiibai_db=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
这将产生以下结果:
emp_id | name | dept
--------+-------+--------------
5 | David | Engineering
6 | Kim | Finance
2 | Allen | Engineering
3 | Teddy | Engineering
4 | Mark | Finance
1 | Paul | IT Billing
7 | James | Finance
(7 rows)
UNION ALL子句
UNION ALL运算符用于组合两个SELECT语句(包括重复行)的结果。 适用于UNION的相同规则也适用于UNION ALL运算符。
语法:
UNION ALL的基本语法如下:
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
UNION ALL
SELECT column1 [, column2 ]
FROM table1 [, table2 ]
[WHERE condition]
这里根据您的要求给出的条件表达式。
示例:
现在,我们在SELECT语句中加入上面提到的两个表,如下所示:
yiibai_db=# SELECT EMP_ID, NAME, DEPT FROM COMPANY INNER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID
UNION ALL
SELECT EMP_ID, NAME, DEPT FROM COMPANY LEFT OUTER JOIN DEPARTMENT
ON COMPANY.ID = DEPARTMENT.EMP_ID;
这将产生以下结果:
emp_id | name | dept
--------+-------+--------------
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
1 | Paul | IT Billing
2 | Allen | Engineering
7 | James | Finance
3 | Teddy | Engineering
4 | Mark | Finance
5 | David | Engineering
6 | Kim | Finance
(14 rows)
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL UNIONS子句
PostgreSQL NULL值 - PostgreSQL教程™
PostgreSQL NULL是用于表示缺少值的术语。 表中的NULL值是一个字段中的值,显示为空白。
具有NULL值的字段是没有值的字段。要知道一个NULL值与零值或包含空格的字段不同是非常重要的。
语法:
创建表时使用NULL的基本语法如下:
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
这里,NOT NULL表示该列应该始终接受给定数据类型的显式值。有两列不使用NOT NULL。 因此这意味着这些列可以为NULL。
具有NULL值的字段是在创建记录期间留空的字段。
示例
然而,当选择数据时,NULL值可能会导致问题,因为当将未知值与任何其他值进行比较时,结果始终是未知的,不包括在最终结果中。 考虑下表-COMPANY拥有以下记录:
ID NAME AGE ADDRESS SALARY
---------- ---------- ---------- ---------- ----------
1 Paul 32 California 20000.0
2 Allen 25 Texas 15000.0
3 Teddy 23 Norway 20000.0
4 Mark 25 Rich-Mond 65000.0
5 David 27 Texas 85000.0
6 Kim 22 South-Hall 45000.0
7 James 24 Houston 10000.0
使用UPDATE语句将几个可空值设置为NULL,如下所示:
yiibai_db=# UPDATE COMPANY SET ADDRESS = NULL, SALARY = NULL where ID IN(6,7);
现在,查询COMPANY表应该有以下记录:
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | |
7 | James | 24 | |
(7 rows)
接下来,使用IS NOT NULL运算符列出SALARY不为NULL的所有记录:
yiibai_db=# SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM COMPANY
WHERE SALARY IS NOT NULL;
PostgreSQL上面的语句将产生以下结果:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(5 rows)
以下是使用IS NULL运算符,查询列出SALARY列的值为NULL的所有记录:
yiibai_db=# SELECT ID, NAME, AGE, ADDRESS, SALARY
FROM COMPANY
WHERE SALARY IS NULL;
PostgreSQL上面的语句将产生以下结果:
id | name | age | address | salary
----+-------+-----+---------+--------
6 | Kim | 22 | |
7 | James | 24 | |
(2 rows)
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL NULL值
PostgreSQL修改表(ALTER TABLE语句) - PostgreSQL教程™
PostgreSQL ALTER TABLE命令用于添加,删除或修改现有表中的列。您还可以使用ALTER TABLE命令在现有表上添加和删除各种约束。
语法:
使用ALTER TABLE语句在现有表中添加新列的基本语法如下:
ALTER TABLE table_name ADD column_name datatype;
现有表中ALTER TABLE到DROP COLUMN(删除某个字段)的基本语法如下:
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE更改表中列的DATA TYPE(修改字段类型)的基本语法如下:
ALTER TABLE table_name ALTER COLUMN column_name TYPE datatype;
ALTER TABLE向表中的列添加NOT NULL约束的基本语法如下:
ALTER TABLE table_name MODIFY column_name datatype NOT NULL;
ALTER TABLE添加唯一约束ADD UNIQUE CONSTRAINT到表中的基本语法如下:
ALTER TABLE table_name
ADD CONSTRAINT MyUniqueConstraint UNIQUE(column1, column2...);
ALTER TABLE将“检查约束”添加到表中的基本语法如下所示:
ALTER TABLE table_name
ADD CONSTRAINT MyUniqueConstraint CHECK (CONDITION);
ALTER TABLE添加主键ADD PRIMARY KEY约束的基本语法如下:
ALTER TABLE table_name
ADD CONSTRAINT MyPrimaryKey PRIMARY KEY (column1, column2...);
使用ALTER TABLE从表中删除约束(DROP CONSTRAINT)的基本语法如下:
ALTER TABLE table_name
DROP CONSTRAINT MyUniqueConstraint;
使用ALTER TABLE从表中删除主键约束(DROP PRIMARY KEY)约束的基本语法如下:
ALTER TABLE table_name
DROP CONSTRAINT MyPrimaryKey;
示例:
考虑一个表 - COMPANY 有以下记录:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
以下是向现有的COMPANY表中添加新列的示例:
yiibai_db=# ALTER TABLE COMPANY ADD GENDER char(1);
现在,COMPANY表被更改,以下使用SELECT语句输出:
id | name | age | address | salary | gender
----+-------+-----+-------------+--------+--------
1 | Paul | 32 | California | 20000 |
2 | Allen | 25 | Texas | 15000 |
3 | Teddy | 23 | Norway | 20000 |
4 | Mark | 25 | Rich-Mond | 65000 |
5 | David | 27 | Texas | 85000 |
6 | Kim | 22 | South-Hall | 45000 |
7 | James | 24 | Houston | 10000 |
(7 rows)
以下是现有表中删除 gender列的示例:
yiibai_db=# ALTER TABLE COMPANY DROP GENDER;
现在,COMPANY表被更改,以下将从SELECT语句输出:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL修改表(ALTER TABLE语句)
PostgreSQL截断表(TRUNCATE TABLE语句) - PostgreSQL教程™
PostgreSQL TRUNCATE TABLE命令用于从现有表中删除完整的数据。您也可以使用DROP TABLE命令删除完整的表,但会从数据库中删除完整的表结构,如果希望存储某些数据,则需要重新创建此表。
它和在每个表上使用DELETE语句具有相同的效果,但由于实际上并不扫描表,所以它的速度更快。 此外,它会立即回收磁盘空间,而不需要后续的VACUUM操作。 这在大表上是最有用的。
语法:
TRUNCATE TABLE的基本语法如下:
TRUNCATE TABLE table_name;
示例
考虑一个表 - Company 有以下记录:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(7 rows)
以下是截断的示例:
yiibai_db=# TRUNCATE TABLE COMPANY;
现在,COMPANY表被截断,以下是执行SELECT语句输出:
yiibai_db=# SELECT * FROM COMPANY;
id | name | age | address | salary
----+------+-----+---------+--------
(0 rows)
从以上查询结果可以知道,COMPANY表中已经没有了数据记录了。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL截断表(TRUNCATE TABLE语句)
PostgreSQL事务 - PostgreSQL教程™
事务是对数据库执行的工作单元。事务是以逻辑顺序完成的工作的单位或顺序,无论是用户手动的方式还是通过某种数据库程序自动执行。
事务性质
事务具有以下四个标准属性,一般是由首字母缩写词ACID简称:
- 原子性(Atomicity):确保工作单位内的所有操作成功完成; 否则事务将在故障点中止,以前的操作回滚到其以前的状态。
- 一致性(Consistency):确保数据库在成功提交的事务时正确更改状态。
- 隔离性(Isolation):使事务能够独立运作并相互透明。
- 持久性(Durability):确保在系统发生故障的情况下,提交的事务的结果或效果仍然存在。
事务控制
以下命令用于控制事务:
- BEGIN TRANSACTION:开始事务。
- COMMIT:保存更改,或者您可以使用END TRANSACTION命令。
- ROLLBACK:回滚更改。
事务控制命令仅用于DML命令INSERT,UPDATE和DELETE。 创建表或删除它们时不能使用它们,因为这些操作会在数据库中自动提交。
BEGIN TRANSACTION命令:
可以使用BEGIN TRANSACTION或简单的BEGIN命令来开始事务。 这样的事务通常会持续下去,直到遇到下一个COMMIT或ROLLBACK命令。 但如果数据库关闭或发生错误,则事务也将ROLLBACK。
以下是启动/开始事务的简单语法:
BEGIN;
or
BEGIN TRANSACTION;
COMMIT命令
COMMIT命令是用于将事务调用的更改保存到数据库的事务命令。
COMMIT命令自上次的COMMIT或ROLLBACK命令后将所有事务保存到数据库。
COMMIT命令的语法如下:
COMMIT;
or
END TRANSACTION;
ROLLBACK命令
ROLLBACK命令是用于还原尚未保存到数据库的事务的事务命令。自上次发出COMMIT或ROLLBACK命令以来,ROLLBACK命令只能用于撤销事务。
ROLLBACK命令的语法如下:
ROLLBACK;
示例
考虑COMPANY表有以下记录:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
现在,我们开始一个事务,并删除表中age = 25的记录,最后使用ROLLBACK命令撤消所有的更改。
yiibai_db=# BEGIN;
DELETE FROM COMPANY WHERE AGE = 25;
ROLLBACK;
如果再次查看COMPANY表应该仍然看到以下记录:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
现在,让我们开始另一个事务,并从表中删除age = 25的记录,最后使用COMMIT命令提交所有的更改。
yiibai_db=# BEGIN;
DELETE FROM COMPANY WHERE AGE = 25;
COMMIT;
如果查看COMPANY表应该看到删除后剩下的记录:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(5 rows)
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL事务
PostgreSQL锁 - PostgreSQL教程™
锁或独占锁或写锁阻止用户修改行或整个表。 在UPDATE和DELETE修改的行在事务的持续时间内被自动独占锁定。 这将阻止其他用户更改行,直到事务被提交或回退。
用户必须等待其他用户当他们都尝试修改同一行时。 如果他们修改不同的行,不需要等待。 SELECT查询不必等待。
数据库自动执行锁定。 然而,在某些情况下,必须手动控制锁定。 手动锁定可以通过使用LOCK命令完成。 它允许指定事务的锁类型和范围。
LOCK命令的语法
LOCK命令的基本语法如下:
LOCK [ TABLE ]
name
IN
lock_mode
- name:要锁定的现有表的锁名称(可选模式限定)。 如果在表名之前指定了ONLY,则仅该表被锁定 如果未指定ONLY,则表及其所有后代表(如果有)被锁定。
- lock_mode:锁模式指定此锁与之冲突的锁。 如果未指定锁定模式,则使用最严格的访问模式ACCESS EXCLUSIVE。 可能的值是:ACCESS SHARE,ROW SHARE,ROW EXCLUSIVE,SHARE UPDATE EXCLUSIVE,SHARE,SHARE ROW EXCLUSIVE,EXCLUSIVE,ACCESS EXCLUSIVE。
死锁
当两个事务正在等待彼此完成操作时,可能会发生死锁。 虽然PostgreSQL可以检测到它们并使用ROLLBACK结束,但死锁仍然可能不方便。 为了防止您的应用程序遇到此问题,请确保以这样的方式进行设计,以使其以相同的顺序锁定对象。
咨询锁
PostgreSQL提供了创建具有应用程序定义含义的锁的方法。这些称为咨询锁(劝告锁,英文为:advisory locks)。 由于系统不强制使用它,因此应用程序正确使用它们。 咨询锁可用于锁定针对MVCC模型策略。
例如,咨询锁的常见用途是模拟所谓的“平面文件”数据管理系统的典型的悲观锁定策略。 虽然存储在表中的标志可以用于相同的目的,但是建议锁更快,避免了表的膨胀,并且在会话结束时被服务器自动清除。
示例
考虑表COMPANY有以下记录:
testdb# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
以下示例在ACCESS EXCLUSIVE模式下将COMPANY表锁定在yiibai_db数据库中。 LOCK语句仅在事务模式下工作:
yiibai_db=#BEGIN;
LOCK TABLE company1 IN ACCESS EXCLUSIVE MODE;
PostgreSQL上面的语句将产生以下结果:
LOCK TABLE
上述消息表示表被锁定,直到事务结束并完成事务,必须回滚或提交事务。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL锁
PostgreSQL子查询 - PostgreSQL教程™
子查询或内部查询或嵌套查询是一个PostgreSQL查询中的查询,它可以嵌入到WHERE子句中。子查询用于返回将在主查询中使用的数据作为进一步限制要检索的数据的条件。
子查询可以与SELECT,INSERT,UPDATE和DELETE语句以及运算符(如=,<,>,>=,<=,IN等)一起使用。
子查询必须遵循以下规则:
- 子查询必须括在括号中。
- 子查询在SELECT子句中只能有一列,除非主查询中有多个列用于比较其所选列的子查询。
- ORDER BY不能用于子查询,尽管主查询可以使用ORDER BY。 GROUP BY可用于执行与子查询中的ORDER BY相同的功能。
- 返回多行的子查询只能与多个值运算符一起使用,例如:IN,EXISTS,NOT IN,ANY / SOME,ALL运算符。
- BETWEEN运算符不能与子查询一起使用; 但是,BETWEEN可以在子查询中使用。
带SELECT语句的子查询
子查询最常用于SELECT语句。 基本语法如下:
SELECT column_name [, column_name ]
FROM table1 [, table2 ]
WHERE column_name OPERATOR
(SELECT column_name [, column_name ]
FROM table1 [, table2 ]
[WHERE])
示例:
考虑COMPANY表有以下记录:
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
现在,我们用SELECT语句检查以下子查询:
yiibai_db=# SELECT *
FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY
WHERE SALARY > 45000) ;
这将产生以下结果:
id | name | age | address | salary
----+-------+-----+-------------+--------
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(2 rows)
带INSERT语句的子查询
子查询也可以用于INSERT语句。INSERT语句使用从子查询返回的数据插入另一个表。 可以使用任何字符,日期或数字函数修改子查询中选定的数据。
基本语法如下:
INSERT INTO table_name [ (column1 [, column2 ]) ]
SELECT [ *|column1 [, column2 ]
FROM table1 [, table2 ]
[ WHERE VALUE OPERATOR ]
示例:
考虑一个表COMPANY_BKP,其结构与COMPANY表类似,可以使用COMPANY_BKP作为表名使用相同的CREATE TABLE数据结构来创建。 现在要将完整的COMPANY表复制到COMPANY_BKP中,以下是语句:
yiibai_db=# INSERT INTO COMPANY_BKP
SELECT * FROM COMPANY
WHERE ID IN (SELECT ID
FROM COMPANY) ;
带UPDATE语句的子查询:
子查询可以与UPDATE语句一起使用。 当使用具有UPDATE语句的子查询时,可以更新表中的单列或多列。
UPDATE table
SET column_name = new_value
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
示例:
假设我们有一个名为COMPANY_BKP表,它是COMPANY表的备份。
以下示例将所有客户(其AGE大于或等于27)在COMPANY表中的SALARY更新为0.50倍:
testdb=# UPDATE COMPANY
SET SALARY = SALARY * 0.50
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE >= 27 );
这将影响两行,最后COMPANY表中将具有以下记录:
id | name | age | address | salary
----+-------+-----+-------------+--------
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
1 | Paul | 32 | California | 10000
5 | David | 27 | Texas | 42500
(7 rows)
带有DELETE语句的子查询:
子查询可以与DELETE语句一起使用,就像上面提到的任何其他语句一样。
基本语法如下:
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
示例:
假设我们有一个COMPANY_BKP表,它是COMPANY表的备份。
以下示例从COMPANY 表中删除所有客户的记录,其AGE大于或等于27数据记录:
testdb=# DELETE FROM COMPANY
WHERE AGE IN (SELECT AGE FROM COMPANY_BKP
WHERE AGE > 27 );
这将影响两行,最后COMPANY表将具有以下记录,查询结果如下:
id | name | age | address | salary
----+-------+-----+-------------+--------
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
5 | David | 27 | Texas | 42500
(6 rows)
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL子查询
PostgreSQL自动递增 - PostgreSQL教程™
PostgreSQL具有数据类型smallserial,serial和bigserial; 这些不是真正的类型,而只是在创建唯一标识符列的标志以方便使用。 这些类似于一些其他数据库支持的AUTO_INCREMENT属性。
如果您希望某列具有唯一的约束或是主键,则必须使用其他数据类型进行指定。
类型名称serial用于创建整数列。 类型名称bigserial创建一个bigint类型的列。 如果您期望在表的使用期限内使用超过2^31个标识符,则应使用bigserial。 类型名称smallserial创建一个smallint列。
语法:
SERIAL数据类型的基本用法如下:
CREATE TABLE tablename (
colname SERIAL
);
示例:
考虑要创建的COMPANY表如下:
yiibai_db=# CREATE TABLE COMPANY(
ID SERIAL PRIMARY KEY,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
现在,将以下记录插入COMPANY表:
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ('Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'Kim', 22, 'South-Hall', 45000.00 );
INSERT INTO COMPANY (NAME,AGE,ADDRESS,SALARY)
VALUES ( 'James', 24, 'Houston', 10000.00 );
这将在表中插入7个元组,COMPANY表将具有以下记录:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL自动递增
PostgreSQL权限 - PostgreSQL教程™
在数据库中创建对象时,都会为其分配所有者。 所有者通常是执行创建语句的用户。 对于大多数类型的对象,初始状态是只有所有者(或超级用户)可以修改或删除对象。 要允许其他角色或用户使用它,必须授予权限或权限。
PostgreSQL中的不同类型的权限是:
- SELECT,INSERT,UPDATE,DELETE,TRUNCATE,REFERENCES,TRIGGER,CREATE,CONNECT,TEMPORARY,EXECUTE 和 USAGE。
根据对象的类型(表,函数等),权限将应用于对象。 要为用户分配权限,使用GRANT命令。
GRANT的语法
GRANT命令的基本语法如下:
GRANT privilege [, ...]
ON object [, ...]
TO { PUBLIC | GROUP group | username }
- privilege值可以是:SELECT,INSERT,UPDATE,DELETE,RULE,ALL。
- object:要向其授予访问权限的对象的名称。 可能的对象是:表,视图,序列
- PUBLIC:表示所有用户的简短形式。
- GROUP group:授予权限的组。
- username:授予权限的用户的名称。 PUBLIC是表示所有用户的简短形式。
REVOKE的语法
REVOKE命令的基本语法如下:
REVOKE privilege [, ...]
ON object [, ...]
FROM { PUBLIC | GROUP groupname | username }
- privilege值可以是:SELECT,INSERT,UPDATE,DELETE,RULE,ALL。
- object: 授予访问权限的对象的名称。 可能的对象是:表,视图,序列。
- PUBLIC:表示所有用户的简短形式。
- GROUP group:授予权限的组。
- username:授予权限的用户的名称。 PUBLIC是表示所有用户的简短形式。
示例
如要理解权限,我们先创建一个USER,如下所示:
yiibai_db=# CREATE USER manisha WITH PASSWORD 'password';
CREATE ROLE
语句CREATE ROLE 表示创建了一个用户名为manisha。
考虑 COMPANY 表有以下记录:
yiibai_db# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
接下来,让我们给予用户“manisha”在表COMPANY上授予所有权限,如下所示:
yiibai_db=# GRANT ALL ON COMPANY TO manisha;
GRANT
语句GRANT指示所有在COMPANY表上的权限都分配给用户“manisha”。
接下来,让我们从用户“manisha”中撤销权限,如下所示:
yiibai_db=# REVOKE ALL ON COMPANY FROM manisha;
REVOKE
REVOKE表示从用户“manisha”撤消所有权限。甚至可以删除用户,如下所示:
yiibai_db=# DROP USER manisha;
DROP ROLE
DROP ROLE表示从数据库中删除用户“manisha”。
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PostgreSQL权限
C/C++连接PostgreSQL数据库 - PostgreSQL教程™
本教程将使用libpqxx库,它是PostgreSQL的官方C++客户端API。 libpqxx的源代码可以在BSD许可证下使用,因此您可以免费下载它,将其传递给其他人,更改它,销售,将其包含在您自己的代码中,并与任何人分享您的更改/修改。
安装
最新版本的libpqxx可从链接下载:Libpqxx下载。 所以下载最新版本,并按照以下步骤:
wget http://pqxx.org/download/software/libpqxx/libpqxx-4.0.tar.gz
tar xvfz libpqxx-4.0.tar.gz
cd libpqxx-4.0
./configure
make
make install
在开始使用C/C++的PostgreSQL接口之前,请在PostgreSQL安装目录中找到pg_hba.conf文件,并添加以下行:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
可以启动/重新启动postgres服务器,使用以下命令运行:
[root@host]# service postgresql restart
Stopping postgresql service: [ OK ]
Starting postgresql service: [ OK ]
C/C++连接到PostgreSQL数据库
以下C代码段显示如何连接到端口5432上本地机器上运行的现有数据库。在这里,我使用反斜杠\行继续。
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
}
现在,我们编译并运行上面的程序来连接到数据库testdb,它已经在你的架构中可用,可以使用用户postgres和密码为:pass123进行访问。 您可以根据数据库设置使用用户名和密码。记住保持-lpqxx和-lpq在给定的顺序! 否则,链接器将抱怨关于缺少以“PQ”开头的名称的函数。
$g++ test.cpp -lpqxx -lpq
$./a.out
Opened database successfully: testdb
创建表
以下C代码段将用于在之前创建的数据库(testdb)中创建一个表:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
char * sql;
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "CREATE TABLE COMPANY(" \
"ID INT PRIMARY KEY NOT NULL," \
"NAME TEXT NOT NULL," \
"AGE INT NOT NULL," \
"ADDRESS CHAR(50)," \
"SALARY REAL );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Table created successfully" << endl;
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
当编译和执行上述程序时,它将在testdb数据库中创建一张COMPANY表,并显示以下语句:
Opened database successfully: testdb
Table created successfully
插入操作
以下C代码段显示了如何在上述示例中创建的COMPANY表中创建记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
char * sql;
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (1, 'Paul', 32, 'California', 20000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) " \
"VALUES (2, 'Allen', 25, 'Texas', 15000.00 ); " \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );" \
"INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)" \
"VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
/* Create a transactional object. */
work W(C);
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records created successfully" << endl;
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
当上述程序被编译和执行时,它将在COMPANY表中创建给定的记录,并显示以下两行:
Opened database successfully: testdb
Records created successfully
SELECT操作
以下C代码段显示了如何从上述示例中创建的COMPANY表中获取和显示记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
char * sql;
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create SQL statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
当上述程序被编译和执行时,将产生以下结果:
Opened database successfully: testdb
ID = 1
Name = Paul
Age = 32
Address = California
Salary = 20000
ID = 2
Name = Allen
Age = 25
Address = Texas
Salary = 15000
ID = 3
Name = Teddy
Age = 23
Address = Norway
Salary = 20000
ID = 4
Name = Mark
Age = 25
Address = Rich-Mond
Salary = 65000
Operation done successfully
更新操作
以下C代码段显示了如何使用UPDATE语句来更新指定记录,然后从COMPANY表中获取并显示更新的记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
char * sql;
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL UPDATE statement */
sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records updated successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
当上述程序被编译和执行时,将产生以下结果:
Opened database successfully: testdb
Records updated successfully
ID = 2
Name = Allen
Age = 25
Address = Texas
Salary = 15000
ID = 3
Name = Teddy
Age = 23
Address = Norway
Salary = 20000
ID = 4
Name = Mark
Age = 25
Address = Rich-Mond
Salary = 65000
ID = 1
Name = Paul
Age = 32
Address = California
Salary = 25000
Operation done successfully
删除操作
以下C代码段显示了如何使用DELETE语句删除指定记录,然后再COMPANY表中获取并显示剩余的记录:
#include <iostream>
#include <pqxx/pqxx>
using namespace std;
using namespace pqxx;
int main(int argc, char* argv[])
{
char * sql;
try{
connection C("dbname=testdb user=postgres password=cohondob \
hostaddr=127.0.0.1 port=5432");
if (C.is_open()) {
cout << "Opened database successfully: " << C.dbname() << endl;
} else {
cout << "Can't open database" << endl;
return 1;
}
/* Create a transactional object. */
work W(C);
/* Create SQL DELETE statement */
sql = "DELETE from COMPANY where ID = 2";
/* Execute SQL query */
W.exec( sql );
W.commit();
cout << "Records deleted successfully" << endl;
/* Create SQL SELECT statement */
sql = "SELECT * from COMPANY";
/* Create a non-transactional object. */
nontransaction N(C);
/* Execute SQL query */
result R( N.exec( sql ));
/* List down all the records */
for (result::const_iterator c = R.begin(); c != R.end(); ++c) {
cout << "ID = " << c[0].as<int>() << endl;
cout << "Name = " << c[1].as<string>() << endl;
cout << "Age = " << c[2].as<int>() << endl;
cout << "Address = " << c[3].as<string>() << endl;
cout << "Salary = " << c[4].as<float>() << endl;
}
cout << "Operation done successfully" << endl;
C.disconnect ();
}catch (const std::exception &e){
cerr << e.what() << std::endl;
return 1;
}
return 0;
}
当上述程序被编译和执行时,将产生以下结果:
Opened database successfully: testdb
Records deleted successfully
ID = 3
Name = Teddy
Age = 23
Address = Norway
Salary = 20000
ID = 4
Name = Mark
Age = 25
Address = Rich-Mond
Salary = 65000
ID = 1
Name = Paul
Age = 32
Address = California
Salary = 25000
Operation done successfully
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » C/C++连接PostgreSQL数据库
Java连接PostgreSQL数据库 - PostgreSQL教程™
在Java程序中使用PostgreSQL之前,我们需要确保在机器上安装了PostgreSQL JDBC和Java。 您可以在机器上检查是否正确安装了Java:Java教程。 现在我们来看一下如何设置PostgreSQL JDBC驱动。
- 从postgresql-jdbc存储库下载最新版本的postgresql-(VERSION).jdbc.jar。
- 在类路径中添加下载的jar文件postgresql-(VERSION).jdbc.jar,或者您可以使用-classpath选项,如下面的例子所述。
Java连接到PostgreSQL数据库
以下Java代码显示如何连接到现有数据库。 如果数据库不存在,那么它将被创建,最后将返回一个数据库对象。
import java.sql.Connection;
import java.sql.DriverManager;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"postgres", "123");
} catch (Exception e) {
e.printStackTrace();
System.err.println(e.getClass().getName()+": "+e.getMessage());
System.exit(0);
}
System.out.println("Opened database successfully");
}
}
在编译并运行上述程序之前,请在PostgreSQL安装目录中找到pg_hba.conf文件并添加以下行:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
您可以启动/重新启动postgres服务器,使用以下命令运行:
[root@host]# service postgresql restart
Stopping postgresql service: [ OK ]
Starting postgresql service: [ OK ]
现在,我们来编译并运行上面的程序来获得与testdb的连接。 在这里使用用户ID为postgres和密码为123来访问数据库。 您可以根据数据库配置和设置进行更改。 我们还假定当前版本的JDBC驱动程序postgresql-9.2-1002.jdbc3.jar在当前路径中(c:\tools\)可用。
C:\JavaPostgresIntegration>javac PostgreSQLJDBC.java
C:\JavaPostgresIntegration>java -cp c:\tools\postgresql-9.2-1002.jdbc3.jar;C:\JavaPostgresIntegration PostgreSQLJDBC
Open database successfully
创建表
以下Java程序将用于在之前打开的数据库中创建一个表。确保目标数据库中没有此表。
import java.sql.*;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] )
{
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "CREATE TABLE COMPANY " +
"(ID INT PRIMARY KEY NOT NULL," +
" NAME TEXT NOT NULL, " +
" AGE INT NOT NULL, " +
" ADDRESS CHAR(50), " +
" SALARY REAL)";
stmt.executeUpdate(sql);
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Table created successfully");
}
}
编译和执行程序时,将在testdb数据库中创建COMPANY表,并显示以下两行:
Opened database successfully
Table created successfully
插入数据操作
以下Java程序显示了如何在上述示例中创建的COMPANY表中创建/插入数据记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main(String args[]) {
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (1, 'Paul', 32, 'California', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (2, 'Allen', 25, 'Texas', 15000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );";
stmt.executeUpdate(sql);
sql = "INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) "
+ "VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );";
stmt.executeUpdate(sql);
stmt.close();
c.commit();
c.close();
} catch (Exception e) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Records created successfully");
}
}
程序编译执行后,将在COMPANY表中创建/插入给定的记录,并显示以下两行:
Opened database successfully
Records created successfully
SELECT操作
以下Java程序显示了如何从上述示例中创建的COMPANY表中获取和显示记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] )
{
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
程序编译执行时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
AGE = 32
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
AGE = 25
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
AGE = 23
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
AGE = 25
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下Java代码显示了如何使用UPDATE语句来更新指定记录,然后从COMPANY表中获取和显示更新的记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC {
public static void main( String args[] )
{
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "UPDATE COMPANY set SALARY = 25000.00 where ID=1;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
程序编译执行时,会产生以下结果:
Opened database successfully
ID = 2
NAME = Allen
AGE = 25
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
AGE = 23
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
AGE = 25
ADDRESS = Rich-Mond
SALARY = 65000.0
ID = 1
NAME = Paul
AGE = 32
ADDRESS = California
SALARY = 25000.0
Operation done successfully
删除操作
以下Java代码显示了如何使用DELETE语句删除指定记录,然后从COMPANY表中获取并显示剩余的记录:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class PostgreSQLJDBC6 {
public static void main( String args[] )
{
Connection c = null;
Statement stmt = null;
try {
Class.forName("org.postgresql.Driver");
c = DriverManager
.getConnection("jdbc:postgresql://localhost:5432/testdb",
"manisha", "123");
c.setAutoCommit(false);
System.out.println("Opened database successfully");
stmt = c.createStatement();
String sql = "DELETE from COMPANY where ID=2;";
stmt.executeUpdate(sql);
c.commit();
ResultSet rs = stmt.executeQuery( "SELECT * FROM COMPANY;" );
while ( rs.next() ) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
String address = rs.getString("address");
float salary = rs.getFloat("salary");
System.out.println( "ID = " + id );
System.out.println( "NAME = " + name );
System.out.println( "AGE = " + age );
System.out.println( "ADDRESS = " + address );
System.out.println( "SALARY = " + salary );
System.out.println();
}
rs.close();
stmt.close();
c.close();
} catch ( Exception e ) {
System.err.println( e.getClass().getName()+": "+ e.getMessage() );
System.exit(0);
}
System.out.println("Operation done successfully");
}
}
程序编译执行时,会产生以下结果:
Opened database successfully
ID = 3
NAME = Teddy
AGE = 23
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
AGE = 25
ADDRESS = Rich-Mond
SALARY = 65000.0
ID = 1
NAME = Paul
AGE = 32
ADDRESS = California
SALARY = 25000.0
Operation done successfully
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » Java连接PostgreSQL数据库
PHP连接PostgreSQL数据库 - PostgreSQL教程™
PostgreSQL扩展在默认情况下在最新版本的PHP 5.3.x中是启用的。 可以在编译时使用--without-pgsql来禁用它。仍然可以使用yum命令来安装PHP-PostgreSQL接口:
yum install php-pgsql
在开始使用PHP连接PostgreSQL接口之前,请先在PostgreSQL安装目录中找到pg_hba.conf文件,并添加以下行:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
您可以启动/重新启动postgres服务器,使用以下命令运行:
[root@host]# service postgresql restart
Stopping postgresql service: [ OK ]
Starting postgresql service: [ OK ]
Windows用户必须启用php_pgsql.dll才能使用此扩展名。这个DLL包含在最新版本的PHP 5.3.x中的Windows发行版中。
PHP连接到PostgreSQL数据库
以下PHP代码显示如何连接到本地机器上的现有数据库,最后将返回数据库连接对象。
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
?>
现在,让我们运行上面的程序打开数据库:testdb,如果成功打开数据库连接,那么它将给出以下消息:
Opened database successfully
创建表
以下PHP程序将用于在之前创建的数据库(testdb)中创建一个表:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
} else {
echo "Table created successfully\n";
}
pg_close($db);
?>
当执行上述程序时,它将在testdb数据库中创建COMPANY表,并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下PHP程序显示了如何在上述示例中创建的COMPANY表中创建记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
} else {
echo "Records created successfully\n";
}
pg_close($db);
?>
当执行上述程序时,它将在COMPANY表中创建给定的记录,并显示以下两行:
Opened database successfully
Records created successfully
SELECT操作
以下PHP程序显示了如何从上述示例中创建的COMPANY表中获取和显示记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)){
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
当执行上述程序时,将产生以下结果。 请记下,在创建表时按照它们使用的顺序返回字段。
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000
Operation done successfully
更新操作
以下PHP代码显示了如何使用UPDATE语句来更新指定记录,然后从COMPANY表中获取并显示更新的记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
UPDATE COMPANY set SALARY = 25000.00 where ID=1;
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
exit;
} else {
echo "Record updated successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)){
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
执行上述程序时,会产生以下结果:
Opened database successfully
Record updated successfully
ID = 2
NAME = Allen
ADDRESS = 25
SALARY = 15000
ID = 3
NAME = Teddy
ADDRESS = 23
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = 25
SALARY = 65000
ID = 1
NAME = Paul
ADDRESS = 32
SALARY = 25000
Operation done successfully
删除操作
以下PHP代码显示了如何使用DELETE语句删除指定记录,然后从COMPANY表中获取并显示剩余的记录:
<?php
$host = "host=127.0.0.1";
$port = "port=5432";
$dbname = "dbname=testdb";
$credentials = "user=postgres password=pass123";
$db = pg_connect( "$host $port $dbname $credentials" );
if(!$db){
echo "Error : Unable to open database\n";
} else {
echo "Opened database successfully\n";
}
$sql =<<<EOF
DELETE from COMPANY where ID=2;
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
exit;
} else {
echo "Record deleted successfully\n";
}
$sql =<<<EOF
SELECT * from COMPANY;
EOF;
$ret = pg_query($db, $sql);
if(!$ret){
echo pg_last_error($db);
exit;
}
while($row = pg_fetch_row($ret)){
echo "ID = ". $row[0] . "\n";
echo "NAME = ". $row[1] ."\n";
echo "ADDRESS = ". $row[2] ."\n";
echo "SALARY = ".$row[4] ."\n\n";
}
echo "Operation done successfully\n";
pg_close($db);
?>
执行上述程序时,会产生以下结果:
Opened database successfully
Record deleted successfully
ID = 3
NAME = Teddy
ADDRESS = 23
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = 25
SALARY = 65000
ID = 1
NAME = Paul
ADDRESS = 32
SALARY = 25000
Operation done successfully
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » PHP连接PostgreSQL数据库
Perl连接PostgreSQL数据库 - PostgreSQL教程™
PostgreSQL可以使用Perl DBI模块与Perl集成,Perl DBI模块是Perl编程语言的数据库访问模块。 它定义了一组提供标准数据库接口的方法,变量和约定。
以下是在Linux / Unix机器上安装DBI模块的简单步骤:
$ wget http://search.cpan.org/CPAN/authors/id/T/TI/TIMB/DBI-1.625.tar.gz
$ tar xvfz DBI-1.625.tar.gz
$ cd DBI-1.625
$ perl Makefile.PL
$ make
$ make install
如果您需要安装DBI的SQLite驱动程序,那么可以安装如下:
$ wget http://search.cpan.org/CPAN/authors/id/T/TU/TURNSTEP/DBD-Pg-2.19.3.tar.gz
$ tar xvfz DBD-Pg-2.19.3.tar.gz
$ cd DBD-Pg-2.19.3
$ perl Makefile.PL
$ make
$ make install
在开始使用Perl连接PostgreSQL接口之前,请在PostgreSQL安装目录中找到pg_hba.conf文件,并添加以下行:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
您可以启动/重新启动postgres服务器,可使用以下命令运行:
[root@host]# service postgresql restart
Stopping postgresql service: [ OK ]
Starting postgresql service: [ OK ]
Perl连接到PostgreSQL数据库
以下Perl代码显示如何连接到现有的数据库。 如果数据库不存在,那么它将自动创建,最后将返回一个数据库对象。
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
现在,我们运行上面的程序来打开数据库:testdb,如果成功打开数据库,那么它将给出以下消息:
Open database successfully
创建表
以下Perl程序将用于在之前创建的数据库(testdb)中创建一个表:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL););
my $rv = $dbh->do($stmt);
if($rv < 0){
print $DBI::errstr;
} else {
print "Table created successfully\n";
}
$dbh->disconnect();
当执行上述程序时,它将在testdb中创建一张COMPANY表,并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下Perl程序显示了如何在上述示例中创建的COMPANY表中创建/插入记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (1, 'Paul', 32, 'California', 20000.00 ));
my $rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 ));
$rv = $dbh->do($stmt) or die $DBI::errstr;
$stmt = qq(INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 ););
$rv = $dbh->do($stmt) or die $DBI::errstr;
print "Records created successfully\n";
$dbh->disconnect();
当执行上述程序时,它将在COMPANY表中创建/插入给定的记录,并显示以下两行:
Opened database successfully
Records created successfully
SELECT操作
以下Perl程序显示了如何从上述示例中创建的COMPANY表中获取和显示记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
my $rv = $sth->execute() or die $DBI::errstr;
if($rv < 0){
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000
Operation done successfully
更新操作
Perl代码显示了如何使用UPDATE语句来更新指定记录,然后从COMPANY表中获取和显示更新的记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(UPDATE COMPANY set SALARY = 25000.00 where ID=1;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ){
print $DBI::errstr;
}else{
print "Total number of rows updated : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0){
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000
Operation done successfully
删除操作
Perl代码显示了如何使用DELETE语句删除指定记录,然后从COMPANY表中获取并显示剩余的记录:
#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $database = "testdb";
my $dsn = "DBI:$driver:dbname=$database;host=127.0.0.1;port=5432";
my $userid = "postgres";
my $password = "pass123";
my $dbh = DBI->connect($dsn, $userid, $password, { RaiseError => 1 })
or die $DBI::errstr;
print "Opened database successfully\n";
my $stmt = qq(DELETE from COMPANY where ID=2;);
my $rv = $dbh->do($stmt) or die $DBI::errstr;
if( $rv < 0 ){
print $DBI::errstr;
}else{
print "Total number of rows deleted : $rv\n";
}
$stmt = qq(SELECT id, name, address, salary from COMPANY;);
my $sth = $dbh->prepare( $stmt );
$rv = $sth->execute() or die $DBI::errstr;
if($rv < 0){
print $DBI::errstr;
}
while(my @row = $sth->fetchrow_array()) {
print "ID = ". $row[0] . "\n";
print "NAME = ". $row[1] ."\n";
print "ADDRESS = ". $row[2] ."\n";
print "SALARY = ". $row[3] ."\n\n";
}
print "Operation done successfully\n";
$dbh->disconnect();
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000
Operation done successfully
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » Perl连接PostgreSQL数据库
Python连接PostgreSQL数据库 - PostgreSQL教程™
PostgreSQL可以使用psycopg2模块与Python集成。sycopg2是用于Python编程语言的PostgreSQL数据库适配器。 psycopg2是非常小,快速,稳定的。 您不需要单独安装此模块,因为默认情况下它会随着Python 2.5.x版本一起发布。 如果还没有在您的机器上安装它,那么可以使用yum命令安装它,如下所示:
$yum install python-psycopg2
要使用psycopg2模块,必须首先创建一个表示数据库的Connection对象,然后可以选择创建可以帮助您执行所有SQL语句的游标对象。
连接到数据库
以下Python代码显示了如何连接到现有的数据库。 如果数据库不存在,那么它将自动创建,最后将返回一个数据库对象。
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
在这里指定使用testdb作为数据库名称,如果数据库已成功打开连接,则会提供以下消息:
Open database successfully
创建表
以下Python程序将用于在先前创建的数据库(testdb)中创建一个表:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute('''CREATE TABLE COMPANY
(ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL);''')
print "Table created successfully"
conn.commit()
conn.close()
当执行上述程序时,它将在数据库testdb中创建COMPANY表,并显示以下消息:
Opened database successfully
Table created successfully
插入操作
以下Python程序显示了如何在上述示例中创建的COMPANY表中创建记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
cur.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print "Records created successfully";
conn.close()
当执行上述程序时,它将在COMPANY表中创建/插入给定的记录,并显示以下两行:
Opened database successfully
Records created successfully
SELECT操作
以下Python程序显示了如何从上述示例中创建的COMPANY表中获取和显示记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
更新操作
以下Python代码显示了如何使用UPDATE语句来更新任何记录,然后从COMPANY表中获取并显示更新的记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("UPDATE COMPANY set SALARY = 25000.00 where ID=1")
conn.commit
print "Total number of rows updated :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows updated : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 25000.0
ID = 2
NAME = Allen
ADDRESS = Texas
SALARY = 15000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
删除操作
以下Python代码显示了如何使用DELETE语句来删除记录,然后从COMPANY表中获取并显示剩余的记录:
#!/usr/bin/python
import psycopg2
conn = psycopg2.connect(database="testdb", user="postgres", password="pass123", host="127.0.0.1", port="5432")
print "Opened database successfully"
cur = conn.cursor()
cur.execute("DELETE from COMPANY where ID=2;")
conn.commit
print "Total number of rows deleted :", cur.rowcount
cur.execute("SELECT id, name, address, salary from COMPANY")
rows = cur.fetchall()
for row in rows:
print "ID = ", row[0]
print "NAME = ", row[1]
print "ADDRESS = ", row[2]
print "SALARY = ", row[3], "\n"
print "Operation done successfully";
conn.close()
执行上述程序时,会产生以下结果:
Opened database successfully
Total number of rows deleted : 1
ID = 1
NAME = Paul
ADDRESS = California
SALARY = 20000.0
ID = 3
NAME = Teddy
ADDRESS = Norway
SALARY = 20000.0
ID = 4
NAME = Mark
ADDRESS = Rich-Mond
SALARY = 65000.0
Operation done successfully
本站代码下载:http://www.yiibai.com/siteinfo/download.html
本文属作者原创,转载请注明出处:易百教程 » Python连接PostgreSQL数据库
