





前言
昨天有朋友说,能不能简单介绍一下Patroni是如何工作的。找了一圈资料,觉得有Zalando的一个PPT(Patroni in 2019: What's New and Future Plans)写的不错,我们就来简单的介绍一下它的工作原理。
Patroni是如何工作的
传统的流复制一个很大的弊病,是不能够提供一个完整的高可用性解决方案。当主机发生异常hang死或者宕机的时候,没办法进行切换。
一个简单的思路其实就是编写脚本,定期的去检查主服务器的状态,如果主服务器不可用,那么我们就把备库提升为主库。但是这其实也是有问题的,有时候网络可能发生了一些闪断,这期间备库就无法访问主库了。然后编写的脚本检测主服务器状态异常,就把备库提升为了主库。但是主库现在仍然对外部客户端可访问,这就造成了脑裂的情况。
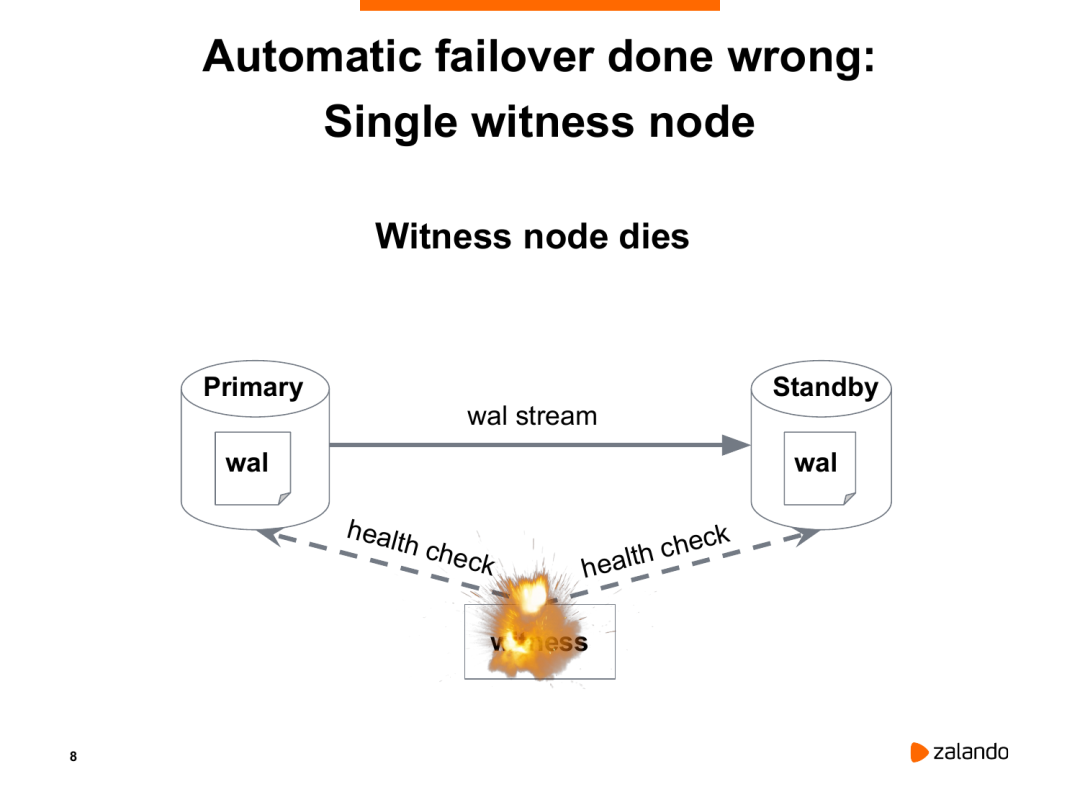
所以后面的思路就是使用第三服务器witness,同时监控主库和备库,主库和备库上都有agent,实时跟witness进行心跳确认,一旦主库出现问题,witness就能清楚的知道情况,然后做故障转移。但是这种方案也是有弊病的,首先witness也是有可能会出问题的,此时再出现故障就无法发生切换。另外一个情况就是主库和witness出现了网络问题,无法访问主库的情况下,witness也会提升备库,但是主库其实对外访问是正常的。
 |  |
|---|
由于上述情况的出现,我们需要一种更加强大的现代化方法来确认主库和从库是否存活,于是我们采用了etcd这样的基数节点集群来实现。
为什么要是基数节点? 假设三个节点,如果有两个节点同意我们的主要节点不可用,则这两个节点具有多数票。如果是四个节点,就必须获取到三个节点的票,才能获得多数票,如果是两票对两票则是平手,还需要再进行投票。所以基数在投票环节上具备天然的优势。
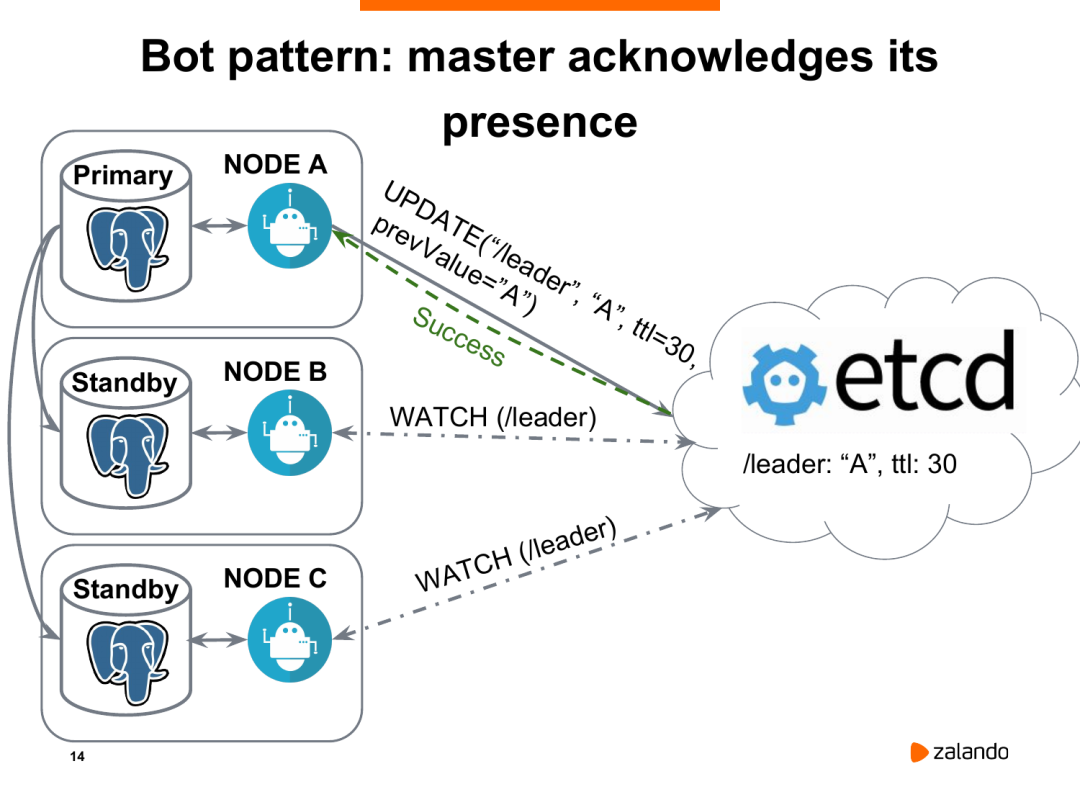
在这个图中,我们的数据库是一主两从的流复制架构,节点A是主节点,B和C是从节点。节点A会定期向etcd发送请求以更新领导者密钥,默认情况是10s更新一次(这是由参数loop_wait控制),更新的时候带了一个TTL,前面说过代表着生存时间。这里面有一个公式:
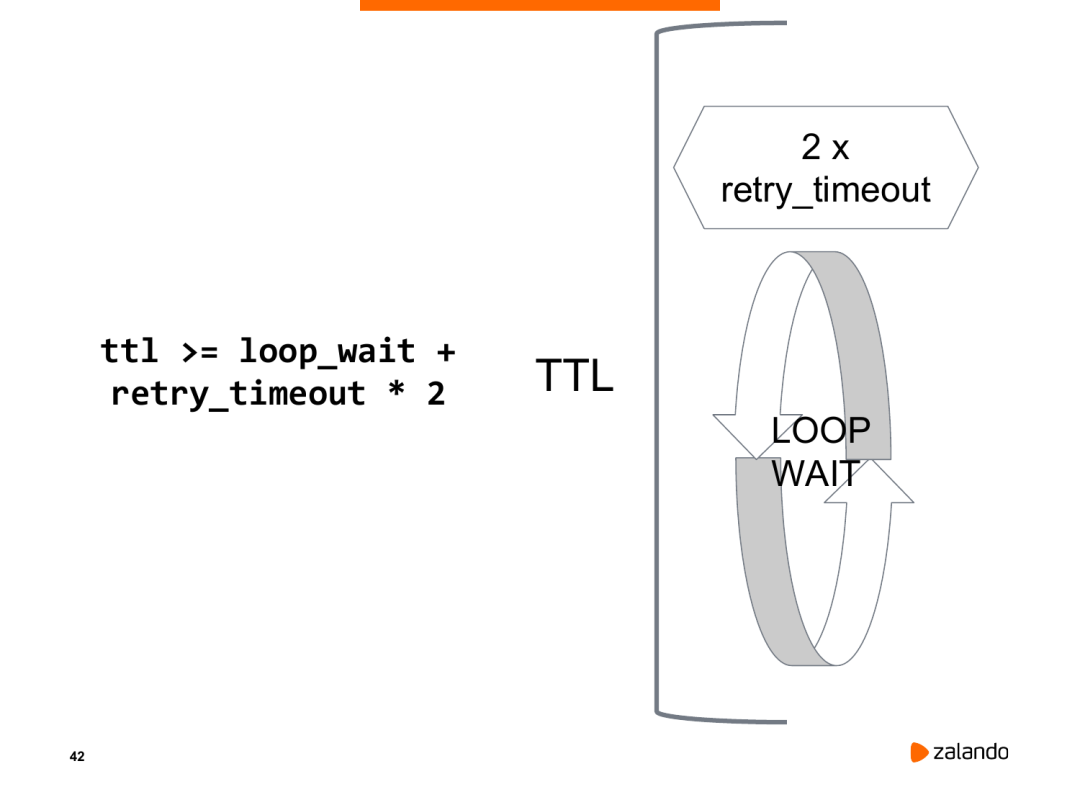
TTL > = loop_wait + retry_timeout * 2
这个机制是这样的,patroni进程每隔10秒(loop_wait)都会更新Leader key还有TTL,如果Leader节点异常导致patroni进程无法及时更新Leader key,则会重新进行2次尝试(retry_timeout)。如果尝试了仍然无效。这个时候时间超过了TTL(生存时间)。领导者密钥就会过期,然后触发新的选举。
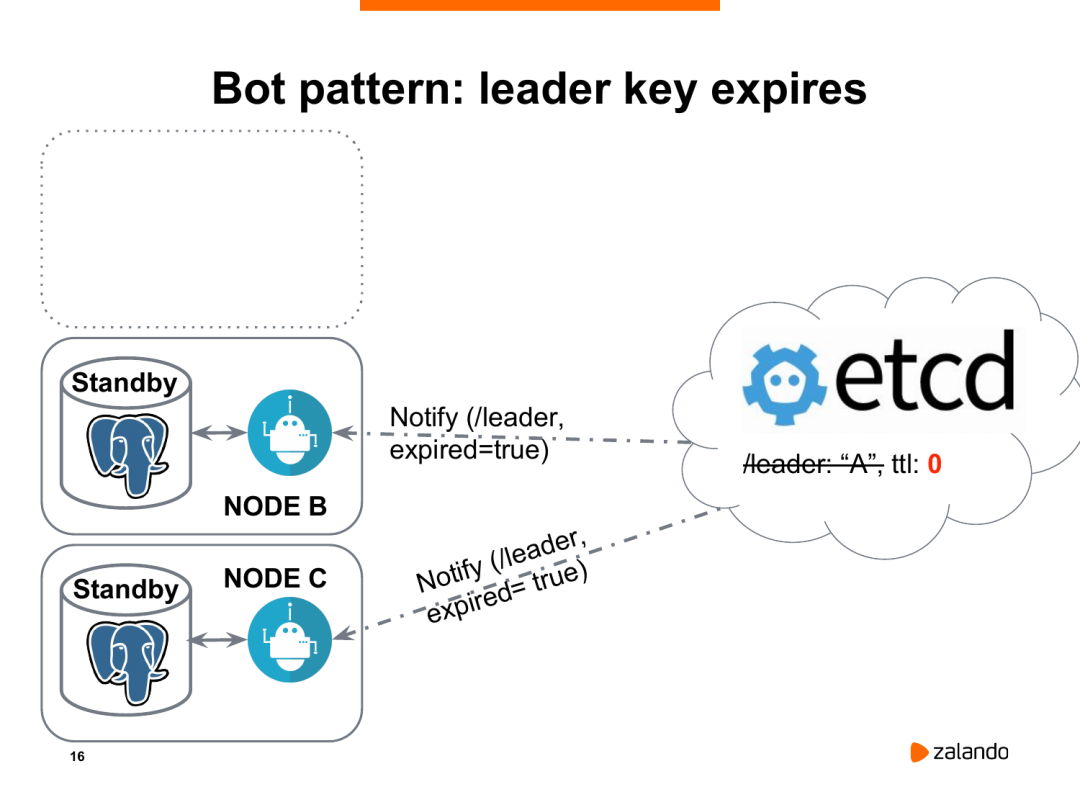
发生新的选举很简单,节点b和节点c此时会收到通知,当前已经没有领导者了,我们必须举行新的选举。
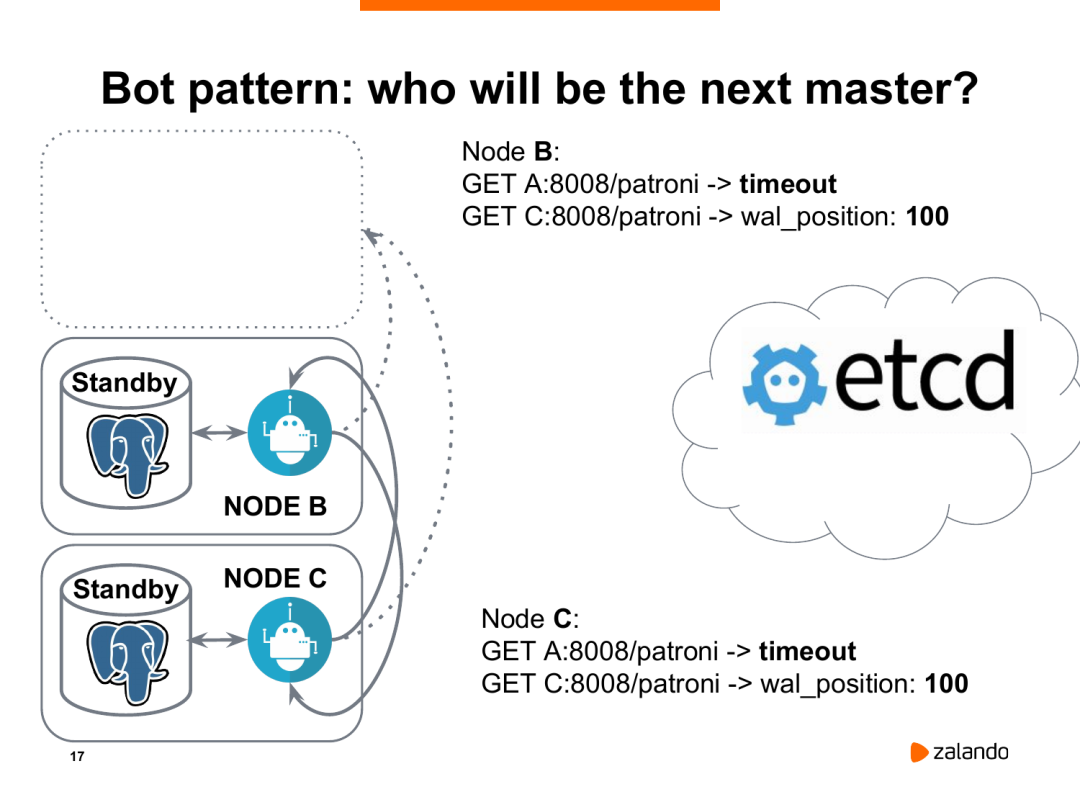
Patroni之间也通过rest api互相访问。他们首先会和曾经的领导者通信,会发现访问超时,然后他们通过rest api访问Patroni进程知道自己的wal_position位置。假设节点b和节点c现在都处于相同的wal_position,都等于100,那么他们会同时访问etcd,发送创建密钥的请求,然后开始领导争夺战。
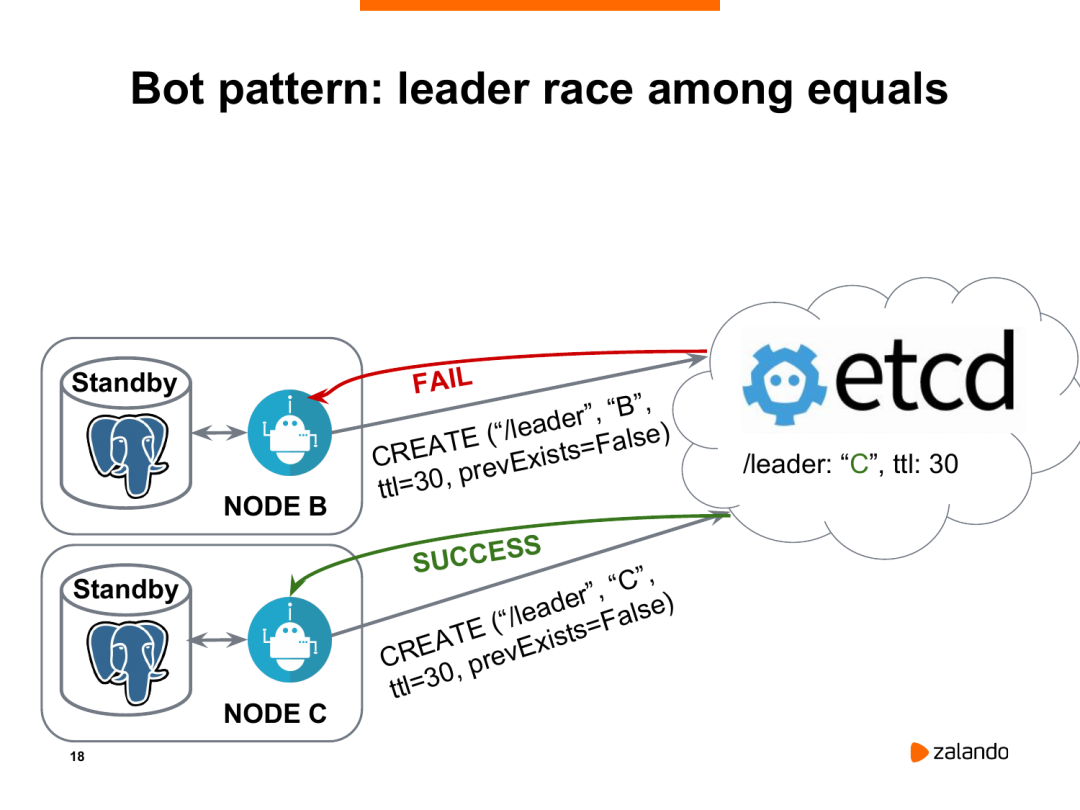
两个节点到etcd之间,Node C率先创建了密钥。Node C上面就执行promote,成为了新的主库,Node B将成为新的从库。它会选择从Node C来进行复制。然后Node C就成为了leader。
May 26 15:16:23 133e0e204e208 patroni: 2021-05-26 15:16:23,865 INFO: no action. i am a secondary and i am following a leaderMay 26 15:16:29 133e0e204e208 patroni: 2021-05-26 15:16:29,436 INFO: Got response from postgres2 http://133.0.204.207:8008/patroni: {"state": "running", "postmaster_start_time": "2021-05-25 16:27:00.818 CST", "role": "replica", "server_version": 130002, "cluster_unlocked": true, "xlog": {"received_location": 3909174320, "replayed_location": 3909174320, "replayed_timestamp": "2021-05-26 15:06:09.766 CST", "paused": false}, "timeline": 13, "database_system_identifier": "6962171552537974697", "patroni": {"version": "2.0.2", "scope": "patnori-test"}}May 26 15:16:29 133e0e204e208 patroni: 2021-05-26 15:16:29,449 WARNING: Request failed to postgres1: GET http://133.0.204.206:8008/patroni (HTTPConnectionPool(host='133.0.204.206', port=8008): Max retries exceeded with url: /patroni (Caused by ProtocolError('Connection aborted.', ConnectionResetError(104, 'Connection reset by peer'))))May 26 15:16:29 133e0e204e208 patroni: 2021-05-26 15:16:29,455 WARNING: Could not activate Linux watchdog device: "Can't open watchdog device: [Errno 2] No such file or directory: '/dev/watchdog'"May 26 15:16:29 133e0e204e208 patroni: 2021-05-26 15:16:29,458 INFO: promoted self to leader by acquiring session lockMay 26 15:16:29 133e0e204e208 patroni: server promotingMay 26 15:16:29 133e0e204e208 patroni: 2021-05-26 15:16:29,461 INFO: cleared rewind state after becoming the leaderMay 26 15:16:30 133e0e204e208 patroni: 2021-05-26 15:16:30,471 INFO: Lock owner: postgres3; I am postgres3
我们模拟一下,把Node A直接关闭,关闭一个Patroni节点这里切换的速度是非常快的。我们看Node C的日志,其中节点C通过Rest API访问自己的patroni进程,获取自己的wal_position,同时它还会用Rest API访问曾经的领导者Node A,发现访问超时。紧接着它会去激活watchdog,我们这个环境没有配置watchdog,所以它这里出现了一个WARNING。同时它会访问etcd创建领导者密钥,如果它创建成功,它将获取会话锁将自己提升为leader。整个日志的过程和前面图片介绍的完全吻合。
后记
了解一下它的工作原理,方便我们后面进行高可用测试。
参考文档https://www.postgresql.eu/events/pgconfeu2019/sessions/session/2717/slides/218/Patroni%20in%202019_%20What's%20New%20and%20Future%20Plans.pdf
