




《碟中谍6:全面瓦解》明天终于在大陆上映了~作为阿汤哥的脑残(颜)粉,先舔为敬。

碟中谍从 1 到 6,从 1996 到 2018, 从未跌下过神坛,这次更是口碑炸裂,烂番茄新鲜度98%,IMDB 8.2 分。小编最喜欢的知名影评人毒 sir 也在八月影片盘货中给出最高五分期待值。说这么多,电影是不是真的好看伐,我们今天用 Oracle Big Data Cloud 简单分析了 IMDB 上 813 条有效影评(北美 7.27 日已上映)。同时也和大家一起认识大数据分析应用中的“Hello Word”--“Wordcount”君。
惯例,先上主要步骤:
第一步,打开集群界面,设置远程访问的基本信息
第二步,利用 Putty 访问集群中的节点
第三步,运行我们的第一个应用(Python)
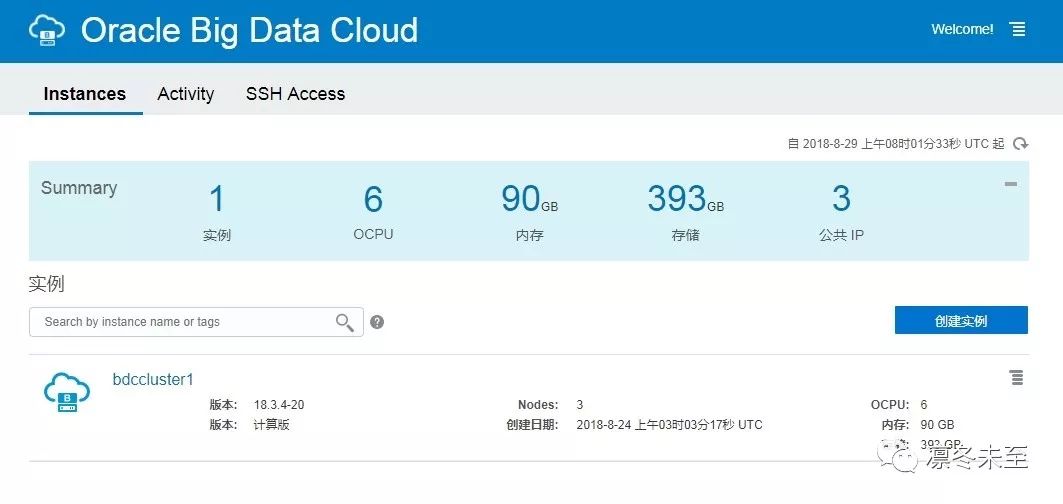
1. 我们在上一篇文章中 Oracle Big Data Cloud 中安装了一个大数据分析的集群,如图:
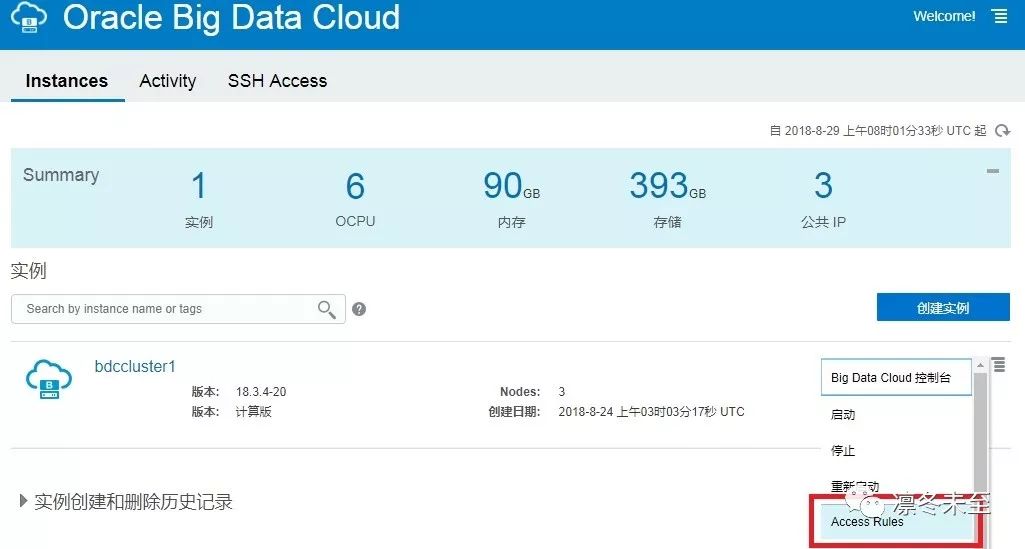
2. 设置访问规则。如图,选择 Access Rules。
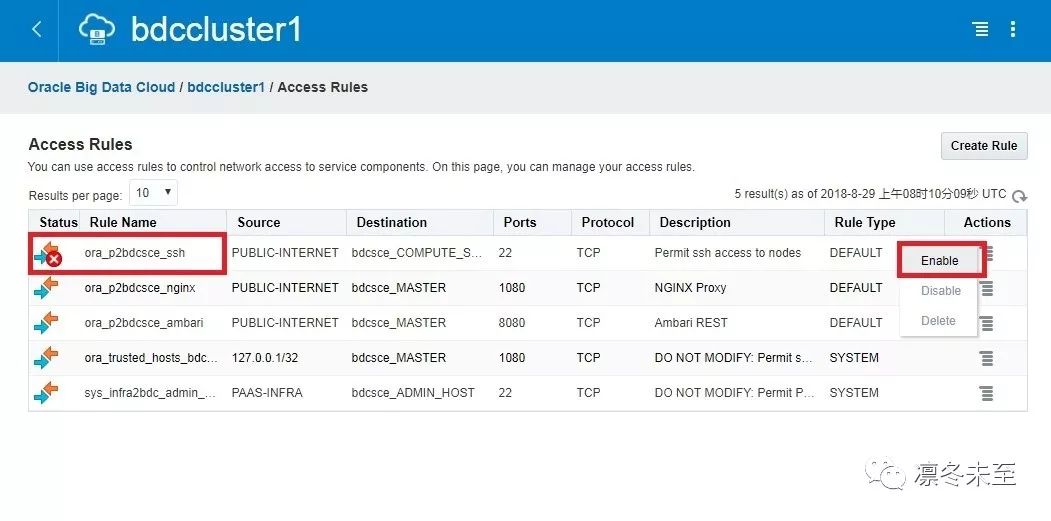
在 Access Rules 界面, 开启 ssh 访问权限,需要等待 30s 到 60s。
3. 获取集群中节点的 IP ,在这个示例中我们选择了第一个节点。

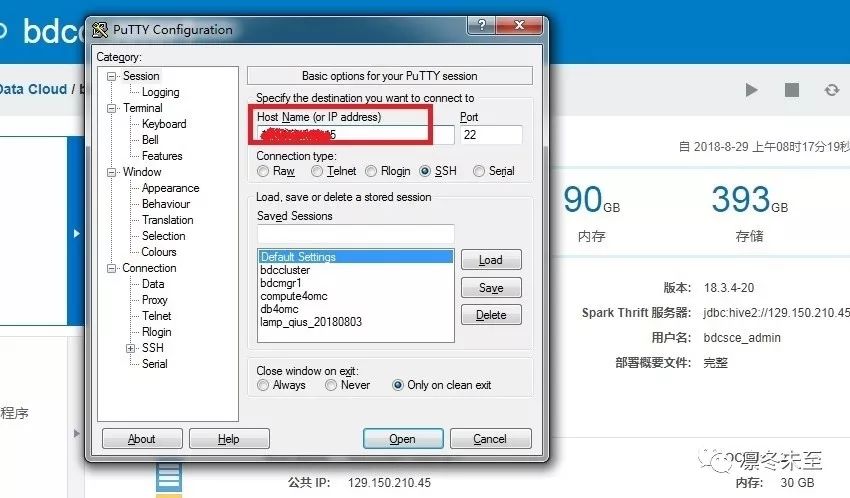
1. 在 Putty 中输入在步骤一中节点的的 IP ,确认连接方式是 SSH,端口为 22,如图:
2. 选择 Connection 中的 Data,在 Auto-login username 中输入 opc , 同时确认 When username is not specified 的选项为 Prompt, 如图:

3. 展开 Connection 中的 SSH, 选择 Auth, 上传私钥文件,请确认和在创建集群时使用的公钥是匹配的。如图,
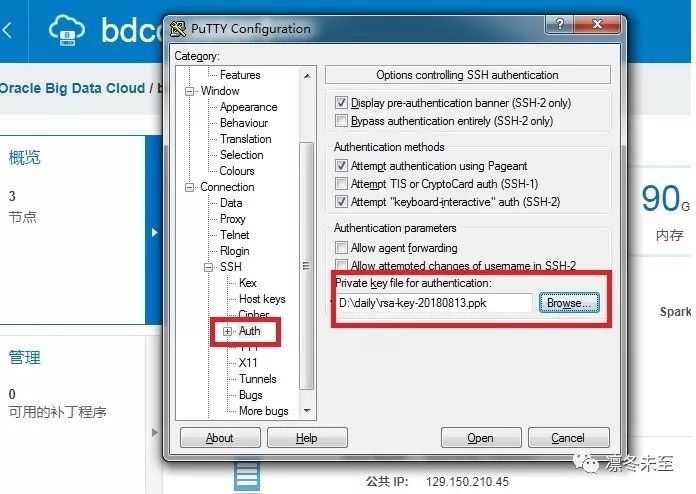
4. 点击 Open, 连接目标节点。
1. 安装后 Spark 的目录默认为 /u01/bdcsce/usr/hdp/2.4.2.0-258/spark。进入该目录,小编用 Python 脚本,所以这次运行 pyspark,如图: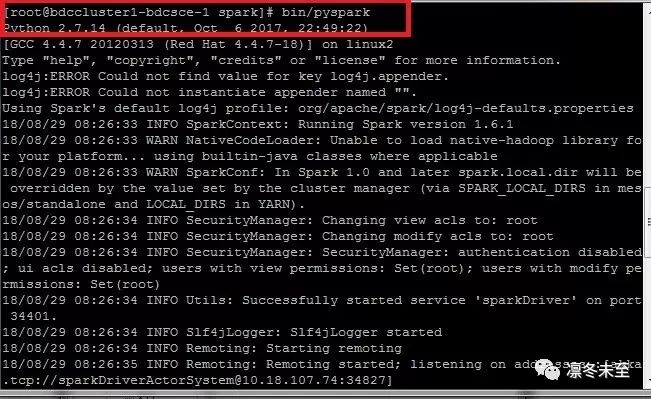 2.初始化成功后,开始运行我们的程序。我们把 IMDB 上的影评保存在了 wordcount.txt 中,首先读入这些评论,
2.初始化成功后,开始运行我们的程序。我们把 IMDB 上的影评保存在了 wordcount.txt 中,首先读入这些评论,
sc.textFile("file:/u01/bdcsce/usr/hdp/2.4.2.0.258/spark/wordcount.txt")
然后对这个 RDD 进行 MapReduce 操作,计算出词频。
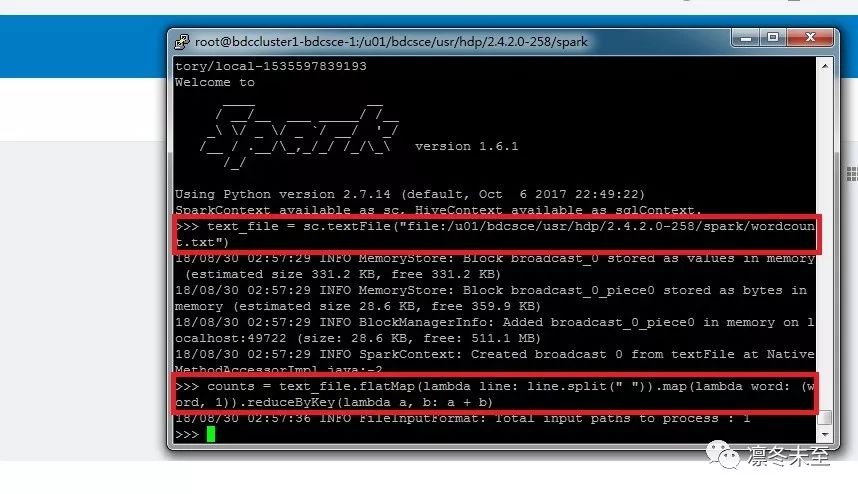
3. 对这个 RDD 进行 action 操作, 按每个词出现的频率由高到低排序,这里我们选取了top 500 的词,counts.takeOrdered(500,key=lambda x:-x[1])。
经过 Spark 内部的运算后,如图:
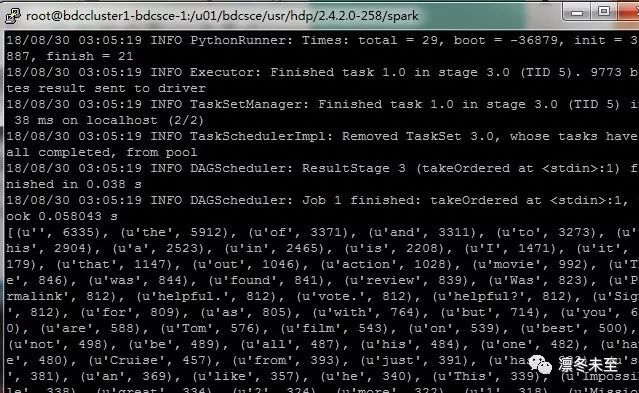
所以,《碟中谍6:全面瓦解》值得看吗?
小编整理了 Top500 中的有效词汇,主要保留了形容词和关键名词,其中'helpful' 812 次,‘best’610 次,‘great’334 次,‘good’307 次,‘stunt’272 次,'bad' 只有69 次哦。看词频结果还是很值得一看的电影,明天走起吧 (*^▽^*)

