





先给大家来一个表情图来决定要看的源码. 这里就话不多话了,来到我们不得不看的 HashMap 源码环节了.
我们抽取 HashMap 中我们经常使用到的 put get 等方法进行阅读分析.
HashMap 结构
// Node 节点的数组transient Node<K,V>[] table;// 长度transient int size;//哈希因子static final float DEFAULT_LOAD_FACTOR = 0.75f;
这里说明主要是存储数据主要是 table.
java.util.HashMap.TreeNode ,这个内部类,大家有兴趣可以自己了解,因为这个就是我们大家所说的 红黑树. 这里我主要是讲述 put get 方法,以及put 方法的扩容方法.
putVal 方法
这里就直接上 putVal 的代码,由于是上代码看到不是很方便,所以我这里直接贴图出代码了. 如果没看过的人,可能看着这源码,就是一顿头晕。

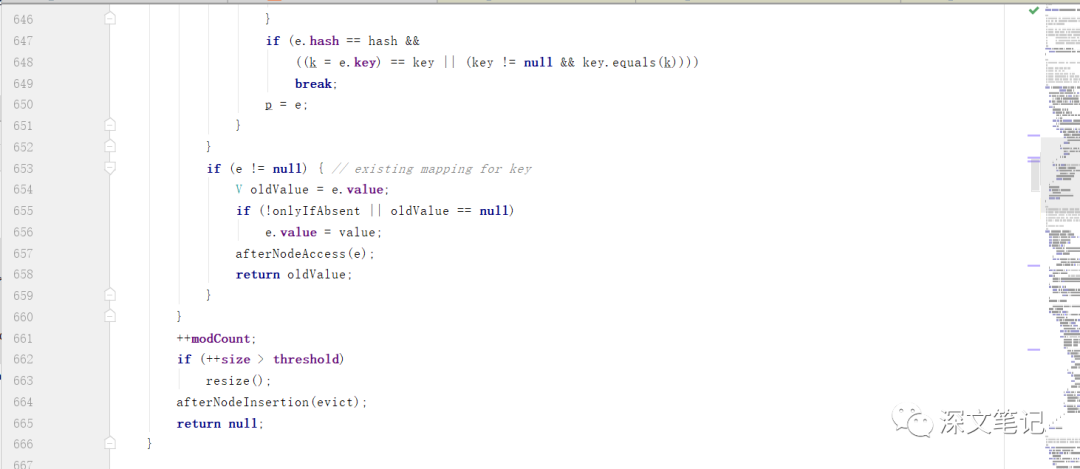
最初如果 table 的长度是 0 的话,就会调用resize扩容的方法.
通过 (n-1)& hash 计算出下标 i , tab [i] 是 null 的话,那么说明没有发生哈希冲突,直接new一个新的节点赋值给 tab[i] 即可.
如果 tab[i] 下标是有值的话,那么就说明是发生了哈希冲突。
冲突处理方案一 : 先是确认 hash 值是不是一样的 & key 以及 key 的值是不是相同的话,如果是相同的话,那就说明你是 put 了相同的数据进来. 这里是对put相同的数据进行处理.
冲突处理方案二 : 如果是红黑树,那么就调用 putTreeVal 给添加到红黑树中来.
冲突处理方案三 : 放入冲突节点的下一个节点(p.next=newNode)可以看出,如果节点的长度是大于等于7的话,那么就会调用 treeifBin 转化为红黑树. 可以很细腻的看到, 一个节点下,可能存在7个以下的值,如果是在第6个冲突了并且其值与原来值是一样的呢?所以在 for(int binCount....) 中可以看到,每次迭代的时候,都会有 一个 hash 值是否相同并且其key值也相同的情况判断。
最后如果 ++szie 是大于 threshold 的话,就会调用 resize 扩容的方法.
扩容方法
看完put 方法,可以看到最后是说提到了扩容的方法,那么 HashMap 是怎么扩容的呢?每次扩容,又是扩容多大呢?
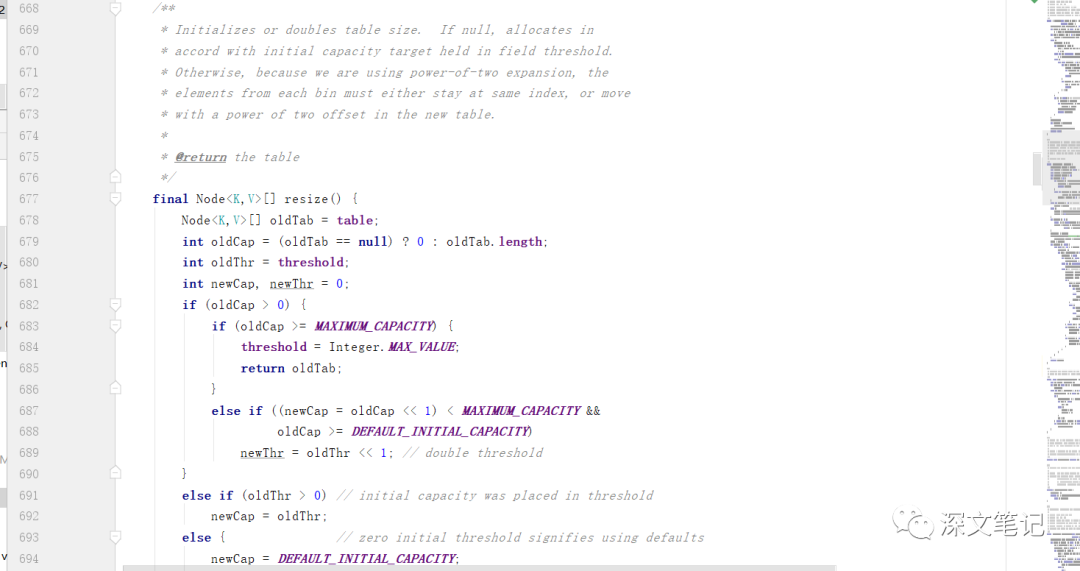
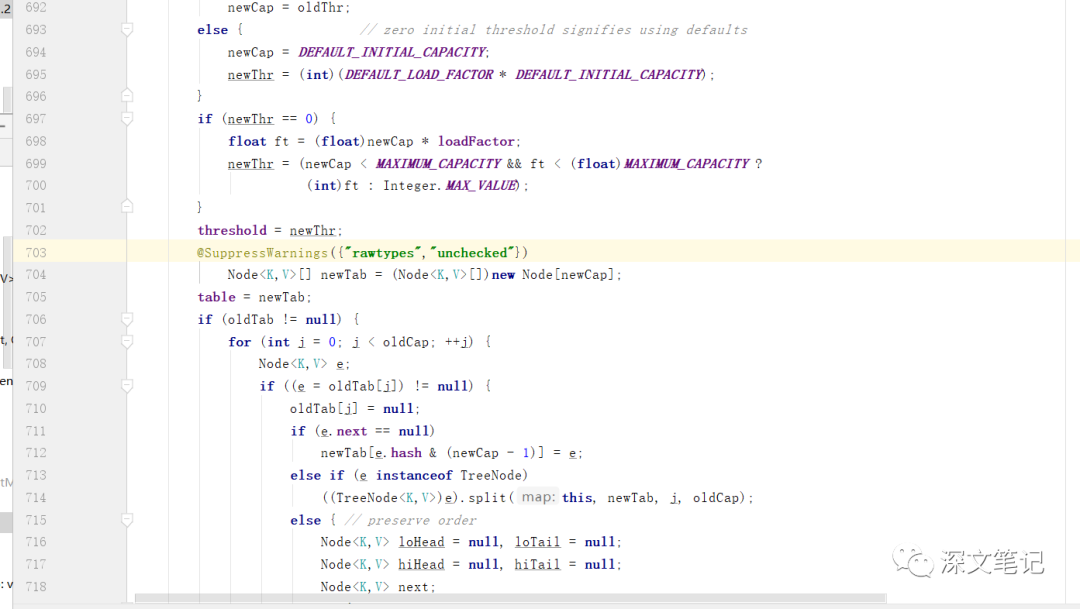


可以看到扩容的方法,相对于其上面的 put 方法的话,其代码还是相对比较多一点的.
于是我们就这个扩容的方法,进行阅读和分析下.
table使用 oldTab来进行存储,拿出oldTab的长度(如果oldTab是null的话,对应的长度就是为0).
oldThr 是 记录 threshold 之前的值, newCap newThr就是需要扩容使用到的变量命名.
这里分为:
1: oldCap 是大于0的。 如果比 MAXIMUM_CAPACITY 还是要大的话,就说明里面存储的元素是太多了,就直接返回oldTab. 还有一种就是 newCap等于oldCap的1.5倍并且小于MAXIMUM_CAPACITY和oldCap是大于默认16的,就会进行1.5倍的扩容
2: oldThr 大于 0, newCap(扩容新长度) 就是等于 oldThe的值.
3 :
否则就是都使用默认的值大小
这是上面的对扩容大小的数值进行确定.
那么真正的移动值,是在
for (int j = 0; j < oldCap; ++j)复制
这个循环里面来进行复制值的操作.
使用扩容后的newCap来创建一个数组,oldTab不是null,然后就需要将老的值赋值到新的newTab里面来.
使用下标来进行迭代,获取每个下标的Node节点的值,然oldTab[j]赋值给e后,然后将oldTab[j]重置为null.
这里面的进行Node复制是有分为下面几种, Node的next节点是没有值得,next下面是由值,e节点转化为了红黑树.
1 : 如果e.next是null,也就是没有值,newTab[e.hash & (newCap - 1)] = e来赋值.
2:如果e是TreeNode的话,就会调用((TreeNode<K,V>)e).split(this, newTab, j, oldCap)方法.
3 : 然后可以看到 do while 循环里面, while 里面的条件是 e.next != null 才会进去,也就是next是由值得情况下才会进入到这里面来.然后可以看到一些系取节点啊,赋值给变量啊,然后赋值给新创建的Node数组下标然后将之前的node节点重置为null。 这里就需要读者对这些代码来慢慢消化了.仔细想看,就是对node节点的取值,赋值,重置等操作.
所以这里,可以看到 HashMap 的扩容方法的大致逻辑.
先是确定扩容后的新的 node 数组的长度,打个比如 这里如果我是10,那么按照1.5倍的话,那么我新的node数组长度就是15.
new一个新的node数组,然后 table = 新node数组, 于是这个时候需要做什么事情呢?是不是需要将之前旧的 node 数组里面的值给复制过来? 所以这里有了 for 来将值都给 一一转移过来. 这里说下我个人观点: HashMap 并没有根据下标 j 来将值给一一对应复制到新的node数组中来,于是我大胆猜测了下,在扩容的时候,是有对下标进行从新计算的.
于是将值都复制完了,那扩容就算是完成了.
扩容方法看完了,整个 put 方法,也就是大致走完了。
get 方法
这里也直接上 get 方法的代码,有了代码就不容易迷路.
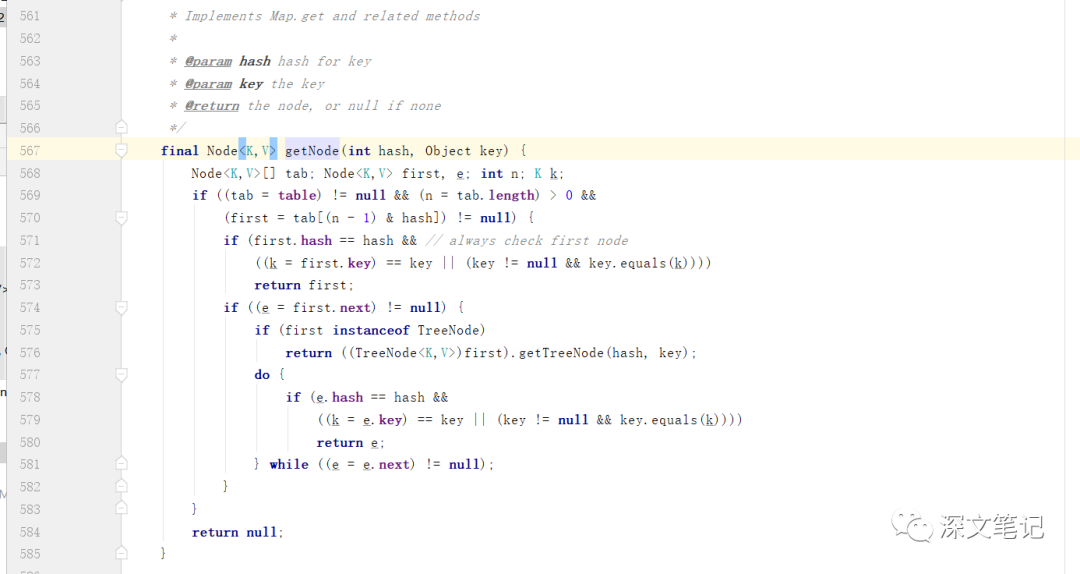
get 方法,最后还是走到了 getNode 方法来. 走到 getNode 方法之前,还是有计算key的hash值来.
如果 table不是Null,并且长度是大于0的,能够根据 (n-1) & hash 得出来的下标是在tab里面能获取到值得,才会进入逻辑代码,否则就是返回null.
如果first的hash是于传入进来的hash相同,斌且给key的值也是相同的话,就会返回first节点.
拿node的next节点,如果是TreeNode的类,就会走TreeNode对应的getTreeNode方法(链表的长度大于8就会转化为红黑树). 否则的话就就迭代这个Node,退出的条件就是 e.next == null,就说说明下面没有对应的节点了。
这里拿值得逻辑,还是比较容易理解得。 先根据计算出来得hash值,去数组中是否可以获取到对应得值,如果有就先会对first进行判断,是否满足条件.如果不满足的话,就说明这个key的hash是由冲突的,也就是由二个不同的值,计算出来相同的hash值,这个时候就会用链表(Node)来进行存储,如果长度是大于8的话,就会转化为TreeNode的红黑树.
注意 : 如果没有根据key获取到值的话,返回的就是null. 避免 NPE.
getOrDefault() 方法,如果是获取出是null 的话,传入的第二个参数是可以当为默认值的.
好啦,今天就更新到了 put get 方法.
然后大家可以扩展阅读 remove / clear / contains 等方法.
最后,谢谢大家关注。这里是 深文笔记.
技术交流加 vx : l18776416225
放下我 永哥 的公众号,大家有兴趣&有时间去关注,永哥会告诉你什么叫健身&Coding硬实力.

