




通常情况下,企业中会采取轮询或者随机的方式,通过Kafka的producer向Kafka集群生产数据,来尽可能保证Kafk分区之间的数据是均匀分布的。
如果对Kafka不了解的话,可以先看这篇博客《一文快速了解Kafka》。
消息积压的解决方法
加强监控报警以及完善重新拉起任务机制,这里就不赘述了。
1.实时/消费任务挂掉导致的消费积压的解决方法
在积压数据不多和影响较小的情况下,重新启动消费任务,排查宕机原因。
如果消费任务宕机时间过长导致积压数据量很大,除了重新启动消费任务、排查问题原因,还需要解决消息积压问题。
解决消息积压可以采用下面方法。
任务重新启动后直接消费最新的消息,对于"滞后"的历史数据采用离线程序进行"补漏"。
如下面图所示。创建新的topic并配置更多数量的分区,将积压消息的topic消费者逻辑改为直接把消息打入新的topic,将消费逻辑写在新的topic的消费者中。
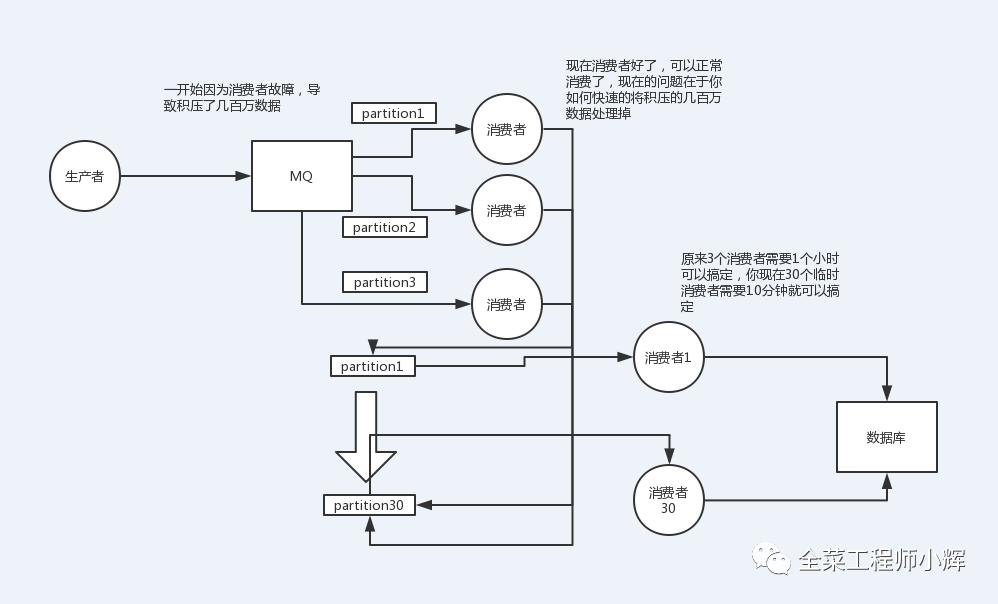
如果还需要保证消息消费的局部有序,可以将消费者线程池改成多个队列,每个队列用单线程处理,更多内容可以查看博客《一文理解Kafka如何保证消息顺序性》
2.Kafka分区数设置的不合理或消费者"消费能力"不足的优化
Kafka分区数是Kafka并行度调优的最小单元,如果Kafka分区数设置的太少,会影响Kafka Consumer消费的吞吐量。
如果数据量很大,Kafka消费能力不足,则可以考虑增加Topic的Partition的个数,同时提升消费者组的消费者数量。
3.Kafka消息key设置的优化
使用Kafka Producer消息时,可以为消息指定key,但是要求key要均匀,否则会出现Kafka分区间数据不均衡。
所以根据业务,合理修改Producer处的key设置规则,解决数据倾斜问题。
文章转载自全菜工程师小辉,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
611次阅读
2025-04-14 09:40:20
Hologres x 函数计算 x Qwen3,对接MCP构建企业级数据分析 Agent
阿里云大数据AI技术
594次阅读
2025-05-06 17:24:44
一页概览:Oracle GoldenGate
甲骨文云技术
483次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
474次阅读
2025-04-30 12:17:50
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
363次阅读
2025-04-18 10:01:22
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
阿里云大数据AI技术
298次阅读
2025-04-27 15:28:51
XCOPS广州站:从开源自研之争到AI驱动的下一代数据库架构探索
韩锋频道
292次阅读
2025-04-29 10:35:54
Coco AI 入驻 GitCode:打破数据孤岛,解锁智能协作新可能
极限实验室
249次阅读
2025-05-04 23:53:06
优炫数据库成功应用于晋江市发展和改革局!
优炫软件
199次阅读
2025-04-25 10:10:31
优炫数据库四个案例入选《2024网信自主创新调研报告》
优炫软件
190次阅读
2025-04-22 10:12:23
