




微信搜索“coder-home”或扫一扫下面的二维码,关注公众号,
第一时间了解更多干货分享,还有各类视频教程资源。扫描它,带走我

前言
创建MySQL主从复制集群
准备MySQL数据库环境
配置主从链路
启动主从复制
安装MHA
下载MHA
安装MHA
配置ssh免密登录
安装MAH软件包
配置MHA
验证MHA配置
启动MHA
MHA命令介绍
mah-manager命令
mha-node命令
mah-自定义脚本
主从切换的验证
监控manager节点的日志
停止master1节点
验证主从切换结果
恢复master1节点
再次启动MHA服务
VIP漂移的三种方式
通过MHA自定义master_ip_failover维护
通过keepalive来维护
安装keepalive
配置keepalive
启动keepalive
通过keepalive和master_ip_failover结合来使用
验证VIP漂移
验证VIP是否可用
验证VIP是否可以漂移
如何恢复失败节点
读服务怎么解决
思考
总结
前言
上一篇文章中,我们分享是MySQL高可用集群实现的方式之一:MMM高可用集群。这是一种比较老的高可用集群实现方式。今天我们来看另外一种MySQL高可用集群的实现方式,MHA(Master High Availability)。
最简单一个MHA网络拓扑如下所示,它不像MMM架构那样可以支持两个Master节点,它支持有一个master节点主从复制集群。
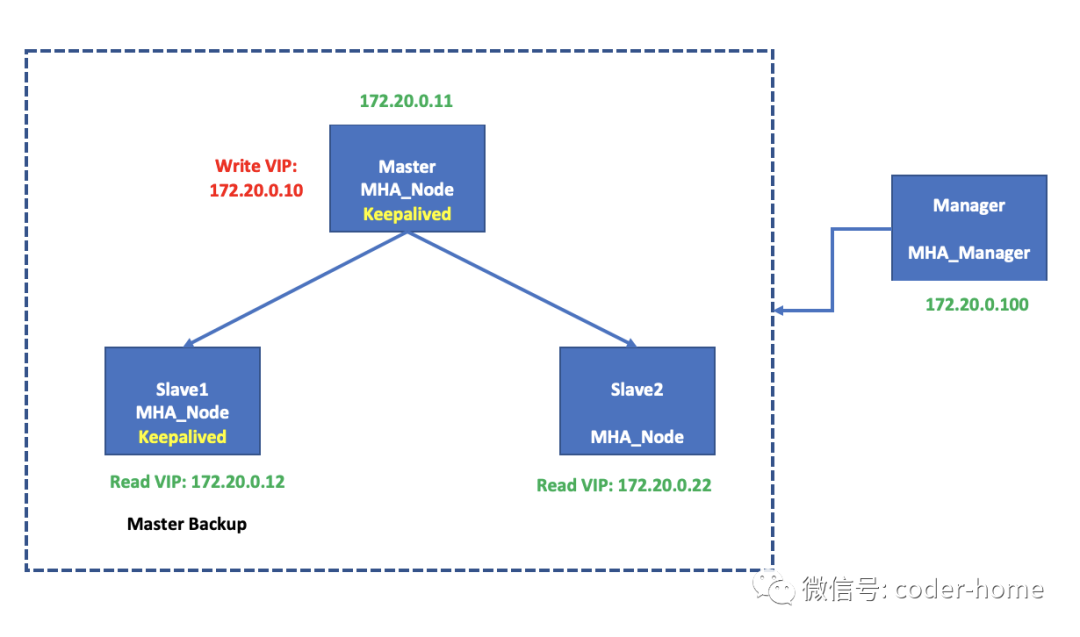
创建MySQL主从复制集群
准备MySQL数据库环境
使用如下命令,创建一个docker虚拟网段,这个网段仅用于当前MySQL安装MHA集群来使用。便于归类管理。
docker network create --subnet=172.21.0.0/24 mysql-ha-mha-network复制
启动三个MySQL数据库示例,分别是master1、slave1、slave2,用于搭建一主两从的MySQL集群。
# master1节点
docker run --net=mysql-ha-mha-network --hostname master1.mysql --ip 172.21.0.11 --cap-add NET_ADMIN --name mysql-ha-mha-master1 -d -v Users/coder-home/docker_mysql_ha/mha/master1:/etc/mysql/conf.d --privileged=true -v sys/fs/cgroup:/sys/fs/cgroup:ro -e MYSQL_ROOT_PASSWORD=root -e TZ="Asia/Shanghai" -p 33011:3306 mysql:5.7.31
# slave1节点
docker run --net=mysql-ha-mha-network --hostname slave1.mysql --ip 172.21.0.12 --cap-add NET_ADMIN --name mysql-ha-mha-slave1 -d -v Users/coder-home/docker_mysql_ha/mha/slave1:/etc/mysql/conf.d --privileged=true -v sys/fs/cgroup:/sys/fs/cgroup:ro -e MYSQL_ROOT_PASSWORD=root -e TZ="Asia/Shanghai" -p 33012:3306 mysql:5.7.31
# slave2节点
docker run --net=mysql-ha-mha-network --hostname slave2.mysql --ip 172.21.0.22 --cap-add NET_ADMIN --name mysql-ha-mha-slave2 -d -v Users/coder-home/docker_mysql_ha/mha/slave2:/etc/mysql/conf.d --privileged=true -v sys/fs/cgroup:/sys/fs/cgroup:ro -e MYSQL_ROOT_PASSWORD=root -e TZ="Asia/Shanghai" -p 33022:3306 mysql:5.7.31复制
除了上面的三个MySQL节点之外,MHA架构还需要一台服务器用于部署MHA的监控服务,当然也可以把这个MHA监控服务器安装在某一个MySQL节点上。我们这里在单独运行一个MySQL容器,用于部署MHA服务。这个MySQL容器,只是用于部署MHA监控服务,不参与其他功能,所以我们挂载MySQL配置my.cnf
配置文件了。
# MHA的管理节点
docker run --net=mysql-ha-mha-network --hostname manager.mysql --ip 172.21.0.100 --cap-add NET_ADMIN --name mysql-ha-mha-manager -d --privileged=true -v sys/fs/cgroup:/sys/fs/cgroup -e MYSQL_ROOT_PASSWORD=root -e TZ="Asia/Shanghai" mysql:5.7.31复制
配置主从链路
我们是一个展现的MySQL集群,不涉及到历史数据的同步,所以在MySQL的三个节点启动成功之后,只要在slave1和slave2上面配置一下主从同步的链路,然后启动主从复制的链路就可以了。
查看master1节点的日志点
mysql> show master status;
+--------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+--------------------------+----------+--------------+------------------+-------------------+
| master1-mysql-bin.000001 | 154 | | | |
+--------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)复制
在两个从节点上,都执行如下命令,用于配置主从链路。
change master to master_user='repl', master_password='repl', master_host='172.21.0.11', master_log_file='master1-mysql-bin.000001', master_log_pos=154;复制
在主节点上面,执行如下命令,用于创建主从复制链路使用的MySQL数据库用户。
create user 'repl'@'172.21.0.%' identified by 'repl';
grant replication client, replication slave on *.* to 'repl'@'172.21.0.%';
/* 这里之所有增加replication client的原因是,这个账号会同步到所有的slave节点,任何一个从节点,在主宕机的时候,都可能成功主,这样做是为了避免以后的权限不足导致主从切换失败。*/复制
启动主从复制
在两个从节点,执行如下命令,来启动主从复制链路。
start slave;复制
在slave上执行如下命令,查看主从同步的状态
show slave status\G复制
如果你对如何配置组从复制集群不了解,可以参考我分享的历史文章。
注意:这里的MySQL集群使用的是基于日志点的复制来实现的,如果使用基于GTID的复制方式也是可以的。
安装MHA
下载MHA
如果是要使用源码编译安装,源码下载的地址有2个地方,一个是Google,另外一个是GitHub。
从Google网站上下载,需要特殊的方式才可以下载,请自备梯子。地址为:https://code.google.com/archive/p/mysql-master-ha/downloads。这里下载的是稳定版本,最近的一个版本是0.55版本。
另外一个下载的地方是GitHub,这里有比较新的版本,如果你想要更新的版本,可以从这里下载。下载地址为:https://github.com/yoshinorim/mha4mysql-manager,目前这里最新的版本是0.58版本。
以上两个下载的地方,除了可以提供源码下载之外,还可以提供试用Linux、CentOS的rpm安装包和使用Debian、Ubuntu的deb安装包。如果你不想使用源码编译安装,那么下载对应的rpm文件和deb文件也是可以的。
我这里使用apt-get来安装,这样的方式也是基于deb文件来安装的,但是它可以自己解决安装MHA的deb安装的依赖文件,不用先安装依赖了。
安装MHA
在下载安装之前,先配置一下apt-get
源,然后安装一下常用的工具包软件。
cp etc/apt/sources.list etc/apt/sources.list.bak
echo "
deb http://mirrors.aliyun.com/debian/ buster main non-free contrib
deb http://mirrors.aliyun.com/debian-security buster/updates main
deb http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib
deb http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib
deb-src http://mirrors.aliyun.com/debian-security buster/updates main
deb-src http://mirrors.aliyun.com/debian/ buster main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ buster-updates main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ buster-backports main non-free contrib
" > etc/apt/sources.list复制
更新系统,并安装常用的软件包:
# 更新系统
apt-get update
# 安装常用软件包
apt-get install net-tools vim ssh telnet iproute2 iproute2-doc -y复制
配置ssh免密登录
在MySQL集群中,需要配合各个节点之间的免密登录,因为MHA在做主从切换故障转移的时候,需要依赖于ssh免密登录的功能。
用操作系统的root用户在每一个节点上面都执行如下命令,一路回车就行
# 创建公钥和私钥,一路回车默认即可
ssh-keygen
# 启动ssh服务
/etc/init.d/ssh start
# 把公钥配置到各个节点的`~/.ssh/authorized_keys`配置文件中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.21.0.11
ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.21.0.12
ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.21.0.22
ssh-copy-id -i ~/.ssh/id_rsa.pub root@172.21.0.100复制
修改所有节点的host文件,在host文件中增加IP地址和主机名称的映射关系如下,便于在使用ssh命令的时候,通过主机名称来连接。
# 修改所有节点的host文件
vim etc/hosts
# host文件增加如下内容
172.21.0.11 master1.mysql master1
172.21.0.12 slave1.mysql slave1
172.21.0.22 slave2.mysql slave2
172.21.0.100 manager.mysql manager复制
备注:方便以后使用,可以配置ssh服务开机自动启动:
systemctl ssh enable复制
安装MAH软件包
我们可以使用apt-get
的方式来安装,也可以使用源码来编译安装。如果是用源码编译安装,需要提前手动安装一些编译所依赖的软件包。如果使用apt-get
则可以避免手动安装依赖,apt-get
会自动下载并安装所有MAH软件依赖的软件包。如果你使用的服务器不是Ubuntu,而是RedHat或者CentOS,可以使用yum
来安装,而不是这里提到的apt-get
。
# 查看mha安装包
apt-cache search mha4mysql
# 所有的node节点执行如下命令,包括manager节点
apt-get install mha4mysql-node -y
# 在manager节点执行如下命令
apt-get install mha4mysql-manager -y复制
注意:截止目前为止,上面命令安装的MHA的版本是0.58,随着时间的推移如果你也采用上面的apt-get
来安装,可能安装的版本会比这个更新。后面的配置也是基于这个版本来操作的。
配置MHA
配置文件目录自定义,文件自己写,可以从GitHub上下载的安装包中查找示例。
建议配置文件放在/etc/mha
下面。这个目录不存在可以使用操作系统的root用户来创建。
# 下面这个目录用于存放mha的配置文件
mkdir -p etc/mha
# 下面的目录用于存放自定义的Perl脚本
mkdir -p etc/mha/aap1复制
在/etc/mha
下面创建一个app1.cnf
配置文件,表示一个MySQL集群的配置文件,如果有多个MySQL集群需要做MHA的监控,这里可以创建多个app.cnf
配置文件。
root@manager:/etc/mha# cat etc/mha/app1.cnf
[server default]
# manager服务在manger节点的工作目录,这里会生成一些临时文件
manager_workdir=/var/log/mha/app1
# node服务在node节点的工作目录,这里会生成一些临时文件,主要用来保存从已经宕机的主节点上保存下来的binglog日志文件
remote_workdir=/var/log/mha/app1
# manager服务运行过程中日志文件
manager_log=/var/log/mha/app1/app1.log
# 当MHA manager检测到master不可用时,通过masterha_secondary_check脚本来进一步确认,减低误切的风险。如下配置,是配置的两个salve节点是否可以通过3306连接到主节点,进行再次确认主是否真的死掉了。
secondary_check_script=masterha_secondary_check -s 172.21.0.12 -s 172.21.0.22 --user=root --master_host=mysql.master1 --master_ip=172.21.0.11 --master_port=3306
# master节点在宕机的时候,执行切换的时候,执行的自定义脚本文件,可以不指定配置这个脚本,如果想在切换的时候,实现自己的逻辑,可以在这里进行编写。比如编写VIP漂移的逻辑等
master_ip_failover_script=/etc/mha/app1/master_ip_failover
# 强制关闭主节点主机的自定义脚本,这个脚本的作用是当发生主从切换之后,把宕机主给再次关闭一次,避免误判后,主还活着,而新的主页选择好了,发生脑裂的现象。
#shutdown_script=/etc/mha/app1/power_manager
# 发生主从切换之后,发送邮件通知运维人员的自定义脚本
#report_script=/etc/mha/app1/send_master_failover_mail
# MySQL的root用户账号和密码
user=root
password=root
# 服务器中配置ssh免密登录的用户
ssh_user=root
# MySQL组从同步复制的用户和密码
repl_user=repl
repl_password=repl
# 检查频次,每3秒检查一次主节点状态。
ping_interval=3
[server1]
hostname=172.21.0.11 # master1节点的配置,这里对应/etc/hosts中配置的主机名称
candidate_master=1
[server2]
hostname=172.21.0.12 # slave1节点IP地址
candidate_master=1 # 1表示该节点为备选主节点
[server3]
hostname=172.21.0.22 # slave2节点IP地址
no_master=1 # 表示该节点不是备选主节点
root@manager:/etc/mha#复制
验证MHA配置
在manager节点检查各个节点之间的ssh免密登录是否成功
root@manager:/etc/mha# masterha_check_ssh --conf=/etc/mha/app1.cnf
Mon Mar 1 14:51:47 2021 - [warning] Global configuration file etc/masterha_default.cnf not found. Skipping.
Mon Mar 1 14:51:47 2021 - [info] Reading application default configuration from etc/mha/app1.cnf..
Mon Mar 1 14:51:47 2021 - [info] Reading server configuration from etc/mha/app1.cnf..
Mon Mar 1 14:51:47 2021 - [info] Starting SSH connection tests..
Mon Mar 1 14:51:48 2021 - [debug]
Mon Mar 1 14:51:47 2021 - [debug] Connecting via SSH from root@master1(172.21.0.11:22) to root@slave1(172.21.0.12:22)..
Mon Mar 1 14:51:47 2021 - [debug] ok.
Mon Mar 1 14:51:47 2021 - [debug] Connecting via SSH from root@master1(172.21.0.11:22) to root@slave2(172.21.0.22:22)..
Mon Mar 1 14:51:48 2021 - [debug] ok.
Mon Mar 1 14:51:48 2021 - [debug]
Mon Mar 1 14:51:47 2021 - [debug] Connecting via SSH from root@slave1(172.21.0.12:22) to root@master1(172.21.0.11:22)..
Mon Mar 1 14:51:48 2021 - [debug] ok.
Mon Mar 1 14:51:48 2021 - [debug] Connecting via SSH from root@slave1(172.21.0.12:22) to root@slave2(172.21.0.22:22)..
Mon Mar 1 14:51:48 2021 - [debug] ok.
Mon Mar 1 14:51:49 2021 - [debug]
Mon Mar 1 14:51:48 2021 - [debug] Connecting via SSH from root@slave2(172.21.0.22:22) to root@master1(172.21.0.11:22)..
Mon Mar 1 14:51:48 2021 - [debug] ok.
Mon Mar 1 14:51:48 2021 - [debug] Connecting via SSH from root@slave2(172.21.0.22:22) to root@slave1(172.21.0.12:22)..
Mon Mar 1 14:51:48 2021 - [debug] ok.
Mon Mar 1 14:51:49 2021 - [info] All SSH connection tests passed successfully.
Use of uninitialized value in exit at usr/bin/masterha_check_ssh line 44.
root@manager:/etc/mha#复制
检查主从同步的状态的脚本执行失败,错误信息如下:
root@manager:/etc/mha# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Mar 1 15:10:33 2021 - [warning] Global configuration file etc/masterha_default.cnf not found. Skipping.
Mon Mar 1 15:10:33 2021 - [info] Reading application default configuration from etc/mha/app1.cnf..
Mon Mar 1 15:10:33 2021 - [info] Reading server configuration from etc/mha/app1.cnf..
Mon Mar 1 15:10:33 2021 - [info] MHA::MasterMonitor version 0.58.
Mon Mar 1 15:10:34 2021 - [error][/usr/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. Redundant argument in sprintf at usr/share/perl5/MHA/NodeUtil.pm line 201.
Mon Mar 1 15:10:34 2021 - [error][/usr/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
Mon Mar 1 15:10:34 2021 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
root@manager:/etc/mha#复制
解决方式如下:
# vi usr/share/perl5/MHA/NodeUtil.pm
sub parse_mysql_major_version($) {
my $str = shift;
my $result = sprintf( '%03d%03d', $str =~ m/(\d+)/g );
return $result;
}
# 改为如下:
# vi usr/share/perl5/MHA/NodeUtil.pm
sub parse_mysql_major_version($) {
my $str = shift;
$str =~ (\d+)\.(\d+)/;
my $strmajor = "$1.$2";
my $result = sprintf( '%03d%03d', $strmajor =~ m/(\d+)/g );
return $result;
}复制
启动MHA
进入/etc/mh
目录,让日志写在这个目录下面,然后启动MHA,命令如下:
nohup masterha_manager --conf=/etc/mha/app1.cnf &复制
启动后可以看到在当前目录下面,有一个名称为nohup.out
的文件生成,这里面是记录的MHA服务启动的日志。这样我们的MHA就搭建完成了。
MHA命令介绍
MAH在安装配置好之后,我们需要熟悉以下的命令才能使用MHA。下面介绍一下MHA中涉及到的各种管理命令。
mah-manager命令
在manager节点安装MHA服务后,会有如下的脚本命令可以使用:
masterha_check_repl:检查当前MySQL集群中的主从复制链路是否正常工作,后面需要跟上
--conf=/xx/xx/xx.cnf
配置文件的参数。使用示例如下所示:
root@manager:/etc/mha# masterha_check_repl --conf=/etc/mha/app1.cnf
Mon Mar 1 23:30:35 2021 - [warning] Global configuration file etc/masterha_default.cnf not found. Skipping.
# 这里省略输出内容
MySQL Replication Health is OK.
root@manager:/etc/mha#复制
masterha_check_ssh:检查MySQL集群中的各个节点ssh免密登录的功能是否可用。使用示例如下所示:
root@manager:/etc/mha# masterha_check_ssh --conf=/etc/mha/app1.cnf
Mon Mar 1 23:32:56 2021 - [warning] Global configuration file etc/masterha_default.cnf not found. Skipping.
Mon Mar 1 23:32:56 2021 - [info] Reading application default configuration from etc/mha/app1.cnf..
Mon Mar 1 23:32:58 2021 - [info] All SSH connection tests passed successfully.
Use of uninitialized value in exit at usr/bin/masterha_check_ssh line 44.
root@manager:/etc/mha#复制
masterha_check_status:检查当前MHA服务的运行状态是running还是stopped。
root@manager:/etc/mha# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:10319) is running(0:PING_OK), master:172.21.0.12
root@manager:/etc/mha#复制
masterha_manager:启动MHA服务的命令,后面需要跟上
--conf=/xx/xx/xx.cnf
配置文件的参数。后台启动示例如下所示:
root@manager:/etc/mha# nohup masterha_manager --conf=/etc/mha/app1.cnf &
[1] 10319
root@manager:/etc/mha# nohup: ignoring input and appending output to 'nohup.out'
root@manager:/etc/mha#复制
masterha_stop:停止MHA服务的命令,后面需要跟上
--conf=/xx/xx/xx.cnf
配置文件的参数。时候示例如下所示:
root@manager:/etc/mha# masterha_stop --conf=/etc/mha/app1.cnf
Stopped app1 successfully.
[1]+ Exit 1 nohup masterha_manager --conf=/etc/mha/app1.cnf
root@manager:/etc/mha#复制
masterha_conf_host:添加或删除配置的server信息,这个命令用来修改MHA的配置文件信息,修改完成之后,最好把MHA的manager服务重启一下。使用示例如下所示:
# 向配置文件/etc/mha/app1.cnf中添加一个block名称为server4的配置信息。
root@manager:/etc/mha# masterha_conf_host --command=add --conf=/etc/mha/app1.cnf --block=server4 --hostname=172.21.0.23
Wrote server4 entry to app1.cnf .
# 查看添加后的结果如下,发现已经增加了一个server4的block信息
root@manager:/etc/mha# tail -6 etc/mha/app1.cnf
[server3]
candidate_master=1
hostname=172.21.0.22
[server4]
hostname=172.21.0.23
root@manager:/etc/mha#
# 删除一个节点server4的配置信息,--command=remove也可以,等于delete也可以。
root@manager:/etc/mha# masterha_conf_host --command=delete --conf=/etc/mha/app1.cnf --block=server4 --hostname=172.21.0.23
Deleted server4 entry from etc/mha/app1.cnf .
# 查看删除后的效果如下,发现配置文件中已经没有server4的block配置信息了
root@manager:/etc/mha# tail -6 etc/mha/app1.cnf
candidate_master=1
hostname=172.21.0.12
[server3]
candidate_master=1
hostname=172.21.0.22
root@manager:/etc/mha#
# 在新增加的block中,增加更多的配置信息,可以使用--params="key=val,key=val,key=val..."这样的方式来做,如下:
root@manager:/etc/mha# masterha_conf_host --command=add --conf=/etc/mha/app1.cnf --block=server4 --hostname=172.21.0.23 --params="no_master=1;ignore_fail=1"
Wrote server4 entry to etc/mha/app1.cnf .
# 检查配置后的结果如下,可以发现我们使用参数--params指定的key和value也配置成功了。
root@manager:/etc/mha# tail -6 etc/mha/app1.cnf
hostname=172.21.0.22
[server4]
hostname=172.21.0.23
ignore_fail=1
no_master=1
root@manager:/etc/mha#复制
masterha_master_switch:控制故障转移的脚本,当MHA发现原先的主宕机之后,会使用这个脚本来进行切换。或者我们可以手动的调用这个脚本来实现手动的转移。使用示例如下所示:
# 确定现在的主节点slave1已经死掉,将原先的主master1提升为新的主。
root@manager:/etc/mha# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=dead --dead_master_host=slave1 --new_master_host=master1
# 确定现有的主slave1已经死掉,由MAH自己选择新的主。
root@manager:/etc/mha# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=dead --dead_master_host=slave1复制
masterha_master_monitor:检查master节点是否宕机,使用示例如下所示:
root@manager:/etc/mha# masterha_master_monitor --conf=/etc/mha/app1.cnf复制
masterha_secondary_check:当MHA manager检测到master不可用时,通过masterha_secondary_check这个脚本来进一步确认主节点是否真正的挂掉了,减低manager节点误判的风险。
root@manager:/etc/mha# masterha_secondary_check -s slave1 -s slave2 --user=root --master_host=master1.mysql --master_ip=172.21.0.11 --master_port=3306
Master is reachable from slave1!
Master is reachable from slave2!
root@manager:/etc/mha#复制
mha-node命令
在其他MySQL服务器节点安装MHA服务之后,会有如下的脚本命令可以使用:
save_binary_logs : 保存和复制master的二进制日志。
apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。
filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
purge_relay_logs : 清除中继日志,这个清除relay log的命令不会阻塞SQL线程,使用示例如下所示:
复制
这里说明一下为什么在node节点上面会有这个purge_relay_logs
的命令呢?MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。
在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。(在mysql数据库中,删除大表时,通常也采用建立硬链接的方式)
mah-自定义脚本
除了上面直接提供的命令之外,还可以自定义如下的脚本命令:
secondary_check_script:通过多条网络路由检测master的可用性;
master_ip_failover_script:更新application使用的masterip,需要自己根据环境需求适当修改。
shutdown_script:当发生主从切换之后,强制关闭master节点,设置故障发生后关闭故障主机脚本,该脚本的主要作用是关闭主节点所在主机,防止发生脑裂。
report_script:发送邮件报告。
init_conf_load_script:加载初始配置参数,如果你的MySQL中的相关密码,不想配置在明文中,可以参考这个脚本来做。
master_ip_online_change:更新master节点ip地址,需要自己根据环境需求适当修改。
主从切换的验证
现在我们来动态的验证一下,MHA是否可以真正地做到在master1节点宕机之后,会自动的完成主从切换的功能。
监控manager节点的日志
首先,我们观察一下在MHA的监控节点的manager上面的日志输出是什么内容。可以在停止主节点的MySQL服务器之前,使用如下命令动态观察日志的输出内容,然后我们再去停止主节点的MySQL服务。
tail -f etc/mha/nohup.out复制
停止master1节点
然后我们在主节点,停止MySQL数据库服务,使用如下两种方式中的任何一种都可以:
# 在master1节点容器的内部执行如下命令:
/etc/init.d/mysql stop
# 或者在docker的宿主机上面执行如下命令,关闭容器
docker stop mysql-ha-mha-master1复制
验证主从切换结果
此时我们会发现manager上面的日志输出,主从同步的主节点从原先的master1上迁移到了从节点slave1上面。salve2节点也自动的把主从同步的链路从master1改为了slave1上面。下面分别在slave1和slave上面执行如下的命令:
Slave1节点如下,可以看出它没有从节点的状态了,已经不再是从节点了,变成了一个新的主节点。并且有master的状态。
/* slave1上面执行的结果如下 */
mysql> show slave status\G
Empty set (0.00 sec)
mysql> show master status;
+-------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------------+----------+--------------+------------------+-------------------+
| slave1-mysql-bin.000001 | 1229 | | | |
+-------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> insert into tab values(3),(4),(5);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from tab;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+----+
5 rows in set (0.00 sec)
mysql>复制
Slave2节点如下,可以看到它可以成功的同步到salve1节点上面插入的数据,主从复制的链路已经切换为salve1作为它的主库,不再是之前的master1作为它的主库了。
/* slave2上面执行的结果如下 */
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.21.0.12
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: slave1-mysql-bin.000001
Read_Master_Log_Pos: 1229
Relay_Log_File: mysql-relay.000002
Relay_Log_Pos: 327
Relay_Master_Log_File: slave1-mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
......... /*省略输出*/
Master_Server_Id: 12
Master_UUID: 401afbfb-7a2b-11eb-b8e5-0242ac15000c
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
......... /*省略输出*/
Master_TLS_Version:
1 row in set (0.00 sec)
mysql> select * from tab;
+----+
| id |
+----+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+----+
5 rows in set (0.00 sec)
mysql>复制
当主从节点切换之后,MHA的服务会自动停止。此时我们从manager节点上查看一下MHA的运行状态如下:
root@manager:/etc/mha# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
root@manager:/etc/mha#复制
同时我们在/var/log/mha/app1
目录下面会发现如下一个标识文件,这个文件没有任何内容,只是一个标记文件。如果要再次启动MHA服务,则必须删除这个标记文件才可以正常启动MHA。
root@manager:/etc/mha# ls -lstr var/log/mha/app1/*
0 -rw-r--r-- 1 root root 0 Mar 1 20:29 var/log/mha/app1/app1.failover.complete
root@manager:/etc/mha#复制
恢复master1节点
在重新启动MHA之前,我们需要把宕机的master1节点恢复一下,让其作为一个slave节点加入到集群中去。从slave1中开始同步数据,因为此时salve1就是当前集群中的主节点。
但是在宕机的master1加入集群之前,需要把落下的数据追赶上当前的主节点。那么到底从哪里开始同步当前主节点的数据呢?在MHA的日志文件中,记录着需要从哪里开始同步当前主上面的数据。有一个change master
的语句在日志文件中,如下所示:
root@manager:/etc/mha# cat nohup.out | grep "CHANGE MASTER"
Mon Mar 1 20:29:36 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.21.0.12', MASTER_PORT=3306, MASTER_LOG_FILE='slave1-mysql-bin.000001', MASTER_LOG_POS=1229, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Mon Mar 1 20:29:37 2021 - [info] Executed CHANGE MASTER.
root@manager:/etc/mha#复制
我们只要在master1节点上执行上面的CHANGE MASTER
语句,然后执行start slave
命令就可以开始从上次宕机的时间点开始同步数据。等待追上当前的主节点的数据之后,我们就可以再次启动MHA监控服务了。
再次启动MHA服务
在宕机的节点被恢复并且追上集群中现有的master节点之后,在manager节点,使用如下命令开启MHA服务。
# 先删除上一次主从切换成功的标识文件
rm var/log/mha/app1/app1.failover.complete
# 后台启动MHA监控服务
nohup masterha_manager --conf=/etc/mha/app1.cnf &复制
如果没有在/etc/mha/app1.cnf
配置文件中定义manager服务的输出日志文件,那么会在当前目录下面的nohup.out文件中输出。有如下的输出日志时候,就表示MHA又一次启动成功了。如果定义了日志文件的目录和名字,可以到对应的目录和日志文件中查看日志。
root@manager:/etc/mha# tail -10 nohup.out
172.21.0.12(172.21.0.12:3306) (current master)
+--172.21.0.11(172.21.0.11:3306)
+--172.21.0.22(172.21.0.22:3306)
Mon Mar 1 21:15:56 2021 - [warning] master_ip_failover_script is not defined.
Mon Mar 1 21:15:56 2021 - [warning] shutdown_script is not defined.
Mon Mar 1 21:15:56 2021 - [info] Set master ping interval 1 seconds.
Mon Mar 1 21:15:56 2021 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes.
Mon Mar 1 21:15:56 2021 - [info] Starting ping health check on 172.21.0.12(172.21.0.12:3306)..
Mon Mar 1 21:15:56 2021 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
root@manager:/etc/mha#复制
VIP漂移的三种方式
MySQL高可用集群已经搭建好,但是当master1节点宕机之后,从节点提升为主节点后,应用连接到MySQL服务的主节点地址就变成了某一个slave从节点,那如何保证应用可用是一个固定的IP来连接MySQL数据库呢?这就需要使用到VIP虚拟IP地址。
这个VIP地址就是应用中配置的IP地址,它可用在活着的主节点上面绑定,如果主宕机了,这个VIP可用漂移到新的主上。这就是VIP要完成功能。那么如何让这个VIP自动漂移到活着的主节点呢?目前可有三种方式:
通过脚本自己去维护VIP绑定的节点,这要在MHA的扩展脚本中去做,使用perl脚本去做。
或者使用keepalive插件自己去维护,这种方式是在MHA做故障迁移的时候,顺便把发生故障的主机上面的keepalive服务给停止掉,这样VIP就可以从故障的节点迁移到指定的节点了。
就是上面两种1和2的方式结合的一种方式。在Perl脚本中不去维护VIP的创建绑定等操作,而是交给keepalive服务去做,只要在perl脚本中,决定什么时候在发生主节点MySQL服务不能用的时候,把该主节点上面的keepalive服务给停止,就可以把对应VIP漂移到其他主机上去了。
通过MHA自定义master_ip_failover维护
这个脚本就是master_ip_failover
自定义脚本。因为我不会写Perl,下面是网上扒来的,供参考。
大体的逻辑就是:我们在脚本中定义一个VIP地址,然后定义一个在远程服务器创建VIP,还有一个取消VIP的方法。然后MAH的manager进程在进行主从切换的时候,会调用这个自定义的master_ip_failover
脚本,并给这个脚本传入对应的参数和命令,这个脚本就根据manager进程转入的命令走对应的逻辑,来调用自定义的创建和取消VIP的方法,从而来实现VIP从原主节点到新节点的漂移。
在使用这个脚本之前,需要原先正常的master节点上,先使用下面的命令来创建一个VIP,然后才能将这个VIP漂移到新的主节点上。
root@master1:/var/log/mha/app1# ifconfig eth0:1 172.21.0.10 up
root@master1:/var/log/mha/app1# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.11 netmask 255.255.255.0 broadcast 172.21.0.255
ether 02:42:ac:15:00:0b txqueuelen 0 (Ethernet)
RX packets 1251 bytes 162986 (159.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3342 bytes 342702 (334.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.10 netmask 255.255.0.0 broadcast 172.21.255.255
ether 02:42:ac:15:00:0b txqueuelen 0 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 154 bytes 21841 (21.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 154 bytes 21841 (21.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0复制
master_ip_failover
的示例脚本如下:
root@manager:/var/log/mha/app1# cat etc/mha/app1/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
# MySQL cluster VIP for write request
my $vip = '172.21.0.10';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
# updating global catalog, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print "Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
#print "Creating app user on the new master..\n";
#FIXME_xxx_create_user( $new_master_handler->{dbh} );
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
#FIXME_xxx;
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
# If you want to continue failover, exit 10.
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
root@manager:/var/log/mha/app1#复制
通过keepalive来维护
我们接下来安装keepalive插接,目的是为了在MySQL数据集群中配置一个虚拟的VIP,然后让这个VIP可以根据主节点的状态来自动的在可用的主节点进行漂移。此时我们不需要自己在master节点上创建VIP,当我们在master节点和备选master节点上,配置好keepalive的配置文件/etc/keepalived/keepalived.conf
之后,启动keepalive服务后会自动在对应的节点创建VIP地址。
安装keepalive
我们在master1节点和slave1节点上面都安装keepalive插件,master1作为默认的主节点,slave1作为备用主节点(如果是有多个备选主节点,那么所有的备选主节点都要安装并启动keepalive服务),使用apt-get命令来安装keepalive软件,如果是centos使用yum来安装。
root@master1:/# apt-get install keepalived -y
root@slave1:/# apt-get install keepalived -y复制
keepalive安装完成之后,会在/etc/init.d
目录里下面生成一个启动脚本文件keepalived
,如下所示,我们只是master1节点上示例展示。查看这个脚本文件,可用看到它的配置文件是在/etc/keepalived/keepalived.conf
这里。所以,后续配置keepalive的时候,我们需要在这个配置文件中进行配置。
# 查看启动和停止keepalive服务的脚本文件
root@master1:/etc/keepalived# ls -lstr etc/init.d/keepalived
4 -rwxr-xr-x 1 root root 2121 Aug 15 2015 etc/init.d/keepalived
# 查看keepalive的默认配置文件配置路径是什么
root@master1:/etc/keepalived# cat etc/init.d/keepalived | grep CONFIG
CONFIG=/etc/keepalived/keepalived.conf
test -f $CONFIG || exit 0
root@master1:/etc/keepalived#复制
配置keepalive
在master1节点和slave1节点上面分别创建配置文件/etc/keepalived/keepalived.conf
,然后分别编辑配置他们。
在maste1上的keepalived.conf`配置文件如下:
root@master1:/etc/keepalived# cat etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 172.21.0.11
}
vrrp_script chk_mysql_status {
script "/etc/keepalived/check_mysql_port.sh 3306"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 251
priority 100
advert_int 1
mcast_src_ip 172.21.0.11
nopreempt
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_mysql_status
}
virtual_ipaddress {
172.21.0.10
}
}
root@master1:/etc/keepalived#复制
在slave1上的keepalived.conf`配置文件如下:
root@slave1:/etc/keepalived# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 172.21.0.12
}
vrrp_script chk_mysql_status {
script "/etc/keepalived/check_mysql_port.sh 3306"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 251
priority 90
advert_int 1
mcast_src_ip 172.21.0.12
nopreempt
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_mysql_status
}
virtual_ipaddress {
172.21.0.10
}
}
root@slave1:/etc/keepalived#复制
现在,针对上面的配置文件的参数,使用master1节点上面的配置文件,做如下简单介绍说明,以便于立即keepalive的配置文件怎么配置。
root@master1:/etc/keepalived# cat etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 172.21.0.11 # keepalive所在主机的IP地址,一个名字而已,这里用IP地址代替了。
}
vrrp_script chk_mysql_status {
# 检查主机3306端口的shell脚本,发生VIP漂移的触发原因就是某一个主机的某个端口不可用。这个脚本需要自定义去写一下,比较简单,后面会给出示例。
script "/etc/keepalived/check_mysql_port.sh 3306"
interval 2 # 端口检查的频次,每2秒中一次
weight -20
}
vrrp_instance VI_1 {
state BACKUP # 当前keepalive节点的角色
interface eth0 # 当前主机的物理网卡名称
virtual_router_id 251
priority 100
advert_int 1
mcast_src_ip 172.21.0.11 # 当前主机的物理IP地址
nopreempt
# keepalive多个节点互相通信的认证方式,用于标识哪些keepalive节点是同一个keepalive集群。
authentication {
auth_type PASS
auth_pass 11111111
}
track_script {
chk_mysql_status # 检查服务端口的脚本,VIP发生漂移的时候就是从这里触发的。
}
virtual_ipaddress {
172.21.0.10 # 这就是我们设置的VIP的地址
}
}
root@master1:/etc/keepalived#复制
注意:上面两台服务器的keepalived都设置为了BACKUP模式,目的是为了尽量减少VIP漂移的次数。具体原因如下:
在keepalived中2种模式,分别是master->backup模式和backup->backup模式。这两种模式有很大区别。
在master->backup模式下,一旦主库宕机,虚拟ip会自动漂移到从库,当主库修复后,keepalived启动后,还会把虚拟ip抢占过来,即使设置了非抢占模式(nopreempt)抢占ip的动作也会发生。
在backup->backup模式下,当主库宕机后虚拟ip会自动漂移到从库上,当原主库恢复和keepalived服务启动后,并不会抢占新主的虚拟ip,即使是优先级高于从库的优先级别,也不会发生抢占。
所以,为了减少ip漂移次数,通常是把修复好的主库当做新的备库。同时把keepalive中的角色都设置为backup角色。
在配置好keepalive的配置文件后,配置文件中有引用到一个监控某个服务是否可以的脚本,这里我们要监控的是MySQL数据库服务是否可用,所以我们监控的是MySQL的3306端口是否在提供监听服务。如果是要监听其他服务的端口,只要作出对应的端口作出修改即可。下面给出监听MySQL服务的shell脚本,这个脚本在每一个keepalive节点上都是一样的,在我们的master1和slave1上使用相同的脚本文件。
root@master1:/etc/keepalived# cat chk_mysql_status.sh
#!/bin/bash
CHK_PORT=$1
if [ -n "$CHK_PORT" ]; then
PORT_PROCESS=`ss -lnt | grep $CHK_PORT | wc -l`
if [ $PORT_PROCESS -eq 0 ]; then
echo "请注意:端口号$CHK_PORT现在已经不可用,下面将退出keepalive的服务,VIP即将发生漂移。" >> ./chk_mysql_status.log
# 发现当前主机的MySQL端口不能访问后,把当前主机的keepalive服务也停止,让这个主机上的VIP漂移到备选主节点上
etc/init.d/keepalived stop
exit 1
fi
else
echo "待监控的服务端口号不能为空!" >> ./chk_mysql_status.log
fi
root@master1:/etc/keepalived# pwd
/etc/keepalived
root@master1:/etc/keepalived#复制
需要注意的是脚本的放置目录,我们是放在和keepalive配置文件相同的目录/etc/keepalive
目录下面了。
启动keepalive
在master1节点上启动keepalive服务,如下所示:
root@master1:/etc/keepalived# etc/init.d/keepalived start
[ ok ] Starting keepalived: keepalived.
# 查看启动keepalive后,VIP已经创建成功
root@master1:/etc/keepalived# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000
link/tunnel6 :: brd ::
59: eth0@if60: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:15:00:0b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.21.0.11/24 brd 172.21.0.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.21.0.10/32 scope global eth0 # 这里就是我们配置的VIP,默认是master1上面,当master1节点的3306端口挂掉,或漂移到slave1上。
valid_lft forever preferred_lft forever
root@master1:/etc/keepalived#复制
在slave1节点上,也启动keepalive服务,如下所示:
root@slave1:/etc/keepalived# etc/init.d/keepalived start
[ ok ] Starting keepalived: keepalived.
root@slave1:/etc/keepalived#
# 此时slave1上面是没有我们配置的VIP的,因为master1目前还是可用状态。
root@slave1:/etc/keepalived# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
3: ip6tnl0@NONE: <NOARP> mtu 1452 qdisc noop state DOWN group default qlen 1000
link/tunnel6 :: brd ::
61: eth0@if62: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:15:00:0c brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.21.0.12/24 brd 172.21.0.255 scope global eth0
valid_lft forever preferred_lft forever
root@slave1:/etc/keepalived#复制
通过keepalive和master_ip_failover结合来使用
这种方式就结合前面使用MHA的master_ip_failover
脚本和keepalive两种方式的变形。实现的方式就是:VIP的创建我们交给keepalive来做,但是这个VIP要向完成漂移的动作,发生故障的服务器上面的keepalive进程必须终止后,VIP才会发生漂移,那么如何让这个发生故障的服务器上面的keepalive终止进程呢?就在我们的master_ip_failover
脚本中去终止对应的服务器上面的keepalive进程服务,这样这个服务器上面的VIP就会发生漂移了。
脚本的实现方式和第一种master_ip_failover
的脚本类似,只是此时我们不需要只是用keepalive的时候自定义的那个chk_mysql_status.sh
脚本来终止keepalive进程了。在master_ip_failover
脚本中去终止对应的keepalive服务进程。脚本如下:
root@manager:/var/log/mha/app1# cat etc/mha/app1/master_ip_failover
#!/usr/bin/env perl
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
# MySQL集群中的VIP地址
my $vip = '172.21.0.10';
# 开启和关闭VIP的命令,下面是通过停止对应的服务器上面的keepalive的命令,来完成VIP的漂移的。
my $ssh_start_vip = "/etc/init.d/keepalived start";
my $ssh_stop_vip = "/etc/init.d/keepalived stop";
# 也可以使用下面的方式,自己通过ifconfig命令在对应的服务器上面增加和删除VIP,这样在master节点和备选master节点就不用安装keepalive服务了。
#my $key = '1';
#my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip up";
#my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip(); # 调用停止VIP的方法
# updating global catalog, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print "Set read_only=0 on the new master.\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
#print "Creating app user on the new master..\n";
#FIXME_xxx_create_user( $new_master_handler->{dbh} ); # 如果应用使用的MySQL用户并没有在salve节点创建,可以在切换的时候,在这里定义并创建。但是一般情况下,整个集群中的所有用户都是相同的,权限也是相通的,所以一般情况用不上这个操作。
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
#FIXME_xxx;
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip(); # 调用开启VIP的方法
$exit_code = 0;
};
if ($@) {
warn $@;
# If you want to continue failover, exit 10.
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
# 在远程服务器开启VIP的方法
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# 在远程服务器停止VIP的方法
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
root@manager:/var/log/mha/app1#复制
验证VIP漂移
在验证VIP是否可以正常漂移的实验中,针对上面提出来的3种实现方式,我们选择第一种方式来验证一下。其他两种方式,我也一并做过,但是这里不再一一贴出实验过程。
第一种方式:通过master_ip_failover
脚本来维护VIP的漂移。在master1节点上创建一个VIP,如下所示,用于对外提供写的服务。然后我们看下在master1节点宕机的时候,这个上面的VIP是否可以自动漂移到salve1备用主主节点上。
# 在master1节点上创建VIP地址
root@master1:/var/log/mha/app1# ifconfig eth0:1 172.21.0.10 up
# VIP地址已经在master1节点上创建完成
root@master1:/var/log/mha/app1# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.11 netmask 255.255.255.0 broadcast 172.21.0.255
ether 02:42:ac:15:00:0b txqueuelen 0 (Ethernet)
RX packets 1251 bytes 162986 (159.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3342 bytes 342702 (334.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.10 netmask 255.255.0.0 broadcast 172.21.255.255
ether 02:42:ac:15:00:0b txqueuelen 0 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 154 bytes 21841 (21.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 154 bytes 21841 (21.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 此时的salve1节点上是没有VIP地址的
root@slave1:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.12 netmask 255.255.255.0 broadcast 172.21.0.255
ether 02:42:ac:15:00:0c txqueuelen 0 (Ethernet)
RX packets 9 bytes 726 (726.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@slave1:/#复制
对于master_ip_failover
脚本,参考上面提到VIP漂移第一种实现方式的贴出来的脚本内容,这不再重复贴出。
验证VIP是否可用
现在的VIP已经在master1上面创建成功了,下面我们来尝试使用这个VIP是否可以正常方式到MySQL服务。我们在安装MHA服务的manager节点上,尝试通过VIP来访问MySQL数据库服务,看是否可以成功。通过如下结果可以看出通过VIP是可以正常方式MySQL服务的。
root@manager:/etc/mha# mysql -uroot -proot -h172.21.0.10
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 48
Server version: 5.7.31-log MySQL Community Server (GPL)
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@hostname;
+---------------+
| @@hostname |
+---------------+
| master1.mysql |
+---------------+
1 row in set (0.00 sec)
mysql>复制
通过上面的实验可以看出,在manager节点172.21.0.100
上是可以通过172.21.0.10
这个VIP来访问MySQL数据库的。
验证VIP是否可以漂移
manager节点的操作
首先,我们在manager节点上面,启动MHA的manager服务。启动方式如下所示,我们选择后台启动。
# 以后进程的方式启动MHA的manager服务
root@manager:/var/log/mha/app1# nohup masterha_manager --conf=/etc/mha/app1.cnf &
[1] 1230
root@manager:/var/log/mha/app1# nohup: ignoring input and appending output to 'nohup.out'复制
查看manager服务启动后,日志目录下面的文件有哪些。日志文件的目录在/etc/mha/app1.cnf配置文件中定义。
# 启动后,发现会在/var/log/mha/app1目录下面生如下3个文件,一个是nohup的日志输出,一个是manager服务的日志输出文件,一个是MySQL数据库集群中master节点监控状态标识文件。
root@manager:/var/log/mha/app1# ls -lstr
total 16
4 -rw------- 1 root root 299 Mar 7 09:56 nohup.out
8 -rw-r--r-- 1 root root 5784 Mar 7 09:56 app1.log
4 -rw-r--r-- 1 root root 33 Mar 7 09:56 app1.master_status.health复制
用如下的命令动态监控manager服务的日志输出是什么,以方便我们在测试主从切换的时候,动态查看manager服务的日志内容。
# 用tail -f的命令动态的观察manager服务日志的输出内容,发现目前已经启动manager服务,它在等待MySQL服务不可用的时候,才会有动作以及日志的输出。
root@manager:/var/log/mha/app1# tail -f app1.log
Sun Mar 7 09:56:55 2021 - [info] Checking master_ip_failover_script status:
Sun Mar 7 09:56:55 2021 - [info] etc/mha/app1/master_ip_failover --command=status --ssh_user=root --orig_master_host=172.21.0.11 --orig_master_ip=172.21.0.11 --orig_master_port=3306
Checking the Status of the script.. OK
Sun Mar 7 09:56:55 2021 - [info] OK.
Sun Mar 7 09:56:55 2021 - [warning] shutdown_script is not defined.
Sun Mar 7 09:56:55 2021 - [info] Set master ping interval 1 seconds.
Sun Mar 7 09:56:55 2021 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes.
Sun Mar 7 09:56:55 2021 - [info] Starting ping health check on 172.21.0.11(172.21.0.11:3306)..
Sun Mar 7 09:56:55 2021 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..复制
master1主节点的操作
下面我们可以尝试把master1节点MySQL服务停止掉,看下VIP是否会自动漂移到slave1上。在master1节点上执行如下操作来停止MySQL数据库服务。由于我们的MySQL服务是用docker容器启动的,当我们停止容器中的MySQL之后,这个容器也就退出了。
root@master1:~# etc/init.d/mysql stop
...........% ➜ ~复制
查看manager节点的日志
当发生主从切换之后,manager节点上面的manager服务会停止,如下可以查看manager服务以及停止,需要在我们恢复好MySQL数据失败的节点之后,再次以后台进程的方式启动起来。
# 检查manager节点上的manager服务的状态,发现在完成主从切换之后,它已经停止了
root@manager:/var/log/mha/app1# masterha_check_status --conf=/etc/mha/app1.cnf
app1 is stopped(2:NOT_RUNNING).
root@manager:/var/log/mha/app1#复制
同时,我们可以查看在manager节点manager服务的日志目录下面,有如下文件生成,需要注意的是,其中的app1.failover.complete
标识文件,需要删除之后,才可以再次启动manager服务。否则我们的manager服务是不能启动成功的。
root@manager:/var/log/mha/app1# ls -lstr
total 28
4 -rw------- 1 root root 773 Mar 7 10:06 nohup.out # nohup的输出日志文件
24 -rw-r--r-- 1 root root 22206 Mar 7 10:06 app1.log # 主从切换过程的日志文件
0 -rw-r--r-- 1 root root 0 Mar 7 10:06 app1.failover.complete # 主从切换完成的标识文件,再次启动manager服务之前,需要将这个文件删除之后,才可以再次启动manager服务。
root@manager:/var/log/mha/app1# pwd
/var/log/mha/app1
root@manager:/var/log/mha/app1#复制
在manager节点上,查看manager节点的主从切换的日志输出如下,由于日志内容太长,这里我们只列出最后几行的日志内容。
root@manager:/var/log/mha/app1# tail -f app1.log
# ...省略...
Master 172.21.0.11(172.21.0.11:3306) is down!
Check MHA Manager logs at manager.mysql:/var/log/mha/app1/app1.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 172.21.0.11(172.21.0.11:3306)
The latest slave 172.21.0.12(172.21.0.12:3306) has all relay logs for recovery.
Selected 172.21.0.12(172.21.0.12:3306) as a new master.
172.21.0.12(172.21.0.12:3306): OK: Applying all logs succeeded.
172.21.0.12(172.21.0.12:3306): OK: Activated master IP address.
172.21.0.22(172.21.0.22:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
172.21.0.22(172.21.0.22:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.21.0.12(172.21.0.12:3306)
172.21.0.12(172.21.0.12:3306): Resetting slave info succeeded.
Master failover to 172.21.0.12(172.21.0.12:3306) completed successfully.复制
slave1节点的操作
查看备选主节点slave1上面的是否有VIP的地址,通过如下命令可以查看VIP已经漂移到了slave1节点上了。这个漂移的动作就是我们在master_ip_failover
脚本中,通过ifconfig
命令来实现的,这个脚本会在MHA的manager服务在完整主从切换之后自动调用的。至于这个脚本的具体位置和路径,则是定义在/etc/mha/app1.cnf
配置文件中。
root@slave1:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.12 netmask 255.255.255.0 broadcast 172.21.0.255
ether 02:42:ac:15:00:0c txqueuelen 0 (Ethernet)
RX packets 433 bytes 61965 (60.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 395 bytes 96296 (94.0 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.21.0.10 netmask 255.255.0.0 broadcast 172.21.255.255
ether 02:42:ac:15:00:0c txqueuelen 0 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 59 bytes 8093 (7.9 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 59 bytes 8093 (7.9 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@slave1:/#复制
以上,我们就验证了通过master_ip_failover
在定义的脚本来完成VIP在发生主从切换的时候漂移的过程。至于另外两种VIP漂移的方式,实验过程大同小异。大家可以自行式样。
如何恢复失败节点
在manger节点上的操作
在manager节点中的app1.log
中,包含具体恢复失败节点的命令提示。其实现的原理则是把失败的主节点,以一个从节点的角色再次加入到集群当中去。
当前启动好失败的主节点之后,如何把这个恢复的节点加入到集群当中去,可以参考app1.log
日志文件中的输出内容。
root@manager:/var/log/mha/app1# cat app1.log | grep "CHANGE"
Sun Mar 7 10:06:25 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.21.0.12', MASTER_PORT=3306, MASTER_LOG_FILE='slave1-mysql-bin.000007', MASTER_LOG_POS=154, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Sun Mar 7 10:06:27 2021 - [info] Executed CHANGE MASTER.
root@manager:/var/log/mha/app1#复制
在失败节点上的操作
根据上面在app1.log
日志文件中输出的内容,改为如下内容,在失败的节点上,执行改变主从复制链路的命令之后,就可以把刚恢复的节点以从节点的角色加入到MHA考可用集群当中。
/* 在失败节点执行如下命令,设置新的复制链路 */
mysql> CHANGE MASTER TO MASTER_HOST='172.21.0.12', MASTER_PORT=3306, MASTER_LOG_FILE='slave1-mysql-bin.000007', MASTER_LOG_POS=154, MASTER_USER='repl', MASTER_PASSWORD='repl';
Query OK, 0 rows affected, 2 warnings (0.03 sec)
/* 启动复制链路 */
mysql> start slave;
Query OK, 0 rows affected (0.03 sec)
/* 查看主从复制后的链路,发现链路已经切换为slave1作为主节点了 */
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.21.0.12
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: slave1-mysql-bin.000007
Read_Master_Log_Pos: 154
Relay_Log_File: master1-relay-bin.000002
Relay_Log_Pos: 327
Relay_Master_Log_File: slave1-mysql-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
/* ...省略输出内容... */
Master_Server_Id: 12
Master_UUID: 3ae2324e-7bef-11eb-bc99-0242ac15000c
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
1 row in set (0.00 sec)
mysql>复制
在manager节点上操作
前面的步骤我们已经恢复了主从复制的链路,接下来就是要再次启动我们的MHA在manager节点上的manager服务。
在启动之前,需要把manager节点上的主从切换完成的标识文件删除掉,如下所示:
root@manager:/var/log/mha/app1# rm /var/log/mha/app1/app1.failover.complete
root@manager:/var/log/mha/app1#复制
然后再次启动MAH监控服务,
# 后台启动MHA的manager服务
root@manager:/var/log/mha/app1# nohup masterha_manager --conf=/etc/mha/app1.cnf &
[1] 1877
root@manager:/var/log/mha/app1# nohup: ignoring input and appending output to 'nohup.out'
# 查看MHA的manager服务启动的结果
root@manager:/var/log/mha/app1# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:1877) is running(0:PING_OK), master:172.21.0.12
root@manager:/var/log/mha/app1#复制
读服务怎么解决
对于一个高可用的MHA集群,对外提供写的服务,可以通过VIP来解决应用层连接的问题。那么对于读的服务,多个slave节点如何对应用层提供服务?
其实,对于这样的高可用的集群,它是一个读写分离的高可用集群。主节点提供写的服务,从节点提供读的服务。在应用层连接数据库的时候,就需要配置两个IP地址,一个用于写,一个用于读。这样对应用层是有侵入性的,因为应用层要自己确定每一个SQL请求到底是该发送到写的IP地址,还是发送到读的IP地址上。
为了解决这种对应用层侵入的问题,有现有的数据库中间件来解决这样问题。MyCat就是这样一个可以使用读写分离的数据库中间件。我们把上面我们提到的VIP地址,和多个slave节点IP地址,分别配置在MyCat中,MyCat会根据接收到的SQL语句自动识别出这是一个写请求还是一个读请求,进而把对应的SQL发送给VIP还是salve的IP。至于到底发送到哪个salve节点上,MyCat里有各种可以选择的配置方式,轮休分发的策略是常用的配置方式。MyCat对外提供一个IP地址,供应用层来连接MyCat。这样就解决了MHA高可用集群的读写分离。
如果考虑到MyCat的高可用,可以在MySQL的MHA集群上层部署两台MyCat,做高可用的MyCat,然后通过keepalive在两个MyCat上启动一个VIP,让应用通过这个VIP来连接MyCat。最后的网络拓扑图,如下所示:
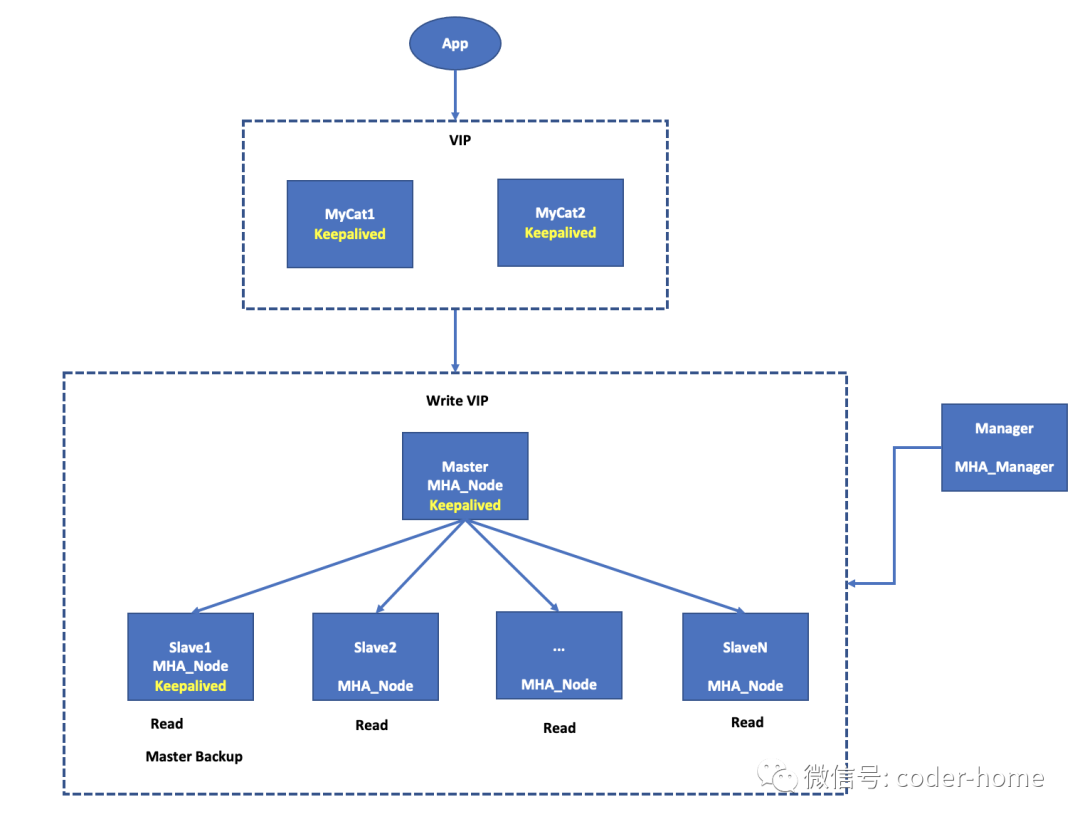
思考
MHA中的manager节点,本身就是一个单节点,该如何避免这个呢?
目前的MHA还不支持两个MHA的manager共同管理一个MySQL集群。从技术上讲,你可以部署两个manager去监控同一个MySQL集群。但是,当发生故障转移的时候两个MHA的manager节点都在对MySQL集群进行故障转移,如果他们选择的从节点不是同一个从节点将会发生什么情况?整个MySQL集群就有可能产生两个master节点,发生脑裂的现象。所以我们目前还没有一个很好的办法对MHA的manager节点做高可用。
比较推荐的一种做法是通过监控脚本去对MHA的manager服务是否正在运用进行监控,如果没有运行就把这个服务再次尝试启动。可以把这样的脚本配置在Linux服务器的crontab中。
另外一种做法就是使用类似于的supervisor这样的后端守护进程去监控manager节点的manager服务是否正常运行,如果发现没有在运行,supervisor会尝试把manager进程给启动起来。此时,我们不用担心在MySQL集群发生故障转移主从切换之后MHA的manager节点在自动停止运行之后,再次被supervisor这样的守护进程给再次拉取起来。因为此时的manager进程是启动不了的,因为manager进程在启动的时候,会检查是否有上一次MySQL宕机的时候生成的标识文件,如果没有这样的文件才会启动成功,有这样的文件,是不会启动成功的。
MySQL中集群虽然高可用了,那VIP漂移的问题怎么解决的呢?
我们可以使用两种方式来解决这个VIP漂移的问题。
可以使用基于MHA的Perl脚本去做VIP的绑定和漂移工作。
可以借助keepalive这样的组件来完成VIP的绑定和漂移的工作,这里需要注意一点,keepalive管理的VIP发生漂移的触发动作是当前绑定VIP的主机上面的keepalive进程关闭退出之后,当前主机绑定的VIP才会发生漂移的动作。所以当我们的master节点如果没有发生宕机,只是MySQL进程出现问题不能访问的时候,我们是需要把当前的主机上面运行的keepalive进程给终止掉,才会发生VIP的漂移。所以,此时我们需要在MHA的master_ip_failover脚本整增加杀死已经死掉的主节点的keepalive进程,
或在keepalive的配置文件中配置一个监控MySQL服务的脚本,根据监控的结果来决定是否要杀死当前主节点的keepalive进程。
MHA中如何保证候选的master是从数据最接近宕机的master中选择出来的呢?可以设置几个candidate_master节点?
可以设置多个候选主节点,但是感觉意义不大。我们设置多个候选节点的目的是担心只要一个候选节点,万一这个候选节点挂掉了,就不能完成主从切换了。因为候选的主节点以及处于宕机的状态,所以这个节点不能用于提供主节点的服务。
但是实验证明,即便使我们设置两个以上的候选节点,如果其中任意一个候选节点出现宕机的情况,此时MHA是不能完成主从切换的。会出现如下的错误信息,在MHA尝试自动完成主从切换的时候。言外之意,如果MySQL集群中,已经存在一个候选节点宕机的情况,是不能自动完成主从切换的,需要保证集群中所有节点都是可用状态。
Sun Mar 7 19:46:16 2021 - [info] Replicating from 172.21.0.11(172.21.0.11:3306)
Sun Mar 7 19:46:16 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Sun Mar 7 19:46:16 2021 - [error][/usr/share/perl5/MHA/ServerManager.pm, ln492] Server 172.21.0.33(172.21.0.33:3306) is dead, but must be alive! Check server settings.
Sun Mar 7 19:46:16 2021 - [error][/usr/share/perl5/MHA/ManagerUtil.pm, ln178] Got ERROR: at /usr/share/perl5/MHA/MasterFailover.pm line 269.复制
如果备选主节点先于主节点宕机了,MHA会发现这个现象吗?主从切换还能完成吗?
MHA不会发现候选节点宕机或者任何一个从节点宕机的情况。如果发生这种现象,将不能完成主从自动切换。
备选主节点的数据不是最接近主节点的情况下,还可以切换成吗?
如果候选节点数据在主节点宕机的时候,它的数据不是和主节点最接近的,那么它会等待manager节点的命令,MHA会从最新的从节点中复制备用主节点没有的relay log,然后应用到备用主节点上,然后再把备用主节点提升为主节点。所以不用担子这个备用主节点数据不是最接近宕机主节点而导致数据丢失或主从复制终端的问题。
主从延迟很严重,导致MHA组从切换失败,怎么解决?
使用主从同步延迟的监控脚本,发现主从同步延迟出现的时候,及时想办法解决,避免当主节点宕机的时候,因为主从复制延迟的问题而导致主从切换失败。可以使用自定义的监控主从延迟的脚本,或者在脚本中调用masterha_check_repl --conf=/etc/app1.cnf
命令,这个是MHA中自带的一个检查主从复制状态的脚本。如果发现问题后,发送告警邮件,以便及时排查解决。
与此同事避免主从延迟的另外一个办法:开启半同步复制的方式在主从复制的时候。
如何避免MHA中发生脑裂的现象
什么是脑裂的现象?
当MAH的manager节点发现master节点宕机后,会把VIP通过它的回调脚本master_ip_failover_script 或者 master_ip_online_change_script
进行漂移。发生这个漂移的原因是MHA认为现在的主已经宕机了,所以选择了一个新的主,但是实际上,各个slave节点是可以连接到原先的master节点的,只是manager服务连接不同了,认为master节点挂掉了,此时MHA节点控制器和主机之间的网络故障可能会导致误报。所以现在在这个集群中有两个主:一个老的主,它任何和其他从节点进行主从同步,一个有MHA选择的新的主,它复制和应用从通过VIP来提供服务。此时就是脑裂的现象发生了。
如何避免呢?
可以配置secondary_check_script
参数,这个参数可以配置在/etc/mha/app1.cnf
配置文件总,参数的值为masterha_secondary_check
脚本的调用。这个脚本可以对mater节点再次确认是否真正的宕机了。这个脚本被执行后,会返回三个值:1,2,3。如果是1,则认为master确实宕机的,开启主从切换;如果是2,则认为是网络延迟导致,并不会开启主从切换的动作;如果是3,则认为master节点是健康的状态,不做任何操作。
另外就是尽量让MySQL集群和MHA的manager节点都处于同一个机房同一个网段内,尽量不要跨机房部署,如果非要跨机房部署,建议用光纤连接两地机房。
总结
关于MAH的高可用集群搭建、主从切换的实验就到这里了,如果你有什么疑问可以评论区留言,我们一起讨论。后续给大家分享MGR高可用集群的搭建和实验。
微信搜索“coder-home”或扫一扫下面的二维码,关注公众号,
第一时间了解更多干货分享,还有各类视频教程资源。扫描它,带走我
