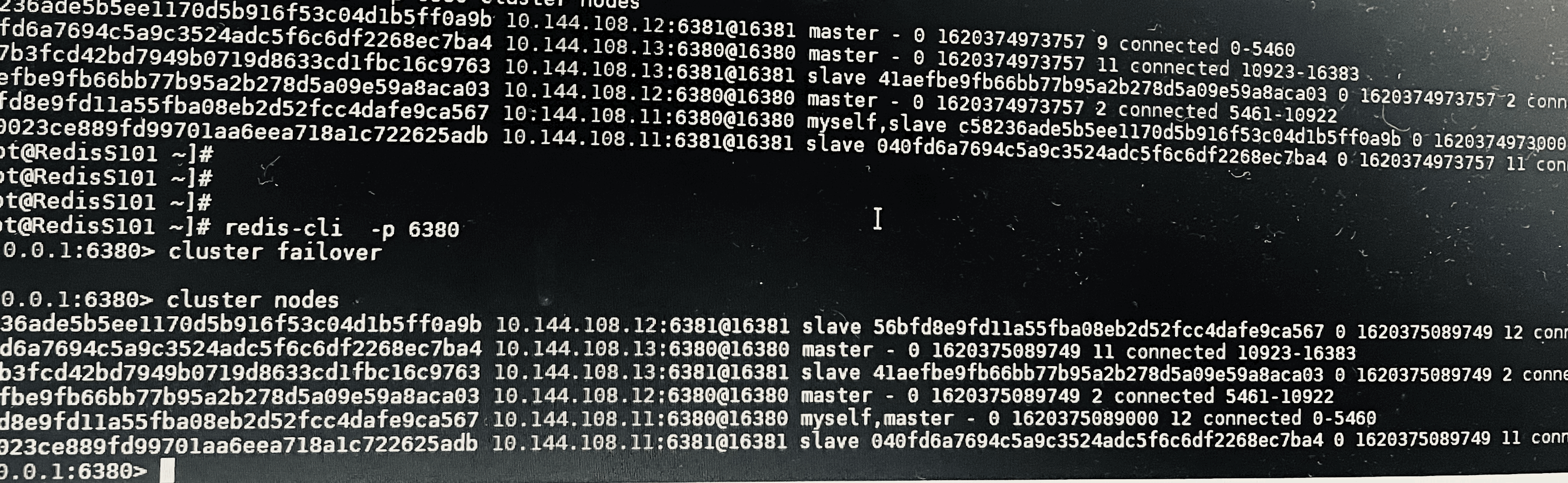
redis手动切换,原主节点 切换成 新主节点
CLUSTER FAILOVER [FORCE|TAKEOVER]
自3.0.0起可用。
时间复杂度: O(1)
该命令只能发送到Redis Cluster副本节点,它强制副本启动其主实例的手动故障转移。
::手动故障转移是一种特殊的故障转移,通常在没有实际故障时执行,但是我们希望以一种安全的方式将当前的主节点与其副本之一(这是我们向其发送命令的节点)交换,没有任何数据丢失的窗口。::
它以以下方式工作:
- 副本告知主机停止处理来自客户端的查询。
- 主服务器以当前复制偏移量回复副本。
- 副本等待复制偏移量在其一侧匹配,以确保副本在继续之前处理了来自主数据库的所有数据。
- 副本启动故障转移,从大多数主服务器获取新的配置纪元,并广播新的配置。
- 旧的主机接收配置更新:解除其客户端的阻止,并开始使用重定向消息进行答复,以便他们继续与新的主机进行聊天。
这样,客户端将原子地从旧的主服务器移到新的主服务器,并且仅当变成新的主服务器的副本处理了来自旧的主服务器的所有复制流时。
强制选项:当主服务器关闭时进行手动故障转移
可以通过两个选项来修改命令行为:FORCE和TAKEOVER。
如果指定了FORCE选项,则副本不会与主服务器进行任何握手,这可能无法实现,而只是从第4点开始尽快启动故障转移。当我们要在主服务器上启动手 动故障转移时,此方法很有用。不再可达。
但是,使用**FORCE,**我们仍然需要大多数主服务器可用,以便授权故障转移并为将成为主服务器的副本生成新的配置时期。
TAKEOVER选项:在没有群集共识的情况下进行手动故障转移
在某些情况下,这还不够,我们希望副本在不与集群其余部分达成任何协议的情况下进行故障转移。一个现实的用例是在所有主数据库都关闭或分区后,将另一个数据中心中的副本大量升级到主数据库,以执行数据中心切换。
该TAKEOVER选项意味着一切FORCE意味着,但也没有任何使用授权集群,以故障转移。副本接收 CLUSTER FAILOVER TAKEOVER将改为:
- configEpoch单方面生成一个新的,仅获取当前可用的最大时期,如果其本地配置时期尚未达到最大,则将其递增。
- 为其自身分配其主节点的所有哈希槽,并将新配置传播到可尽快到达的每个节点,最后传播到每个其他节点。
请注意,TAKEOVER违反了Redis Cluster的last-failover-wins原则,因为副本生成的配置时期在几种方面违反了正常的配置时期: - 不能保证它实际上是较高的配置时期,因为,例如,我们可以在少数群体中使用TAKEOVER选项,也不执行任何消息交换来生成新的配置时期。
- 如果我们生成的配置时期恰巧与另一个实例发生冲突,则最终我们的配置时期或具有相同时期的另一个实例中的一个会使用配置时期冲突解决算法来移开。
因此,应谨慎使用TAKEOVER选项。
实施细节和注意事项
除非指定了TAKEOVER选项,否则 CLUSTER FAILOVER 不会同步执行故障转移,它只会安排手动故障转移,绕过故障检测阶段,因此要检查故障转移是否确实发生,应使用 CLUSTER NODES 或其他方式进行发送命令一段时间后,请验证集群的状态是否已更改。
返回值
OK
如果命令被接受并且将尝试进行手动故障转移。
如果无法执行该操作(例如,如果我们正在与已经是主节点的节点进行对话),则会发生错误。
适用情况
1.指定的主机进行主从切换
2.意外发生主从切换之后,手动恢复主从顺序
实例如下: