






►►►
状态算子的解析和优化
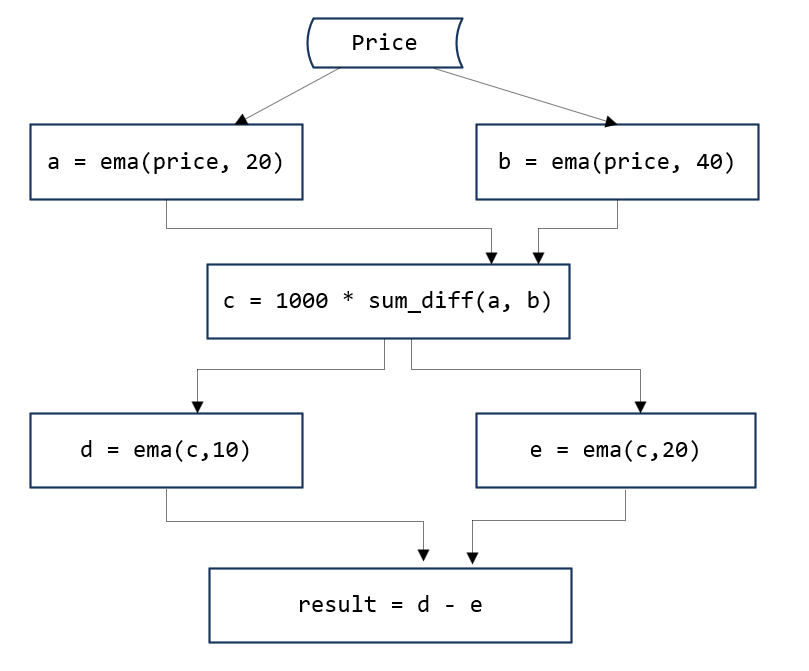
要实现这个图中的计算过程,有2个难点:
►►►
强大的计算性能
DolphinDB 的响应式状态引擎可以实现以下功能:
投研阶段使用历史数据快速计算大量复杂因子;
实盘阶段在每个行情 tick 数据到来时,为每只股票实时计算大量复杂因子;
流计算的代码实现与批处理同等高效,实现代码统一,轻松保证数据一致和正确性。
| 股票个数 | 因子个数 | 耗时(单位:ms) |
| 4000 | 20 | 6 |
| 1 | 20 | 0.07 |
| 4000 | 1 | 0.8 |
| 200 | 20 | 0.2 |
由于 DolphinDB 内置的状态算子经过了大量的优化,因而在单个线程上的计算达到了非常好的性能。
►►►
为什么不用 Python pandas/numpy
对历史数据进行计算时,单线程的计算性能存在很大提升空间。
由于 python 的 Global interpreter lock 限制,我们无法轻易实现并行计算。也就是说,对实时数据进行计算时,由于 python 仅支持全量计算,不支持增量计算,所以无法达到实时计算的性能要求。
►►►
为什么不用 Flink
Flink 是一种流批统一的解决方案,支持 SQL 和窗口函数,高频因子用到的基本算子在 Flink 中也已经内置实现。因此,简单的因子用 Flink 实现比较高效,运行性能也较好。
但 Flink 最大的问题是无法实现复杂的高频因子计算。比如我们前面提到的例子,需要多个窗口函数的嵌套,Flink 就无法直接实现。
与之相比,DolphinDB 既可以保证历史数据并行计算性能,又能保证复杂高频因子的实时计算,在和传统解决方案的大 PK 中,完胜!
PS:DophinDB 的响应式状态引擎还支持过滤输出结果、快照机制和并行处理,满足了投研和生产环境业务的各方面需要。更多详细内容,请点击文末阅读原文查看。
Explore More




文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
