




Elasticsearch 是一个基于 Lucene 库分布式、可扩展的搜索引擎,提供近实时的搜索和分析功能。
数据结构
查询花费的时间与底层的数据结构是紧密相关的。链表的查找时间复杂度一般是 O(n),树型的查找时间复杂度一般是 O(logn),哈希表的查找时间复杂度一般是 O(1),不同数据结构所花的时间往往不一样,想要查找的时候要快,就需要底层的数据结构的支持。
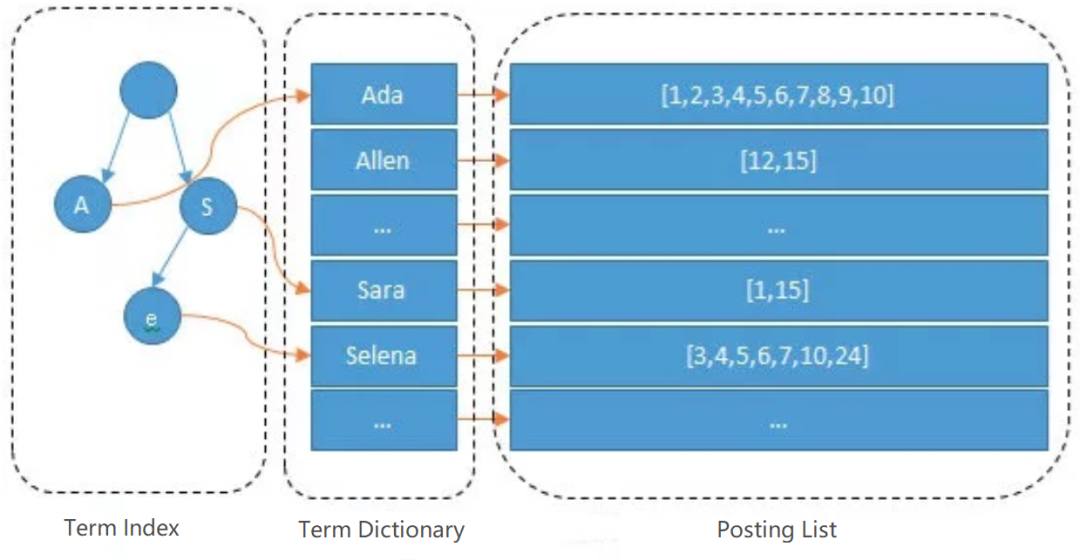
根据精准条件查找记录叫做正向索引,像关系型数据库往往采用 B+ 数实现正向索引。Elasticsearch 所采用的数据结构叫做倒排索引,也常被称为反向索引、置入档案或反向档案。它是一种索引方法,被用来存储在全文检索下某个分词在一个文档或者一组文档中存储位置的映射。
倒排索引涉及一个新的概念——分词。顾名思义,分词就是将文本分割为一个个词项,这些分词汇总起来我们叫做 Term Dictionary,我们需要通过分词找到对应的记录,这些文档 ID 保存在 Posting List 中( Posting List 还保存着词频和偏移量,形如:(文档ID;频率;<偏移量>)),为了避免查找记录时遍历整个 Term Dictionary,分词存储时会进行排序以便二分查询。但 Term Dictionary 词项数量往往十分庞大,不可能都存放到内存中,于是 Elasticsearch 还设计了一层 Term Index,采用 FST 存储的,它的作用类似于字典树,可以快速定位词项位置,但不同的是和字典树相比它不仅可以复用单词前缀,而且可以复用单词后缀。
分词
Analysis 是指把文本转换成一系列单词(term/token)的过程,也叫分词。Elasticsearch 通过 Analyzer(分词器)实现 Analysis。
Analyzer 由下面三个部分组成:
Character filters:处理原始文本,剥离 html 标记。
Tokenizer:根据 Analyzer 分词规则将文本切分为文本标记,包括每个词的顺序或位置、词所代表的原始词的开始和结束字符偏移量。
Token Filters:对切分后的文本标记进行加工,如:小写转换,删除终止词,引入同义词等。
在将文档添加到索引之前,每个需要分析的字段会被 Character filters、Tokenizer、Token Filters 依次处理,最终将文本标记存入索引。
下图展示了 "share your experience with NoSql & big data technologies" 分析的标记:share、your、experience、with、nosql、big、data、tools 及 technologies 词项的过程。
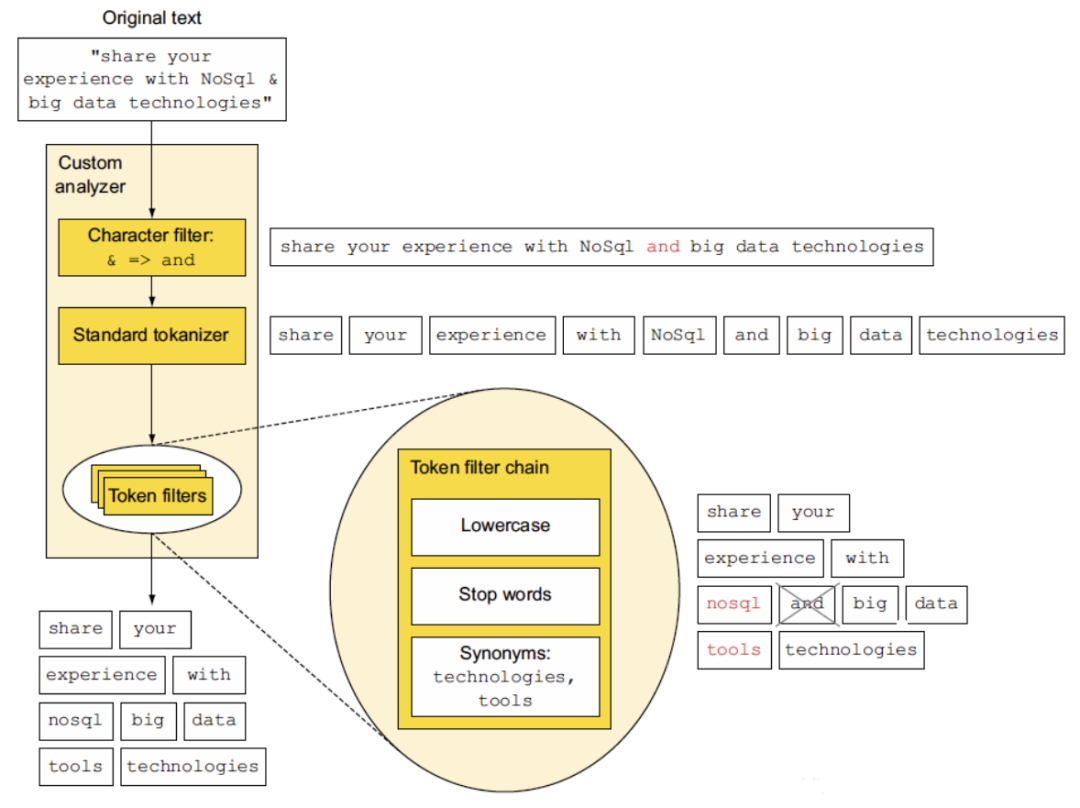
注意:Analysis 一般执行在两种场合:
在 indexing 的时候,即建立索引的时候。
在 searching 的时候,即全文检索时,分析需要搜索的词项。
更多内容,建议阅读 Elasticsearch 官方文档 。
文章同步 github。
地址:github.com/lazecoding/Note/blob/main/note/articles/es/数据结构和分词.md
