




一、现象描述
这是一个之前遇在从10G迁移数据到19C时遇到的一个问题。
在10G到19C开始OGG同步前,先将目标端19C的job_queue_processes设置为0,以防止在数据导入过程中因有JOB执行导致启动一些任务引起数据混乱。目前10G到19COGG已开启OGG同步,两端数据同步正常。
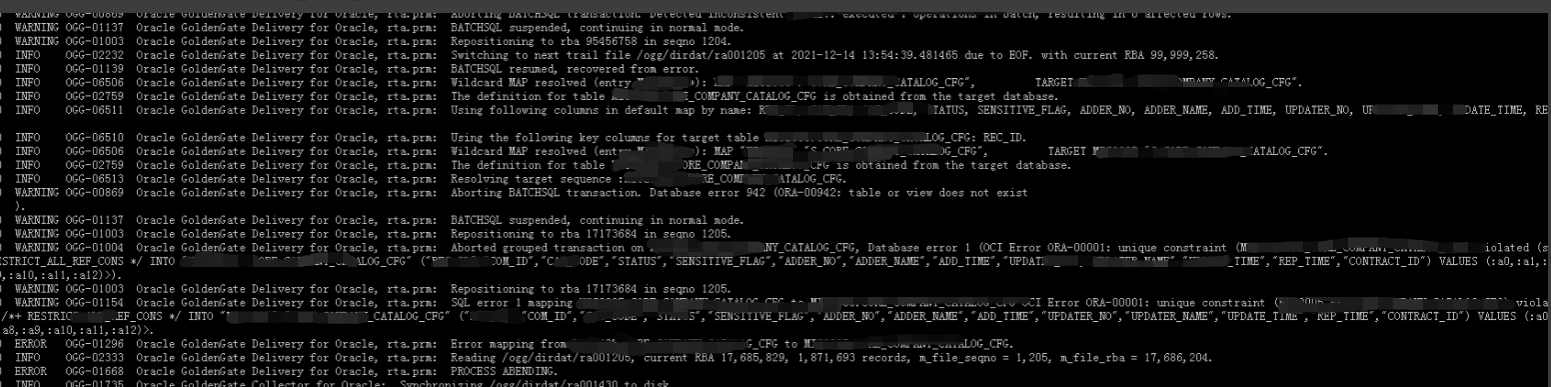
尝试将19C目标端job_queue_processes值重新恢复到初始值640,之后过了几分钟,发现19C目标端OGG应用进程APPENDING,现象如下:

二、处理过程
查看到目标端应用进程APPENDING后,迅速排查问题,潘工通过日志发现是因为目标端在开启job_queue_processes这段时间内,有JOB任务执行,导致源端和目标端结构发生混乱,产生了异常数据,导致了这个1403 这个比较经典的报错,这
时就无法再如过去将源端和目标端抽取、投递及应用进程按照目标端心跳表SCN号重新配置就能解决,因为该问题比较复杂,难以排查出在开启job_queue_processes这段时间内还有哪些JOB执行了。因为目前还是测试阶段,此时可以通过在目
标端OGG应用进程里设置REPERROR (1403, DISCARD)参数跳过1403报错,重新启动同步。重新启动应用进程后,过了一段时间,OGG同步又APPENDING,排查原因是因为目标端表中检测有重复值,在目标端应用进程里设置HANDLECOLLISIONS可以跳过此报错。
一、结论
此事给自己的教训就是:OGG同步过程中,勿轻易设置目标端job_queue_processes,最好是修改为0,除非是排查到具体那些JOB,然后将其停了,才可修改该值,否则会导致同步过程中一些利问题。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
文章被以下合辑收录
评论
TA的专栏
热门文章
Elasticsearch运维篇_ES启动失败常见问题及解决办法整理
2023-05-09 14442浏览
Centos 7 静默安装Oracle 11.2.0.4 单机版安装指南
2023-05-24 7568浏览
达梦数据库初始化数据库需特别注意的几个参数
2022-11-08 6800浏览
记一次Oracle数据库SQL执行超时产生ORA-609报错导致进程被abort问题分析及处理
2022-11-29 5434浏览
ORA-1652: unable to extend temp segment by 128 in tablespace导致流复制中断影响数据同步问题分析
2022-11-22 5413浏览
最新文章
企业版 YashanDB 23.2.4 分布式集群 数据库一主二备集群安装部署指南
2024-12-23 354浏览
企业版 YashanDB 23.2.4 YAC 单库多实例架构多活共享集群安装部署指南
2024-12-23 247浏览
打工人的心声:眼花缭乱的世界,疲惫的心和不安的未来
2024-12-05 171浏览
[【ClickHouse 运维系列】ClickHouse 集群从 22.5.1.2079 滚动升级到 24.8.6.70 流程步骤
2024-12-02 265浏览
金仓数据库 KingbaseES V9 详解:目录结构与配置文件 (上)
2024-11-27 278浏览
目录
