




1.核心概念
2.核心流程:
1.org.apache.shardingsphere和io.shardingsphere的关系:
2.相关依赖包:
3.分库分表配置:
4.创建数据库和表:
5.代码-》单元测试:
一、前言
二、实战
三、整体介绍
四、结尾
一、前言
分库分表的技术现在相对来说已经很成熟了,现在比较流行的就是量种方式,mycat是一种解耦方式代理实现的分库分表中间件,代码侵入性低,但是运维维护的话相对于sharding比较麻烦,还有就是mycat的冗余字段表、事务、分页问题等需要特殊的处理,所以相对讲sharding的使用更简单些,但是sharding的话对于依赖包的版本匹配则更严格,也会面临升级的问题,但是这些相对来说可控。本篇是基于2.3.0.RELEASE和sharding的分库分表事件总结。
二、实战
1.org.apache.shardingsphere和io.shardingsphere的关系:
io.shardingsphere下面的sharding-jdbc-spring-boot-starter的到了3.x以后现在已经不维护了,所以使用springboot高版本的sharding最好是使用org.apache.shardingsphere里面的sharding-jdbc-spring-boot-starter,因为sharding是2018年加入到Apache基金会孵化器。后面的版本迭代也会在org.apache.shardingsphere里面进行发布。官网开发手册地址:https://shardingsphere.apache.org/document/current/cn/overview/
2.相关依赖包:
这次实战使用的是spring-boot-starter-parent 2.3.0.RELEASE、mysql8、com.alibaba、mybatis-spring-boot-starter、com.github.pagehelper,这些组件版本的版本号非常重要,我在此过程中就是踩了很多坑,然后最终才配置完成启动了起来成功运行。
3.分库分表配置:
这是一个比较重要的环节,因为分库的逻辑和分表的逻辑在这里实现,直接上干货配置:
spring.shardingsphere.datasource.names=doc0,doc1
spring.shardingsphere.datasource.doc0.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.doc0.driver-class-name= com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.doc0.url=
spring.shardingsphere.datasource.doc0.username=
spring.shardingsphere.datasource.doc0.password=
#数据源2
spring.shardingsphere.datasource.doc1.type= com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.doc1.driver-class-name= com.mysql.cj.jdbc.Driver
#数据库链接账号
spring.shardingsphere.datasource.doc1.url=
spring.shardingsphere.datasource.doc1.username=
spring.shardingsphere.datasource.doc1.password=
#分片策略
#库分片策略(按照表的id进行分库是用的比较常用的取模运算)、科普:取模运算就是取两个数相除的余数,下面的结果就是数据库分两片doc0/doc1
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=log_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=doc${log_id % 2}
#表分片策略 表的分片也是采用的取模运算,只不过这里是分了三片,0,1,2
spring.shardingsphere.sharding.tables.dcs_log.actualDataNodes= doc$->{0..1}.dcs_log${0..2}
spring.shardingsphere.sharding.tables.dcs_log.tableStrategy.inline.shardingColumn=log_id
spring.shardingsphere.sharding.tables.dcs_log.tableStrategy.inline.algorithmExpression= dcs_log${log_id % 3}
4.创建数据库和表:
创建个对应的数据库需要手动的创建,然后和对应的分片表,一定要跟上面的分片的逻辑对应上,要不然就会报错。数据库图:
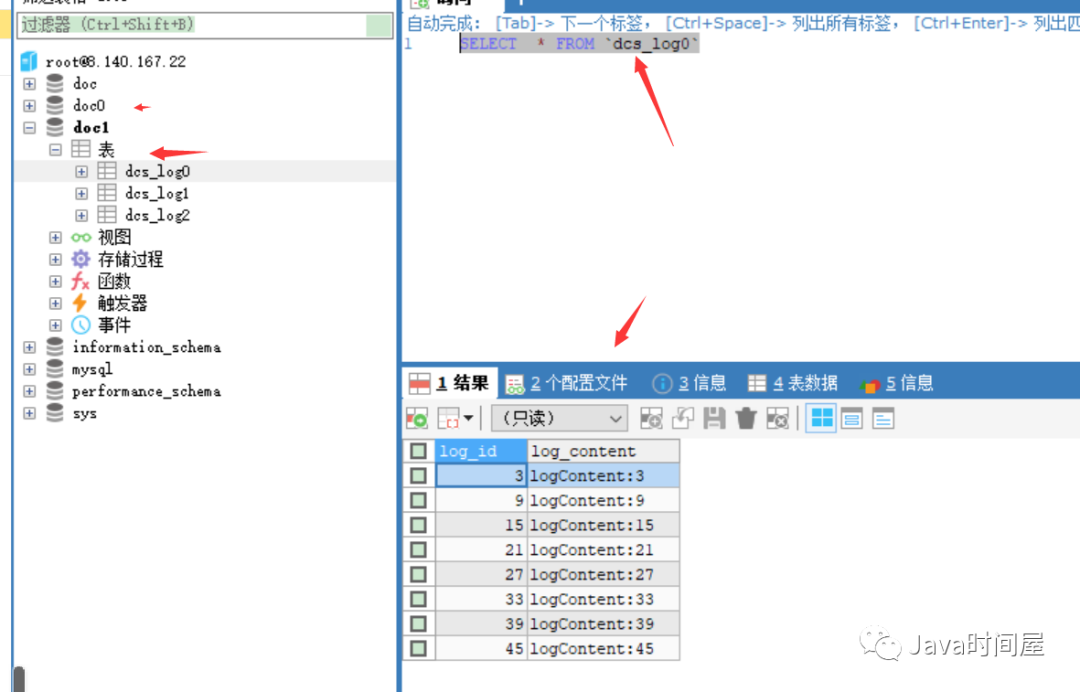
表图:
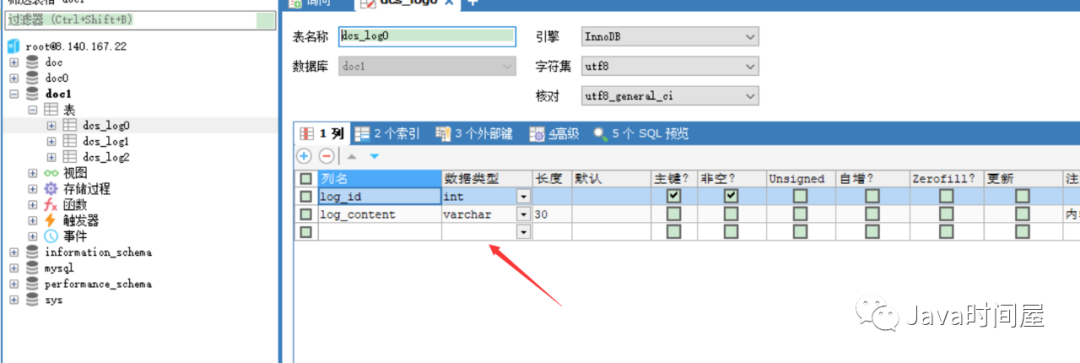
因为就两个字段,非常的简单,这个就是按照上面的分库、分表的逻辑创建的数据库表,对应的两个库和三个表,相当于分片成了6份进行存储,已经能够满足大部分的扩容、高并发的需求。
5.代码-》单元测试:
@Resource
private DcsLogMapper dcsLogMapper;
@Test
public void testShardingPage(){
//插入分库分表的数据
for(long i=1;i <= 50; i++){
DcsLog dcsLog=new DcsLog();
dcsLog.setLogId((int) i);
dcsLog.setLogContent("logContent:" + i);
dcsLogMapper.addLog(dcsLog);
}
//分页
PageHelper.startPage(1,5);
List<DcsLog> list= dcsLogMapper.findDcsLog();
PageInfo<DcsLog> pageInfo = new PageInfo<DcsLog>(list);
System.out.println(pageInfo);
}
这其中遇到的问题就是myabatis中的sql怎么写,因为表创建的时候都是有序号的,但是这个时候sql写的时候不应该序号,因为sharding是按照上面的配置的逻辑自动的给加上序号。直接上源码:
<insert id="addLog">
INSERT INTO dcs_log (`log_id`, `log_content`)
VALUES
(#{logId}, #{logContent});
</insert>
<select id="findDcsLog" resultType="com.jack.wx.small.model.DcsLog">
SELECT
`log_id` logId ,
`log_content` logContent
FROM
`dcs_log` order by log_id ASC
</select>
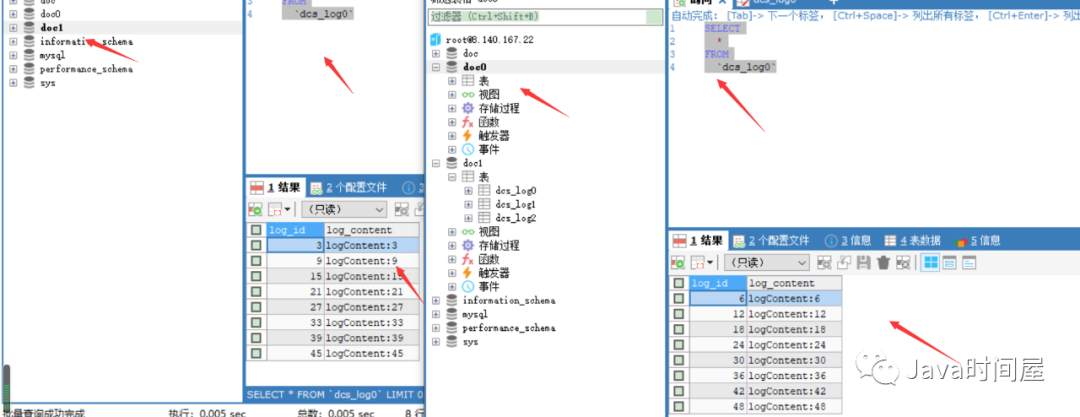
上面一个是插入的sql,一个是查询分页的sql,可以注意到上面的查询用了id排序,因为不排序的话,sharding会直接取到当前库的满足条件的数据不再进行夸库查询。执行完单元测试后看看效果吧: 表中插入数据:
分页查询结果: 第一页:
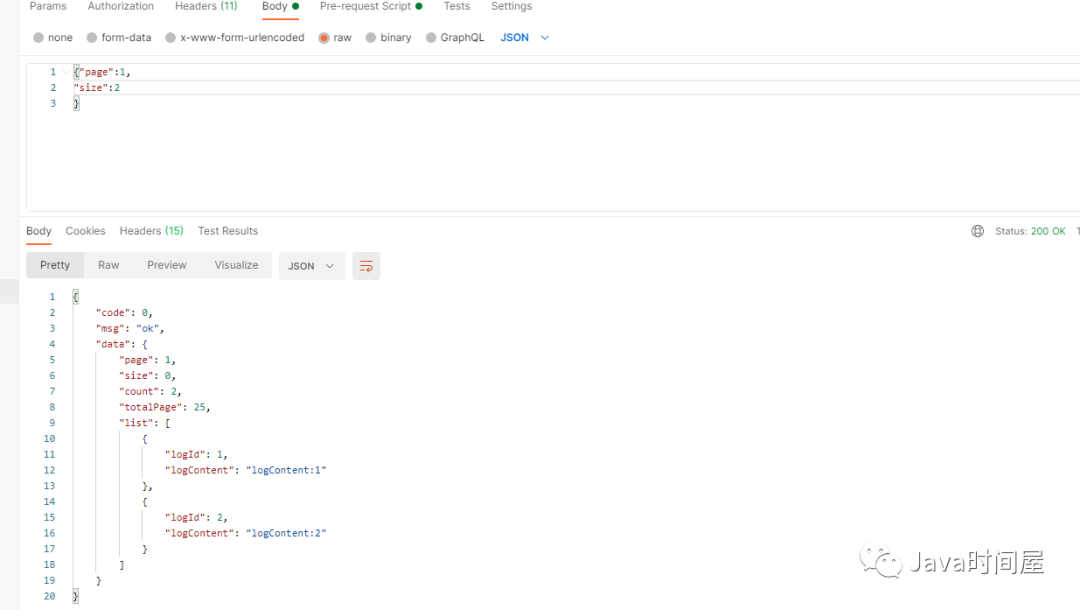
第二页:
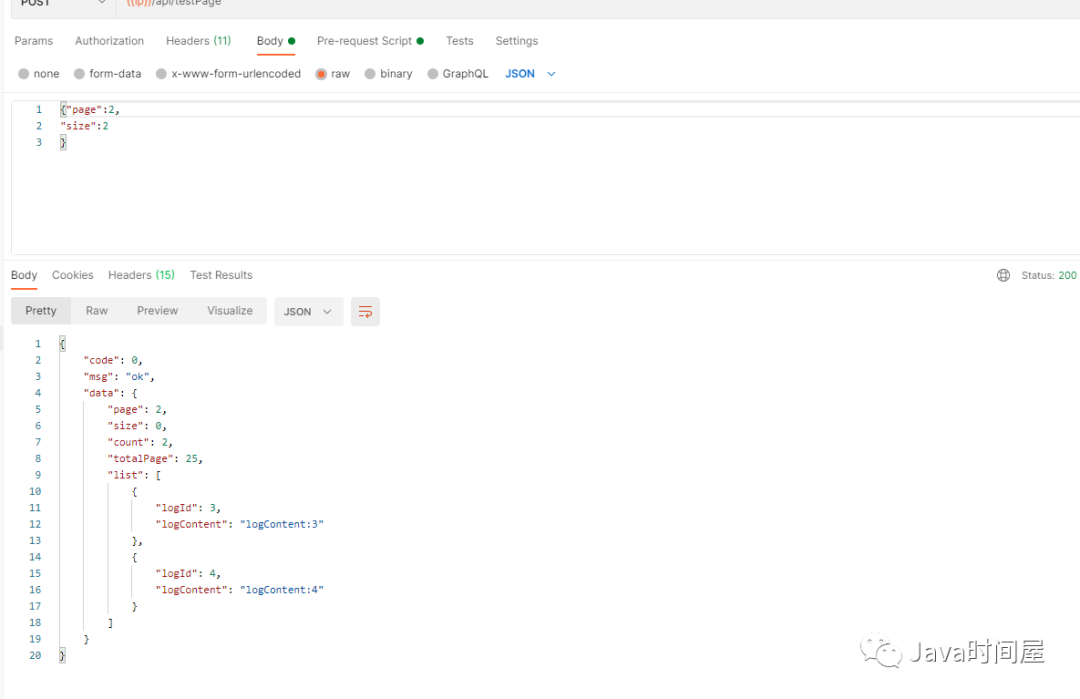
至此,整个的基于sharding-jdbc的分库分表的操作已经完成。
三、整体介绍
参考:https://www.cnblogs.com/jackion5/p/13658615.html
1.核心概念
| 概念 | 说明 |
|---|---|
| 逻辑表 | 通过水平拆分的库/表拥有相同的的表结构和逻辑,如dcs_log表水平拆分成dcs_log0、dcs_log1、dcs_log2等分表,但是在逻辑上都统称为dcs_log表 |
| 真实表 | 真实存储数据的物理表,如user表水平拆分成dcs_log0/1/2表,那么dcs_log0/1/2就是真实表 |
| 数据节点 | 数据分片的最小单元,由数据源和数据表组成,如doc0.dcs_log0表 |
| 绑定表 | 分片规则一致的主表和子表,如order表和order_detail表,都按照orderId进行分片,两种表互为绑定表关系,配置绑定关系之后,主表和字表关联查询就不存在笛卡尔积关联 |
| 广播表 | 所有的分片中都存在表结构和数据都完全一致的表,一般用于存储数据字典或每个库都需要用到的公用数据,通常数据量都不大但是使用频繁的 |
| 分片键 | 用于分片的数据库字段,如水平拆分时将dcs_log0表中的log_id进行取模算法分配,根据log_id%3的余数判断数据在那个节点 |
| 分片算法 | 分片算法用于将分片键根据具体的算法进行分片,算法主要分如下几种:1.精确分片算法(PreciseShardingAlgorithm):用于处理使用单一键作为分片键的=和IN的场景,需要配合StandardShardingStrategy使用2.范围分片算法(RangeShardingAlgorithm):用于处理使用单一键作为分片键的between、and、>、<、>=、<=等分片场景,需要配合StandardShardingStrategy使用3.复合分片算法(ComplexKeysShardingAlgorithm):用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑比较复杂,需要配合ComplexShardingStrategy使用4.Hint分片算法(HintShardingAlgorithm):用于处理Hint行分片的场景,需要配合HintShardingStrategy使用 |
| 分片策略 | 分片键和分片算法配合起来就是一种分片策略,主要分片策略如下: 1.标准分片策略:对应StandardShardingStrategy,提高对SQL语句中的=,>,<,>=,<=,IN,AND,BETWEEN等分片操作的支持.StandardShardingStrategy只支持单键分片,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理2.复合分片策略:对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度3.行表达式分片策略:对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如:t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。4.Hint分片策略:对应HintShardingStrategy,通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略5.不分片策略:对应NoneShardingStrategy,不分片的策略 |
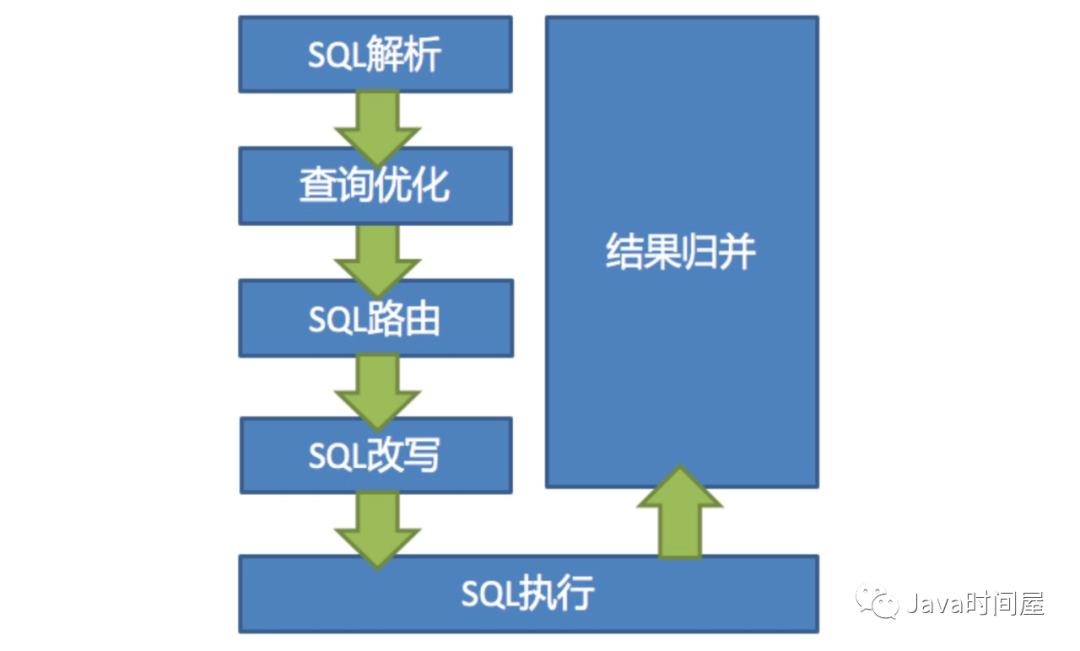
2.核心流程:
Shardingjdbc核心流程分6个步骤:sql解析-》sql优化-》sql路由-》sql改写-》sql执行-》结果归并
图示:
四、结尾
上面就是整个我总结的ShardingJDBC的使用总结,整个过程虽然采坑很多,但是最后收获还是挺多的,虽然可能公司的实际业务暂时不需要分库分表,但是还是应该掌握分库分表的技术为未来做好准备,欢迎交流、转载、点赞、赞赏。
