





当 AMD 宣布其新的 Zen 3 核心经过彻底重新设计并提供完全领先的性能时,我们不得不要求他们确认这是否正是他们所说的。尽管规模还不到英特尔的 10%,并且在 2015 年就已经接近倒闭,但 AMD 在这段时间内对其下一代 Zen 微架构和 Ryzen 设计所做的赌注现在正在开花结果。针对台式机市场的 Zen 3 和全新 Ryzen 5000 处理器正在实现这些目标:不仅是每瓦性能和性价比领先者,而且是每个细分市场的绝对性能领先者。我们已经研究了新的微架构并测试了新的处理器。AMD 是新王者,我们有数据证明这一点。
新核心,同样7nm,超过5.0GHz!
全新 Ryzen 5000 处理器是 Ryzen 3000 系列的直接替代品。如今,任何拥有 AMD X570 或 B550 主板且具有最新 BIOS(AGESA 1081 或更高版本)的人都应该能够毫不费力地购买和使用其中一款新处理器。拥有 X470/B450 主板的任何人都必须等到 2021 年第一季度,因为这些主板会更新。
正如我们之前报道的,AMD 今天将推出四款零售处理器,范围从六核到十六核。
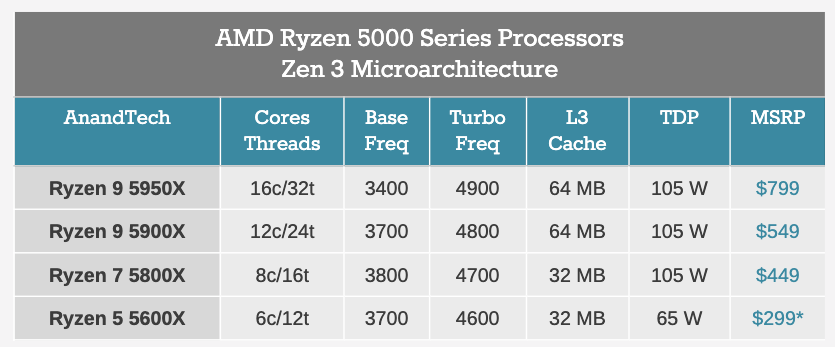
*附带捆绑的 CPU 冷却器

根据 JEDEC 标准,所有处理器都对 DDR4-3200 内存提供本机支持,但 AMD 建议采用稍快的速度以获得最佳性能。所有处理器还具有 20 个 PCIe 4.0 通道,用于附加设备。
Ryzen 9 5950X:16 核,售价 799 美元
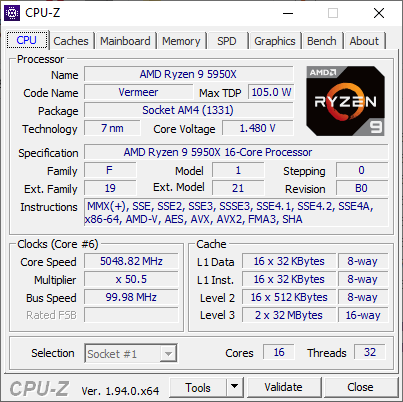
顶级处理器是 Ryzen 9 5950X,具有 16 核心和 32 线程,提供 3400 MHz 的基础频率和 4900 MHz 的睿频频率 - 在我们的零售处理器上,我们实际上检测到单核心频率为 5050 MHz,这表明这处理器将加速到 5.0 GHz 以上,并具有足够的热余量和冷却!

该处理器通过两个八核小芯片(下文将详细介绍小芯片)启用,每个小芯片具有 32 MB 的 L3 缓存(总计 64 MB)。Ryzen 9 5950X 的额定 TDP 与 Ryzen 9 3950X 相同,均为 105 W。根据 AMD 的插槽设计,在支持它的主板上,峰值功率约为 142 W。
对于那些没有阅读评论其余部分的人来说,Ryzen 9 5950X 的简短结论是,即使建议零售价为 799 美元,它也能全面提升消费级性能的新水平。单线程频率非常高,当与具有更高 IPC 的新核心设计相结合时,将单核限制的工作负载推向超越英特尔最好的 Tiger Lake 处理器的水平。在多线程工作负载方面,我们全面刷新了消费级处理器的记录。
核心到核心延迟
随着现代 CPU 的核心数量不断增加,从不同核心访问每个核心的时间不再是恒定的。即使在异构 SoC 设计出现之前,基于大环或网格构建的处理器在访问最近的内核与访问最远的内核时也可能具有不同的延迟。这在多插槽服务器环境中尤其如此。
但现代 CPU,甚至是台式机和消费类 CPU,在访问另一个核心时可能会存在可变的访问延迟。例如,在第一代 Threadripper CPU 中,我们的封装中有四个芯片,每个芯片有 8 个线程,并且每个芯片都有不同的核心到核心延迟,具体取决于它是在芯片上还是在芯片外。对于像 Lakefield 这样的产品,情况会变得更加复杂,它有两种不同的通信总线,具体取决于哪个内核正在与哪个内核通信。
如果您经常阅读 AnandTech 的 CPU 评论,您将会认识到我们的核心到核心延迟测试。这是准确显示核心组在硅上如何布局的好方法。这是一个自定义的内部测试,我们知道存在竞争测试,但我们认为我们的测试对于两个核心之间的访问速度是最准确的。
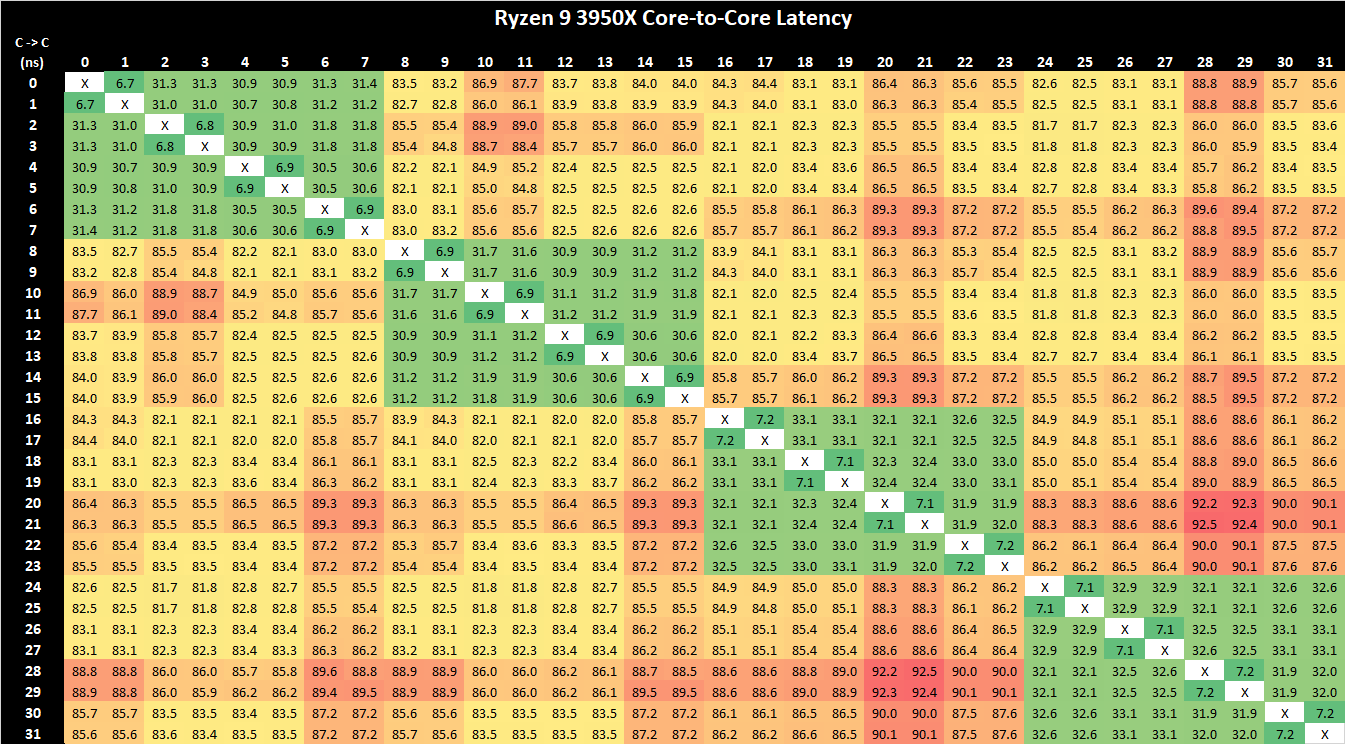
我们注意到各种 Zen2 CPU 的核心到核心延迟行为存在一些差异,具体取决于当时测试的主板和 AGESA 版本。例如,在当前版本中,我们发现 CCX 的 L3 缓存内的核心间延迟约为 30-31 纳秒,但过去我们在相同的 CPU 上测量的数据在 17 纳秒范围内。我们在 Zen2 Renoir 测试中测量了类似的数字,因此现在在不同主板上的 3950X 上得到 31ns 的数字就更奇怪了。我们已经就这种奇怪的差异与 AMD 联系,但从未真正得到关于到底发生了什么的正确回应 - 毕竟是相同的 CPU,甚至相同的测试二进制文件,只是主板平台和 AGESA 版本不同。
尽管如此,在结果中我们可以清楚地看到四个CCX的低延迟,不同CCX的CPU之间的核心间延迟在82ns范围内受到更大程度的影响,这仍然是AMD核心复合体和CPU的主要缺点之一。小芯片架构。
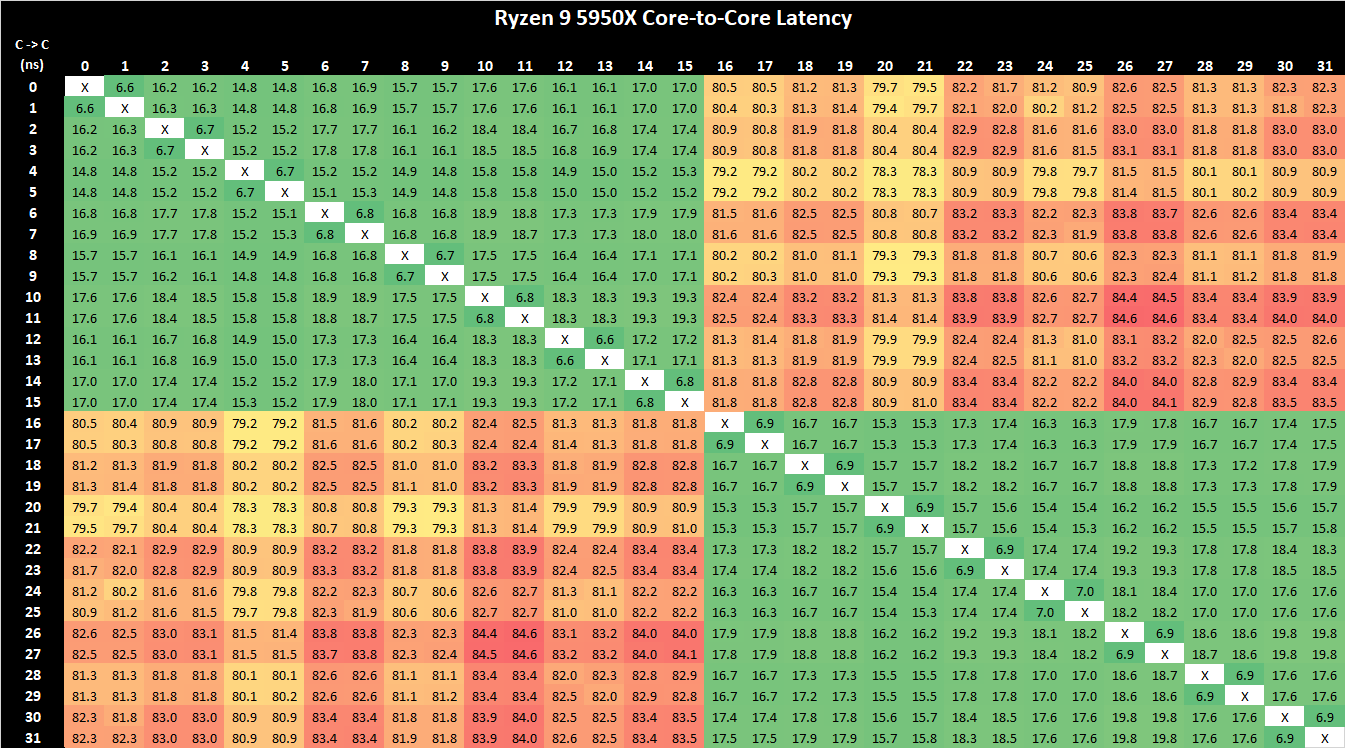
在基于 Zen3 的新 Ryzen 9 5950X 上,显而易见的是,现在只有两个而不是四个低延迟 CPU 集群。这对应于AMD从其16核前身的四个CCX,到新部件上只有两个这样的单元,而这次新的CCX基本上是整个CCD。
L3 内的核心间延迟为 15-19ns,具体取决于核心对。影响这里的数字的一个方面也是核心对可以达到的升压频率,因为我们没有将芯片固定到设定频率。与 3950X 相比,这在延迟方面是一个很大的改进,但考虑到在某些固件组合中,以及在 AMD 的 Renoir 移动芯片上,这是预期的正常延迟行为,新的 Zen3 部件在在这方面,显然除了在 CCD 内的更多 8 个核心池上实现这种延迟之外。
不同 CCD 中的核心之间的核心间延迟仍然会产生 79-80ns 的较大延迟损失,这在某种程度上是可以预料的,因为与前代产品相比,新的 Ryzen 5000 部件不会改变 IOD 设计,并且流量仍然需要改变。穿过上面的无限织物。
对于同步繁重且多线程(最多 8 个主线程)的工作负载,这对于新的 Zen3 CCD 和 L3 设计来说是一个巨大的胜利。事实上,AMD 的新 L3 复合体现在比英特尔基于环的消费类设计提供了更好的内核间延迟和更平坦的拓扑,10900K 等 SKU 的内核间延迟在 16.5-23ns 之间变化。AMD 在减少 CCD 间延迟方面还有很长的路要走,但这也许是下一代设计中需要解决的问题。
缓存和内存延迟
由于 Zen3 在内存缓存层次结构部分做出了一些重大更改,我们也预计这会在我们的缓存和内存延迟测试中以完全不同的行为实现。从理论上讲,Zen3 上的 L1D 和 L2 缓存与 Zen2 相比应该没有任何差异,因为两者具有相同的大小和周期延迟 - 然而我们在微架构深入研究中确实指出,AMD 确实对此处的行为进行了一些更改由于预取器以及缓存替换策略。
在 L3 方面,我们预计延迟曲线将大幅转移到更深的内存区域,因为单个核心现在可以访问完整的 32MB,是上一代的两倍。更深入地了解 DRAM,AMD 实际上并没有过多讨论新微架构对内存延迟的影响——我们预计这里不会有太大变化,因为新芯片重复使用相同的 I/O 芯片相同的内存控制器和无限结构。这里的任何延迟影响应该完全是由于实际 CPU 和核心复合体芯片上所做的微架构更改造成的。
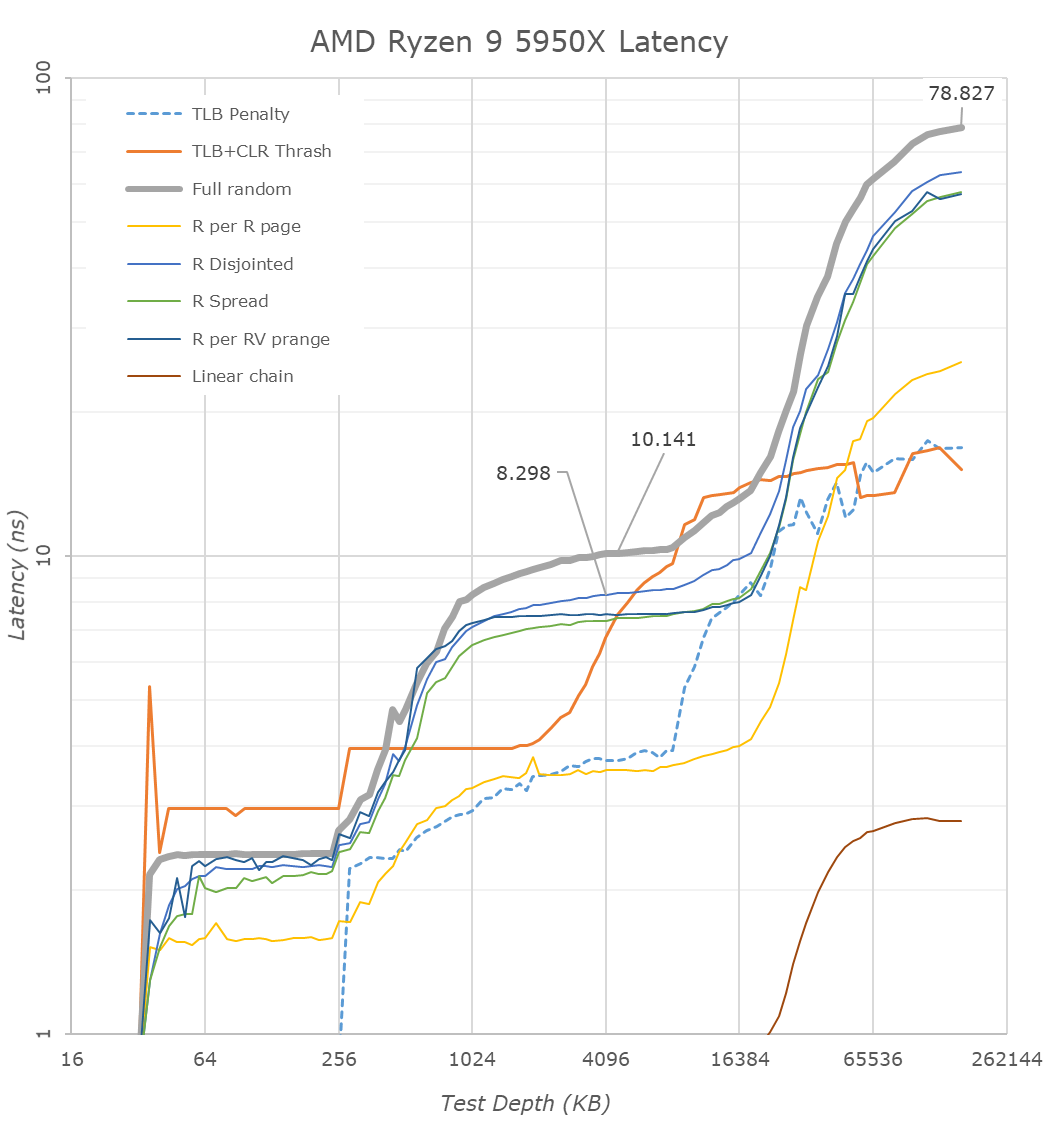
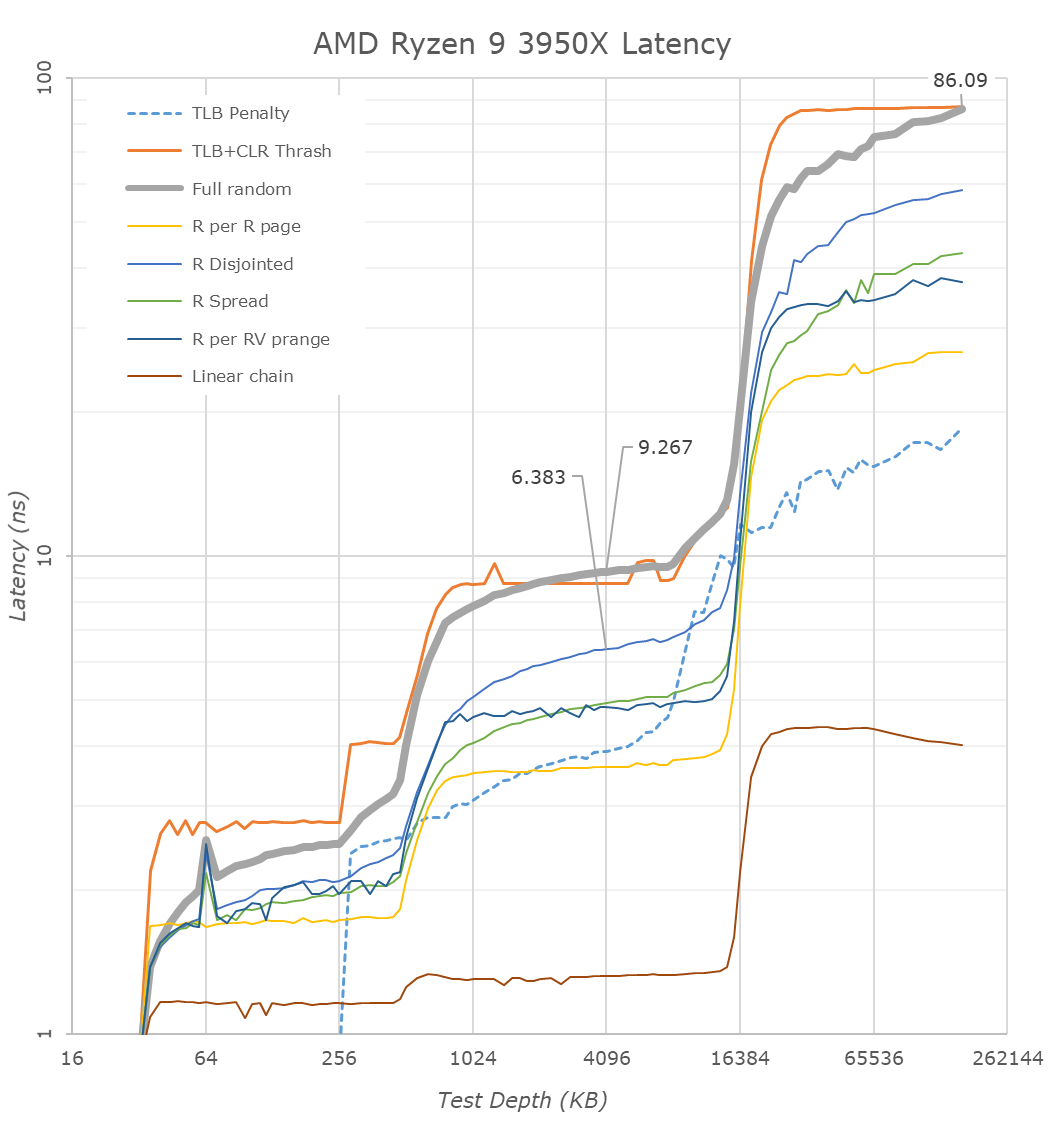
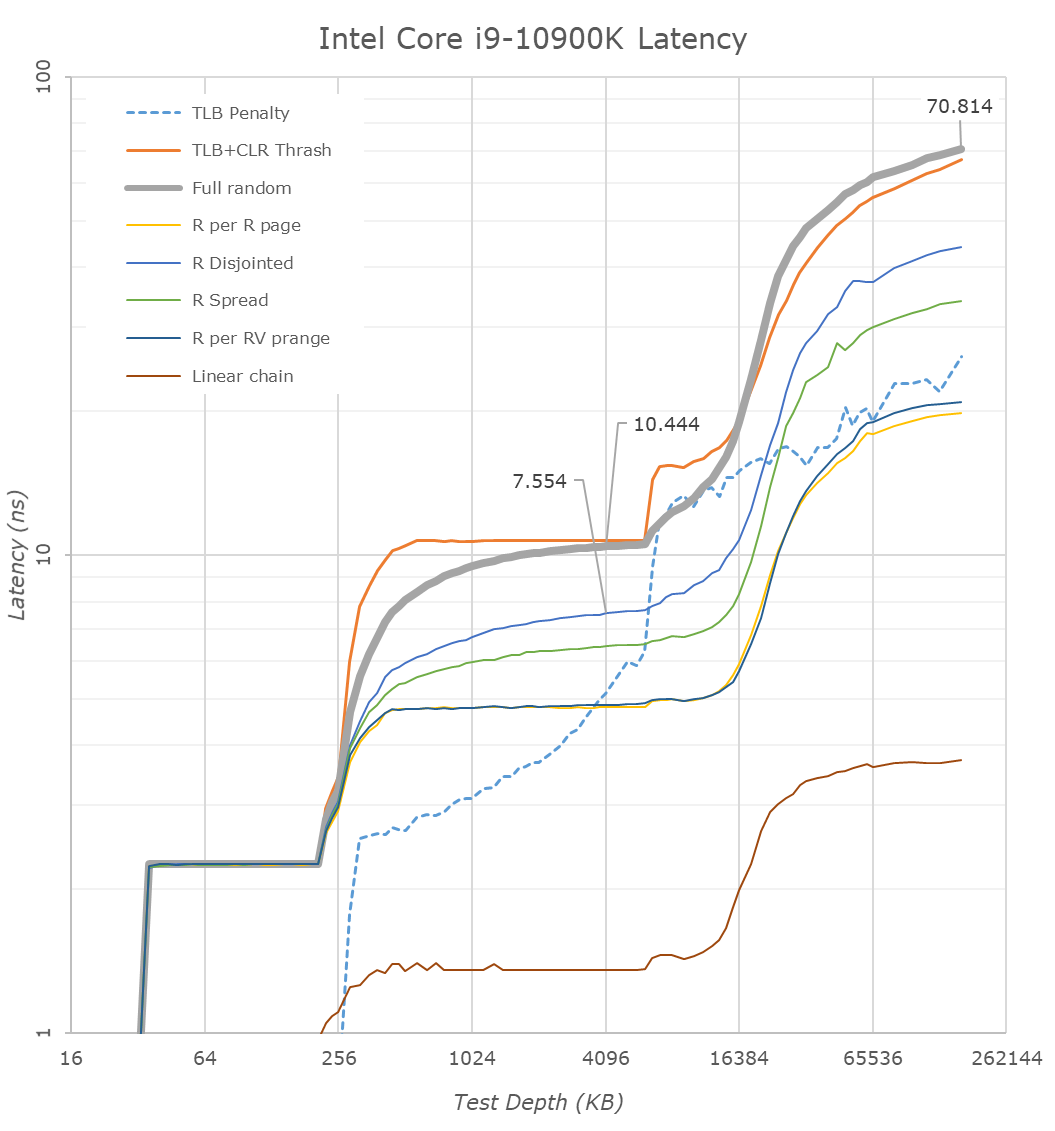
从新 Zen3 5950X 顶级 CPU 的 L1D 区域开始,我们看到访问延迟为 0.792ns,这对应于 5050MHz 的 4 周期访问,这是该新部件在单通道中提升到的最大频率。线程工作负载。
然而,进入 L2 区域,我们已经开始在延迟测试方面看到一些非常不同的微架构行为,因为它们看起来与我们在 Zen2 和前几代上看到的完全不同。
从最基本的访问模式(地址空间内的简单线性链)开始,我们看到访问延迟从 Zen2 上的平均 5.33 个周期改善到 Zen3 上的 ±4.25 个周期,这意味着这一代的相邻行预取器将数据拉入 L1D 时更加积极。这实际上比英特尔的内核更加激进,英特尔的内核在 L2 区域内相同模式的平均访问延迟为 5.11 个周期。
除了简单的线性链之外,我们还在许多其他模式中看到了非常不同的行为,我们其他一些更抽象的模式并没有像 Zen2 上那样积极地预取,稍后会详细介绍。更有趣的是完全随机访问和 TLB+CLR 垃圾模式的行为现在完全不同:完全随机曲线现在在 L1 到 L2 边界上更加陡峭,我们看到 TLB+CLR 具有这里也有一个奇怪的(可重现的)峰值。TLB+CLR 模式遍历随机页面,始终只命中单个但每次页面内不同的缓存行,强制 TLB 读取(或未命中)以及缓存行替换。
事实上,与 Zen2 相比,该测试现在在 L2 到 L3 和 DRAM 中的表现完全不同,这意味着 AMD 现在在 Zen3 上采用了非常不同的缓存行替换策略。L3 中的测试曲线不再实际匹配缓存大小,这意味着 AMD 现在正在优化替换策略,以重新排序/移动组内的缓存行,以减少缓存层次结构中不需要的替换。在这种情况下,这是一个非常有趣的行为,我们在任何微架构中都没有见过这种程度的行为,并且基本上破坏了我们之前用来估计设计的物理结构延迟的 TLB+CLR 测试。
我认为正是这种新的缓存替换策略导致在 L2 和 L3 缓存之间以及从 L3 到 DRAM 之间转换时曲线更加平滑 - 后一种行为现在看起来更接近英特尔和其他一些竞争微架构的行为最近展出。
在 L3 中,测量有点困难,因为现在有几种不同的效果在起作用。Zen3 上的预取器似乎对我们的某些模式没有那么激进,这就是为什么这里的延迟增加了一点点——我们不能真正使用它们进行同类比较到 Zen2 因为他们不再做同样的事情。我们的 CLR+TLB 测试也没有按预期工作,这意味着我们必须求助于完全随机的数字;此处,4MB 深度的新 Zen3 缓存在 5950X 上测得为 10.127ns,而在 3950X 上为 9.237ns。将其转化为周期相当于从平均 42.9 个周期回归到 51.1 个周期,或者基本上+8 个周期。AMD 的官方数据是 Zen2 和 Zen3 的 39 个周期和 46 个周期,+7 周期回归 – 与我们的测量结果一致,
即使 L3 深度为 32MB,超过 8MB 的延迟仍然会增加,这仅仅是因为它超过了 4K 页面大小的 2K 页面的 L2 TLB 容量。
在 DRAM 区域,我们测得 5950X 为 78.8ns,而 3950X 为 86.0ns。将其转换为周期实际上最终会得到两个芯片在 160MB 完全随机访问深度下相同的 398 个周期。我们必须注意到,由于缓存线替换策略的变化,新的 Zen3 芯片在 32-128MB 之间的测试深度上的延迟似乎更好,但这只是测量的副作用,似乎并不是实际的结果。新芯片的物理和结构延迟的表示。您必须测试更深的 DRAM 区域才能获得准确的数据 - 所有这些都是有意义的,因为新的 Ryzen 5000 芯片使用相同的 I/O 芯片和内存控制器,并且我们正在以相同的 3200MHz 速度测试相同的内存。
总体而言,尽管 Zen3 的缓存结构除了加倍且速度稍慢的 L3 之外没有发生显着变化,但对于 AMD 来说,各代微架构之间的实际缓存行为已经发生了很大变化。新的 Zen3 设计似乎更智能地利用了预取和缓存行处理——其中一些性能影响很容易盖过 L3 的提升。我们向 AMD 的 Mike Clarke 询问了其中一些新机制,但该公司不会对他们暂时不愿透露的一些新技术发表评论。
频率斜坡
AMD 和 Intel 在过去几年中都在其处理器中引入了一些功能,可以加快 CPU 从空闲状态进入高功率状态的时间。这样做的效果意味着用户可以更快地获得峰值性能,但最大的连锁反应是移动设备的电池寿命,特别是如果系统可以快速加速和快速减速,确保其保持在最低水平以及尽可能长时间的最高效电源状态。
Intel的技术被称为SpeedShift,尽管SpeedShift直到Skylake才启用。
但这项技术的问题之一是,有时频率的调整可能非常快,软件无法检测到它们。如果频率以微秒的量级变化,但您的软件仅以毫秒(或秒)为单位探测频率,那么将错过快速变化。不仅如此,作为探测频率的观察者,您可能会影响实际的涡轮性能。当 CPU 改变频率时,它本质上必须暂停所有计算,同时调整整个核心的频率。
由于用户没有观察 AMD 处理器的峰值 Turbo 速度,我们就此撰写了一篇广泛的评论分析文章,名为“实现 Turbo:将感知与 AMD 的频率指标保持一致”。
我们通过对导致涡轮增压的工作负载进行频率探测来解决这个问题。该软件能够检测微秒级的频率调整,因此我们可以看到系统达到这些提升频率的效果如何。我们的频率斜坡工具已在许多评论中使用。
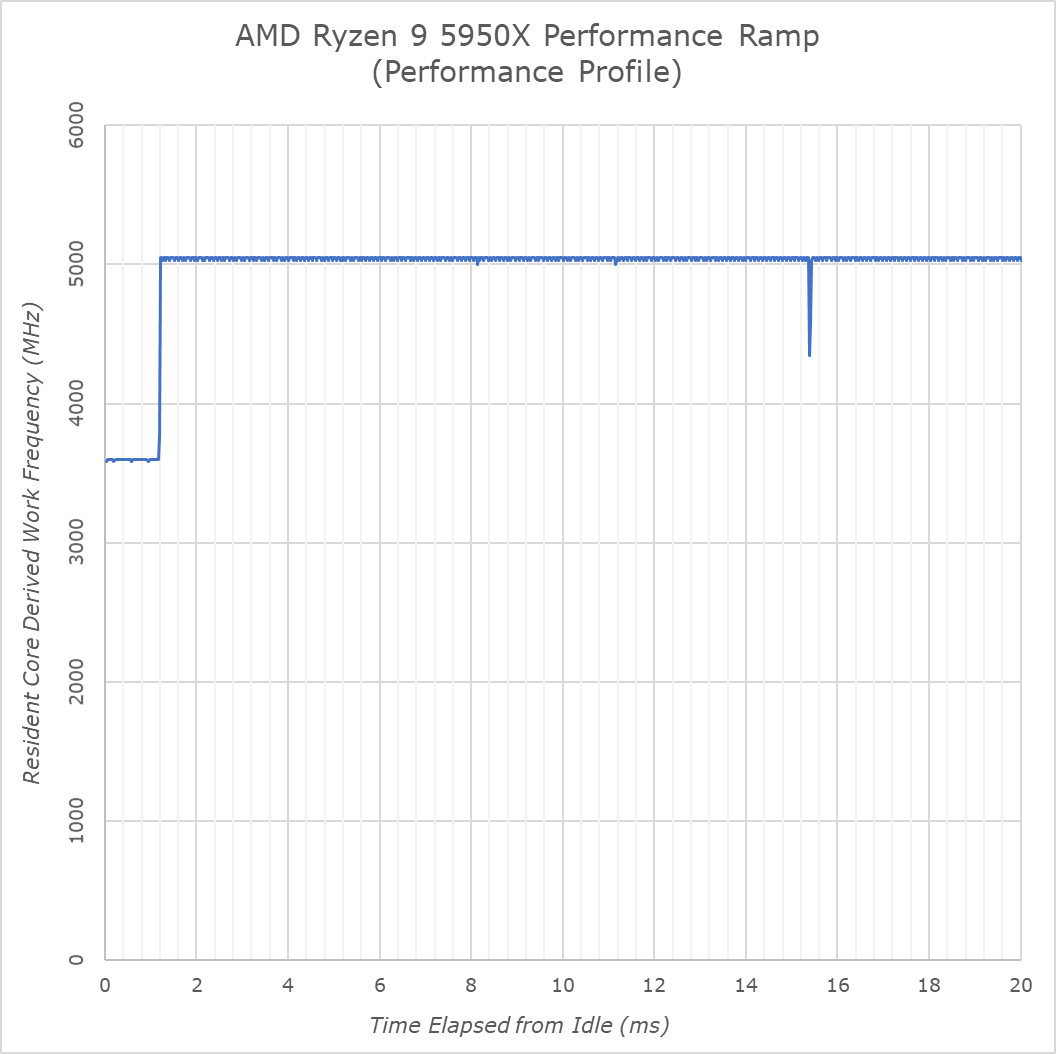
在性能方面,新款 5950X 的表现与 Ryzen 3000 系列相同,在 1.2 毫秒内升至最大频率。在平衡配置上,该时间为 18 毫秒,以避免在零星后台任务期间不必要地提高空闲频率。
新CPU的空闲频率达到3597MHz,而Zen3 CPU在单线程工作负载上将提升至5050MHz。在我们的测试工具中,它实际上读出了 5025 和 5050MHz 之间的波动,但这似乎只是一个混叠问题,因为计时器分辨率为 100ns,而我们测量的是 20μs 工作负载块。在这个特定的主板上,根据基本时钟和倍频器的实际频率看起来是 5048.82MHz。
参考:https://zhuanlan.zhihu.com/p/586136393
原文:https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested
