




深度学习是一个计算能力需求强烈的领域,GPU的选择将从根本上决定深度学习研究过程和体验。选择一个好的,合适的GPU以及基于GPU的运行环境,研究人员和企业可以快速开始迭代深度学习网络,几个月的实验可以在几天之内跑完,几天的实验可以在几个小时之内跑完。
拥有高速GPU是开始学习深度学习的一个非常重要的方面,因为这可以快速获得实践经验,这是搭建专业知识的关键,有足够的时间将深度学习应用于解决新问题。如果没有这种快速的反馈,就需要花费太多的时间从错误中学习。因此,GPU以及基于GPU的运行环境,正确的选择至关重要。
对于深度学习来说,算力是一切的根本。为了用海量数据训练性能更好的模型、加速整个流程,企业的 IT 系统需要具备快速、高效调用管理大规模 GPU 资源的能力。同时,由于算力资源十分昂贵,出于成本控制,企业也需要通过分布式训练等方式最大化 GPU 资源利用率。
现如今,随着企业纷纷在机器学习和深度学习上加大投入,企业开始发现从头构建一个 AI 系统并非易事。面对这类新要求,基于 Kubernetes 的云原生技术为人工智能提供了一种新的工作模式。凭借其特性,Kubernetes可以无缝将模型训练部署扩展到云 GPU 集群,允许数据科学家跨集群节点自动化多个 GPU 加速应用程序容器的部署、维护、调度和操作。

通过云部署的Kubernetes GPU 环境,可以帮助机器学习研究和企业很大程度上实现降本增效。具体来说体现在三个方面:
加速部署:通过容器构想避免重复部署机器学习复杂环境;
提升集群资源使用率:统一调度和分配集群资源;
保障资源独享:利用容器隔离异构设备,避免互相影响。
首先是加速部署,避免把时间浪费在环境准备的环节中。通过容器镜像技术,将整个部署过程进行固化和复用,如果同学们关注机器学习领域,可以发现许许多多的框架都提供了容器镜像。我们可以借此提升 GPU 的使用效率。通过分时复用,来提升 GPU 的使用效率。当 GPU 的卡数达到一定数量后,就需要用到 Kubernetes 的统一调度能力,使得资源使用方能够做到用即申请、完即释放,从而盘活整个 GPU 的资源池。
Oracle Cloud Infrastructure Container Engine for Kubernetes (OKE) 是适用于Oracle云基础架构容器引擎, 是一项完全托管,可扩展且高度可用的服务,可用于将容器化的应用程序部署到云中。OKE借助OCI GPU卓越的性能优势,提供GPU工作负载容器化的运行环境,其中最新型NVIDIA A100 GPU 利用基于远程直接内存访问(RDMA)的Oracle低延迟集群网络,可以托管多个GPU集群并按需扩展。
在OKE上部署并运行容器化的GPU 工作负载只需简单三步:
1.初始化OKE集群,工作节点池,选择GPU节点类型。

OCI OKE 会自动匹配含该GPU类型的驱动类型的镜像。
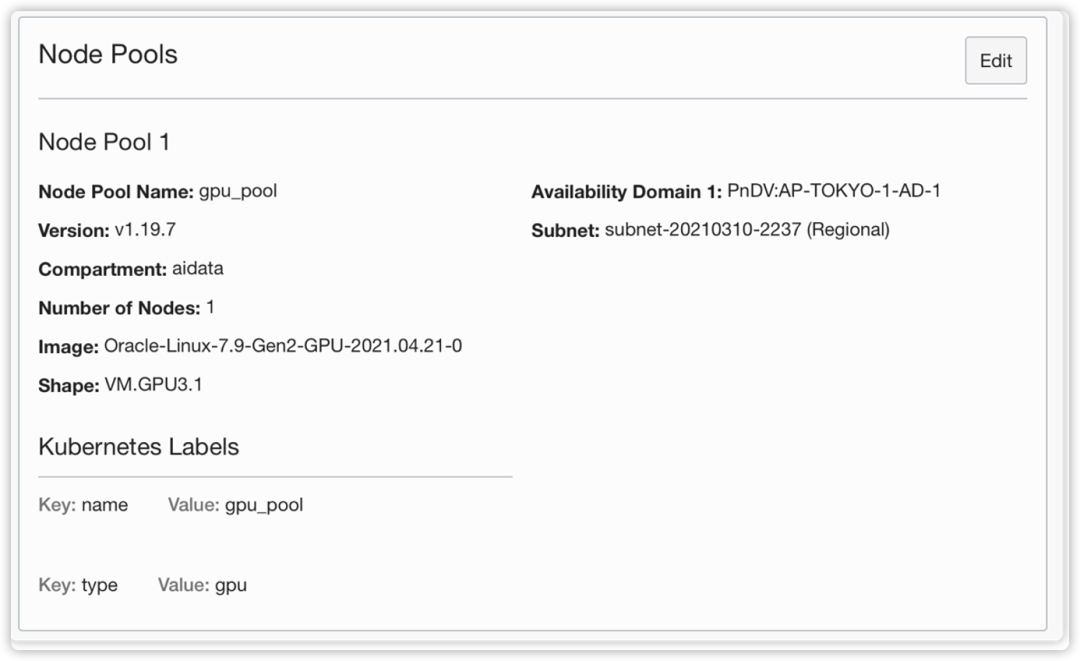
OKE集群创建成功后的节点资源池。
2.部署容器化的GPU应用到OKE集群
Yaml文件中配置指定使用的GPU资源,以及GPU工作负载镜像。
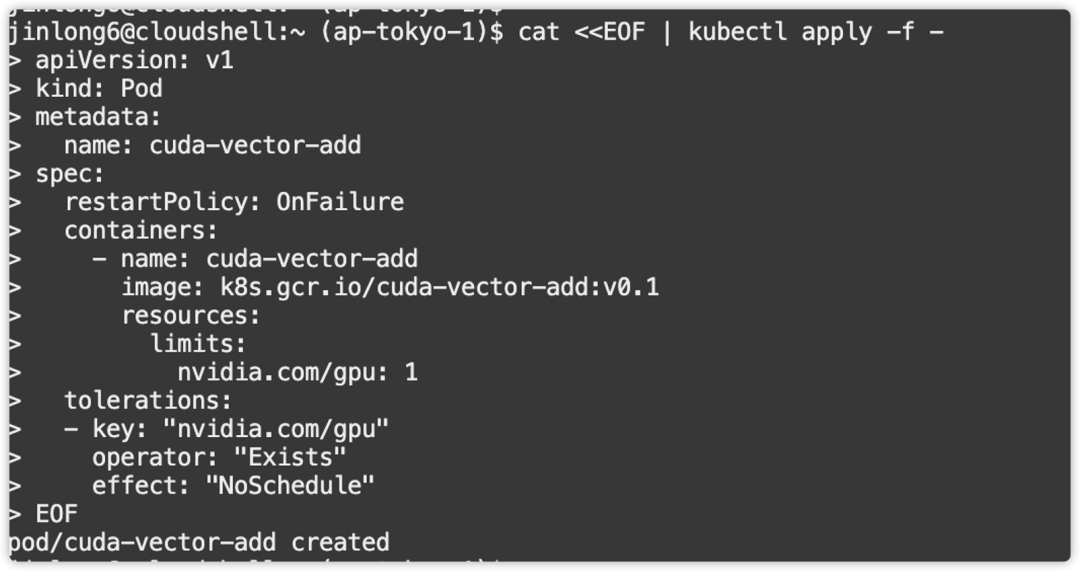
3.管理GPU工作负载运行状态,及查看运行结果
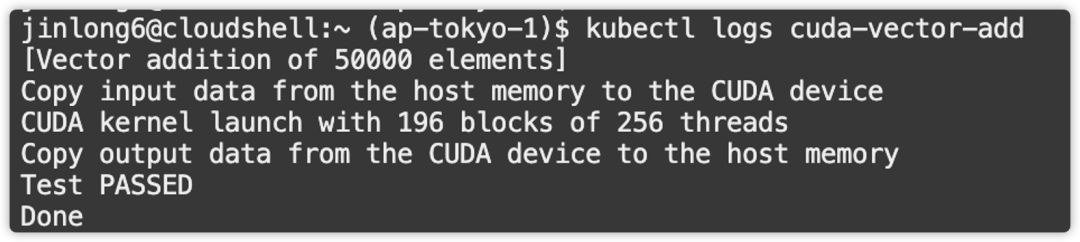
GPU程序运行成功,并正常退出。
以上是一种简单的运行GPU示例程序的方式,实际上,在GPU 容器应用部署调度过程中,可以结合OKE的Cluster Autoscaler功能特性自动伸缩GPU Node节点,Cluster Autoscaler 是一个可以自动伸缩集群 Node 的组件。如果集群中有未被调度的 Pod,它将会自动扩展 Node 来使Pod 可用,或是在发现集群中的 Node 资源使用率过低时,删除 Node 来节约资源,通过这种调度方式来达到GPU资源的高效利用。
欢迎登陆Oracle OCI Console体验更多OKE GPU功能。

作者简介
向志华,甲骨文云架构团队高级解决方案专家,专注 Application PaaS 产品及服务,同时关注Docker容器产品及Kubernetes容器调度产品方向。13年IT行业从业经验,擅长J2EE产品架构及开发,参与过Openstack相关产品研发工作。您可以通过george.xiang@oracle.com,与他联系。
