




【第一篇详见】
0048.D Prometheus+Grafana监控DorisDB(一)

DorisDB提供两种监控报警的方案,第一种是使用内置的DorisManager,其自带的Agent从各个Host采集监控信息上报到Center Service然后做可视化展示,也提供了邮件和Webhook的方式发送报警通知。
但是如果用户为了二次开发需求,需要自己搭建部署监控服务,也可以使用开源的Prometheus+Grafana的方案,DorisDB提供了兼容Prometheus的信息采集接口,可以通过直接链接BE/FE的HTTP端口来获取集群的监控信息。
如果采购DorisDB企业版,则提供DorisManager组件;
如果使用Apache Doris、DorisDB标准版、百度Palo,则需要采用开源Prometheus+Grafana监控方案。

文中多图预警=> 文中多图预警 <=文中多图预警
4. Grafana添加promethues数据源
1) 首页点击“data sources”
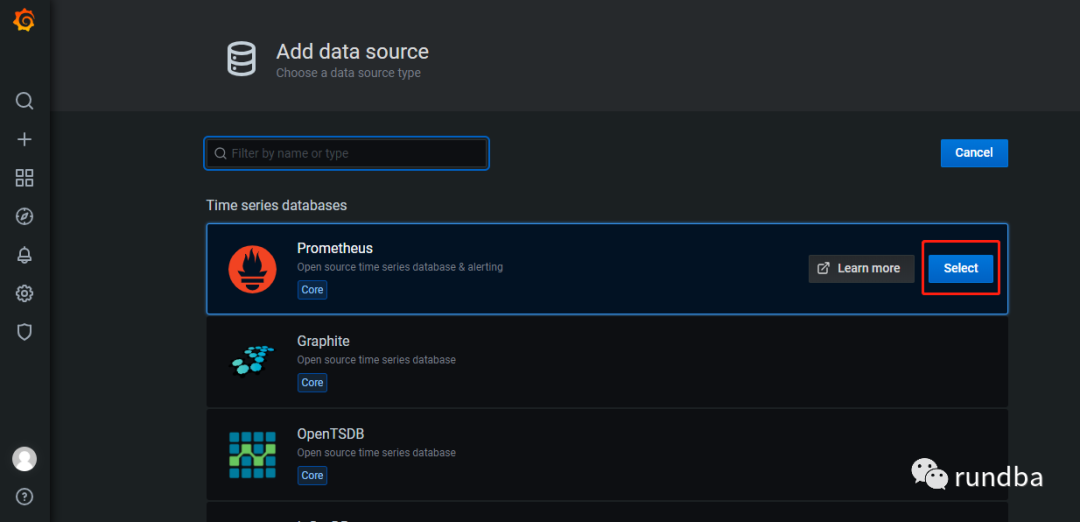
2) 点击“Prometheus”-“Select”
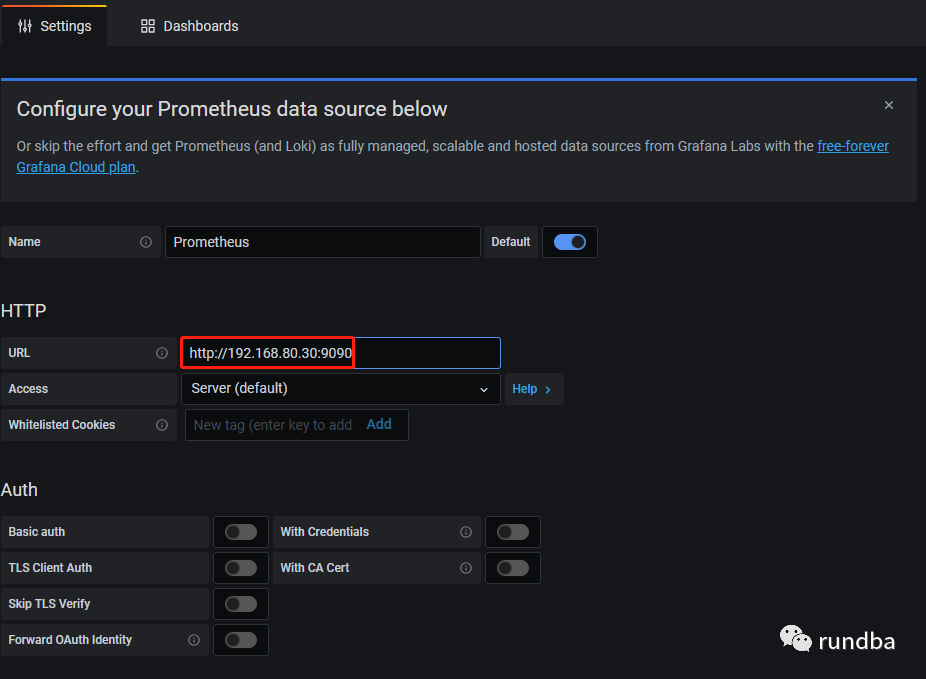
3) 输入名称,服务器地址及端口
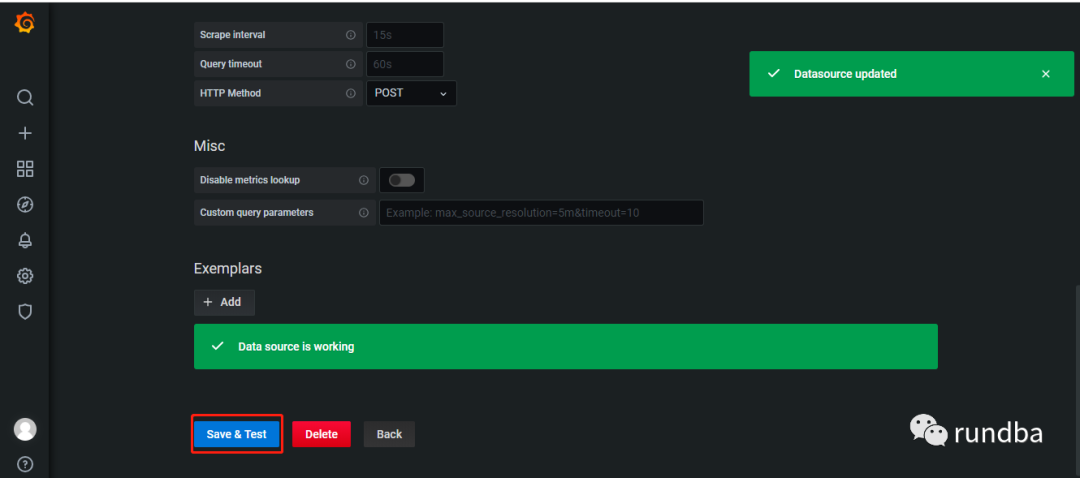
4) 点击“保存和测试”
5. Grafana添加DorisDB监控模板
1) Grafana首页,点击“+”--“Import”
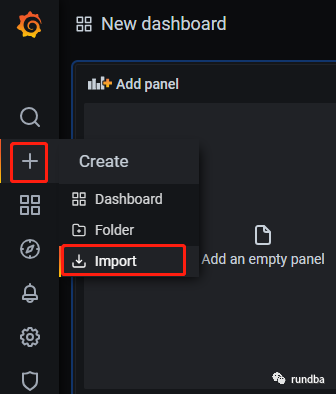
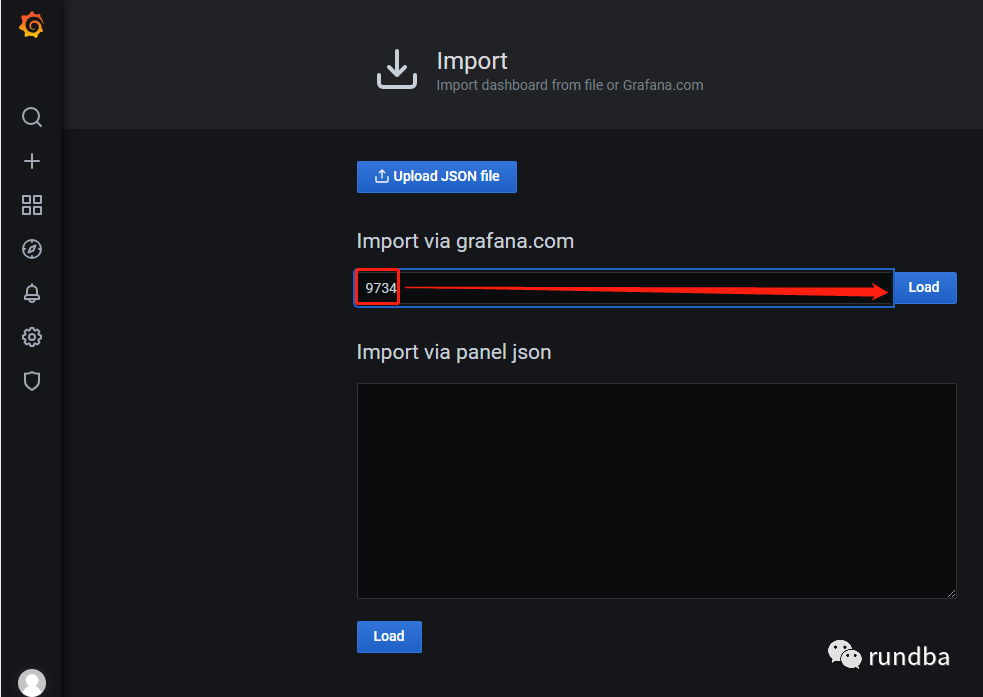
2) 输入DorisDB JSON文件编号9734,点击Load
或者输入https://Grafana.com/Grafana/dashboards/9734
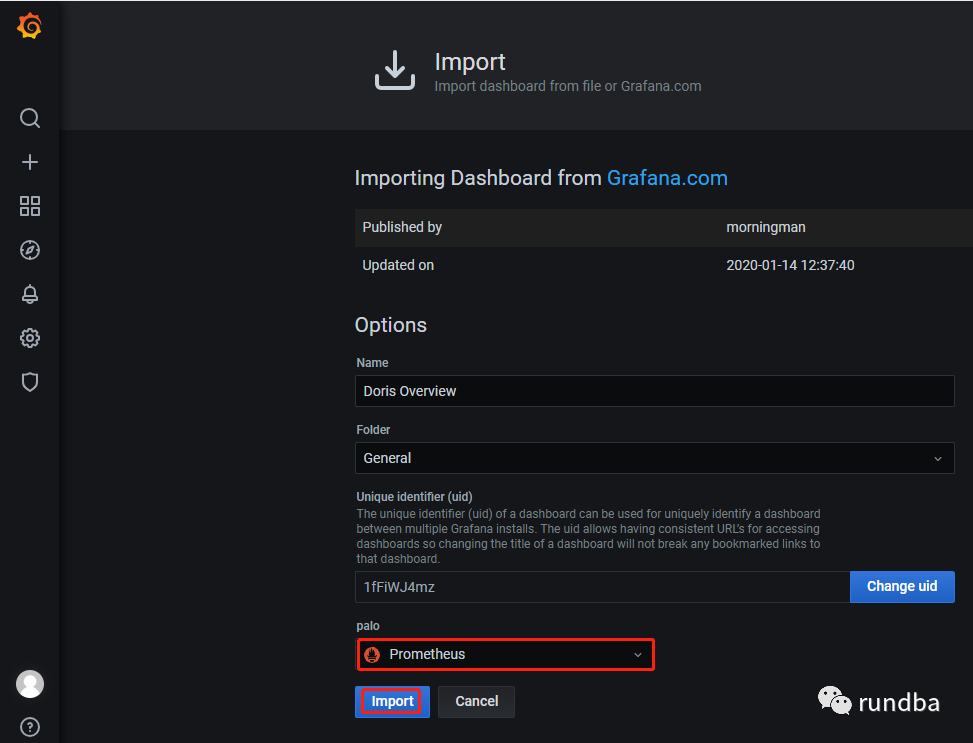
3) Palo一栏选择“Premethues”,点击“Import”
6. Prometheus监控DorisDB
1) Promethues配置文件添加DorisDB内容
vim monitor/prometheus/prometheus.yml #添加如下内容# DorisDB CLUSTER 1- job_name: 'CLUSTER1'metrics_path: '/metrics'static_configs:- targets: ['doris1:8030', 'doris2:8030']labels:group: fe- targets: ['doris1:8040', 'doris2:8040', 'doris3:8040']labels:group: be复制
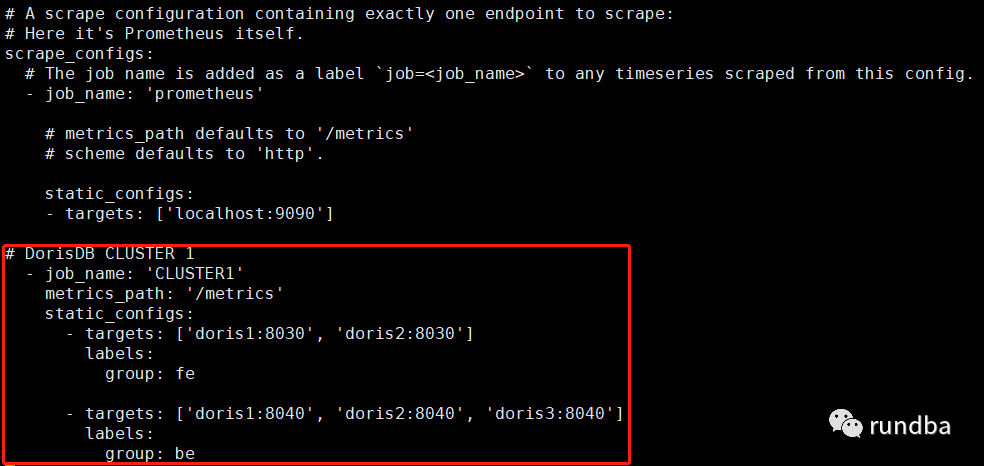
注意缩进格式,非正常缩进可能导致监控异常。
2) 配置文件说明
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'PALO_CLUSTER' #每一个Doris集群,我们称为一个job。这里可以给job取一个名字,作为Doris集群在监控系统中的名字。metrics_path: '/metrics' #这里指定获取监控项的restful api。配下面的targets中的 host:port,Prometheus 最终会通过host:port/metrics_path来采集监控项。static_configs: #这里开始分别配置FE和BE的目标地址。所有的FE和BE都分别写入各自的group中。- targets: ['fe_host1:8030', 'fe_host2:8030', 'fe_host3:8030']labels:group: fe #这里配置了fe的group,该group中包含了3个Frontends- targets: ['be_host1:8040', 'be_host2:8040', 'be_host3:8040']labels:group: be #这里配置了be的group,该group中包含了3个Backends复制
3) 热加载使配置生效
curl -XPOST http://localhost:9090/-/reload复制
7. Grafana+Prometheus监控DorisDB效果展示
Prometheus提供监控抓取,附带TSDB时序数据存储功能,Grafana提供展示功能,将监控数据进行展示。
1) 点击“Search”

2) 点击Doris Overview
3) DorisDB监控内容
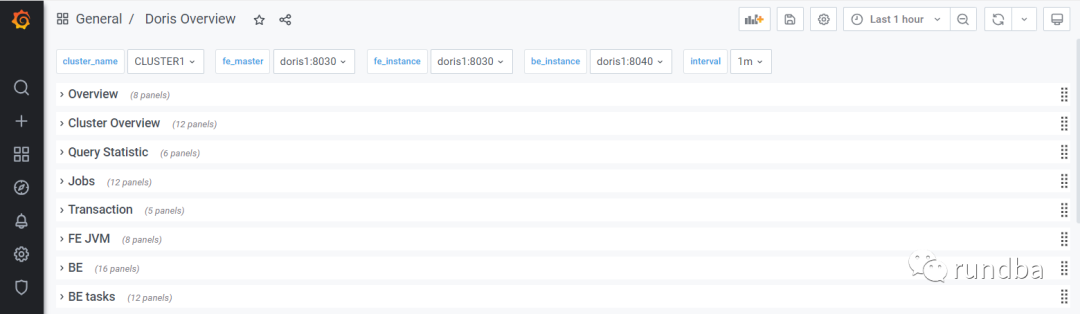
Grafana 中,Row 的概念,即一组图表的集合。如上图中的 Overview、Cluster Overview 即两个不同的 Row。可以通过点击 Row,对 Row 进行折叠。当前 Dashboard 有如下 Rows(持续更新中):
Overview: 所有DorisDB集群的汇总展示;
Cluster Overview: 选定集群的汇总展示;
Query Statistic: 选定集群的查询相关监控;
Jobs:数据加载汇总;
Transaction:事物运行监控;
FE JVM: 选定 Frontend 的 JVM 监控;
BE: 选定集群的 Backends 的汇总展示;
BE Tasks: 选定集群的 Backends 任务信息的展示。
4) 监控数据展示
Overview:
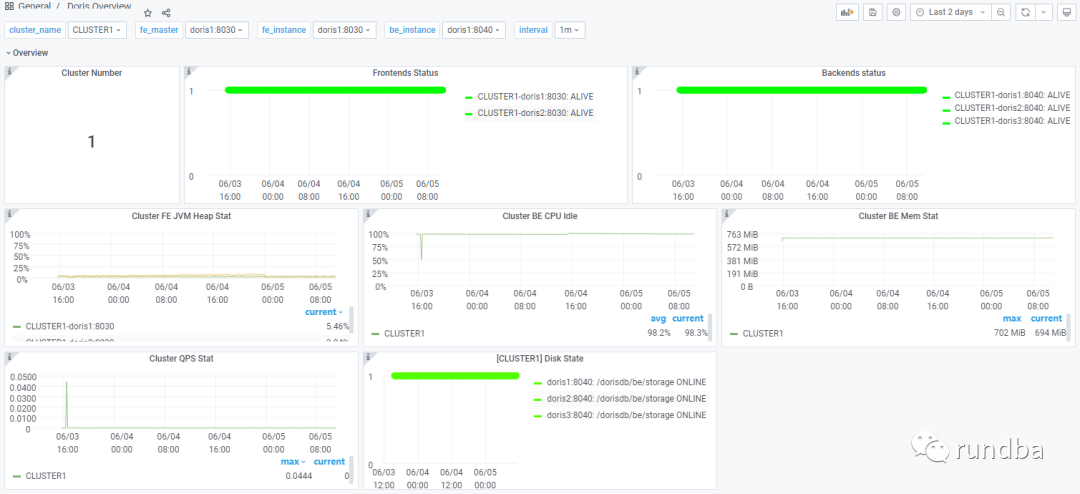
Cluster Overview:

Query Statistic:
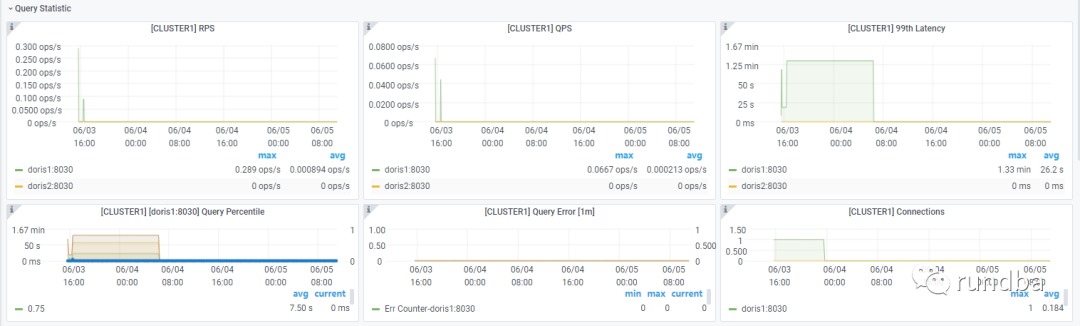
Jobs:

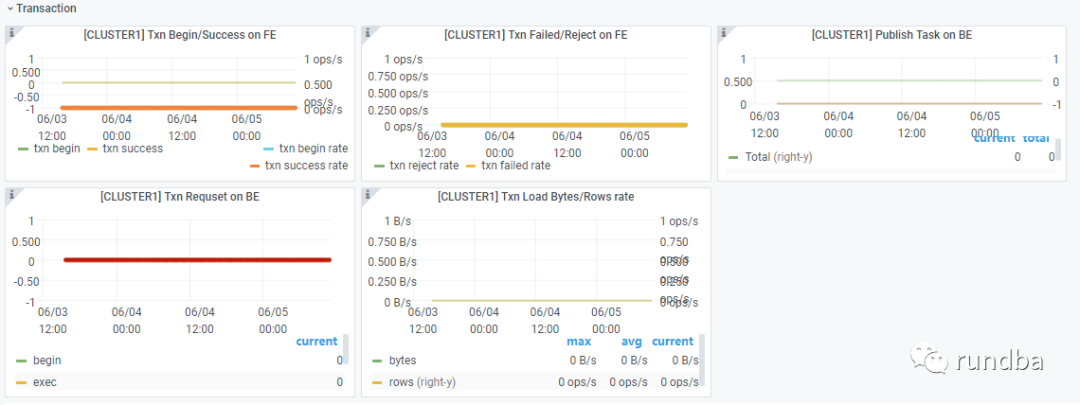
Transaction:
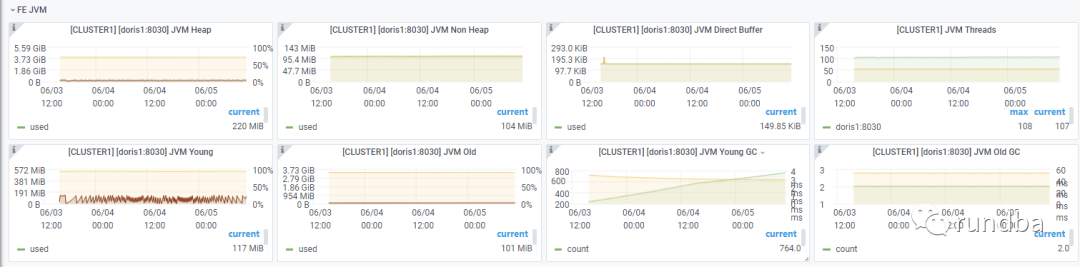
FE JVM:
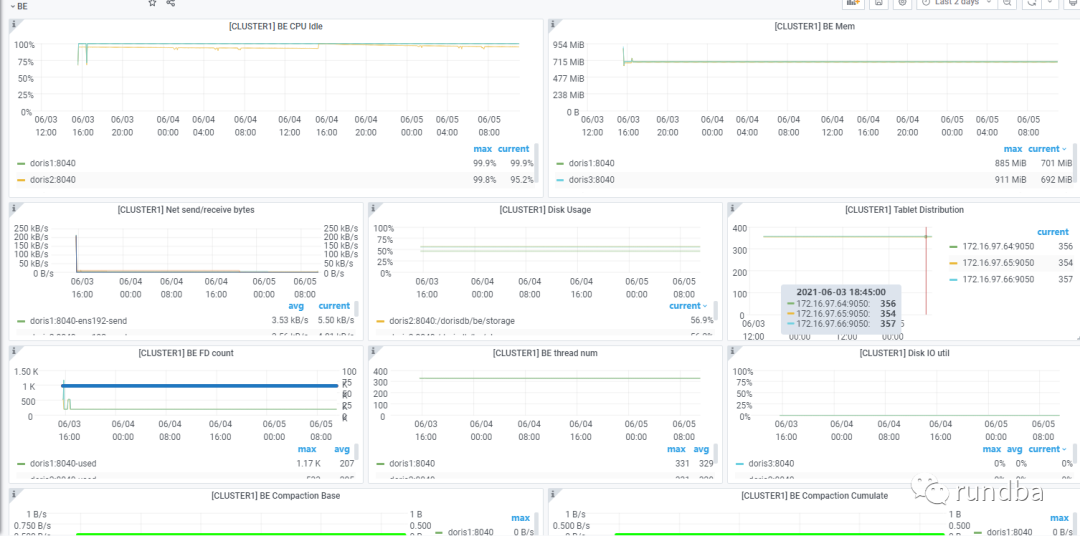
BE:
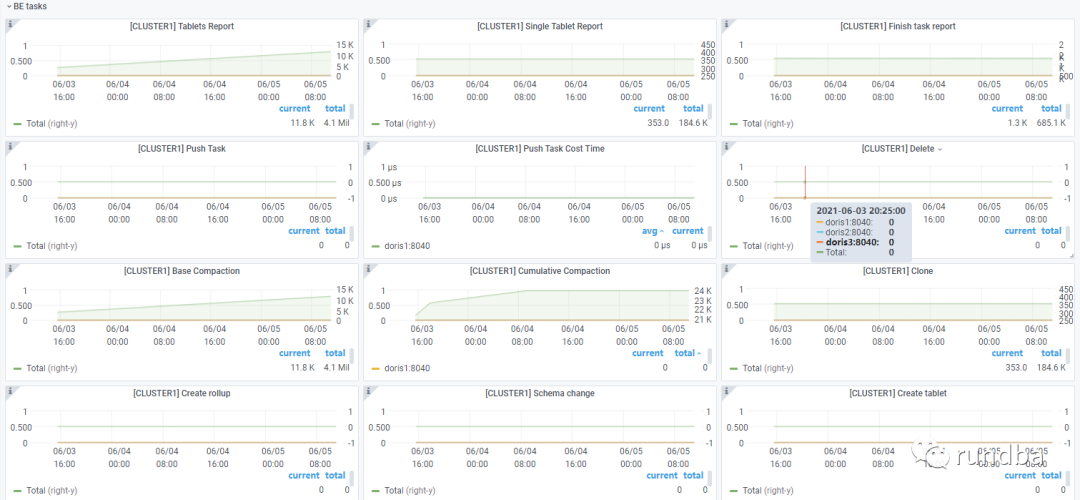
BE Tasks:
8. 小结
在未有DorisManager情况下,文中通过Prometheus+Grafana监控DorisDB进行了操作实现。
对DorisDB主机监控可采用Prometheus的node_exporter模块实现,后续将在其它篇幅展示,告警可采用Prometheus的alertmanager方式实现。
作者:王坤,微信公众号:rundba,欢迎转载,转载请注明出处。
如需公众号转发,请联系wx:landnow。


