




PolarDB for PostgreSQL(简称 PolarDB-PG)是一款阿里云自主研发的云原生关系型数据库产品,100% 兼容 PostgreSQL,高度兼容Oracle语法;采用基于 Shared-Storage 的存储计算分离架构,具有极致弹性、毫秒级延迟、HTAP 的能力和高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB 具有大规模并行计算能力,可以应对OLTP与OLAP混合负载。
在 PolarDB 存储计算分离的架构基础上我们研发了基于共享存储的MPP架构步具备了 HTAP 的能力,对一套 TP的数据支持两套执行引擎:
- 单机执行引擎用于处理高并发的 OLTP
- MPP跨机分布式执行引擎用于复杂的 OLAP 查询,发挥集群多个 RO 节点的算力和IO吞吐能力
存储计算分离架构

首先我们先来了解一下 PolarDB 的架构,从上图中可以看到,左侧是计算存储一体化,传统的数据库的存储是存在本地的。右侧是 PolarDB 存储计算分离架构,底层是共享存储,可以挂任意多个计算节点。计算节点是无状态的,可以很好地做一个扩展,另外可以降低成本,比如用户可以扩展到16个节点,但底层存储还是一份存储。
分布式存储是比较成熟的存储解决方案,自带存储的高可用,秒级备份,像 Ceph、PolarStorage,都是比较成熟的存储解决方案。把社区单机的 PostgreSQL 数据库,直接跑在一个共享存储设备上,是不是可以认为是PolarDB 呢?答案是不可以直接这么做,根本原因是在这套架构下有一份存储,但是计算节点有N个,计算节点之间需要协调。
HTAP 架构 - 存储计算分离处理AP查询的挑战
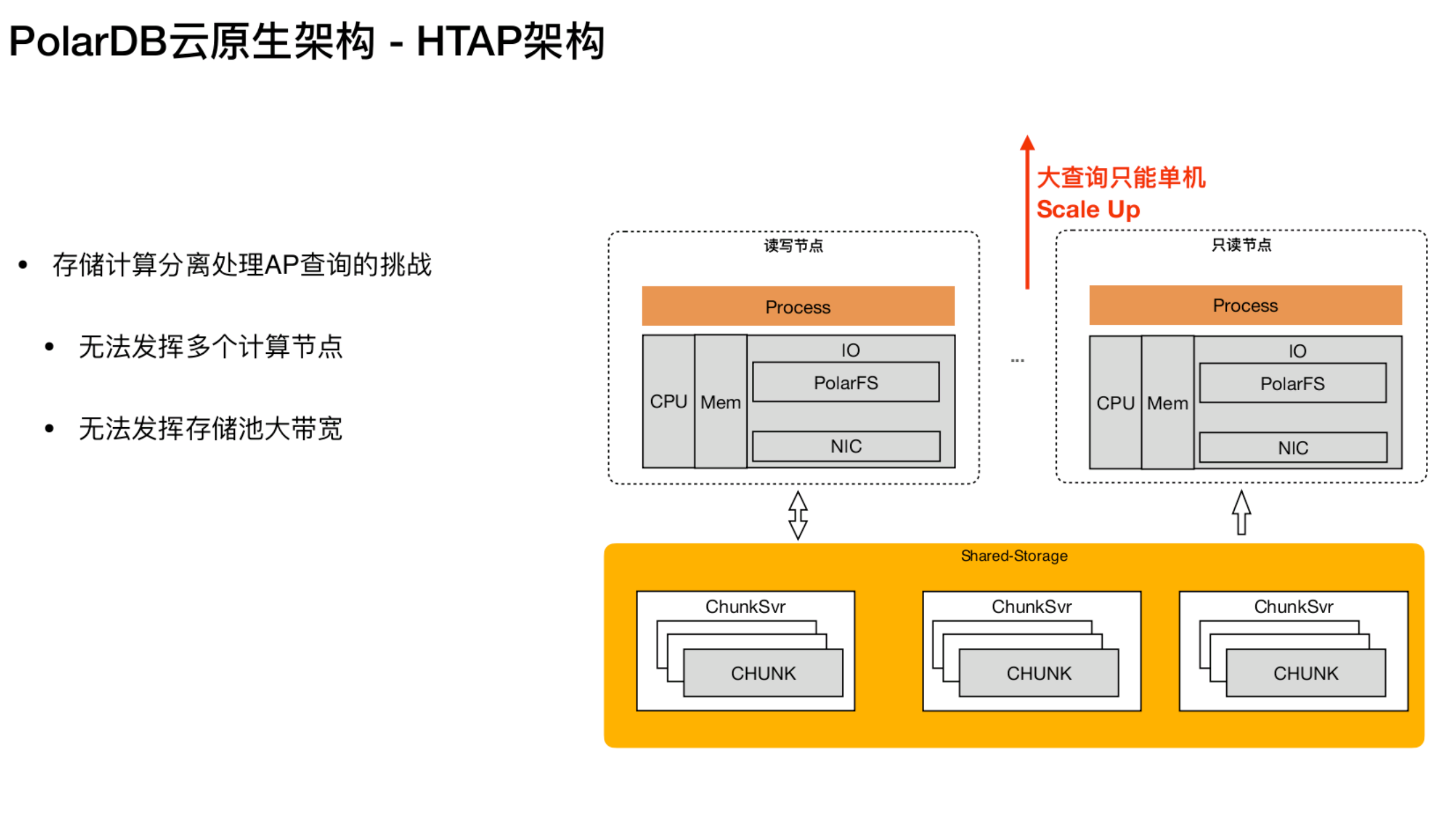
在这个架构下,如果用户需要跑一些分析型的查询,可以举个实际例子,比如像电信计费系统,白天处理用户的充值、各种积分的结算,像这样的请求,都会带有 UserID,通过索引可以精确地定位到修改的页面。在晚上会跑一些批量的分析,比如做对账,在不同的维度去统计省、市,统计整体的销售情况。存储计算分离的架构在处理大查询上,把 SQL 通过读写分离,将 SQL 动态地负载到负载较低的节点上。
这个节点在处理复杂 SQL 时,PG 数据库具备单机并行的能力,虽然单机并行处理复杂 SQL 比单机的串行有很大的提升,但在单机并行下内存和 CPU 还是有一定局限性,在这种架构下处理复杂 SQL 只能通过 Scale Up 的方式来加速。也就是说如果发现 SQL 处理得比较慢,就只能增加 CPU,增加内存,找一个配置更高的机器来当只读节点。而且单一节点来处理一个复杂SQL,是无法发挥出整个存储池大带宽的优势。
因为分布式存储底层是有多个盘,每个盘都具有读写的能力。如果计算节点成为瓶颈,那么底层共享存储池,每个盘的能力是无法发挥的 。另外一个问题,当只用一个节点来处理复杂 SQL 时,其他节点有可能是空闲的,因为通常AP的并发是很低的,有可能只是几个节点在跑一些固定的报表SQL,而其他的节点是处于空闲的状态,它的CPU,内存还有网络也是没有办法利用起来的。
HTAP 架构 - 基于共享存储的MPP
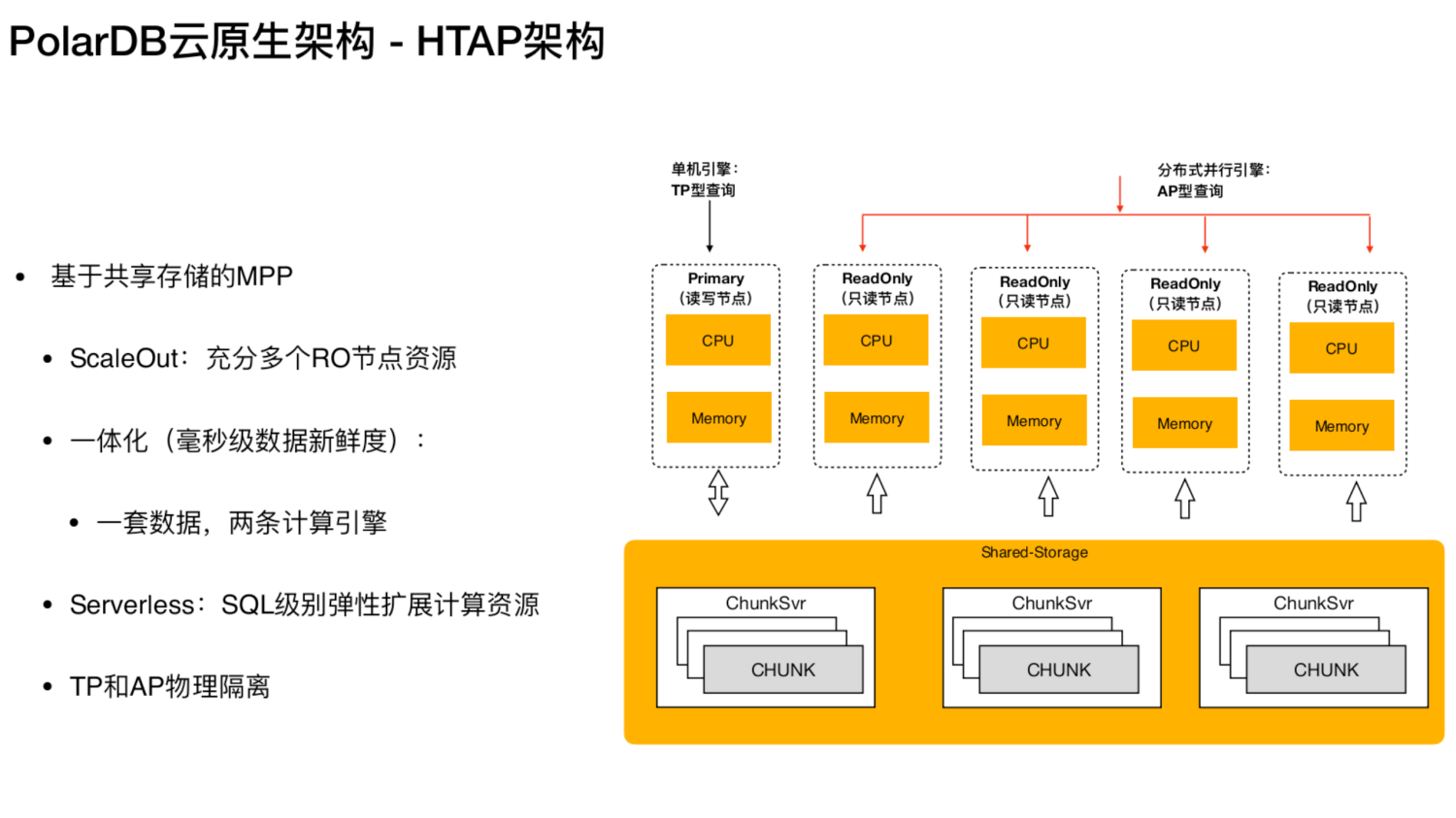
PolarDB
的解决方案是将多个只读节点连在一起,实现了基于共享存储的分布式的并行执行引擎,用户可以比较灵活地来使用整个系统。比如用某些节点来跑 TP
查询,代码路径就走到了单机查询。单机查询的好处是处理点查点写比较快,因为它不涉及到分布式事务,单机可以很快处理完成。当需要对复杂 SQL
来做计算时,可以利用多个只读节点并行执行一个 SQL,即分布式的并行执行引擎 MPP 方案。
PolarDB 的 MPP 和传统数据库比如
Greenplum 这类基于分片的 MPP 是有本质区别。比如在某个时间点发现分计算能力不足了,PolarDB
可以很快地增加只读节点的个数,而且此时整个底层的共享存储数据不需要去做重分布。用过 Greenplum 传统的 share nothing
MPP 会知道,扩容或缩容是非常大的运维动作。
PolarDB 是存储计算分离的,计算节点是无状态的,可以通过迅速增加节点让计算能力变得更强大。另外的好处是TP 和 AP 可以做到物理隔离状态,保证用户在执行 TP 时不影响AP, AP 也不影响 TP。
这套方案实际上是具有一套数据,像传统的一些方案支持两套,比如将TP的数据导出到另外一套
AP
的系统里面,它的数据要拷贝一份,同步出过程数据的延迟也是比较大的。而且对资源是一种浪费,比如白天跑TP,晚上跑AP,实际上两个集群只有一个集群在发挥作用。PolarDB
是提供一体化解决方案——在共享存储上用一套数据支持两套计算引擎,一个是单机引擎,一个是分布式并行的执行引擎。通过共享存储的特性,以及在读写节点之间的延迟可以做到毫秒级。相比于传统的通过
TP 数据导到 AP 的系统里面,数据新鲜度可以做到毫秒级的延迟。




