




一般情况下,OSS外表存储的数据是冷数据,数据量比较大,当单个CSV格式的数据文件过大时,对其进行查询会非常耗时。因此PolarDB支持单表多文件查询功能,您可以将单个OSS外表的数据文件拆分为多个小的数据文件,以加快查询速度。本文介绍了基于OSS外表的单表多文件查询的操作步骤。
前提条件
PolarDB集群版本需满足如下条件之一:
- PolarDB MySQL版8.0.1版本且修订版本为8.0.1.1.28及以上。
- PolarDB MySQL版8.0.2版本且修订版本为8.0.2.2.5.1及以上。
如何确认集群版本,详情请参见查询版本号。
操作步骤
- 拆分CSV文件。
- 您可以将CSV文件按行拆分为多个小的CSV文件,且单个CSV文件大小建议为128 MB,最大限制为1 GB。
说明 拆分CSV格式的文件时,必须按照完整的一行数据进行拆分,不能从一行数据中间进行拆分,需要保证每一个OSS数据文件的完整性。
文件命名规则如下:
- 使用OSS外表的建表语句
CONNECTION参数中配置的文件名称。如果该参数中没有配置文件名称,则数据文件名称为当前OSS外表的表名.CSV。示例如下:CONNECTION参数中已配置文件名称。
通过示例可以看出:OSS上的数据文件路径为create table t1 (id int) engine=csv connection="server_name/a/b/c/d/t1";oss_prefix/a/b/c/d/,数据文件名称为t1.CSV。CONNECTION参数中没有配置文件名称。
则数据文件名称为create table t1 (id int) engine=csv connection="server_name";t1.CSV。
需要拆分的数据文件名称 - 任意数字.CSV。示例如下:假设需要拆分的数据文件名称为
t1.CSV,则拆分后的文件名称为t1.CSV、t1-1.CSV和t1-2.CSV等。
- 使用OSS外表的建表语句
- 上传数据文件。
文件拆分后,您需要手动将所有的CSV文件上传到OSS上的同一路径下。此处以使用ossutil命令行工具批量上传CSV文件为例,关于ossutil命令行工具更多内容请参见ossutil。
其中,./ossutil64 cp localfolder/ oss://examplebucket/desfolder/ --include "*.CSV" -rlocalfolder为待上传的CSV文件的文件夹名称,oss://examplebucket/desfolder/为OSS上的CSV文件路径。使用过程中请根据实际使用场景进行替换。
- 您可以将CSV文件按行拆分为多个小的CSV文件,且单个CSV文件大小建议为128 MB,最大限制为1 GB。
- 添加OSS连接信息。
您可以通过创建OSS server来添加OSS连接信息。语法如下:
CREATE SERVER <server_name> FOREIGN DATA WRAPPER oss OPTIONS ( EXTRA_SERVER_INFO '{"oss_endpoint": "<my_oss_endpoint>","oss_bucket": "<my_oss_bucket>","oss_access_key_id": "<my_oss_access_key_id>","oss_access_key_secret": "<my_oss_access_key_secret>","oss_prefix":"<my_oss_prefix>","oss_sts_token":"<my_oss_sts_token>"}' );说明
- PolarDB MySQL版为8.0.1版本且修订版本为8.0.1.1.29及以上,或PolarDB MySQL版为8.0.2版本且修订版本为8.0.2.2.6及以上时,支持使用
my_oss_sts_token参数。 - 该语法支持
DATABASE参数,若您创建的OSS server中既存在DATABASE参数,又存在my_oss_prefix参数,则最终查找文件的路径为my_oss_prefix/DATABASE。请保证在该语法中配置的数据文件路径与拆分文件中上传到OSS上的数据文件路径一致。
参数名称 参数类型 参数说明 server_name 字符串 OSS server名称。 说明 该参数为全局参数,且全局唯一。该参数不区分大小写,最大长度不超过64个字符,超过64个字符的名称会被自动截断。您可以将OSS server名称指定为带引号的字符串。
my_oss_endpoint 字符串 OSS对应区域的域名。 说明 如果是从阿里云的主机访问数据库,应该使用内网域名(即带有“internal”的域名),避免产生公网流量。
例如:
oss-cn-xxx-internal.aliyuncs.commy_oss_bucket 字符串 数据文件所在OSS的bucket,需要通过OSS预先创建。 说明 OSS的bucket和PolarDB最好在同一个可用区内,以减少两者之间的网络延迟。
my_oss_access_key_id 字符串 OSS账号的AccessKey ID。 my_oss_access_key_secret 字符串 OSS账号的AccessKey Secret。 my_oss_prefix 字符串 当前CSV格式的数据文件在OSS中的路径。 my_oss_sts_token 字符串 OSS临时访问凭证。获取OSS临时访问凭证详情请参见获取临时访问凭证。 说明
my_oss_sts_token参数值有默认的过期时间。如果my_oss_sts_token已过期,您需要通过以下命令重置EXTRA_SERVER_INFO中的全部参数值。ALTER SERVER server_name OPTION(EXTRA_SERVER_INFO '{"oss_endpoint": "<my_oss_endpoint>", "oss_bucket": "<my_oss_bucket>", "oss_access_key_id": "<my_oss_access_key_id>", "oss_access_key_secret": "<my_oss_access_key_secret>", "oss_prefix":"<my_oss_prefix>", "oss_sts_token": "<my_oss_sts_token>"}');说明
- 创建OSS server时需要SERVERS_ADMIN权限,您可以通过
show grants for 当前用户命令查看当前用户是否具有SERVERS_ADMIN权限。目前,高权限账户默认具有该权限,并且高权限账户可以给低权限账户赋予该权限。 - 如果您是高权限用户,可以通过
SELECT Server_name, Extra_server_info FROM mysql.servers;命令查看您创建的OSS Server信息,且oss_access_key_id和oss_access_key_secret参数信息因为涉及安全信息会被加密处理,无法查看其详细信息。
- PolarDB MySQL版为8.0.1版本且修订版本为8.0.1.1.29及以上,或PolarDB MySQL版为8.0.2版本且修订版本为8.0.2.2.6及以上时,支持使用
- 创建OSS外表,具体请参见创建OSS外表。外表创建成功后,PolarDB会根据您设定的路径,查找对应的文件。
- 数据查询。
以上述步骤示例中的
t1表为例进行说明。
查询数据的过程中,常见的报错信息及报错原因请参见下表:#查询t1表内的数据数量 SELECT count(*) FROM t1; #范围查询 SELECT id FROM t1 WHERE id < 10 AND id > 1; #点查 SELECT id FROM t1 where id = 3; #多表join SELECT id FROM t1 left join t2 on t1.id = t2.id WHERE t2.name like "%er%";说明 如果在查询数据的过程中,没有报错信息但有警告信息时,您需要通过
SHOW WARNINGS;命令查看报错信息。报错信息 报错原因 解决方案 OSS error: No corresponding data file on the OSS engine. OSS上没有找到对应的数据文件。 您需要根据上述规则检查OSS上对应的路径下是否存在数据文件。 - 若存在,确认数据文件格式是否符合命名规则。即符合
外表名.CSV,且文件名后缀CSV必须为大写格式。 - 若不存在,则需要将数据文件上传至目标路径。
There is not enough memory space for OSS transmission. Currently requested memory %d. 没有足够的空间进行OSS查询。 您可以通过以下两种方式中的任意一种来修复该错误: - 在控制台的参数配置中通过修改
loose_csv_max_oss_threads参数值来运行更多的OSS线程。 - 通过flush table关闭某些OSS表的线程。
ERROR 8054 (HY000): OSS error: error message : Couldn't connect to server.Failed connect to aliyun-mysql-oss.oss-cn-hangzhou-internal.aliyuncs.com:80; 当前的数据库实例无法连接OSS服务器。 检查当前的数据库实例与OSS bucket是否在同一个可用区。 - 如果不在同一个可用区,则需要将当前的数据库实例与OSS bucket放在同一个可用区。
- 如果在同一个可用区,您可以将endpoint修改为公网的endpoint。如果endpoint修改后仍然报错,请联系阿里云技术支持解决。
- 若存在,确认数据文件格式是否符合命名规则。即符合
- (可选)增加新的数据文件。
如果您需要上传新的数据文件,并在
t1表中读取该文件中的数据,您可以执行步骤1上传目标文件,上传完成后,对t1表执行以下操作,即可使用查询命令查询新上传文件中的数据。FLUSH table t1;
查询优化
说明 仅支持PolarDB MySQL版8.0.2版本且修订版本为8.0.2.2.5.1及以上的版本使用该功能。
创建了多文件的OSS外表之后,PolarDB会预先扫描OSS上当前表的数据文件,得到总行数的估计值,基于代价启动一定数量的worker,将多个OSS数据文件分给不同的worker进行并行扫描,以此来加快扫描速度。其原理图如下所示: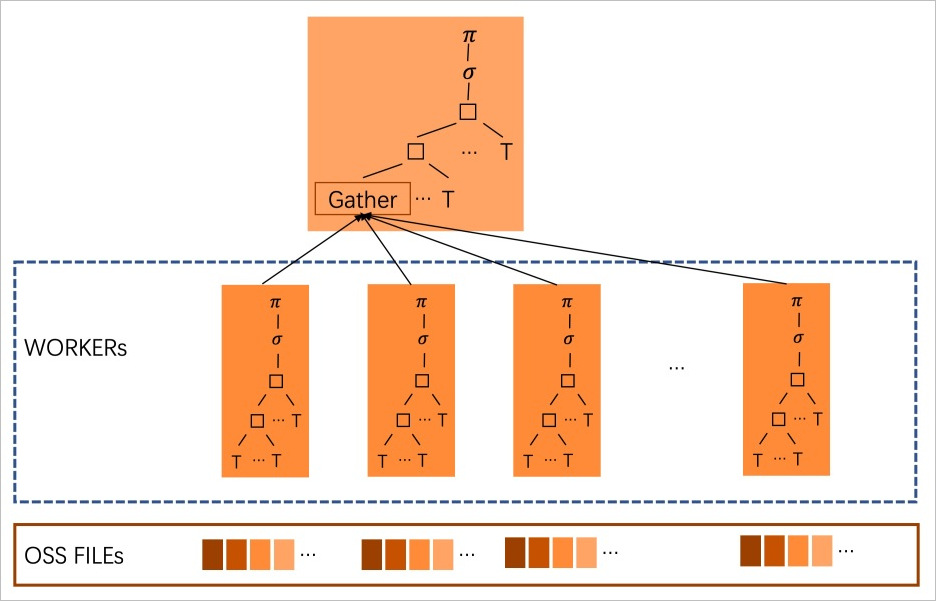
- 开启并行查询功能,具体请参见概述。
- 开启CSV引擎的并行扫描开关。
CSV引擎的并行扫描开关
loose_csv_parallel_scan_enabled默认关闭,您需要在控制台的参数配置中将其设置为ON,具体请参见设置集群参数和节点参数。CSV引擎的并行扫描开关开启后,您可以通过EXPLAIN命令查看当前表的执行计划。如果当前表的行数较多,就可以看出当前的执行计划是并行查询。示例如下:
查询结果如下:EXPLAIN select * from t;EXPLAIN select * from t; +----+-------------+-------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------+ | 1 | SIMPLE | <gather1.1> | NULL | ALL | NULL | NULL | NULL | NULL | 15000 | 100.00 | NULL | | 1 | SIMPLE | t | NULL | ALL | NULL | NULL | NULL | NULL | 3750 | 100.00 | Parallel scan (4 workers) | +----+-------------+-------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------+ 2 rows in set, 1 warning (0.01 sec) - 增加OSS允许并行的线程数量。
每一个OSS worker需要一定的内存来存储从OSS中读取的数据,且当前PolarDB默认的同时允许存在的OSS线程数量为1。
您可以通过在控制台的参数配置中修改
loose_csv_max_oss_threads参数值来增加OSS允许并行的线程数量,且保证该参数值大于步骤2中通过EXPLAIN命令查询到的worker数+1。如果您设置的loose_csv_max_oss_threads参数值小于或等于通过EXPLAIN命令查询到的worker数+1,PolarDB会报错,报错信息如下:There is not enough memory space for OSS transmission. Currently requested memory <%d>.说明
- 每一个OSS worker默认占用的内存为128 MB,您需要保证系统中有足够的内存空间来启动多个OSS worker。且使用OSS功能时,OSS占用的总内存尽量不要超过当前节点内存的5%,否则可能会出现内存溢出问题。OSS功能占用的总内存最大为:
您可以在控制台的参数配置页面查看loose_csv_max_oss_threads * loose_csv_oss_buff_sizeloose_csv_oss_buff_size和loose_csv_max_oss_threads参数值,参数详情请参见参数说明。 - 如果您需要修改单个worker占用的默认内存大小,可以在控制台的参数配置页面通过修改
loose_csv_oss_buff_size参数值来调整。
- 每一个OSS worker默认占用的内存为128 MB,您需要保证系统中有足够的内存空间来启动多个OSS worker。且使用OSS功能时,OSS占用的总内存尽量不要超过当前节点内存的5%,否则可能会出现内存溢出问题。OSS功能占用的总内存最大为:
