




背景:
监控平台收到告警(【一体化运维平台】:告警名称:/ 文件系统分区使用率连续3次大于等于85%且小于95% 告警时间:2023-07-05 06:26:49)
思路:
1、通过堡垒机进入Oracle数据库,发现根目录空间使用率达到85%,剩余200G。
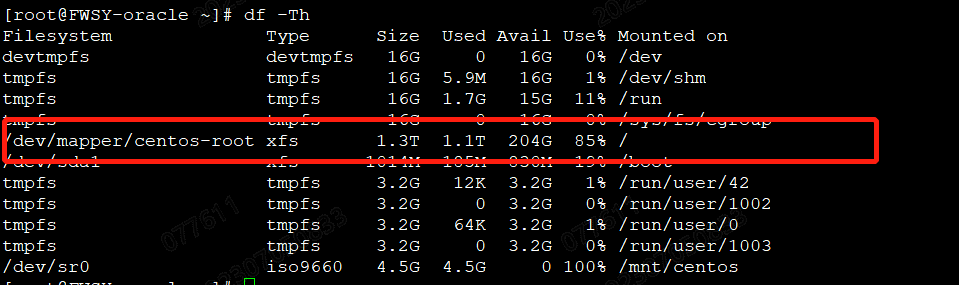
2、进入根目录,查看具体是哪个目录占空间大(大概率是归档日志满了)。du -sh * (定位问题的关键步骤),最终发现是归档目录特别大。
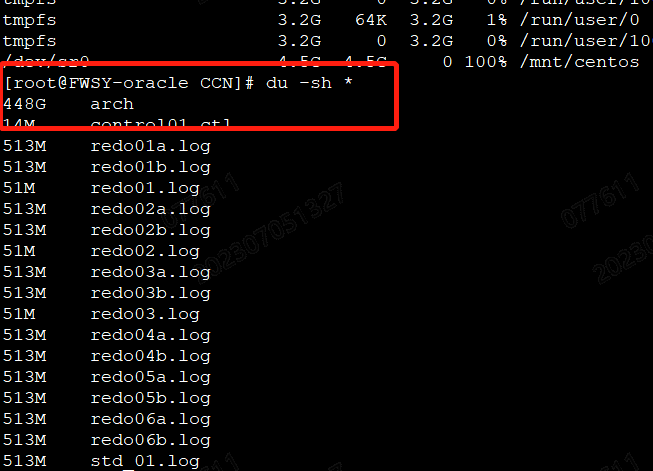
4、决定手动删除归档日志。但是有一个问题,该数据库早已接入爱数备份平台,该平台会有删除归档日志的策略,但是未生效,后续需要排查失效原因。
1、delete noprompt archivelog until time 'sysdate-7' backed up 1 times to sbt;(爱数平台删除归档日志命令)
2、DELETE ARCHIVELOG ALL COMPLETED BEFORE 'SYSDATE-7';(一般命令删除归档日志)
3、delete noprompt force archivelog all completed before 'sysdate-7;(命令加force,强行删除一周前的归档日志)
前两个都报错了,删除归档失败,报错原因一样,决定使用第三种删除方式(成功删除)。
信息 RMAN-08137: WARNING: archived log not deleted, needed for standby or upstream capture process
解决问题:
1、经过爱数人员排查,发现Oracle是DG,经过多方确认,确定是DG(判断是否是DG的方法:https://www.cnblogs.com/avasteven/p/13141306.html)。DG是需要使用归档日志同步到备库的,所以会导致一般的删除归档命令失效。
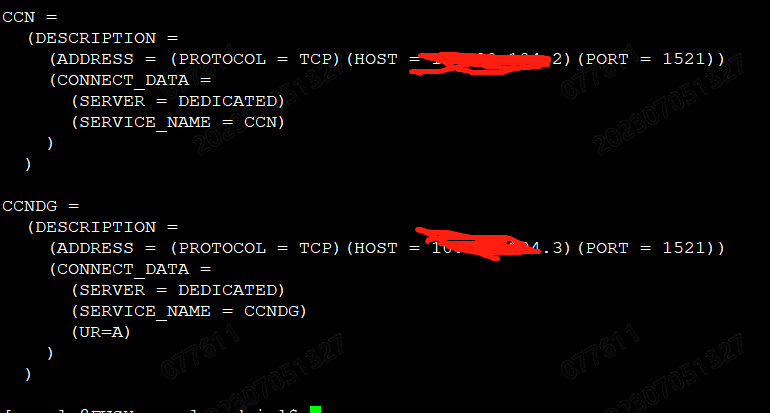
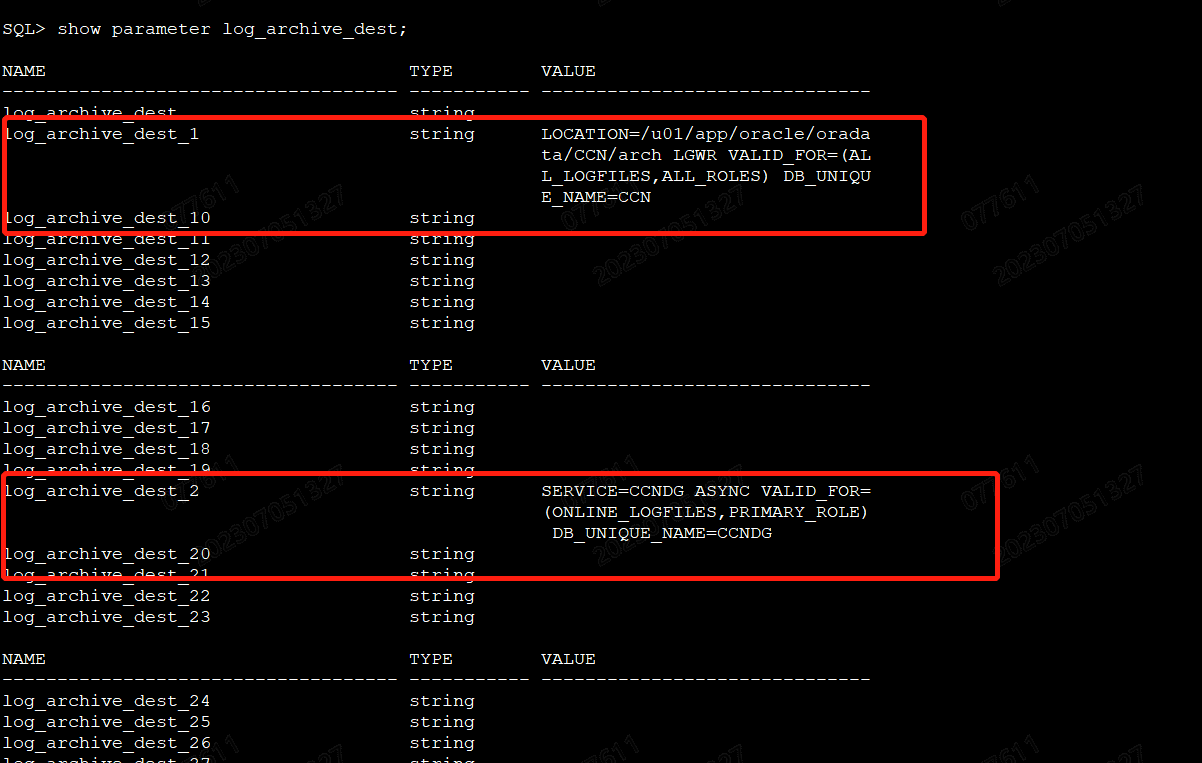
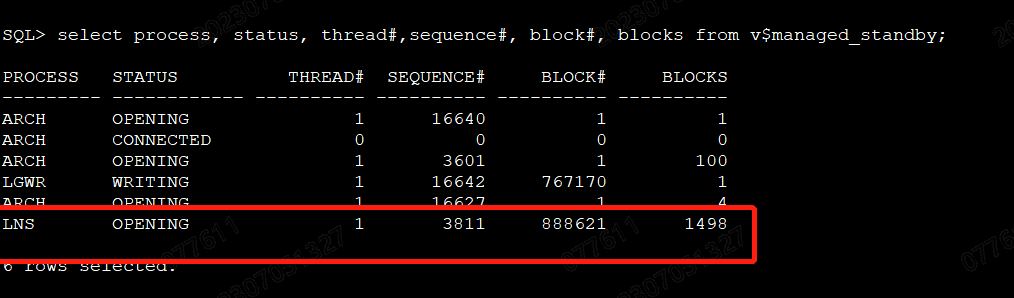
2、既然已经强制删除了一周前的归档日志,我们看看DG的状态是否正常(dataguard环境下判断主从数据同步是否正常:https://blog.csdn.net/weixin_41561862/article/details/104185660),根据需要做出适当调正,原则是不能影响数据库正常运行,不能影响业务。
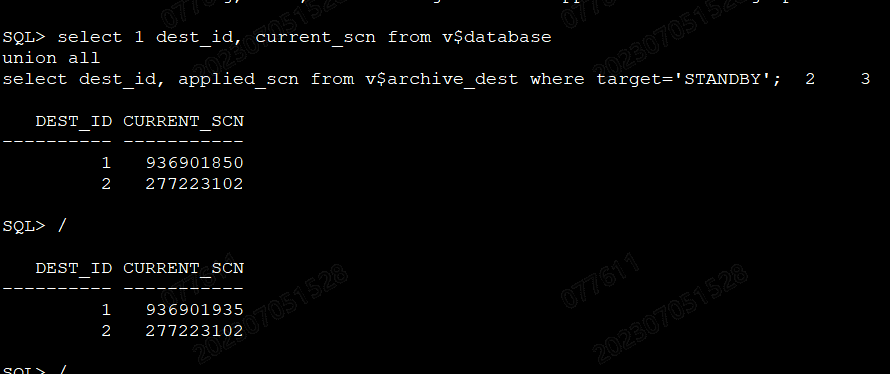
如果主库、备库的scn一直在变,并且很接近,说明备库日志恢复正常。--看来备份日志不正常。

status=VALID 则归档位置正常;不正常的情况下,error字段会给出错误原因。
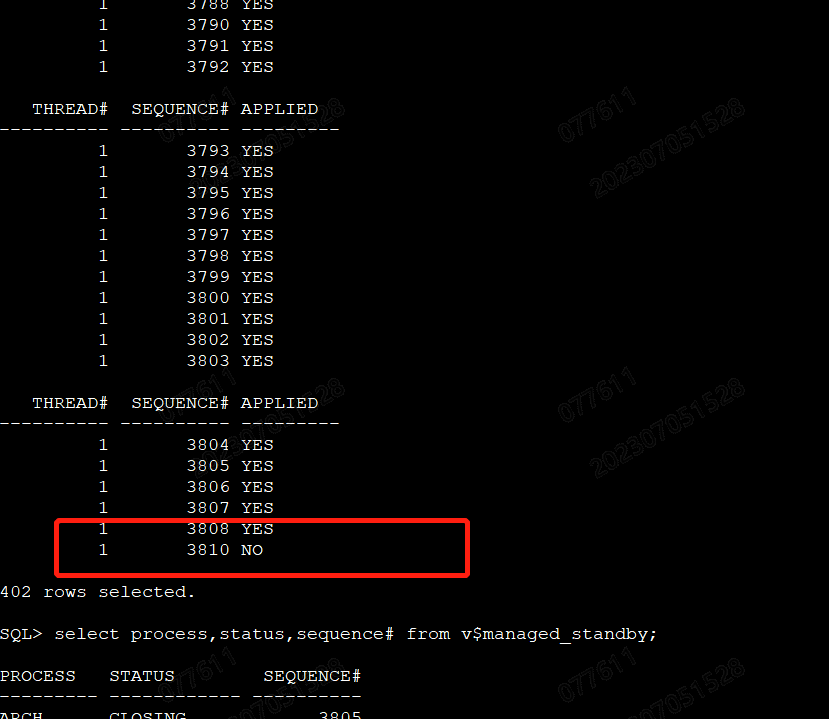
select thread#,sequence#,applied from v$archived_log;
查看applied的结果,如果是YES 最后为IN-MEMORY 表示数据已经应用。
如果 结果中出现NO,表示数据同步已经出现延迟,要明确是未来得及应用还是同步中断。--少了3809,应该是同步中断。
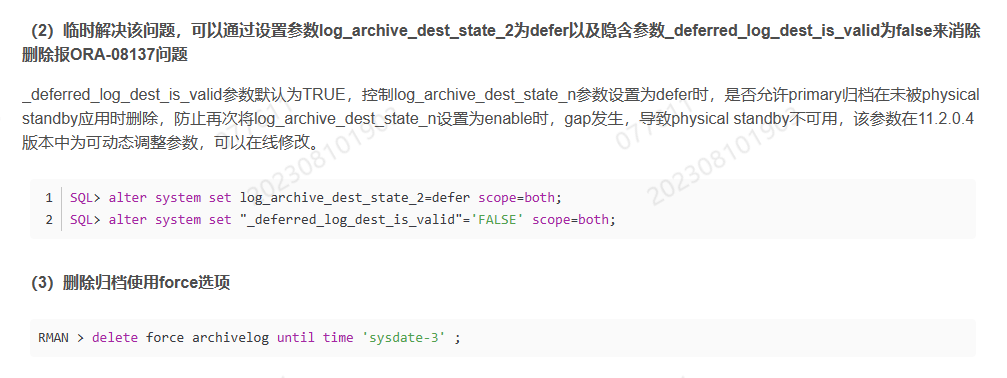
这个问题后续处理(2023-08-11获得处理,步骤如下图,亲测有效)。
结论:
手动强制删除归档日志(加force)有风险,要明确数据库架构,判断是单机/DG/RAC后再操作。
评论

 0 点赞
0 点赞 0 点赞
0 点赞


