




 听说,这里有最具价值的大数据实战干货、
听说,这里有最具价值的大数据实战干货、
大数据技术经验、大数据创新思维,
更有你想融入的大数据高端人脉圈
据说,国内近6成大数据精英都在这
尽情分享吧 我的朋友
让我们用优质原创内容 占领整个朋友圈
一、简介
ELK 由三部分组成elasticsearch、logstash、kibana,elasticsearch是一个近似实时的搜索平台,它让你以前所未有的速度处理大数据成为可能。

Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文搜索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
应用程序的日志大部分都是输出在服务器的日志文件中,这些日志大多数都是开发人员来看,然后开发却没有登陆服务器的权限,如果开发人员需要查看日志就需要到服务器来拿日志,然后交给开发;试想下,一个公司有10个开发,一个开发每天找运维拿一次日志,对运维人员来说就是一个不小的工作量,这样大大影响了运维的工作效率,部署ELKstack之后,开发任意就可以直接登陆到Kibana中进行日志的查看,就不需要通过运维查看日志,这样就减轻了运维的工作。
日志种类多,且分散在不同的位置难以查找:如LAMP/LNMP网站出现访问故障,这个时候可能就需要通过查询日志来进行分析故障原因,如果需要查看apache的错误日志,就需要登陆到Apache服务器查看,如果查看数据库错误日志就需要登陆到数据库查询,试想一下,如果是一个集群环境几十台主机呢?这时如果部署了ELKstack就可以登陆到Kibana页面进行查看日志,查看不同类型的日志只需要电动鼠标切换一下索引即可。
Logstash:日志收集工具,可以从本地磁盘,网络服务(自己监听端口,接受用户日志),消息队列中收集各种各样的日志,然后进行过滤分析,并将日志输出到Elasticsearch中。
Elasticsearch:日志分布式存储/搜索工具,原生支持集群功能,可以将指定时间的日志生成一个索引,加快日志查询和访问。
Kibana:可视化日志Web展示工具,对Elasticsearch中存储的日志进行展示,还可以生成炫丽的仪表盘。
二、安装部署(因为我是测试环境,就将ElasticSearch+Logstash+ Kibana装在一台虚拟机上面了)
安装jdk
rpm -ivh jdk-8u92-linux-x64.rpmvi etc/profileJAVA_HOME=/usr/java/jdk1.8.0_92/
source etc/profile
echo $JAVA_HOME /usr/java/jdk1.8.0_92/
java -versionjava version "1.8.0_92"Java(TM) SE Runtime Environment (build 1.8.0_92-b14)Java HotSpot(TM) 64-Bit Server VM (build 25.92-b14, mixed mode)
安装elasticsearch
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch添加yum文件echo "[elasticsearch-2.x]name=Elasticsearch repository for 2.x packagesbaseurl=http://packages.elastic.co/elasticsearch/2.x/centosgpgcheck=1gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearchenabled=1" >> etc/yum.repos.d/elasticsearch.repoyum install elasticsearch -y
mkdir data/elk/{data,logs}
Type Description Locationhome elasticsearch安装的目录 {extract.path}bin elasticsearch二进制脚本目录 {extract.path}/binconf 配置文件目录 {extract.path}/configdata 数据目录 {extract.path}/datalogs 日志目录 {extract.path}/logsplugins 插件目录 {extract.path}/plugin
配置说明:vi etc/elasticsearch/elasticsearch.ymlcluster.name: espath.data: data/elk/datapath.logs: data/elk/logsbootstrap.mlockall: truenetwork.host: 0.0.0.0http.port: 9200discovery.zen.ping.unicast.hosts: ["192.168.2.215", "host2"]启动:/etc/init.d/elasticsearch start
elasticsearch的config文件夹里面有两个配置文件:elasticsearch.yml和logging.yml,
第一个是es的基本配置文件,第二个是日志配置文件,es也是使用log4j来记录日志的,所以logging.yml里的设置按普通log4j配置文件来设置就行了。下面主要讲解下elasticsearch.yml这个文件中可配置的东西。cluster.name:elasticsearch配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。node.name:”FranzKafka”节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。node.master:true指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。node.data:true指定该节点是否存储索引数据,默认为true。index.number_of_shards:5设置默认索引分片个数,默认为5片。index.number_of_replicas:1设置默认索引副本个数,默认为1个副本。path.conf:/path/to/conf设置配置文件的存储路径,默认是es根目录下的config文件夹。path.data:/path/to/data设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data:/path/to/data1,/path/to/data2path.work:/path/to/work设置临时文件的存储路径,默认是es根目录下的work文件夹。path.logs:/path/to/logs设置日志文件的存储路径,默认是es根目录下的logs文件夹path.plugins:/path/to/plugins设置插件的存放路径,默认是es根目录下的plugins文件夹bootstrap.mlockall:true设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit-lunlimited`命令。network.bind_host:192.168.0.1设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。network.publish_host:192.168.0.1设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。network.host:192.168.0.1这个参数是用来同时设置bind_host和publish_host上面两个参数。transport.tcp.port:9300设置节点间交互的tcp端口,默认是9300。transport.tcp.compress:true设置是否压缩tcp传输时的数据,默认为false,不压缩。http.port:9200设置对外服务的http端口,默认为9200。http.max_content_length:100mb设置内容的最大容量,默认100mbhttp.enabled:false是否使用http协议对外提供服务,默认为true,开启。gateway.type:localgateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。gateway.recover_after_nodes:1设置集群中N个节点启动时进行数据恢复,默认为1。gateway.recover_after_time:5m设置初始化数据恢复进程的超时时间,默认是5分钟。gateway.expected_nodes:2设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。cluster.routing.allocation.node_initial_primaries_recoveries:4初始化数据恢复时,并发恢复线程的个数,默认为4。cluster.routing.allocation.node_concurrent_recoveries:2添加删除节点或负载均衡时并发恢复线程的个数,默认为4。indices.recovery.max_size_per_sec:0设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。indices.recovery.concurrent_streams:5设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。discovery.zen.minimum_master_nodes:1设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)discovery.zen.ping.timeout:3s设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。discovery.zen.ping.multicast.enabled:false设置是否打开多播发现节点,默认是true。discovery.zen.ping.unicast.hosts:[“host1″,”host2:port”,”host3[portX-portY]”]设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
安装head插件(集群管理插件)
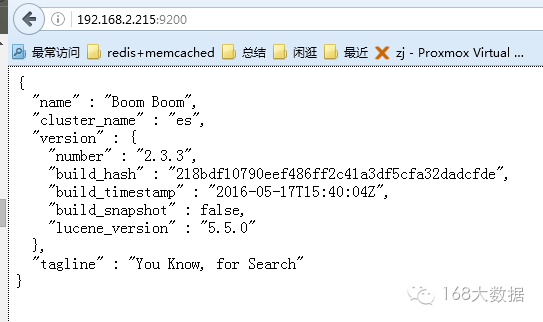
cd usr/share/elasticsearch/bin/./plugin install mobz/elasticsearch-headll usr/share/elasticsearch/plugins/headhttp://192.168.2.215:9200/_plugin/head/
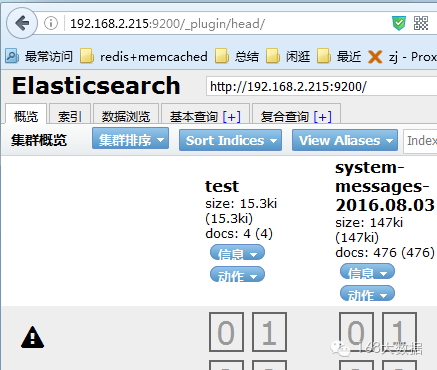 安装kopf插件(集群资源查看和查询插件)/usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopfhttp://192.168.2.215:9200/_plugin/kopf
安装kopf插件(集群资源查看和查询插件)/usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopfhttp://192.168.2.215:9200/_plugin/kopf
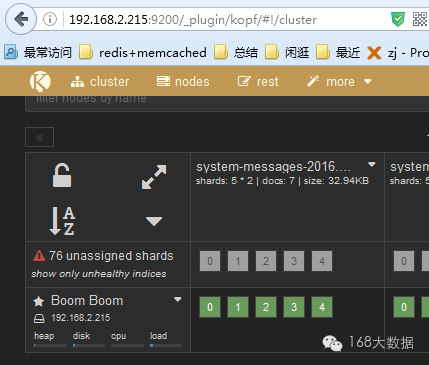
启动elasticearch/etc/init.d/elasticsearch start
安装kibanakibana本质上是elasticsearch web客户端,是一个分析和可视化elasticsearch平台,可通过kibana搜索、查看和与存储在elasticsearch的索引进行交互。可以很方便的执行先进的数据分析和可视化多种格式的数据,如图表、表格、地图等。
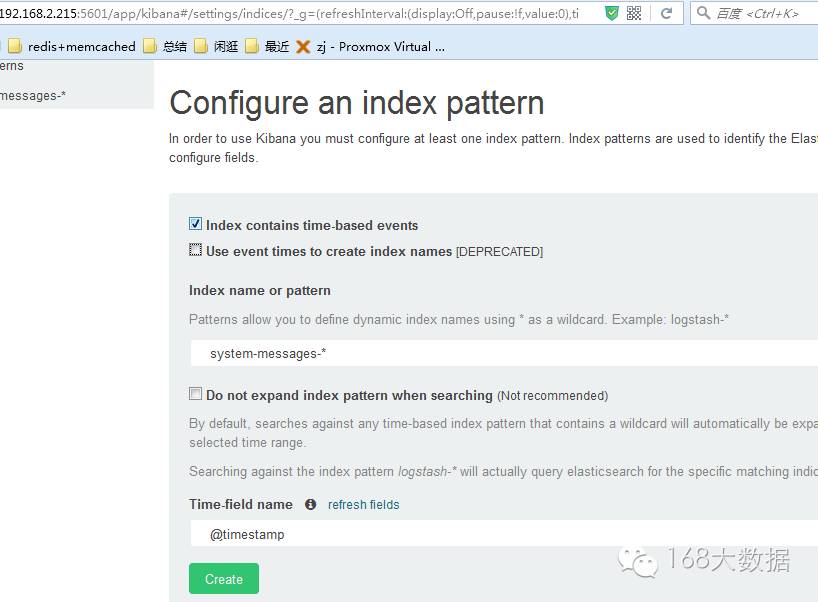
Discover页面:交互式的浏览数据。可以访问所匹配的索引模式的每个索引的每个文档。可以提交搜索查询,过滤搜索结果和查看文档数据。还可以搜索查询匹配的文档数据和字段值的统计数据。还可以选定时间以及刷新频率https://download.elastic.co/kibana/kibana/kibana-4.5.1-linux-x64.tar.gztar zxvf kibana-4.5.1-linux-x64.tar.gzmv kibana-4.5.1-linux-x64 usr/local/vi etc/rc.local/usr/local/kibana-4.5.1-linux-x64/bin/kibana > var/log/kibana.log 2>&1 &vi usr/local/kibana-4.5.1-linux-x64/config/kibana.ymlserver.port: 5601server.host: "192.168.2.215"elasticsearch.url: "http://192.168.2.215:9200"
将nginx日志转换成json
vim usr/local/nginx/conf/nginx.conflog_format access1 '{"@timestamp":"$time_iso8601",' '"host":"$server_addr",' '"clientip":"$remote_addr",' '"size":$body_bytes_sent,' '"responsetime":$request_time,' '"upstreamtime":"$upstream_response_time",' '"upstreamhost":"$upstream_addr",' '"http_host":"$host",' '"url":"$uri",' '"domain":"$host",' '"xff":"$http_x_forwarded_for",' '"referer":"$http_referer",' '"status":"$status"}'; access_log var/log/nginx/access.log access1;
重新载入nginx
/usr/local/nginx/sbin/nginx -s reload
安装logstash在logstash中,包括了三个阶段:输入input --> 处理filter(不是必须的) --> 输出output
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearchecho "[logstash-2.1]name=Logstash repository for 2.1.x packagesbaseurl=http://packages.elastic.co/logstash/2.1/centosgpgcheck=1gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearchenabled=1" >> etc/yum.repos.d/logstash.repoyum install logstash -y通过配置验证Logstash的输入和输出vim etc/logstash/conf.d/stdout.confinput { stdin {}}
output { stdout { codec => "rubydebug" }}
vim etc/logstash/conf.d/logstash.confinput { stdin {}}input { stdin {} }output { elasticsearch { hosts => ["192.168.2.215:9200"] index => "test" }}
http://192.168.2.215:9200/_plugin/head/
vim etc/logstash/conf.d/logstash.conf output { elasticsearch { hosts => ["192.168.2.215:9200"] index => "test" }input { file { type => "messagelog" path => "/var/log/messages"
start_position => "beginning"
}
}
output {
file {
path => "/tmp/123.txt"
}
elasticsearch {
hosts => ["192.168.2.215:9200"]
index => "system-messages-%{+yyyy.MM.dd}"
}
}
检查配置文件语法
/etc/init.d/logstash configtest
vim /etc/init.d/logstash
LS_USER=root
LS_GROUP=root
来源:博客园 zclzhao
与作者留言评论互动吧!
AIBD 2016国际机器智能前沿论坛即将于12月17日在北京举行
原创连载丨从零搭建推荐体系:用户体系、项目体系和推荐体系(中)
免责声明:本站所载内容来源于读者投稿或互联网、微信公众号等公开渠道,纯属作者个人观点,不代表本站立场,仅供读者交流学习,非用于商业用途。转载的稿件版权归原作者或机构所有,如有侵权,请联系删除。投稿、爆料、版权、商务合作请联系:link@bi168.cn
168大数据
168大数据 www.bi168.cn 是国内最具影响力的学习型大数据社群媒体,是专注大数据、商业智能、数据分析、云计算、人工智能等数据科学领域的深度交流、知识分享与职业发展平台,以大数据驱动创业创新和助力传统产业转型升级为使命,致力于为大数据产业的从业者、传统企业、厂商、服务商提供最具价值的资讯、服务与连接。平台聚集了国内外近十万数据领域的创始人CEO、首席技术官、首席数据官、数据科学家、大数据工程师等精英人物,共同致力于大数据技术、大数据价值、大数据思维的传播、交流与分享。
加入大数据高端人脉圈,请微信后台回复:大数据俱乐部
入群暗号:入群姓名-公司-职务,将根据职务分配相关群
也欢迎大家加入:
大数据技术精英会千人QQ群①89294140 ②262822271
SAP HANA+BO交流群:521871032 大数据高管群:364910323
投稿/合作请邮件至link@bi168.cn
大数据讲师入驻:http://form.mikecrm.com/M7zzSY
大数据人才库:http://form.mikecrm.com/ftGxaA
大数据招聘需求:http://form.mikecrm.com/9o2naK

