




引言
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能(OLAP)和数据挖掘等。自2015年10月正式开源以来,受到国内外业内人士的广泛关注。大数据是个炙手可热的词,各行各业都在谈。一谈到大数据,好多人认为就是Hadoop。实际上Hadoop只是大数据若干处理方案中的一个。现在的SQL、NoSQL、NewSQL、Hadoop等等,都能在不同层面或不同应用上处理大数据的某些问题。而Greenplum数据库做为一个分布式大规模并行处理数据库,在大多数情况下,更适合做大数据的存储引擎、计算引擎和分析引擎。先进的MPP架构,完善的标准支持,支持分布式事务,良好的线性扩展能力等都使其在商业应用中体现出了良好的潜力,下文将就Greenplum的基本框架进行简单介绍和分析。
一、架构分析
Greenplum的高性能得益于其良好的体系结构。Greenplum的架构采用了MPP (Massive Parallel Processor,大规模并行处理)。在MPP系统中,每个SMP(SymmetricMulti-Processing,对称多处理结构的简称,是指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。在这种技术的支持下,一个服务器系统可以同时运行多个处理器,并共享内存和其他的主机资源。)节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(DataRedistribution)。与传统的SMP架构明显不同,通常情况下,MPP系统因为要在不同处理单元之间传送信息,所以它的效率要比SMP要差一点,但是这也不是绝对的,因为MPP系统不共享资源,因此对它而言,资源比SMP要多,当需要处理的事务达到一定规模时,MPP的效率要比SMP好。这就是看通信时间占用计算时间的比例而定,如果通信时间比较多,那MPP系统就不占优势了,相反,如果通信时间比较少,那MPP系统可以充分发挥资源的优势,达到高效率。当前使用的OTLP程序中,用户访问一个中心数据库,如果采用SMP系统结构,它的效率要比采用MPP结构要快得多。而MPP系统在决策支持和数据挖掘方面显示了优势,可以这样说,如果操作相互之间没有什么关系,处理单元之间需要进行的通信比较少,那采用MPP系统就要好,相反就不合适了。
Sharednothing架构
常见的OLTP数据库系统常常采用shared everything架构来做集群,例如oracle RAC架构,数据存储共享,节点间内存可以相互访问。
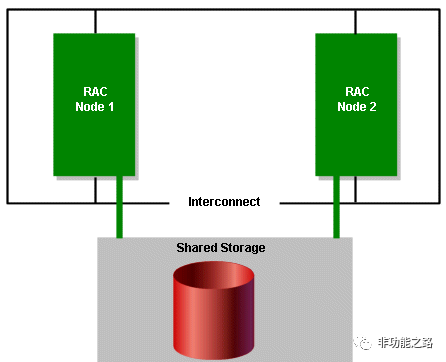
图1: OracleRAC架构
Greenplum是一种基于postgresql(开源数据库)的分布式数据库。其采用sharednothing架构(MPP),主机,操作系统,内存,存储都是自我控制的,不存在共享。主要由masterhost,segmenthost,interconnect三大部分组成。
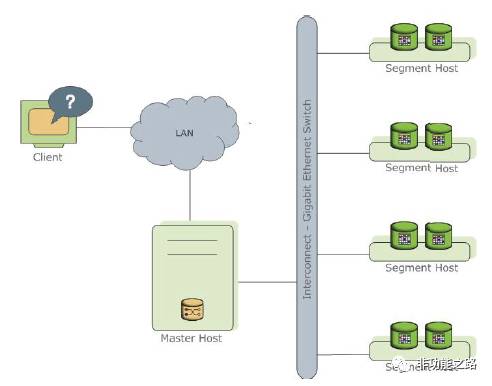
图2:Greenplum架构图
master节点作为主要的访问系统的入口,其保证着处理用户连接、监听数据库状态、建立查询计划,协调工作处理过程等工作。同时所有的系统目录表和元数据均存在在master节点上,master节点上不存放任何的用户数据。
每个segment节点存放一部分用户数据,可以通过增加segment节点实现Greenplum系统的线性扩展。但用户并不能直接访问segme
nt节点,所有的访问都需要通过master节点进行。
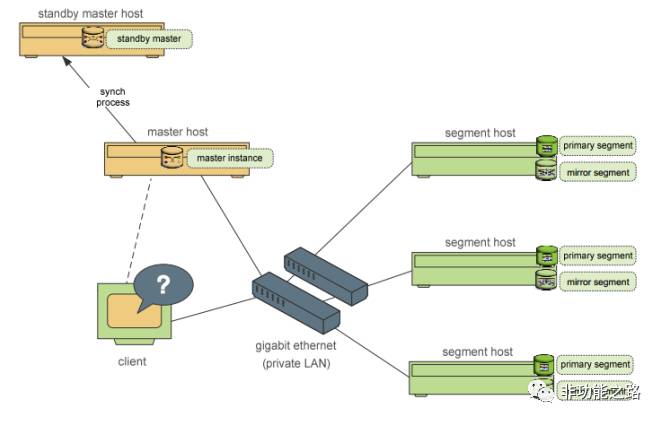
图3:Greenplum节点图
greenplum同样具备高可用特性保证数据库不会受到单点故障的影响。master节点可以通过在备机上建立standby节点维持提供服务的能力,segment节点的数据也同样可以选择使用primary和mirror实例进行备份,通常mirror和primary实例会选择放在不同的服务器节点上。
二、工作原理
2.1进程控制
在主节点上存在querydispatcher(QD)进程,该进程前期负责查询计划的创建和调度,segmentinstance返回结果后,该进程再进行聚合与向用户展示;segmenthost存在queryexecutor(QE)进程,该进程负责其它节点相互通信与执行QD调度的执行计划。
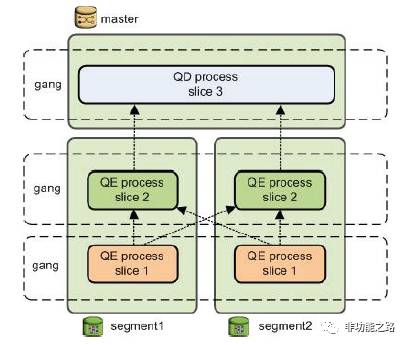
图4:进程控制图
2.2数据存储
Greenplum数据库通过将数据分布到多个节点上来实现规模数据的存储。数据库的瓶颈经常发生在I/O方面,Greenplum采用对数据进行分片的方式,将数据规律的分布到节点上,充分利用segment主机的IO能力,以此让系统达到最大的IO能力。
在Greenplum中每个表都是分布在所有节点上的。GP提供了两种常用的数据分布方式,即hash方式和random方式。在创建数据表时GreenPlum会要求用户提供分布键,之后Masterhost通过对该分布键进行hash或随机运算,根据结果将表的数据分布到segmenthost中。整个过程中masterhost不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。

图5:Greenplum数据存储图
2.3并行处理
2.3.1联机查询
Greenplum的查询优化器负责将SQL解析成每个节点(segments)所要走的物理执行计划。也是基于成本的优化策略:评估若干个执行计划,找出最有效率的一个。主节点master负责SQL解析和执行计划的生成。
不像传统的查询优化器,Greenplum的查询优化器必须全局的考虑整个集群,在每个候选的执行计划中考虑到节点间移动数据的开销。一旦执行计划确定,比如有join,那么join是在各个节点分别进行的(本机只和本机的数据join)。所以它的查询很快。
查询计划包括了一些传统的操作,比如:扫描、Join、排序、聚合等等。greenplum中有三种数据的移动操作:
A: BroadcastMotion(N:N),即广播数据,每个节点向其他节点广播需要发送的数据。
B: RedistributeMotion(N:N),重新分布数据,利用join的列值hash不同,将筛选后的数据在其他segment重新分布。
C: GatherMotion(N:1),聚合汇总数据,每个节点将join后的数据发到一个单节点上,通常是发到主节点master。
只利用了全广播的示例:
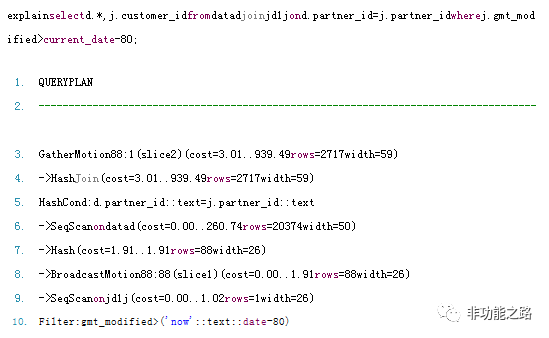
执行计划执行从下至上:
A、在各个节点扫描自己的jd1表数据,按照条件过滤生成数据rs
B、各节点将自己生成的rs依次发送到其他节点。(BroadcastMotion(N:N),即广播数据)
C、每个节点上的data表的数据,和各自节点上收到的rs进行join。这样就保证本机上的 数据只和本机的数据join
D、各节点将join后的结果发给master(GatherMotion(N:1))
表1:执行计划
由上面的执行过程可以看出,Greenplum是将rs给每个含有data表数据的节点都发了一份的。要是rs很大的话,广播数据网络就会成为瓶颈。可以看出greenplum很聪明:它是将小表广播到各个segment上。可以看出统计信息对于生成好的查询计划是何等重要。
带有节点数据重分布的查询示例:

执行计划:
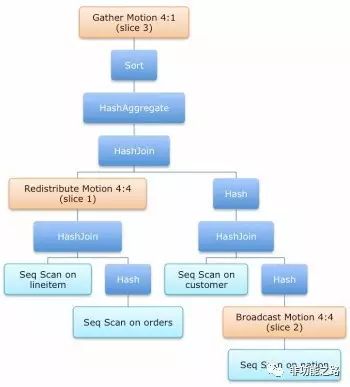
图6:执行计划图
A、各个节点上同时扫描各自的nation表数据,将各segment上的nation数据向其他节点广播(BroadcastMotion(N:N))
B、各个节点上同时扫描各自customer数据,和收到的nation数据join生成RS-CN
C、各个segment同时扫描自己orders表数据,过滤数据生成RS-O
D、各个segment同时扫描自己lineitem表数据,过滤生成RS-L
E、各个segment同时将各自RS-O和RS-L进行join生成RS-OL,注意此过程不需要 RedistributeMotion(N:N),重新分布数据,因为orders和lineitem的distributecolumn 都是orderkey。这就保证了各自需要join的对象都是在各自的机器上,所以n个节点就开 始并行join了
F、各个节点将自己在步骤E生成的RS-OL按照cust-key在所有节点间重新分布数据 (RedistributeMotion(N:N),可以按照hash和range在节点间来重新分布数据,默认是 hash),这样每个节点都会有自己的RS-OL
G、各个节点将自己在步骤B生成的RS-CN和自己节点上的RS-OL数据进行join,又是本机 只和本机的数据进行join
H、聚合,排序,发往主节点master
表2:执行计划
存在一种特殊情况,即列值出现倾斜的时候,数据表没有按照主键来hash分布,而是人为指定按照其他列的hash在各个节点上分布数据,若表中中80%的数据出现集中,此时就会有单个节点上拥有了大量的的数据,此时,如果进行连接操作,算是小表广播到其他节点了也无济于事,因为计算的压力都集中在一台机器了。因此选择合适的列进行hash分布,对于GP的性能表现,是非常关键的。
2.3.2数据导入导出

图7:Gpfdist架构
Gpfdist程序能够以370MB/s装载text格式的文件和200MB/s装载CSV格式文件,ETL带宽为1GB的情况下,我们可以运行3个gpfdist程序装载text文件,或者运行5个gpfdist程序装载CSV格式文件。例如图例中采用了2个gpfdist程序进行数据装载。可以根据实际的环境通过配置postgresql.conf参数文件来优化装载性能。
Gpfdist利用greenplum的外部表与外部服务器进行交换,在保证网络访问关系的前提下,在gpfdist服务器上建立外部表,ETL服务器生成了数据之后即可将数据按格式导入到多个gpfdist外部表数据源服务器上,此时即可利用gpfdist命令将数据并行导入到greenplum中。
利用外部表进行数据导入导出的示例:
1. 创建文件服务器
如果数据在一个segment服务器上,则可以用file://协议或者greenplum文件服务器gpfdist://协议,若数据需要从多个segment上来,则必须用greenplum文件服务器的方式:从$GPHOME/bin下面copy文件gpfdist到文件服务器上,然后启动:
gpfdist -d var/load_files -p 8081 -l /home/gpadmin/log &
2. 创建外部表:
例如:
CREATE EXTERNAL TABLE ext_expenses
( name text,date date, amount float4, category text, desc text )
LOCATION (‘gpfdist://etlhost:8081/*’,‘gpfdist://etlhost1:8081/*’)
FORMAT ‘TEXT’ (DELIMITER ‘,’);
3. 装载数据:
数据装载可使用insert或create table XXX as select * from 外部表的方式创建,例如:
insert方式
INSERT INTO expenses_travel
SELECT * from ext_expenses where category=’travel’;
create table…as … 方式
CREATE TABLE expenses AS SELECT * from ext_expenses;
4. COPY命令的方式装载
Copy命令装载数据并不是并行装载,而且所装载的数据文件必须放在master服务器上,例 如:
COPY country FROM ‘/data/gpdb/country_data’
WITH DELIMITER ‘|’ LOG ERRORS INTO err_country
SEGMENT REJECT LIMIT 10 ROWS;
结语
本文就Greenplum的基本框架、进程控制、数据存储及并行处理机制等方面进行了介绍,并对特定的查询进行了查询计划分析和详解,后续将对Greenplum的基本数据管理、操作命令等进行进一步的介绍,欢迎给出宝贵意见,谢谢!
