




作者:陈梓麟 RisingWave Labs 内核开发工程师
1背景
Join在流处理中是一个常见的操作,它可以将两个或更多的数据流按照某种关联条件合并到一起。这对于那些需要同时分析和理解多个数据源的实时数据的情景特别有用。以下是一些常见的使用流处理Join的应用场景[1]:
实时广告效果监控:在实时广告系统中,广告展示和用户点击会被实时地记录和收集。我们可以使用流处理来实时处理这些数据,并使用 Join 操作,按广告 ID 和用户 ID 合并广告展示数据和用户点击数据。这样,我们可以实时计算每个广告的点击率,以便实时监控广告效果。 服务器集群性能异常检查:集群监控系统通过采集服务器网卡设备监控指标与 TCP 协议层性能监控指标,通过 Join 展示,找到有异常流量的网卡上对应所有的 TCP 监控指标信息。 实时推荐系统:电商平台可能需要将用户行为数据(如点击、购买)和商品信息进行join,以便实时地为用户提供个性化的商品推荐。 金融交易风控:银行或金融机构可能需要将交易数据和用户风险评级数据进行 join,以便实时地进行交易风险评估。 ETL场景:流处理系统处理上游来自不同数据源(例如 Kafka,Database)的数据,并通过 Join 将不同数据源打宽成大宽表再写入下游数据分析系统。
RisingWave 作为一个分布式的流数据库,针对 Join 这一重要的流处理算子做了不少技术上的探索与优化,下面将会为大家逐一介绍。
2流处理Join的特点
RisingWave对于查询的处理可以分为两大类,一类称为是Streaming Query,另外一类称为Batch Query。其中Batch Query对Join的处理方式和传统数据库的原理是一样的,处理的输入都是有界限的(bounded)数据集。而Streaming Query主要的表达形式是CREATE MATERIALIZED VIEW
,Streaming Query的Join需要处理流上无界限(unbounded)的数据流。流上Join的两个上游输入有任何数据变更都需要增量地计算出Join的变更结果输出到下游。Join是一个重状态的算子,如何管理Join的状态也成了流数据库中非常重要的课题。
3Symmetric Hash Join
业界通用的流处理Join使用的算法基本上都是Symmetric Hash Join[2](需要有等值连接条件),它的思想很简单,主要是为Join的两边输入各自维护一个Hash表(Hash key为Join key)。每当一边有输入过来时,先插入自己的Hash表,再去查一下另外一边的Hash表并计算出Join的输出结果。不难看出这里的两边输入是对等(Symmetric)的关系。其中的Hash表也称为Join的状态(State)。
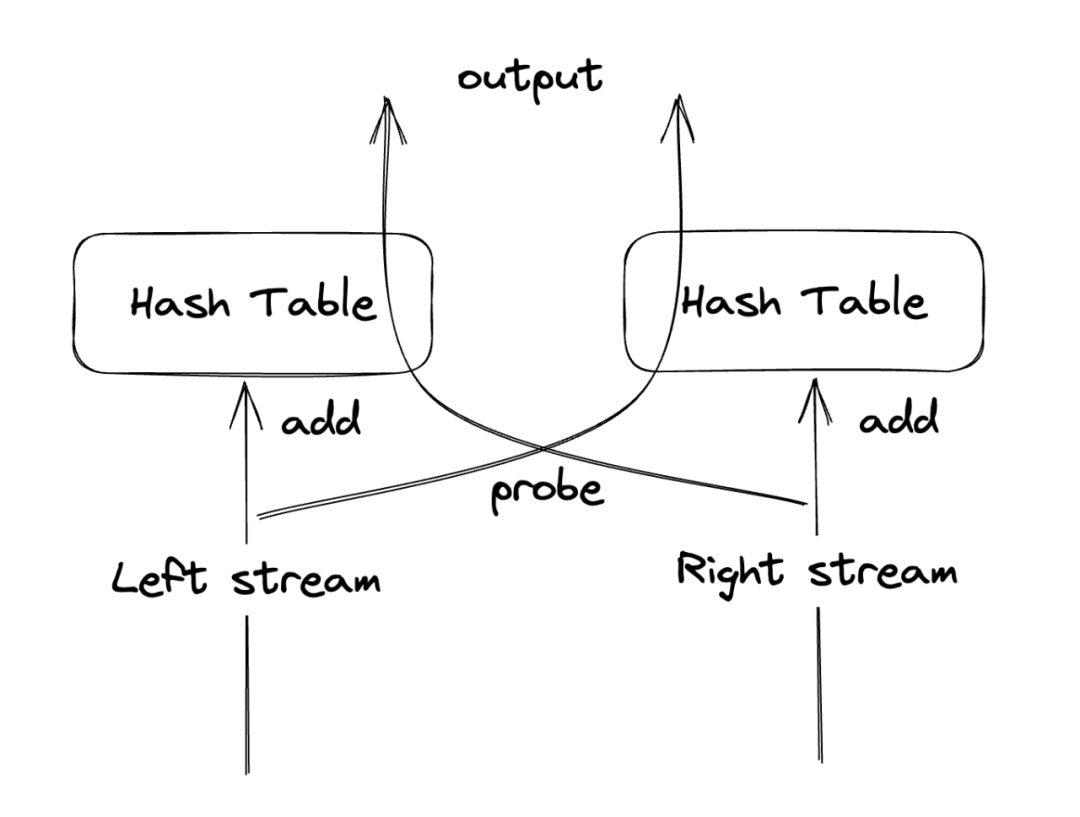
4Unbounded state
由于Join输入是unbounded的,可以推导出Join的状态也是unbounded的。显然这会导致存储上的问题。RisingWave通过存算分离的架构,可以把Join的状态存储到对象存储(Object store)当中。对象存储相比于传统的本地存储有诸多优点,例如容量扩展性高,可靠性高,成本效益更经济。理论上Risingwave的存储容量上限跟对象存储的容量上限是一样的。当然为了弥补对象存储访问延迟较高的问题,Risingwave会利用内存和本地盘来缓存对象存储的文件,并通过LRU策略管理这些缓存。之前我们有文章专门介绍存储针对流处理状态的写入读取的优化,点这里阅读。
5Watermark & Window
即使Join的输入可能是unbounded的,但很多时候我们不希望Join的状态大小也是Unbounded的。通过水位线和窗口Join技术可以将Join状态控制在一个有限的大小之内。流上的数据一般是没有严格顺序的,但是通过定义Watermark,我们可以得到一个相对有序的流[3]。例如我们可以个Source流上的时间列设置一个Watermark限制为-20s,代表当目前看见流数一行数据的时间列的时间戳为T时,意味着时间戳为T-20s的所有数据都已经到达。有了这个保证,我们可以在流上传递一个Watermark的消息,用来表示Watermark消息之后所有的数据的时间戳都是大于T-20s的。这样我们就可以在流上表达相对有序这个属性。
-- 定义一个具有Watermark的Source
CREATE SOURCE s1 (
id int,
value int,
ts TIMESTAMP,
WATERMARK FOR ts AS ts - INTERVAL '20' SECOND
) WITH (connector = 'datagen');
有了相对有序的属性我们就可以结合窗口(Window)来限制Join状态的空间大小。窗口在流处理上一般是通过TUMBLE或者HOP Window函数的方式为数据划分时间窗口,如果划分的时间字段带有Watermark信息,那么经过窗口函数后优化器也可以进一步推导出窗口时间列的Watermark信息。Window Join顾名思义,是在窗口中做Join,Join的连接条件要求左右输入的窗口时间列有等值关系。由于Watermark的存在,窗口不断地往前推进,已经做完Join的窗口中的状态便可以被清理。这样我们就可以有效的控制Join状态的大小。
CREATE SOURCE s2 (
id int,
value int,
ts TIMESTAMP,
WATERMARK FOR ts AS ts - INTERVAL '20' SECOND
) WITH (connector = 'datagen');
-- 创建使用Window Join的物化视图
CREATE MATERIALIZED VIEW window_join AS
SELECT s1.id AS id1,
s1.value AS value1,
s2.id AS id2,
s2.value AS value2
FROM TUMBLE(s1, ts, interval '1' MINUTE)
JOIN TUMBLE(s2, ts, interval '1' MINUTE)
ON s1.id = s2.id and s1.window_start = s2.window_start;
6Interval Join
假如你正在处理的是用户的点击流数据,你可能想要连接用户的点击事件和他们的购买事件,但是这两个事件可能不会在严格的窗口期间内发生。在这种情况下,使用 Interval Join [4]就会更加合适。Interval Join允许两个事件在一定的时间间隔内连接,而不是在严格的窗口期间内。可能你会说,我们可以使用普通的Symmetric Hash Join来处理,去掉Interval的时间限制条件也可以。但我们在流处理Join上面的一个目标是控制Join状态的大小,而通过Interval Join我们可以利用输入流的Watermark信息用于清理过期(确定不会再被Join上)的状态。Interval Join的语法如下,它需要在Join条件上加入左右两边流时间列上的范围约束条件。
-- 创建使用Interval Join的物化视图
CREATE MATERIALIZED VIEW interval_join AS
SELECT s1.id AS id1,
s1.value AS value1,
s2.id AS id2,
s2.value AS value2
FROM s1 JOIN s2
ON s1.id = s2.id and s1.ts between s2.ts and s2.ts + INTERVAL '1' MINUTE;
7Temporal Join
上面我们提到的Join对两边输入都是对等处理的,而对等处理需要付出比较高的代价,例如我们需要给两边的输入都维护对应的Hash Table作为状态。而传统数据库中的Hash Join只需要选择一边建立Hash Table。为了提高性能,一个思考方向是打破对Join两边输入的对等关系。Risingwave提供Temporal Join [5],它可以将一边流Join一个Risingwave内部表或者物化视图,流的一边可以不再维护状态,当有数据过来时,可以直接查询另外一边的表,同时表则充当了Join状态本身。可以看到在这种模式下Temporal Join本身是不再需要维护任何状态的,它的效率会变得非常高。但天下没有免费的午餐,Temporal Join中表这一侧的任何数据变更都不像前面Symmetric Hash Join那样可以影响到之前Join的输出结果上。同时为了保证系统的一致性,它要求流的一侧是Append Only的。Append Only意味着这个数据流只能是Insert,不能带有Update,Delete。接下来我们看看Temporal Join的语法,它包含了特殊的FOR SYSTEM_TIME AS OF PROCETIME()
的语法,这是因为Risingwave中同样的SQL在Batch Query和Streaming Query中得到结果是需要保持一致的。但Temporal Join的出现使得无发用普通的SQL来表达这样的结果,因此需要使用特殊的语法来表示。
-- 创建Table
CREATE table t1 (
id int primary key,
value int
);
-- 创建使用Temporal Join的物化视图
CREATE MATERIALIZED VIEW interval_join AS
SELECT s1.id AS id1,
s1.value AS value1,
t1.id AS id2,
t1.value AS value2
FROM s1 JOIN t1 FOR SYSTEM_TIME AS OF PROCTIME()
ON s1.id = t1.id;
8Join Ordering
当提到Join的时候,不得不提及的一个问题是Join Ordering。传统数据库中针对Join Ordering的优化文献浩如烟海,其中很重要的一个思想是利用CBO(Cost Based Optimizer)来枚举执行计划搜索空间, 利用表的统计信息,估算每个算子的需要处理的数据量,计算出执行计划的代价,最后采用估算代价最低的执行计划。但是在流数据库中,Join的输入是实时不断有输入的流,而不是可以提前知道数据量和数据分布的静态数据集。有Paper提出了Rate-based [6]的Join Ordering,主要思想是利用输入流的速率来估算经过Join后输出流的速率,然后找到最大化输出平均速率的Join Order。
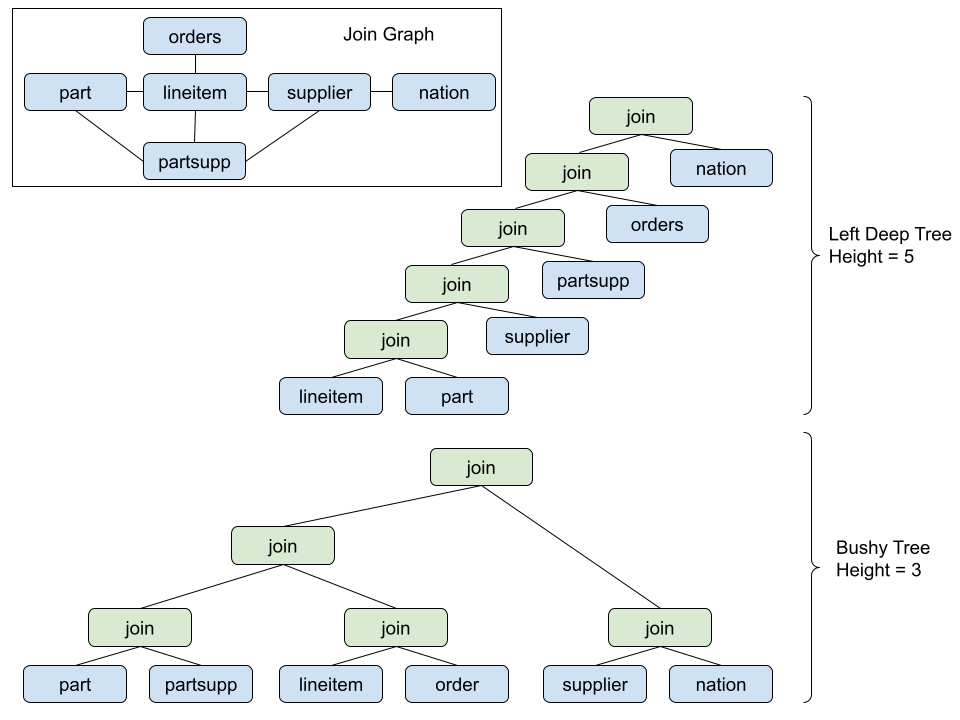
有兴趣的读者可以细读一下论文,这里我给出一些结论。结论是直接精确计算输出平均速率的代价会比较高,因此需要一种启发式的算法来取得效果与优化速度的平衡。另外把速率比较快的流放在离Join输出最近,最远,中间都可能是最优的,取决于Join Tree的形状。但比较有意思的点是Bushy Tree的形状比Left Deep Tree的形状似乎更适合流处理。仅仅形状上分析,可以看出Bushy Tree可以让数据并行地流过整个Join,同时相比于Left Deep Tree它的一条数据从下往上Join,Latency更低。我们也做个一些实验验证了确实Bushy Tree可以更好地利用资源,提高吞吐和降低延迟。因此Risingwave目前使用的Join Ordering算法是**尽量地将这棵树变成Bushy Tree并使得它的树高最低[7]**。最后还想说的一点是不是所有的Join都能变成Bushy Tree,很多情况下用户写的SQL就是很多的Left Join串成的Left Deep Tree形状的,这种时候是无法优化成Bushy Tree形状的,所以在限定了Left Deep Tee形状的情况下,更优做法是把速率快的流放得离输出更近。
下图为TPCH Q9的Join Graph及Left Deep Tree和Bushy Tree的比较:
9更多
子查询
上面提及的很多Join都是Inner Join或者Outer Join,实际上在Join实现上RisingWave还支持SemiJoin和AntiJoin,只不过这两个类型的Join不能直接通过Join语法写出,而是需要以相关联子查询的形式表达出来。RisingWave的子查询Unnesting技术是按照Paper:Unnesting arbitrary queries [8]来实现的。所有的子查询都会被转成Apply算子,并将Apply算子不断往下推直到所有关联项都被改写成普通引用后就可以转成Join。因此在RisingWave的Streaming Query中子查询也被看成是Join的一种表达。
NestedLoop Join
上文提及到的Join都是带有等值连接条件的,但是对于不包含任何非等值条件的Join,我们显然就无法使用Symmetric Hash Join了。同时NestedLoop Join目前在RisingWave的Streaming Query中是被禁止的,因为在流处理中它的效率非常的低下,可以想象一下,Join流的任意一侧有变更都需要与另外一侧的所有数据做一遍比较才能得到增量的结果。
但有些特殊类型的非等值连接条件的Join实际上可以做到比较的高效,在Risingwave中有一个特殊的算子被称为Dynamic Filter [9],最初被提出是用于解决TPCH Q11这种带有非关联子查询而产生的NestedLoop Join的场景。特别之处在于这个Join的一侧只有一行(由不带Group by的Agg)不断在变的数据,Join的关联条件是一个范围条件。在这种情况下左右两侧数据的变化都可以通过一个比较小的范围查询来实现高效的增量算法,有兴趣的同学可以去看看对应的RFC。
Delta Join
通过前文我们可以了解到Join是一个重状态的算子,每个Join有需要维护自身的Join状态。那如果有多条SQL都使用了同一个表输入,并且Join Key都一样,我们可以复用它的状态,之前我们也有相关的文章在这里就不过多介绍,感兴趣的读者可以在这里阅读[10]。
与Join相关但没做的
Multi-Way Joins
前文提及的Join都是假定每个Join算子是Binary的,也就是说输入只有两个,但我们需要做N个输入Join的时候我们就会有N-1个Join算子,而Multi-Way则是一个Join算子可以有多个输入。传统数据库中实际上Binary Join已经在绝大部分场景都能做到很好,只剩下一些很特别的场景例如:使用BInary Join的中间结果可能会出现放大。这些特殊场景可以留给Multi-Way Joins优化[11]。而Multi-Way Joins对流数据库的优势应该是可以降低Join的Latency,原理是原来在好几个算子才能Join完的结果,现在可以在一个Multi-Way Joins算子中完成。但这个Multi-Way Joins没有对Streaming很友好的Scale方式,要么所有流都得汇聚到一个节点上完成计算,要么通过Broadcast方式N-1个流广播到另外一个Hash的流上,要么是引入更为复杂的HyperCube Shuffle。
快慢流
流上的数据是有快有慢的,对于Join来说两边输入的流如果一边速率非常的快,一个边速率很慢,我们是不是可以利用这种非对称性,在Join状态的数据结构上也适应这种非对称性?有Paper [12]研究在快流一侧不做Hash表的索引,慢流一侧才做Hash表索引来利用这种非对称性。
10总结
RisingWave 是一个云原生 SQL 流式数据库,并针对流处理Join做了大量状态管理、复用、以及性能优化。本文介绍了RisingWave的Join的使用场景,流处理Join的基本原理,以及Join状态的特点。同时介绍了如何使用Watermark来控制Join状态的大小。RisingWave提供Symmetric Hash Join、Interval Join、Temporal Join、Delta Join等面向用户的Join Features。RisingWave有专门针对流处理的场景Join Ordering优化,一套完善的子查询Unnesting优化技术将子查询转换成Join,和针对特殊NestedLoop Join场景的Dynamic Filter优化。
11Reference
https://www.risingwave.dev/docs/current/real-time-ad-performance-analysis Xie J, Yang J. A survey of join processing in data streams[J]. Data Streams: Models and Algorithms, 2007: 209-236. https://github.com/risingwavelabs/rfcs/pull/2 https://github.com/risingwavelabs/rfcs/pull/32 https://github.com/risingwavelabs/rfcs/blob/main/rfcs/0049-temporal-join.md Viglas S D, Naughton J F. Rate-based query optimization for streaming information sources[C]//Proceedings of the 2002 ACM SIGMOD international conference on Management of data. 2002: 37-48. https://github.com/risingwavelabs/rfcs/blob/main/rfcs/0023-minimize-height-join-ordering.md Neumann T, Kemper A. Unnesting arbitrary queries[J]. Datenbanksysteme für Business, Technologie und Web (BTW 2015), 2015. https://github.com/risingwavelabs/rfcs/blob/main/rfcs/0033-dynamic-filter.md https://zhuanlan.zhihu.com/p/607054467 Freitag M, Bandle M, Schmidt T, et al. Adopting worst-case optimal joins in relational database systems[J]. Proceedings of the VLDB Endowment, 2020, 13(12): 1891-1904. Kang J, Naughton J F, Viglas S D. Evaluating window joins over unbounded streams[C]//Proceedings 19th International Conference on Data Engineering (Cat. No. 03CH37405). IEEE, 2003: 341-352.

