说起国内的数据库,一般用的最多的是MySQL吧。最早接触,已经忘了是什么时候了,大概是上次进公司的时候,那时,给国内的项目整理过数据库表结构文档。也是我上一本笔记开始的第一页,MySQL相关的东西。笔记早已写完,第一页已经脱落,边缘已经泛黄。记录着我走过的一路……

最近凌晨两三点一直都被梦惊醒,自己给自己的压力太大了吗?而且梦境都特别清晰。如果时间没有记错的话,昨天梦到:姐夫安排的宣传工作,直接推给了朋友,说做好了我请客吃饭,结果朋友办了一个特别的“黑板报”。然后就醒了,然后我的感觉,喂,至少让我看看吃的啥饭。梦里出现的东西,多半和现实是有联系的。比如,白天姐夫给我打过电话,那天唯一一个电话。黑板报中的部分创意,和以前看过的视频有类似的地方,这是借鉴。话说我梦里的东西,算是我自己想的吧;今天做的,清晰度不是很高,但是醒了以后有点难以入眠。大概说的是,朋友私下做了个网站,结果有些东西匹配不了。我给了个建议,生成所有的脱氧核糖核酸,让后两小时内随机自由匹配,最后被采纳。这都是什么鬼!!!这些都忽略吧。后续是另一个朋友问,你们搞技术的,都喜欢干这个吧。最后我回的,“不是你做错了什么,而是对手做对了什么。不学习新的东西,就要被淘汰”。感觉逻辑上不对,不过这个梦记得不清,最关键的是,我醒了就睡不着了...不是这个,是最后那句话。可能和白天和别人讨论过一些MySQL数据库的问题,最后的结论是需要自己实践。还和别人聊过工作,还感触过...扯多了。聊聊主题相关的东西吧。上一次写VBA已经记不清是什么时候了。可能在上海,写过的两个工具,都和sql文有关。又或者在济南,写过从Excel表结构生成sql文。是那个已经都不重要了,因为它们都没有留下自己的存在,估计以后也用不到。然后是今天的主角,一个和上边相反的工具,根据表结构来生成文档。
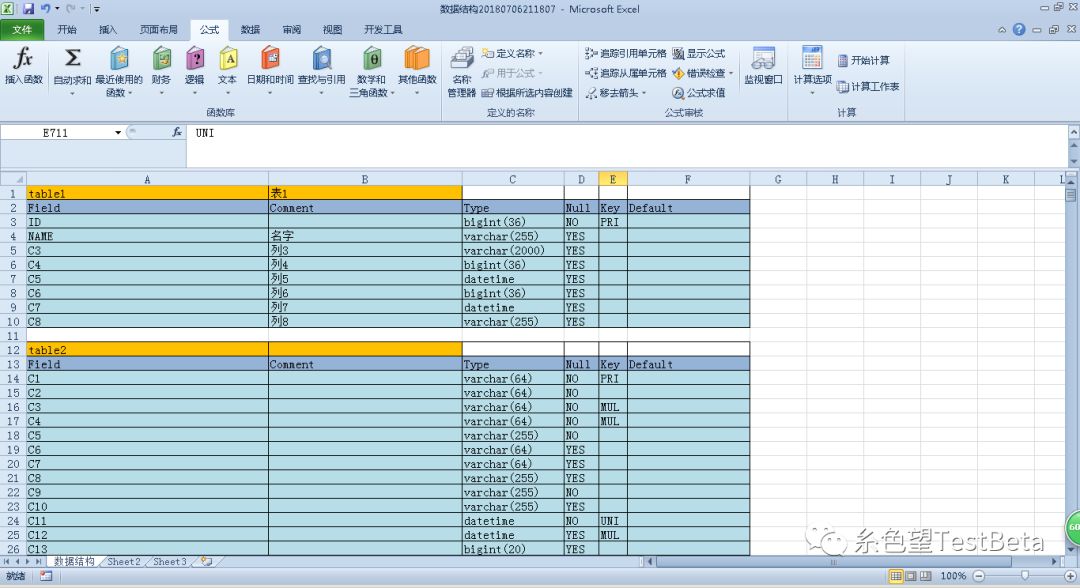
起因是想理解一下数据库结构,但是没有相应的文档,就打算边看边写。但是数据库有接近180的表,就有了写工具的想法。文档的话,首选VBA。源文件是基于Navicat for MySQL抽出的数据库结构文件。生成的结构是desc 表返回的结果去掉Extra列。
主要是晚上在公司写的,花费了4晚上,白天有一段时间在测试。本身难度不大,就是MySQL接触太少,有些地方需求不明确,没法实现。问朋友,也没有太明白的。本来打算实践的,不过查阅了一些资料,有了新的理解。主要有两个地方,一个是key值的设定。一个是数据类型的覆盖。
Key,网上解释的都大同小异。最后从官网看的文档。MySQL官网对key的解释,版本是8.0,看了一下7.5的解释,都是一样的。链接内容如下;
https://dev.mysql.com/doc/refman/8.0/en/show-columns.html
Key
Whether the column is indexed:
•If Key is empty, the column either is not indexed or is indexed onlyas a secondary column in a multiple-column, nonunique index.
•If Key is PRI, the column is a PRIMARY KEY or is one of the columnsin a multiple-column PRIMARY KEY.
•If Key is UNI, the column is the first column of a UNIQUE index. (AUNIQUE index permits multiple NULL values, but you can tell whether the columnpermits NULL by checking the Null field.)
•If Key is MUL, the column is the first column of a nonunique indexin which multiple occurrences of a given value are permitted within the column.
If more than one of the Key values appliesto a given column of a table, Key displays the one with the highest priority,in the order PRI, UNI, MUL.
A UNIQUE index may be displayed as PRI ifit cannot contain NULL values and there is no PRIMARY KEY in the table. AUNIQUE index may display as MUL if several columns form a composite UNIQUEindex; although the combination of the columns is unique, each column can stillhold multiple occurrences of a given value.
列中可能存在的索引:
•如果键是空的, 则该列没有索引或是非唯一索引的非第一行。
•如果键是PRI,则列是主键或多列主键中的列之一。
•如果键是UNI,则该列是唯一索引的第一列。(唯一索引允许多个空值,但可以通过检查Null字段来判断该列是否允许空。)
•如果键为MUL,则该列是非唯一索引的第一列,其中允许在列中多次出现给定值。
如果不止一个键值应用于表的给定列,则键以优先级PRI、UNI、MUL的顺序显示优先级最高的一个。
如果不能包含空值且表中没有主键,则可以显示唯一索引作为PRI。如果多个列形成复合唯一索引,则唯一索引可以显示为MUL;尽管列的组合是唯一的,但每个列仍然可以保持给定值的多次出现。
我的理解,也是按照下边逻辑写的,没有主键有唯一的情况未考虑:
只要是主键就表示PRI。
只要是单列唯一索引就表示UNI。
多列组合唯一索引第一列,非唯一索引第一列表示MUL。
唯一索引的非第一行,不表示。
数据类型是在跑的时候,报错才考虑。刚开始以为,比较偏的类型和常用的类型不一致,今天才返现我的想法是错误的。主要受到抽出的sql文件影响,真正的建表sql不是我想的那样后来修改了取数据的逻辑(数据类型带()时,现在的代码有可能报错,不过从navicat里抽出来的基本没这可能)。制作的过程如下。
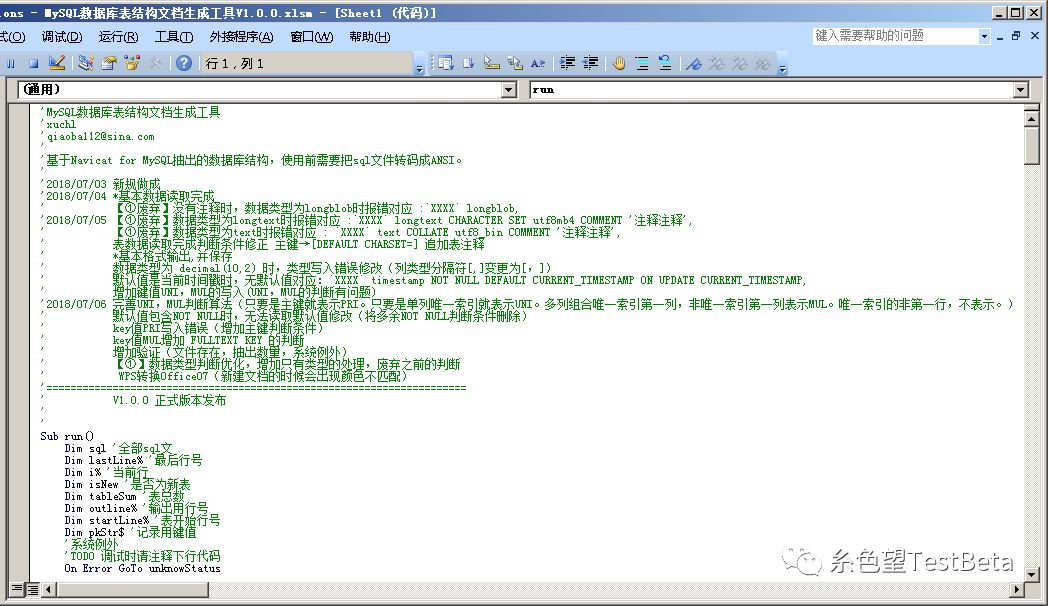
原理是根据sql文生成的样式固定,来截取需要的数据。比较复杂的,就是key值判断了。大概的感觉如下,因为没有优化,可读性很差。感兴趣的可以问我要工具,源码没有加密。即使加密也能破解,除了进入文档的密码外,都能破解。
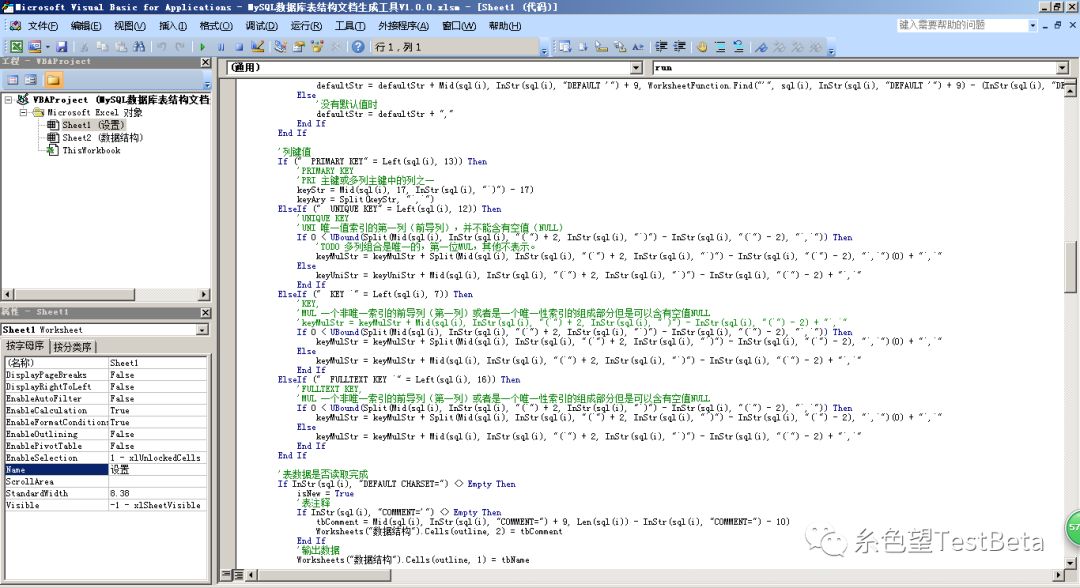
然后是界面,只能更改目标文件的路径。具体的情况可以看页面说明,懒得打了。
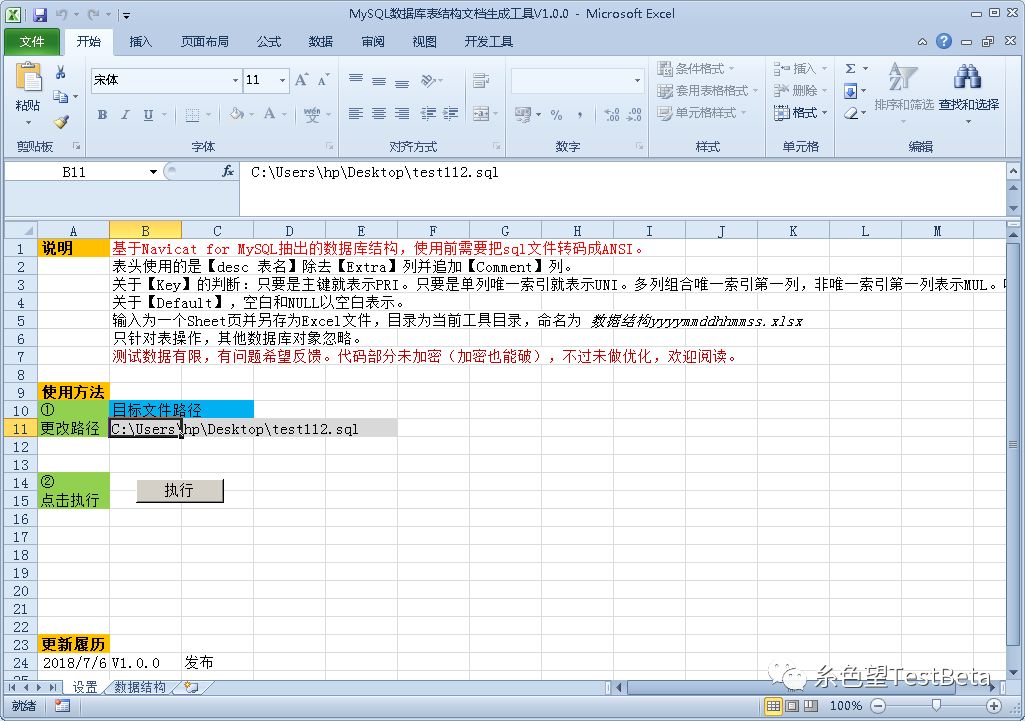
最后来一张生成完成的效果图吧。不知道对高版本的有没有影响。原来用wps写的,比我07应该高。发现颜色不兼容,又从新更新了背景色的代码,不然颜色太难看了。如果数据库本身就没有注释,也只能呵呵了。或许大神们有更好的办法,PL/SQL,脚本之类的,望赐教。