




SELECT COUNT(*)是一个很经典的问题,也是我经常用来面试MySQL DBA的一个问题。这里面涉及到关于InnoDB表的存储结构、索引、成本计算等诸多方面。下面先通过一个案例来说明一下。
1. 准备工作
(1).创建表结构
CREATE TABLE `t1` (
`a` int(11) NOTNULL AUTO_INCREMENT,
`b` int DEFAULTNULL,
`c` smallintDEFAULT NULL,
`d` char(100)DEFAULT NULL,
PRIMARY KEY(`a`),
KEY `idx_b`(`b`),
KEY `idx_c` (`c`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
(2).构造数据
$ seq 1000000|awk '{print int(10000*rand())+1"\t" int(1000*rand())+1 "\t" 1 }'>t1.txt
mysql> LOAD DATA INFILE 't1.txt' INTO TABLE t1(b,c,d);
Query OK, 1000000 rows affected (22.57 sec)
Records: 1000000 Deleted: 0 Skipped: 0 Warnings: 0
(3).分析表
mysql> ANALYZE TABLE t1;
+---------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+---------+----------+----------+
| test.t1 | analyze | status | OK |
+---------+---------+----------+----------+
(4).查看表统计信息
mysql> show table status like 't1'\G;
*************** 1. row*****************
Name: t1
Engine:InnoDB
Version: 10
Row_format:Compact
Rows:1000125
Avg_row_length:141
Data_length:141197312
Max_data_length: 0
Index_length:45187072
Data_free:6291456
Auto_increment:1048561
Create_time:2015-01-16 19:24:47
Update_time:NULL
Check_time:NULL
Collation:latin1_swedish_ci
Checksum:NULL
Create_options:
Comment:
mysql> show index from t1\G;
********** 1. row **********
Table: t1
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: a
Collation: A
Cardinality: 1000125
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************** 2. row*********
Table: t1
Non_unique: 1
Key_name: idx_b
Seq_in_index: 1
Column_name: b
Collation: A
Cardinality: 21741
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
************** 3. row************
Table: t1
Non_unique: 1
Key_name: idx_c
Seq_in_index: 1
Column_name: c
Collation: A
Cardinality: 1845
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
3 rows in set (0.00 sec)
(5).说明
我构造了一张大表,保存了100万的数据。表存在4个字段,前3个字段都是数字类型,但存储长度不同(SMALLINT为2个字节、INT为4个字节)。第1个字段为主键,后2个字段分别建立了索引。
2.测试SQL
(1).缺省情况
mysql> explain select count(*) from t1\G;
*************** 1. row***********
id: 1
select_type:SIMPLE
table: t1
type:index
possible_keys: NULL
key:idx_c
key_len: 3
ref: NULL
rows:1000125
Extra:Using index
1 row in set (0.00 sec)
选择使用普通索引(idx_c)扫描。
(2).禁用索引idx_c
mysql> explain select count(*) from t1 ignoreindex(`idx_c`)\G;
*************** 1. row ************
id: 1
select_type:SIMPLE
table: t1
type:index
possible_keys: NULL
key:idx_b
key_len: 5
ref: NULL
rows:1000125
Extra:Using index
1 row in set (0.00 sec)
选择使用普通索引(idx_b)扫描。
(3).禁用索引idx_c、idx_b
mysql> explain select count(*) from t1 ignoreindex(`idx_c`) ignore index(`idx_b`)\G;
************* 1. row***********
id: 1
select_type:SIMPLE
table: t1
type:index
possible_keys: NULL
key:PRIMARY
key_len: 4
ref: NULL
rows:1000125
Extra:Using index
1 row in set (0.00 sec)
选择使用主键扫描。
(4).禁用索引idx_c、idx_b、primary key
mysql> explain select count(*) from t1 ignoreindex(`idx_c`) ignore index(`idx_b`) ignore index(`PRIMARY`)\G;
************* 1. row***********
id: 1
select_type:SIMPLE
table: t1
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows:1000125
Extra:
1 row in set (0.00 sec)
选择使用全表扫描。
(5).总结
通过上面4种情况可见,对COUNT(*)操作,MySQL是按照索引(索引字段存储长度小)、索引(索引字段存储长度大)、主键、全表扫描的方式完成。
通过跟踪具体得执行步骤可见,主键扫描和全表扫描的整体开销是一样的。
四种情况的成本都是一样的。这也说明了在MySQL的优化器中,没有严格按照基于成本的优化器选择,也有一些基于内部规则的。
3.问题解答
针对上面的执行结果,可能有一些疑问。我有针对性地解答一下。
(1).为什么没有走主键,而是走了普通索引?
传统印象里,对COUNT(*)操作应该走主键索引扫描,但在上例中没有。其原因是在MySQL中(特指在InnoDB中),表是按照B+树索引结构存储的。换句话说,表本身就是索引。其存储结构类似下面:
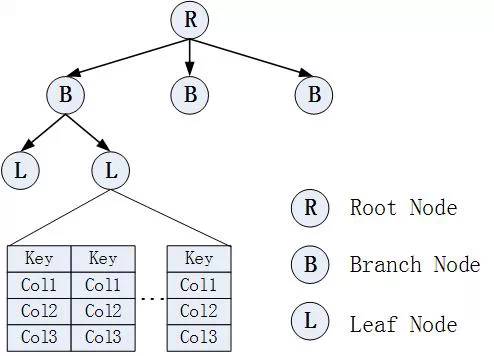
在这棵树的叶子节点,保存着整行记录,显然这会占用大量数据页。如果是按照主键方式访问的话,则需要遍历大量数据页。但对于索引访问不同,通过下面的索引存储结构查看:
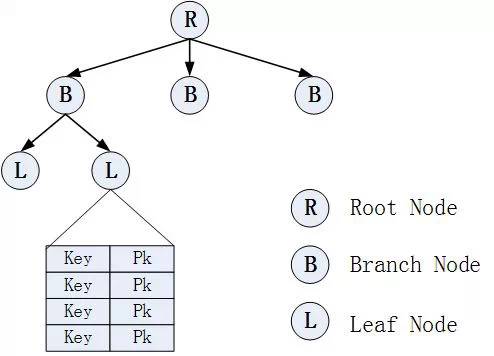
在这棵树中,叶子节点保存的索引键值和对应的主键值。显然,索引的尺寸要远远小于表的尺寸。按照索引访问,则需要只需要遍历较少的数据页。
(2).走索引能返回全部记录数吗?
这里需要明确一下,COUNT(*)是代表着求出记录集的所有行数。在很多数据库中,通过遍历索引是无法取得全部记录数的,究其原因是因为索引不保存空值。但是在MySQL中不同,InnoDB中的B+树索引是存储空值的,也就是说每一条记录都对应于索引的一个键值对,因此遍历索引就可以获得全部记录数。
(3).两个普通索引,如何选择?
在示例中,存在两个普通索引,MySQL优先选择的是索引字段存储长度较小的索引(即idx_c,因为它的索引字段类型是smallint,占用2个字节;而idx_b对应的字段类型为int,占用4个字节)。如果两个字段的存储长度相同,则是按照索引创建顺序来选择索引。
