




点 击 金 融 科 技 顾 问 即 可 关 注

摘要(长度: 4100字,时长: 12分钟)
融合式架构是终极大数据系统的答案吗?
1
湖仓一体:统一架构走上舞台
“湖仓一体(Lakehouse)”是近来热门的大数据系统架构设计方法。随着Iceberg(Netflix)、Hudi(Uber)、Delta Lake(Databricks)三大开源数据湖项目的应用,亦看得出云计算厂商、大数据平台供应商、互联网公司,越来越多地在推广其“湖仓一体”产品方案。
“湖仓一体”的诞生有数字化时代的背景因素,也有行业痛点的驱动因素。从大数据架构的发展历程来看,无论是基于一体机、MPP架构,还是基于Hadoop框架的大数据平台构建方法,实质目标都是一个:解决大量数据存储、离线批量计算或实时流计算,并满足上层决策分析应用。传统数据仓库对于存储结构和schema有着清晰的定义;数据湖则更为关注数据存储本身而无需满足特定的schema,目的在于解决多样化数据的存储问题。在产业数字化转型的浪潮下,数据作为数字科技驱动业务转型的重要生产要素,企业搭建数字化平台,将大量结构化、半结构化与非结构化数据收集、汇聚起来,并期望同时获得数据标准化、多样化数据类型支持、决策分析应用的支持;与此同时,又希望通过一致性的数据架构满足多样化场景分析的要求,而不是搭建多套数据系统来实现。
基于此背景,“湖仓一体”概念的背后是试图实现数据仓库、数据湖融合的解决方案,同时满足海量数据资源积累、数据价值创造的要求。从定义来看,“湖仓一体”数据架构至少包括以下特点:
首先是一个分布式数据系统
具备分布式文件系统,如HDFS、阿里云Pangu
具备对象存储,如阿里OSS、Amazon S3,支持如Apache Parquet、ORC文件格式
支持元数据Meta、Schema定义
支持分布式事务ACID
支持基于AI和BI的数据分析
数据类型多样化,支持结构化、文件、视频、日志、音频等类型
存算分离:提供存储集群快速扩展、计算集群快速扩展的能力
流批一体:同时支持离线引擎如Spark、实时计算如Flink
开放性:支持Iceberg、Hudi、Delta Lake这类开源数据湖框架
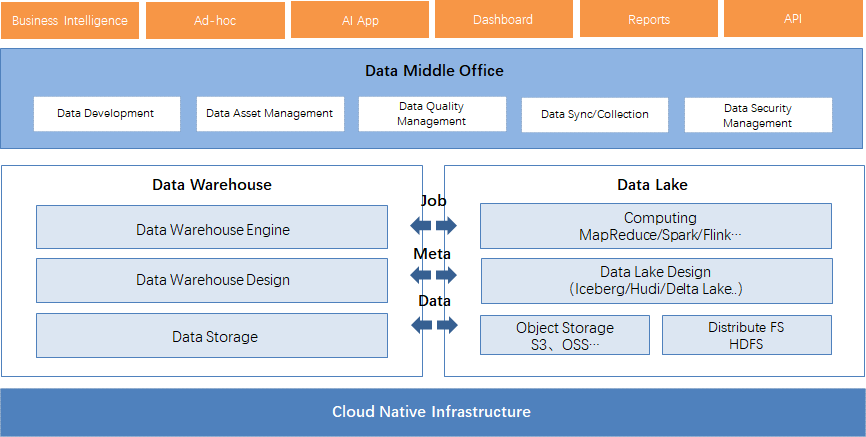
图:“湖仓一体Lakehouse”架构
不可否认,“湖仓一体”这种一体化数据架构,解决了数据湖与数据仓库分开建设所带来的数据冗余问题,通过对象存储解决了大量小文件存储的问题,降低了数据存储成本问题,打破了过去的复杂数据架构体系,提供了一致性的数据平台来满足多样化的场景应用。不过,我对于传统企业是否具备迫切的数据湖需求仍抱有疑问。对于互联网企业场景来说,业务本身来自于数据智能技术的驱动,需要对离线、实时作业任务统一管理,以及对多样化数据格式的灵活访问和快速分析;但在传统企业中,业务数据化的基本能力尚未构建,对数据价值和数字化业务的理解还非常初期,尤其数据存储层面仍以传统关系型、结构化数据库为主,距离利用IoT、视频、图像等非结构化数据创造商业价值还较远。这一过程一定是漫长的。
我并不建议传统企业寄期望于通过一套“湖仓一体”平台,就能够实现数字化跃迁。通过一次性建设平台就完成全面的数字化业务能力并不现实。近年来计算引擎、架构方案的新概念与新工具层出不穷,从务实的角度看,追求数据系统的架构优化一定是合理的。但从场景出发,建立数据驱动业务增长的良好机制则更为关键。此外,不少企业或多或少已经具备了Hadoop集群、MPP或传统数仓以及大数据平台,重建“湖仓一体”意味着对原有多样化数据架构体系的重构,想要顺利的完成这种架构一致性的切换和原有数据平台的迁移亦不是一件容易的事。
2
HTAP:多模融合数据库的快进
HTAP(Hybrid Transaction and Analytical Process)不是一个新概念,近来又随着蚂蚁集团OceanBase数据库跑出了TPC-H世界纪录,成为了数据库界热议的话题。而本次峰会上值得关注的是,其自研PolarDB数据库亦会向HTAP发力。
在2018年《大数据架构:HTAP与Hadoop的定位与竞合》这篇文章中,我对HTAP描述的并不是特别充分,只是站在HTAP与SQL on Hadoop的混合式架构角度提出了一种适配事务、数仓等多种应用场景的解决方案。那个时期的HTAP仍或多或少存在一定的贴标签色彩——越来越多的分布式数据库厂商,宣称同时支持OLTP事务与OLAP分析复合处理能力。厂商往往从TP侧的事务处理能力出发,目标提供“去Oracle”的国产数据库解决方案。像Oceanbase、TiDB、PolarDB-X等,基于shared-nothing的分布式可扩展MPP架构,基于Paxos、Raft等分布式一致性协议实现,对高并发、大批量数据的查询优化、向量化处理有较好的支持。当然,在同一套引擎中同时实现TP和AP混合负载、又要确保资源逻辑隔离,技术实现上的确不容易。
而到了今天,从TPC-C和TPC-H的测试结果来看,国产分布式数据库已充分具备了多模融合数据库系统能力。虽然说让HTAP去同时替代关系数据库和ROLAP引擎(如ClickHouse)还为时尚早,但不能否认多模融合数据库进入商用化数仓分析领域的趋势将会越来越明显。作为基础设施"三大件"(芯片、操作系统、数据库)之一,数据库技术的发展近年来愈发呈现多样性、百花齐放的状态,这对于企业基于不同场景选择不同的技术路线是有利的。
对于HTAP数据库来说,当下的难点不仅是在国际测试中证明自己的实力,而是从真实业务场景中验证事务处理、数据分析双重身份的能力,从而逐步满足汰换要求。从现状来看,距离这一目标仍为时尚早。从关系数据库市场来看,无论是企业还是社区开发者,仍大量采用MySQL、PostgreSQL、MongoDB等开源数据库。而在技术多样性更为复杂的OLAP领域,Teradata、SAP HANA、微软等传统数仓,基于MPP架构的ROLAP引擎、基于Kylin的MOLAP引擎,以及多种开源生态的技术产品,都有自己的技术思路和应用场景,也绝非HTAP数据库短期内所能替代。
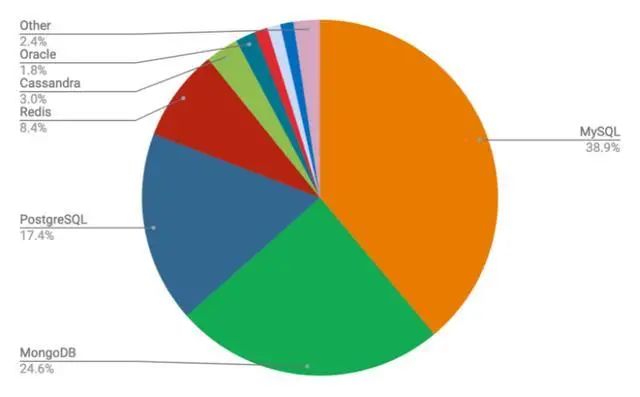
2019年数据库开发者调研(来源:DeveloperWeek)
当然,HTAP数据库当下比较热也是由于国产化替代的呼声。厂商更更合理的策略是走出自己的特色技术路线、以及从专属的应用场景方案来切入,而不是演变成一种样样都能干、每样都有限的“叫好不叫座”状态。此外,开放也是一种机会。近来数据库社区最重大消息就是蚂蚁OceanBase即将开源,而这和我过去的推测是一致的。从封闭到开源,将加速国产化替代过程和商业化生态搭建,不管对于企业还是社区无疑都是利好。
3
云原生:大数据与数据库一体化
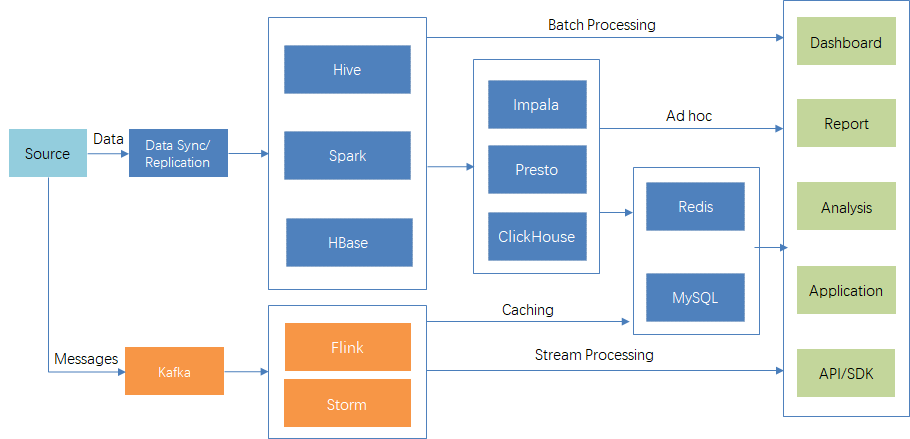

图:利用融合式数据系统简化复杂数据链路
4
思考:融合是大数据系统的答案吗?
专注于金融科技原创文章与深度思考
欢迎在文章下方留言与交流




原创文章,转载请申请白名单。媒体转载请事先取得授权,并请注明来自“(公众号)金融科技顾问 | 作者 祖峰”
感谢支持与分享

