




本期问答如下:
- 下划线数据类型
- 备份锁等待问题
- 单独备份分区结构
- NCR字符转义问题
Q1.下划线数据类型
问题描述
有客户询问_varchar和_int这种带下划线的数据类型是否为可用的数据类型,语法层面建表时可以创建成功。
postgres=# create table ttt(a _varchar);
CREATE TABLE
复制问题解答
带下划线的数据类型可以理解为对象数组的一种内部别名形式.
除了基本的数据对象类型有下划线类型,当我们新建table时,pg_type系统表也会产生两个类型,一个是table本身的类型,另一个是带下划线的数组类型,示例如下:
postgres=# select typname from pg_type where typname like '%ttt';
┌─────────┐
│ typname │
├─────────┤
│ ttt │
│ _ttt │
└─────────┘
(2 rows)
复制不管是基本数据对象还是我们创建的对象,都可以正常使用下划线类型:
postgres=# insert into ttt values('{abc}'::varchar[]);
INSERT 0 1
postgres=# select '{100,200}'::_varchar;
┌───────────┐
│ _varchar │
├───────────┤
│ {100,200} │
└───────────┘
(1 row)
复制我们使用pg_typeof可以看到它的类型本质上是数组类型。
postgres=# select pg_typeof('{100,200}'::_varchar);
┌─────────────────────┐
│ pg_typeof │
├─────────────────────┤
│ character varying[] │
└─────────────────────┘
(1 row)
复制int家族亦是如此:
postgres=# select pg_typeof('{100,200}'::_int2);
┌────────────┐
│ pg_typeof │
├────────────┤
│ smallint[] │
└────────────┘
(1 row)
postgres=# select pg_typeof('{100,200}'::_int4);
┌───────────┐
│ pg_typeof │
├───────────┤
│ integer[] │
└───────────┘
(1 row)
postgres=# select pg_typeof('{100,200}'::_int8);
┌───────────┐
│ pg_typeof │
├───────────┤
│ bigint[] │
└───────────┘
(1 row)
复制Q2.备份锁等待问题
问题描述
客户使用备份软件进行备份时监控到备份过程中产生了锁,模拟截图如下:
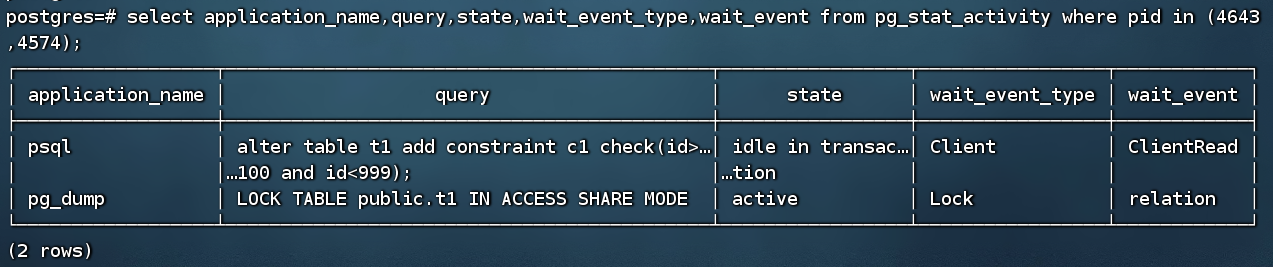
从截图中可以看到第一条alter语句对t1表进行结构修改,并且不提交,此时pg_dump备份到t1表时需要获取共享锁会等待。
另一种场景是pg_dump备份t1表数据过程中,有客户端对t1表进行结构修改,此时结构修改需要等待数据备份完成。
问题解答
针对第一种场景pg_dump备份可能阻塞在获取表的共享锁,可以设置锁等待超时,参考命令如下:
$ pg_dump -U postgres postgres -f t1.sql --lock-wait-timeout=5
复制等待超时后pg_dump报错退出备份:
pg_dump: error: query failed: ERROR: canceling statement due to statement timeout pg_dump: error: query was: LOCK TABLE public.t1 IN ACCESS SHARE MODE复制
第一种场景是先进行DDL结构修改,已经获取了锁资源。
第二种场景是后进行DDL结构修改,需要先从pg_stat_activity检测是否有其他客户端应用还在使用。
同时针对在线修改表约束,可以利用NOT VALID/VALID选项拆分多个步骤:先获取SHARE UPDATE EXCLUSIVE,再短暂获取ACCESS EXCLUSIVE LOCK,让整个过程更加可靠。
Q3.如何单独备份分区结构
问题描述
分区表结构如何一次性全部备份出来呢,比如需要在另外一个环境重建一样的表结构。
问题解答
使用pg_dump导出分区表的数据可以用load-via-partition-root选项使用父表作为目标表进行数据加载,可以通过父表规划数据。
使用pg_dump导出分区表的结构可以配置多个-t显式指定所有分区,另外一种方式是使用%通配符;
不过上面两种方案都不完美:要么表分区的数量并不是固化不发生改变,要么模糊匹配名可能与其他表名重叠。
即将发布版本16对pg_dump新增了"–table-and-children"选项,可以导出所有分区,包括声明式分区和继承表都适用。
$ /opt/pg16/bin/pg_dump -f xxx.sql -s --table-and-children=person
复制Tips: 低版本的server也可以使用这个特性,只要pg_dump客户端是16即可。
Q4.xml标签属性值转义问题
问题描述
在数据库里使用xpath函数解析xml时,观察如下几种场景:
- 场景一
postgres=# select (xpath('/正文','<?xml version="1.0" encoding="UTF-8"?><正文>这是正文</正文>'))[1];
┌───────────────────────┐
│ xpath │
├───────────────────────┤
│ <正文>这是正文</正文> │
└───────────────────────┘
(1 row)
复制xml的标签名称及标签内容如果是中文可以正常显示。
- 场景二
postgres=# select (xpath('/正文','<?xml version="1.0" encoding="UTF-8"?><正文 国家="china">这是正文</正文>'))[1];
┌────────────────────────────────────┐
│ xpath │
├────────────────────────────────────┤
│ <正文 国家="china">这是正文</正文> │
└────────────────────────────────────┘
(1 row)
复制xml标签的属性如果是中文可以也正常显示。
- 场景三
postgres=# select (xpath('/正文','<?xml version="1.0" encoding="UTF-8"?><正文 国家="中国">这是正文</正文>'))[1];
┌───────────────────────────────────────────────┐
│ xpath │
├───────────────────────────────────────────────┤
│ <正文 国家="中国">这是正文</正文> │
└───────────────────────────────────────────────┘
(1 row)
复制xml标签的属性值如果是中文,会被转义为十六进制Unicode码。
问题解答
在xml规范里,上面的转义字符标准叫法是Numeric Character Reference(NCR),直译为数字字符引用,简称为NCR。
NCR是为了方便浏览器网页方便解析xml或html,而不用考虑文件本身的编码,因为NCR字符只用到了ASCII字符集里的字符。
NCR使用的Unicode码支持以"&#“开头的十进制表示形式或”&#x"开头的十六进制形式,后面再跟一个分号组成。
NCR转义字符在浏览器或脚本语言javascript可以被正常解析:
<script type="text/javascript">
document.write(unescape("中国"))
</script>
复制编程语接口例如Python,也可以使用HTMLParser进行解析
$ python2
Python 2.7.5 (default, Oct 14 2020, 14:56:59)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from HTMLParser import HTMLParser
>>> print HTMLParser().unescape('中国')
中国
>>>
复制数据库也提供了unistr函数(新增于版本14)将unicode转义字符转化为可读的字符串:
postgres=# select unistr('\u4E2D\u56FD');
┌────────┐
│ unistr │
├────────┤
│ 中国 │
└────────┘
(1 row)
复制Tips: “&#x"替换为”\u"
