




大家好, 好久没有更新了。 最近主要是在忙公司的事情另外还参加了一个3月份的PMP考试,占用了很大的精力和时间。
不出意外,今年开始我司开始大刀阔斧的进行去O的项目了: 数据库替换方案上主要是把ORACLE 这个航空母舰分解成 PG,MYSQL,MONGO,Redis … 等等的开源产品。 商业上我们选择的POC对象是 Oceanbase 这个业界旗舰产品。
本篇文章其实是我们内部对开发人员的一个培训资料, 由于老板是新加玻人,原文是英文的,我这边的文章简单的翻译了一下。
**Different points from oracle migration **
(PG VS ORACLE 的一些不同点)
- NULL & DUAL
- ORACLE NUMBER vs PG numeric
- Exception for data not found & too many rows
- Outer Joins & Subquery in FROM
- Connect by vs Generate_series
- invalid byte sequence for encoding “UTF8”: 0x00
- No interval partition support
- No global index for partition table
- Sequence session level
- SQL execution plan cache session level
- Database, Schema, Role, User
- Default auto-commit
- DDL for rollback
- Default No Hint support
- Object name lower case base (No sensitive unless quoted)
- No need for user defined tablespace, No need specify the name on DDL
- Duplicate index
NULL & DUAL: 空值处理和虚拟表dual
PG的空值连接问题 : 与ORACLE不同, oracle 的 null||'jason' = ‘jason’, PG的 null||'jason' ='' , 解决方法: 我们需要用 concat 作为连接串, 不要使用 || 符号
具体方式可以参考下面的表格里面的案例。
PG 中 没有dual, 直接 select xxx 就可以了
| Function | Oracle | Postgres |
|---|---|---|
| ORACLE NVL vs PG coalesce | SQL> select nvl(null,'empty') from dual; NVL(N SQL> select null||'jason' from dual; NULL| | postgres@[local:/tmp]:2030=#33234 select coalesce(null,'empty'); postgres@[local:/tmp]:2030=#33234 select null||'jason'; postgres@[local:/tmp]:2030=#33234 select coalesce(null,'')||'jason'; OR postgres@[local:/tmp]:2030=#34776 select concat_ws('','jason'); postgres@[local:/tmp]:2030=#84421 select concat('','jason'); |
| Unique index | SQL> create table t2(id int, name varchar2(30)); Table created. SQL> create unique index uk_name on t2(name); Index created. SQL> insert into t2 values (1,NULL); 1 row created. SQL> insert into t2 values (2,NULL); 1 row created. SQL> commit; Commit complete. | postgres@[local:/tmp]:2030=#34776 create table t2(id int, name varchar(30)); Support on PG 15: NULL AS not distinct postgres@[local:/tmp]:2030=#34776 create unique index uk_name3 on t2(name) NULLs not distinct; |
ORACLE NUMBER vs PG numeric
oracle number(38): 9999999999999999999999999999999
PG numeric(m,n): up to 131072 digits before the decimal point; up to 16383 digits after the decimal point
TABLE Primary key option: 主键类型转换的对照关系

Finance column: 财务数据类型: numeric(n,m)和decimal(n,m) 在PG里是等价的

Performance : 20%-30% performance lost (性能损耗测试): PK bigint vs numeric
| PK with bigint | PK with numeric |
|---|---|
postgres@[local:/tmp]:2030=#51374 create table tab_bigint1(id bigint); postgres@[local:/tmp]:2030=#51374 create table tab_bigint2(id bigint); postgres@[local:/tmp]:2030=#51374 insert into tab_bigint1 select generate_series(1,1000000); postgres@[local:/tmp]:2030=#51374 select count(1) from tab_numeric1 t1 inner join tab_numeric2 t2 on t1.id = t2.id; Time: 408.367 ms | postgres@[local:/tmp]:2030=#51374 create table tab_numeric1(id numeric); postgres@[local:/tmp]:2030=#51374 insert into tab_numeric1 select generate_series(1,1000000); postgres@[local:/tmp]:2030=#51374 select count(1) from tab_bigint1 t1 inner join tab_bigint2 t2 on t1.id = t2.id; Time: 340.888 ms |
Exception for data not found & too many rows: NO_DATA_FOUND and TOO_MANY_ROWS are not default exception on PG
PLSQL 中的异常处理, PGPLSQL 中 data not found & too many rows 默认不是 exception.
| PLSQL Exception | ORACLE | Postgres |
|---|---|---|
NO_DATA_FOUND | SQL> DECLARE | do NOTICE: <NULL> |
TOO_MANY_ROWS | SQL> DECLARE | postgres@[local:/tmp]:2030=#9114 select name from t1 where id =1; postgres@[local:/tmp]:2030=#9114 do |
postgres@[local:/tmp]:2030=#9114 do postgres-# $$ postgres$# declare postgres$# v_name varchar; postgres$# begin postgres$# select name postgres$# into strict v_name postgres$# from t1 postgres$# where id = 1; postgres$# raise notice '%', v_name; postgres$# end; postgres$# $$ language plpgsql; ERROR: query returned more than one row HINT: Make sure the query returns a single row, or use LIMIT 1. CONTEXT: PL/pgSQL function inline_code_block line 5 at SQL statement postgres@[local:/tmp]:2030=#9114 do postgres-# $$ postgres$# declare postgres$# v_name varchar; postgres$# begin postgres$# select name postgres$# into strict v_name postgres$# from t1 postgres$# where id = -1; postgres$# raise notice '%', v_name; postgres$# end; postgres$# $$ language plpgsql; ERROR: query returned no rows CONTEXT: PL/pgSQL function inline_code_block line 5 at SQL statement |
Outer Joins & Subquery in FROM:
外连接 (+): 需要修改成 outer join
子查询PG中需要加一个 alias 别名
| ORACLE | Postgres | |
|---|---|---|
Outer Joins | SELECT a.field1, b.field2 FROM a, b WHERE a.item_id = b.item_id(+) | SELECT a.field1, b.field2 FROM a LEFT OUTER JOIN b ON a.item_id = b.item_id; |
Subquery in FROM | SELECT * FROM (SELECT * FROM t2) | postgres@[local:/tmp]:2030=#9114 SELECT * FROM (SELECT * FROM t2); |
Connect by vs Generate_series: 递归查询
| ORACLE | Postgres | |
Connect by Genrate_series | SQL> select level rn from dual connect by level <= 5; RN | postgres@[local:/tmp]:2030=#84421 SELECT * FROM generate_series(1,5) as rn; |
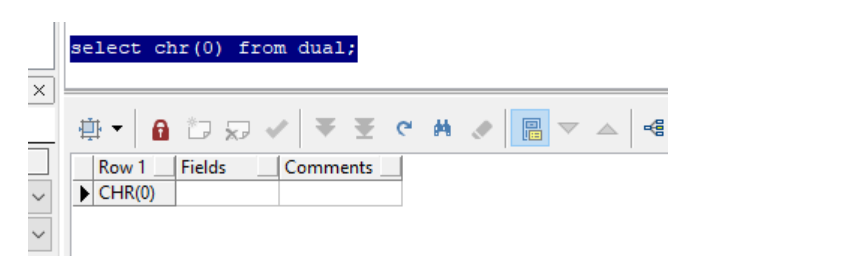
Invalid byte sequence for encoding "UTF8": 0x00: 无效的字符
ORACLE VARCHAR2 can store the 0x00, Postgres can't do that.
这个问题主要出现在数据同步的时候, ORACLE 的vatchar2可以保存一些不可用的字符, 像是 0x00, 这样的字符迁移到PG端则会报错。
这个报错在ETL中是比较常见的。
字符0x00 对应的是 NULL , 实际上就是不可见的空字符。
解决方法:
1.在源端对有问题的列,进行update 操作,替换 chr(0) 为 ''
2.源端数据保持不变,在做数据同步的之后,查询的SQL 进行 replace 替换:replace(column,chr(0),'')
No interval partition support: No native interval partition syntax for PG.
没有原生的自增类型的分区表
Workaround: use extension pg_partman or crontab job scripts. Monitor the partition availability is mandatory(DBA task).
替换方案, 使用 pg_partman 或者 crontab job 来实现自增或者自维护。 --后续会有这个主题独立的文章
No global index for partition table: No native global index syntax for PG.
没有全局索引的概念
Workaround: Replace them with local index. Unique index or Primary key must contains partition column.
只能有本地索引,唯一键和主键需要包含分区间。
postgres@[local:/tmp]:2030=#106776 create table payment_request ( postgres(# id serial , postgres(# account_no varchar(50) not null, postgres(# pay_amount decimal (6,2), postgres(# pay_date date, postgres(# pay_status int) partition by range(pay_date); CREATE TABLE postgres@[local:/tmp]:2030=#106776 alter table payment_request add constraint pk_id_paydate primary key (id); ERROR: unique constraint on partitioned table must include all partitioning columns DETAIL: PRIMARY KEY constraint on table "payment_request" lacks column "pay_date" which is part of the partition key. |
Primary key: id + partition column
主键+分区键
postgres@[local:/tmp]:2030=#106776 alter table payment_request add constraint pk_id_paydate primary key (id,pay_date); ALTER TABLE |
Unique key: account + partition column
唯一键 + 分区键
postgres@[local:/tmp]:2030=#106776 alter table payment_request add constraint uk_account_paydate unique (account_no,pay_date); ALTER TABLE |
View index:
postgres@[local:/tmp]:2030=#106776 \d+ payment_request
Partitioned table "public.payment_request"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
------------+-----------------------+-----------+----------+---------------------------------------------+----------+-------------+--------------+-------------
id | integer | | not null | nextval('payment_request_id_seq'::regclass) | plain | | |
account_no | character varying(50) | | not null | | extended | | |
pay_amount | numeric(6,2) | | | | main | | |
pay_date | date | | not null | | plain | | |
pay_status | integer | | | | plain | | |
Partition key: RANGE (pay_date)
Indexes:
"pk_id_paydate" PRIMARY KEY, btree (id, pay_date)
"uk_account_paydate" UNIQUE CONSTRAINT, btree (account_no, pay_date)
Number of partitions: 0
|
Sequence session level : Cache not shared, Only session level
序列是session 级别私有的,不同session 不会共享缓存的值
Create Sequence:
postgres@[local:/tmp]:2030=#106776 create sequence seq_gap_val cache 100; CREATE SEQUENCE |
| Session A | Session B |
|---|---|
postgres@[local:/tmp]:2030=#106776 SELECT nextval('seq_gap_val'); | |
postgres@[local:/tmp]:2030=#1675 SELECT nextval('seq_gap_val'); | |
postgres@[local:/tmp]:2030=#106776 SELECT nextval('seq_gap_val'); | |
postgres@[local:/tmp]:2030=#1675 SELECT nextval('seq_gap_val'); |
SQL execution plan cache session level:
SQL执行计划缓存是session 私有化。 这点和ORACLE是有极大的不同的。
PostgreSQL does not have a shared query plan cache, but it has an optional query plan cache for prepared statements. That means that the developer has the choice to use a prepared statement with or without cached query plan. But note that the cache is dropped when the prepared statement is closed.
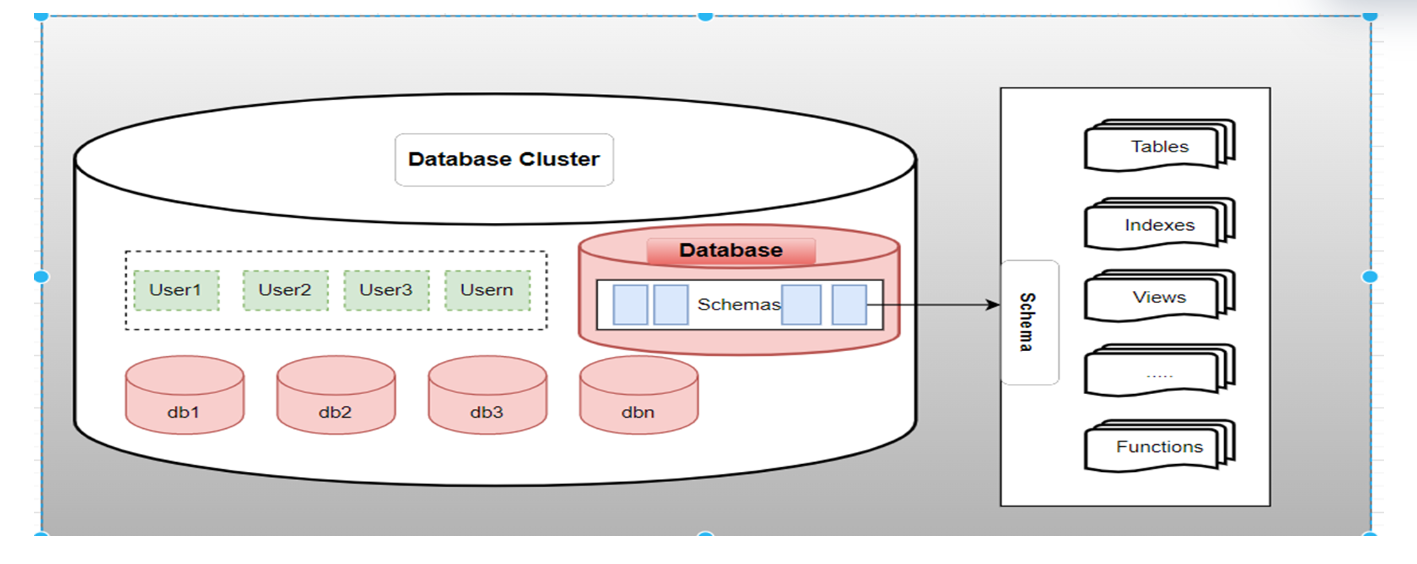
Database, Schema, Role, User: Different concept from mysql , oracle.
数据库,schema,role, user这些概念和mysql, oracle 中是不一样的
下面是一些基本概念的对照关系:
PG 的实例包含了多个database, 是访问相互隔离的,而user 是一个 global 全局的概念存在。schema是每个数据库下一些表,试图什么的集合。
ORACLE 的实例下包含了多个schema, 也就是user ,每个应用开发程序会连到一个schema 。
mysql 的实例下面的database 就是schema的概念。
| Oracle | Postgres |
|---|---|
| Instance | |
| Instance | database |
| schema = user | schema != user (User is a global concept ) |
| table/index/view... | table/index/view... |
PG 的概念对象图:
We mapping the schema & user together as ORACLE :
在取O的项目中,我们把schema 和 user 做了个授权的映射, 这样用起来更像ORACLE的schema的感觉:
postgres@[local:/tmp]:2030=#1675 create user app_cashier password '12345678'; CREATE ROLE postgres@[local:/tmp]:2030=#1675 create schema app_cashier authorization app_cashier; CREATE SCHEMA postgres@[local:/tmp]:2030=#1675 show search_path; search_path ----------------- "$user", public (1 row) |
Default auto-commit behavior:
postgres@[local:/tmp]:2030=#1675 insert into t1 select 1, 'jason'; INSERT 0 1 postgres@[local:/tmp]:2030=#1675 commit; WARNING: there is no transaction in progress COMMIT |
Manually commit: begin
我们在部署项目的时候,需要手动执行 begin 开启事务,来判断是否需要提交还是回滚change.
postgres@[local:/tmp]:2030=#1675 begin; BEGIN postgres@[local:/tmp]:2030=#1675 insert into t1 select 1, 'jason'; INSERT 0 1 postgres@[local:/tmp]:2030=#1675 commit; COMMIT |
DDL for rollback : DDL 也是支持回滚的,所以一旦手动开始事务,DDL同样需要commit或者rollback.
Like several of its commercial competitors, one of the more advanced features of PostgreSQL is its ability to perform transactional DDL via its Write-Ahead Log design. This design supports backing out even large changes to DDL, such as table creation. You can't recover from an add/drop on a database or tablespace, but all other catalog operations are reversible.
postgres@[local:/tmp]:2030=#1675 begin;
BEGIN
postgres@[local:/tmp]:2030=#1675 alter table t1 add age int;
ALTER TABLE
postgres@[local:/tmp]:2030=#1675 rollback;
ROLLBACK
postgres@[local:/tmp]:2030=#1675 \d t1;
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+-------------------------+-----------+----------+---------
id | integer | | |
name | character varying(1000) | | |
Indexes:
"idx" btree (id)
|
Not support all DDL: like create database or tablespace
一些特使创建数据库,表空间的语句是不支持 手动开始事务的
postgres@[local:/tmp]:2030=#1675 begin; BEGIN postgres@[local:/tmp]:2030=#1675 create database db1; ERROR: CREATE DATABASE cannot run inside a transaction block |
Default No Hint support : 原生不支持hint
Extension PG_HINT_PLAN : https://github.com/ossc-db/pg_hint_plan 可以手动安装 pg_hint_plan的插件
Object name lower case base: No sensitive (Oracle is convert to upper case, PG is convert to lower case)
postgres@[local:/tmp]:2030=#1675 create table TAB_UPPER (id int); CREATE TABLE postgres@[local:/tmp]:2030=#1675 select * from pg_tables where tablename = 'tab_upper'; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity ------------+-----------+------------+------------+------------+----------+-------------+------------- public | tab_upper | postgres | | f | f | f | f (1 row) |
Create object with ": change to case sensetive
如果用引号声明对象的名字,那么将变成大小写敏感的对象名
postgres@[local:/tmp]:2030=#1675 create table "TAB_UPPER" (id int); CREATE TABLE postgres@[local:/tmp]:2030=#1675 select * from pg_tables where tablename = 'TAB_UPPER'; schemaname | tablename | tableowner | tablespace | hasindexes | hasrules | hastriggers | rowsecurity ------------+-----------+------------+------------+------------+----------+-------------+------------- public | TAB_UPPER | postgres | | f | f | f | f (1 row) |
postgres@[local:/tmp]:2030=#1675 insert into tab_upper select 1; INSERT 0 1 postgres@[local:/tmp]:2030=#1675 select * from tab_upper; id ---- 1 (1 row) postgres@[local:/tmp]:2030=#1675 select * from TAB_UPPER; id ---- 1 (1 row) postgres@[local:/tmp]:2030=#1675 select * from "TAB_UPPER"; id ---- (0 rows) |
No need for user defined tablespace, No need specify the name on DDL
来自于AWS和cybertech 关于 tablespace in PG的观点:

Duplicate index : 重复的索引
postgres@[local:/tmp]:2030=#113686 \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+-------------------------+-----------+----------+---------
id | integer | | |
name | character varying(1000) | | |
Indexes:
"idx" btree (id)
postgres@[local:/tmp]:2030=#113686 create index idx on t1(id);
ERROR: relation "idx" already exists
postgres@[local:/tmp]:2030=#113686 create index idx1 on t1(id);
CREATE INDEX
postgres@[local:/tmp]:2030=#113686 \d+ t1
Table "public.t1"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+-------------------------+-----------+----------+---------+----------+-------------+--------------+-------------
id | integer | | | | plain | | |
name | character varying(1000) | | | | extended | | |
Indexes:
"idx" btree (id)
"idx1" btree (id)
Access method: heap
postgres@[local:/tmp]:2030=#113686 SELECT
postgres-# t.schemaname,
postgres-# t.tablename,
postgres-# c.reltuples::bigint AS num_rows,
postgres-# pg_size_pretty(pg_relation_size(c.oid)) AS table_size,
postgres-# psai.indexrelname AS index_name,
postgres-# pg_size_pretty(pg_relation_size(i.indexrelid)) AS index_size,
postgres-# CASE WHEN i.indisunique THEN 'Y' ELSE 'N' END AS "unique",
postgres-# psai.idx_scan AS number_of_scans,
postgres-# psai.idx_tup_read AS tuples_read,
postgres-# psai.idx_tup_fetch AS tuples_fetched
postgres-# FROM
postgres-# pg_tables t
postgres-# LEFT JOIN pg_class c ON t.tablename = c.relname
postgres-# LEFT JOIN pg_index i ON c.oid = i.indrelid
postgres-# LEFT JOIN pg_stat_all_indexes psai ON i.indexrelid = psai.indexrelid
postgres-# WHERE
postgres-# t.schemaname NOT IN ('pg_catalog', 'information_schema')
postgres-# ORDER BY 1, 2;
schemaname | tablename | num_rows | table_size | index_name | index_size | unique | number_of_scans | tuples_read | tuples_fetched
------------+-----------------+----------+------------+--------------------+------------+--------+-----------------+-------------+----------------
public | TAB_UPPER | -1 | 0 bytes | | | N | | |
public | payment_request | -1 | 0 bytes | | 0 bytes | Y | | |
public | payment_request | -1 | 0 bytes | | 0 bytes | Y | | |
public | student_grade | -1 | 8192 bytes | student_grade_pkey | 16 kB | Y | 0 | 0 | 0
public | t1 | 5000002 | 211 MB | idx1 | 107 MB | N | 0 | 0 | 0
public | t1 | 5000002 | 211 MB | idx | 107 MB | N | 3 | 9 | 9
public | tab_upper | -1 | 8192 bytes | | | N | | |
public | tax_revenue | -1 | 8192 bytes | tax_revenue_pkey | 16 kB | Y | 0 | 0 | 0
(8 rows)
|
Find out duplicated index:
监控和查找重复的索引:
postgres@[local:/tmp]:2030=#113686 SELECT pg_size_pretty(sum(pg_relation_size(idx))::bigint) as size, postgres-# (array_agg(idx))[1] as idx1, (array_agg(idx))[2] as idx2, postgres-# (array_agg(idx))[3] as idx3, (array_agg(idx))[4] as idx4 postgres-# FROM ( postgres(# SELECT indexrelid::regclass as idx, (indrelid::text ||E'\n'|| indclass::text ||E'\n'|| indkey::text ||E'\n'|| postgres(# coalesce(indexprs::text,'')||E'\n' || coalesce(indpred::text,'')) as key postgres(# FROM pg_index) sub postgres-# GROUP BY key HAVING count(*)>1 postgres-# ORDER BY sum(pg_relation_size(idx)) DESC; size | idx1 | idx2 | idx3 | idx4 --------+------+------+------+------ 214 MB | idx | idx1 | | (1 row) |
