今天一个同事问起关于RAC的job会不会 每个节点的系统时间不一致导致job重复执行的问题。
就此事我也查一下相关知识,随笔记录一下。
对于集群数据库,一个JOB可以运行在db级与instance级
如果把job定义在db级,job可以运行在任何活动的instance上,并遵循job的调度机制,JOB的调度通过JOB协调进程来完成的,通过JQ队列锁来避免竞争和重复执行,每个JOB分配一个唯一的JQ锁;
如果把job定义在instance级别上,job将运行在指定的实例上,如因某种异常导致创建job的实例当机,那job将运行在存活的实例上。
参考Oracle文档:
you can create a job at the cluster database level and the job will run on any active instance of the target Oracle RAC database. Or you can create a job at the instance level and the job will only run on the specific instance for which you created it. In the event of a failure, recurring jobs can run on a surviving instance.
Each RAC instance has its own job coordinator. The database monitoring checks that determine whether or not to start the job coordinator do take the service affinity of jobs into account. For example, if there is only one job scheduled in the near future and the job class to which this job belongs has service affinity for only two out of the four RAC instances, only the job coordinators for those two instances will be started
DECLARE
X NUMBER;
BEGIN
SYS.DBMS_JOB.SUBMIT(job=> X,
what => ‘declare
v_a nvarchar2(10);
begin
select ‘’ a’’ into v_a from dual;
end;’,
next_date => to_date(‘08/19/2011 11:26:43’,
‘mm/dd/yyyy hh24:mi:ss’),
interval => 'SYSDATE+30/1440 ',
no_parse => FALSE,
Instance_id => 1,
force => TRUE);
:JobNumber := to_char(X);
END;
不指定instance参数 ,默认创建在’0’ 实例上,代表可以在任何节点上运行。
查看job运行在哪个实例上:
select job, instance, what from dba_jobs;
改变运行的实例:
exec dbms_job.instance(41,1);–41为job id, 1 为指定的要运行在哪个实例id上。
同事说它的RAC有4个节点,节点之间时间相差了一分钟多,而job的执行间隔为10s,导致job会重复运行,说把时间调一致了就不会重复执行了。
我就奇怪了,间隔那么短,执行那么频繁,数据库节点间怎么区分是执行了这次的还是下次的。
去官方文档查一下job是怎么执行的
Administrator’s Guide 中的shedule concept一章。
How Jobs Execute
When a job is picked for processing, the job slave:
1.Gathers all the metadata needed to run the job. As an example, arguments of the program and privilege information.
2.Starts a database session as the owner of the job, starts a transaction, and then starts executing the job.
3.Once the job is complete, the slave commits and ends the transaction.
4.Closes the session.
Job Slaves
Job slaves actually execute the jobs you submit. They are awakened by the job coordinator when it is time for a job to be executed. They gather metadata to run the job from the job table.
When a job is done, the slaves:
1.Reschedule the job if required
2.Update the state in the job table to reflect whether the job has completed or is scheduled to run again
3.Insert an entry into the job log table
4.Update the run count, and if necessary, failure count and retry count
5.Clean up
6.Look for new work (if none, they go to sleep)
The Scheduler dynamically sizes the slave pool as required.
Using the Scheduler in Real Application Clusters Environments
In a Real Application Clusters (RAC) environment, the Scheduler uses one job table for each database and one job coordinator for each instance. The job coordinators communicate with each other to keep information current. The Scheduler attempts to balance the load of the jobs of a job class across all available instances when the job class has no service affinity, or across the instances assigned to a particular service when the job class does have service affinity.
Figure 26-4 illustrates a typical RAC architecture, with each instance’s job coordinator exchanging information with the others.
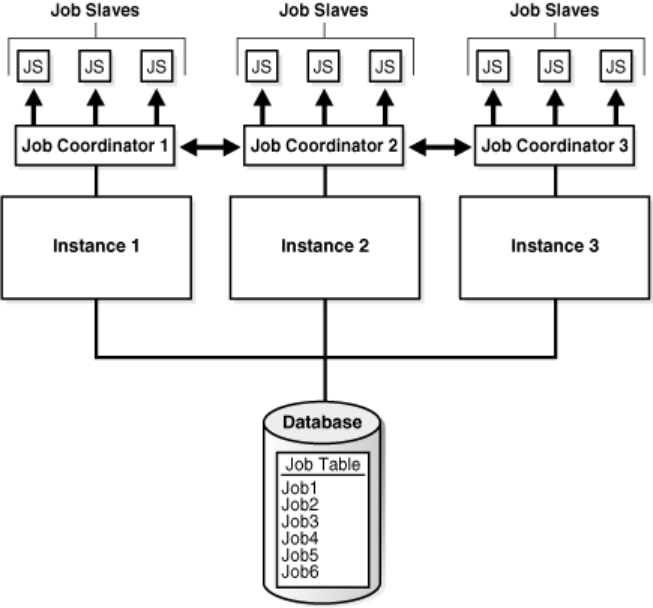
从官方文档说明来看,Job执行完毕 job slave会重新shedule下次执行的时间,由于job执行的间隔时间短,那么由于节点间时间差,而且这个时间差大于job的执行间隔,势必会造成某个节点先到达指定时间,后台进程job cordinator启动,去唤醒job slave去执行,完毕后定下下次执行时间,等另一个节点又到达下次的这个时间,又会触发job cordinator去工作。 确实会出现重复执行的情况。只能这样理解,你既然设置job间隔为10s,那就是代表节点间重复执行没有问题。
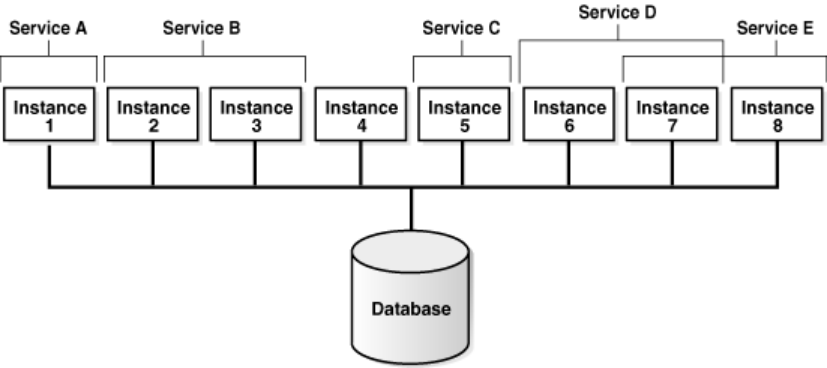
另外特别指出 对集群中job指定service 比指定instance 有更好的可用性。因为service可覆盖多个instance,并且可以指定优先连接的实例。
Srvctl 命令创建服务的语法:
11g:
srvctl add service -d
-d
-s
-r"<pref_list>" List ofpreferred instances (优先连接的实例)
-a"<avail_list>" List ofavailable instances (优选实例宕机后,连接其他可用实例)
12c中有些改变
srvctl add service -database db_unique_name -service service_name
-preferred preferred_list -available available_list]
为job指定service可以通过DBMS_SCHEDULER.CREATE_JOB_CLASS创建job_class, service参数指定service affinity,然后create_job存储过程创建job时指定参数job_class为前面创建的job class name。
官方文档是这样说的
Service Affinity when Using the Scheduler
The Scheduler enables you to specify the database service under which a job should be run (service affinity). This ensures better availability than instance affinity because it guarantees that other nodes can be dynamically assigned to the service if an instance goes down. Instance affinity does not have this capability, so, when an instance goes down, none of the jobs with an affinity to that instance can run until the instance comes back up. Figure 28-8 illustrates a typical example of how services and instances could be used.